Kuwaiti Arabic: a Socio-Phonological Perspective
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

كتاب-الاحصاء-السنوي-الكهرباء-Compressed.Pdf
;jÁÊ“’\;Ï’ÂÄ State Of Kuwait ;ÍÊfiâ ’\;Ô]ë t¸\;g ]i— 2 0 2 0 ;ÎÄÅq i∏\;ÏÕ] ’\Â;Ô]∏\Â;Ô]dÖ‚“ ’\;ÎÑ\Ü ;ÄŬ’\;C;ÏË]dÖ‚“ ’\;ÏÕ] ’\;D 4 4 ” ; W ^ اﻟﻄﺎﻗﺔ اﻟﻜﻬﺮﺑﺎﺋﻴﺔ Electrical Energy Electricity & W ater & Renew able Energy f ;ÍÊfiâ’\;Ô]ët¸\;g]i— Statistical Year Book ;k]ŸÊ÷¬∏\;á—ÖŸÂ;Ô]ët¸\;ÎÑ\Äb;U;ÉË fihÂ;Ä\Å¡b M instry O 2021;U;Ñ\Åêb Statistical Year 2020 ( Electrical Energy ) Edition 44 “A” ;€ËtÖ’\;˛fl∂Ö’\;˛!\;€âd ;ÿ˛Ü]fi˛Ÿ;˛‰ˇÑ˛ÅÕ˛Â;\˛ÑÊ›;ˇÖ˛⁄˛Œ˛’\Â;˛Ô]˲î;ä˛⁄ç’\;◊˛¬˛p;Ͳɒ\;Ê˛·;Dˇ ’˛b;”˛’Ç;ٰ˛!\;ˇœ˛÷˛|;]˛Ÿ;˛ۚ;g]˛â˛¢\Â;˛Ø˛fiâ’\;Ä˛Å˛¡;\Ê˛⁄ˇ÷˛¬iˆ; C;;‡Ê˛⁄ˇ÷˛¬Á;˛‹ÊŒ˛’;k]Á˛˙\;◊ˇë ˛Á;ˇۚ;œ¢]˛d; ;C5D;ÏÁ˙\;U;ä›ÊÁ;ÎÑÊà ;ÓÅ ∏\;Ęe’\;3Ÿ^;Ê⁄â’\;ft]ê;ÎÖït @Åbjó€a@ãibßa@áº˛a@“aÏ„@ÑÓì€a ;jÁÊ“’\;Ï’ÂÄ;3Ÿ^ H.H Sheikh Nawaf Al-Ahmed Al-Jaber Al-Sabah The Amir of the State of Kuwait @Åbjó€a@ãibßa@áº˛a@›»ìfl@ÑÓì€a@Ï8 ;jÁÊ“’\;Ï’ÂÄ;Å‚¡;È’Â H.H Sheikh Mishal Al-Ahmed Al-Jaber Al-Sabah The Crown Prince of the State of Kuwait تقديم تعمل وزارة الكهرباء واملاء جاهدةً على املشاركة يف حتقيق رؤية 2035 التنموية يف جمال توليد الطاقة الكهربائية وحتلية املياه ، ومن اجلهود الواضحة يف هذا اجملال إدخال تكنولوجيا الطاقة البديلة )املتجددة( تدرجيياً للعمل جنباً إىل جنب مع مصادر الطاقة اﻷخرى . إن اهلدف املخطط له من قِبل الوزارة ضمن رؤية 2035 هو الوصول بإنتاج الطاقة الكهربائيةة البديلة إىل ما نسبته 15% من حاجة البﻻد الكلية من الطاقة الكهربائية وحتقيق اﻷمن املائي ، وذلك من خﻻل حتفيز برنامج الشراكة بني القطاعني العام واخلاص يف تنفيذ بعض مشاريع الطاقة الكهربائية وحتلية املياه . -

News Harvard University
THE CENTER FOR MIDDLE EASTERN STUDIES, NEWS HARVARD UNIVERSITY SPRING 2015 1 LETTER FROM THE DIRECTOR A message from William Granara 2 SHIFTING TOWARDS THE ARABIAN PENINSULA Announcing a new lecture series 3 NEWS AND NOTES Updates from faculty, students and visiting researchers 12 EVENT HIGHLIGHTS Spring lectures, workshops, and conferences LETTER FROM THE DIRECTOR SPRING 2015 HIGHLIGHTS I’M HAPPY TO REPORT THAT WE ARE DRAWING TO THE CLOSE OF AN ACADEMIC YEAR FULL OF ACTIVITY. CMES was honored to host a considerable number of outstanding lectures this year by eminent scholars from throughout the U.S. as well as from the Middle East and Europe. I mention only a few highlights below. Our new Middle Eastern Literatures initiative was advanced by several events: campus visits by Arab novelists Mai Nakib (Kuwait), Ahmed Khaled Towfik (Egypt), and Ali Bader (Iraq); academic lectures by a range of literary scholars including Hannan Hever (Yale) on Zionist literature and Sheida Dayani (NYU) on contemporary Persian theater; and a highly successful seminar on intersections between Arabic and Turkish literatures held at Bilgi University in Istanbul, which included our own Professor Cemal Kafadar, several of our graduate students, and myself. In early April, CMES along with two Harvard Iranian student groups hosted the first Harvard Iranian Gala, which featured a lecture by Professor Abbas Milani of Stanford University and was attended by over one hundred guests from the broader Boston Iranian community. Also in April, CMES co-sponsored an international multilingual conference on The Thousand and One Nights with INALCO, Paris. Our new Arabian Peninsula Studies Lecture Series was inaugurated with a lecture by Professor David Commins of Dickinson College, and we are happy to report that this series will continue in both the fall and spring semesters of next year thanks to the generous support of CMES alumni. -

Kuwait Targeted by Terrorism: Ghanem Egypt Police Foil Attack at Famed Luxor
SUBSCRIPTION THURSDAY, JUNE 11, 2015 SHAABAN 24, 1436 AH www.kuwaittimes.net Ibn Sina Policeman Africa leaders FIFA Hospital who pulled sign ‘Cape to suspends hit by gun at Texas Cairo’ free trade 2026 World blackout4 pool resigns9 bloc21 deal Cup20 bidding Kuwait targeted by Min 32º Max 48º High Tide terrorism: Ghanem 06:50 & 18:40 Low Tide Government briefs MPs on beefed-up security 00:05 & 13:15 40 PAGES NO: 16548 150 FILS By B Izzak Kuwaiti media delegation visits Kurdistan KUWAIT: Speaker of the National Assembly Marzouq Al- Ghanem said yesterday that no country in the region including Kuwait is safe from terror plots, and the coun- try is a target for terrorists. Speaking after the govern- ment briefed MPs on the securi- ty situation and raising the secu- rity alert, Ghanem said Interior Minister Sheikh Mohammad Al- Khaled Al-Sabah provided the meeting with a detailed report on protection provided to mosques, husseiniyas and other worship places. MPs had requested to hold a Marzouq Al-Ghanem debate in the Assembly about security measures in the country following suicide bombings at Shiite mosques in Saudi Arabia, but the Assembly and government agreed to hold the meeting behind closed doors at the Assembly bureau. Ghanem said Foreign Minister Sheikh Sabah Al-Khaled Al-Sabah Continued on Page 13 Bank hours in Ramadan KUWAIT: The Kuwait Banking Association announced yesterday that the banks’ work hours dur- ing Ramadan would be from 9:30 am to 2 pm. Banks will serve clients from 10 am until 1 pm, said the ERBIL, Iraq: President of the Kurdistan region of Iraq Masoud Barzani (center) meets members of a Kuwaiti media delegation including Kuwait Times Editor-in- association, citing a relevant statement of instruc- Chief Abd Al-Rahman Al-Alyan (right) yesterday. -

FOREIGNER TALK in ARABIC Input in Circumstances Such As Those
CHAPTER SIX FOREIGNER TALK IN ARABIC Input in circumstances such as those illustrated in chapter four took place by means of modifying the target language (i.e. tendencies of Foreigner Talk). Because Arabs, as the native speakers of the target language, were the majority group in the loci of early communica- tion, they themselves were able to undertake the initiative of modify- ing their native language, especially when the majority of them were monolinguals. Although heavy restructuring and loaning from a for- eign language have permanently affected the formation of varieties of Arabic elsewhere in East Africa and Asia, the type of input and the non-linguistic ecological conditions that facilitated it in the now-Arab world inhibited this process in the case of the dialects. It is unlikely, according to the conclusion of the previous chapter, that native speak- ers undertake a heavy restructuring of their language, even if the purpose is educational. If heavy restructuring is attempted by native speakers it takes place in highly marked situations. When restructur- ing occurs, however, the upgrading nature of FT does not allow a per- manent mark on the output of the non-native speaker. Generally speaking, if FT should be grammatical, and if the con- clusions concerning the socio-demographics of Arabicization have any historical truth, then it must be responsible for the differences between Classical Arabic (as the nearest variety to pre-Islamic Arabic) and the Modern Arabic dialects. These differences are less than the differences between Classical Arabic and Modern Standard Arabic on the one hand and the Arabic-based pidgins and creoles on the other, but are in many respects the result of internal processes, such as gen- eralization and reduction. -

PRIVATE HOUSING MURSHID 2014 Brief on Real Estate Union
PRIVATE HOUSING MURSHID 2014 Brief on Real Estate Union Real Estate Association was established in 1990 by a distinguished group headed by late Sheikh Nasser Saud Al-Sabah who exerted a lot of efforts to establish the Association. Bright visionary objectives were the motives to establish the Association. The Association works to sustainably fulfil these objectives through institutional mechanisms, which provide the essential guidelines and controls. The Association seeks to act as an umbrella gathering the real estate owners and represent their common interests in the business community, overseeing the rights of the real estate professionals and further playing a prominent role in developing the real estate sector to be a major and influential player in the economic decision-making in Kuwait. The Association also offers advisory services that improve the real estate market in Kuwait and enhance the safety of the real estate investments, which result in increasing the market attractiveness for more investment. The Association considers as a priority keeping the investment interests of its members and increase the membership base to include all owners segments of the commercial and investment real estate. Summary Private housing segment is the single most important segment of real estate industry in Kuwait. The land parcels zoned for private housing account for 78% of all land parcels in Kuwait and the segment is the main source of wealth (as family houses) for most of the households. This report is written with an objective to provide a comprehensive analysis of this segment with the historical trends of prices, rental activities, and impact of land features on property prices. -

Semantic Innovation and Change in Kuwaiti Arabic: a Study of the Polysemy of Verbs
` Semantic Innovation and Change in Kuwaiti Arabic: A Study of the Polysemy of Verbs Yousuf B. AlBader Thesis submitted to the University of Sheffield in fulfilment of the requirements for the degree of Doctor of Philosophy in the School of English Literature, Language and Linguistics April 2015 ABSTRACT This thesis is a socio-historical study of semantic innovation and change of a contemporary dialect spoken in north-eastern Arabia known as Kuwaiti Arabic. I analyse the structure of polysemy of verbs and their uses by native speakers in Kuwait City. I particularly report on qualitative and ethnographic analyses of four motion verbs: dašš ‘enter’, xalla ‘leave’, miša ‘walk’, and i a ‘run’, with the aim of establishing whether and to what extent linguistic and social factors condition and constrain the emergence and development of new senses. The overarching research question is: How do we account for the patterns of polysemy of verbs in Kuwaiti Arabic? Local social gatherings generate more evidence of semantic innovation and change with respect to the key verbs than other kinds of contexts. The results of the semantic analysis indicate that meaning is both contextually and collocationally bound and that a verb’s meaning is activated in different contexts. In order to uncover the more local social meanings of this change, I also report that the use of innovative or well-attested senses relates to the community of practice of the speakers. The qualitative and ethnographic analyses demonstrate a number of differences between friendship communities of practice and familial communities of practice. The groups of people in these communities of practice can be distinguished in terms of their habits of speech, which are conditioned by the situation of use. -

Al Koot Kuwait Provider Network
AlKoot Insurance & Reinsurance Partner Contact Details: Kuwait network providers list Partner name: Globemed Tel: +961 1 518 100 Email: [email protected] Agreement type Provider Name Provider Type Provider Address City Country Partner Al Salam International Hospital Hospital Bnaid Al Gar Kuwait City Kuwait Partner London Hospital Hospital Al Fintas Kuwait City Kuwait Partner Dar Al Shifa Hospital Hospital Hawally Kuwait City Kuwait Partner Al Hadi Hospital Hospital Jabriya Kuwait City Kuwait Partner Al Orf Hospital Hospital Al Jahra Kuwait City Kuwait Partner Royale Hayat Hospital Hospital Jabriyah Kuwait City Kuwait Partner Alia International Hospital Hospital Mahboula Kuwait City Kuwait Partner Sidra Hospital Hospital Al Reggai Kuwait City Kuwait Partner Al Rashid Hospital Hospital Salmiya Kuwait City Kuwait Partner Al Seef Hospital Hospital Salmiya Kuwait City Kuwait Partner New Mowasat Hospital Hospital Salmiya Kuwait City Kuwait Partner Taiba Hospital Hospital Sabah Al-Salem Kuwait City Kuwait Partner Kuwait Hospital Hospital Sabah Al-Salem Kuwait City Kuwait Partner Medical One Polyclinic Medical Center Al Da'iyah Kuwait City Kuwait Partner Noor Clinic Medical Center Al Ageila Kuwait City Kuwait Partner Quttainah Medical Center Medical Center Al Shaab Al Bahri Kuwait City Kuwait Partner Shaab Medical Center Medical Center Al Shaab Al Bahri Kuwait City Kuwait Partner Al Saleh Clinic Medical Center Abraq Kheetan Kuwait City Kuwait Partner Global Medical Center Medical Center Benaid Al qar Kuwait City Kuwait Partner New Life -
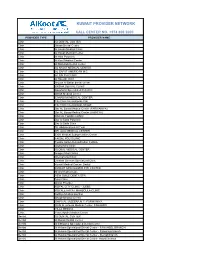
Kuwait Provider Network
KUWAIT PROVIDER NETWORK CALL CENTER NO. +974 800 2000 PROVIDER TYPE PROVIDER NAME Clinic 32 DENTAL CENTER Clinic Aknan Dental Center Clinic Al Ansari Medical Clinic Clinic Al Hayat Medical Center Clinic Al Hilal Polyclinic Clinic Al Kout Medical Center Clinic Al Muhallab Dental Center Clinic AL NAJAT MEDICAL CENTER Clinic AL SAFAT AMERICAN M.C. Clinic AL SALEH CLINIC Clinic Al Sayegh Clinic Clinic Arouss Al Bahar dental center Clinic BASMA DENTAL CLINIC Clinic Boushahri Specialized Polyclinic Clinic British Medical Center Clinic CANADIAN MEDICAL CENTER Clinic City Clinic International- Fah Clinic City Clinic International- Mirgab Clinic Dar AL Baraa Medical Center (FARWANIYA) Clinic Dar AL Baraa Medical Center (JABRIYA) Clinic DAR AL FOUAD CLINIC Clinic Dar Al Saha Polyclinic Clinic Dar Al Shifa Clinic Clinic Dr. Abdulmohsen Al Terki Clinic DR. ALIA MEDICAL CENTER Clinic EXIR Medical Subspecialties Center Clinic FAISAL POLYCLINIC Clinic Fawzia Sultan Rehabilitation Institute Clinic Global Med Clinic Clinic GLOBAL MEDICAL CENTER Clinic Images Med Clinics Clinic International Clinic Clinic Jarallah German Specialized Clinic Clinic Kuwait Medical Center- Dental Clinic KUWAIT SPECIALIZED EYE CENTER Clinic Metro Medical Care Clinic NEW SMILE DENTA SPA Clinic Noor Clinic Clinic Oman Provider Clinic ROYAL CITY CLINIC - JLEEB Clinic ROYALE HAYAT MAHBOULA CLINIC Clinic Salhiya Medical pavilion Clinic Shaab Medical Center Clinic SHIFA AL JAZEERA M.C.-FARWANIYA Clinic Shifa Al Jazeera Medical Center, FAHAHEEL Clinic VILLA MEDICA Clinic Yiaco Apollo -

Comparative Geomatic Analysis of Historic Development, Trends, And
University of Arkansas, Fayetteville ScholarWorks@UARK Theses and Dissertations 5-2015 Comparative Geomatic Analysis of Historic Development, Trends, and Functions of Green Space in Kuwait City From 1982-2014 Yousif Abdullah University of Arkansas, Fayetteville Follow this and additional works at: http://scholarworks.uark.edu/etd Part of the Near and Middle Eastern Studies Commons, Physical and Environmental Geography Commons, and the Urban Studies and Planning Commons Recommended Citation Abdullah, Yousif, "Comparative Geomatic Analysis of Historic Development, Trends, and Functions of Green Space in Kuwait City From 1982-2014" (2015). Theses and Dissertations. 1116. http://scholarworks.uark.edu/etd/1116 This Thesis is brought to you for free and open access by ScholarWorks@UARK. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of ScholarWorks@UARK. For more information, please contact [email protected], [email protected]. Comparative Geomatic Analysis of Historic Development, Trends, and Functions Of Green Space in Kuwait City From 1982-2014. Comparative Geomatic Analysis of Historic Development, Trends, and Functions Of Green Space in Kuwait City From 1982-2014. A Thesis submitted in partial fulfillment Of the requirements for the Degree of Master of Art in Geography By Yousif Abdullah Kuwait University Bachelor of art in GIS/Geography, 2011 Kuwait University Master of art in Geography May 2015 University of Arkansas This thesis is approved for recommendation to the Graduate Council. ____________________________ Dr. Ralph K. Davis Chair ____________________________ ___________________________ Dr. Thomas R. Paradise Dr. Fiona M. Davidson Thesis Advisor Committee Member ____________________________ ___________________________ Dr. Mohamed Aly Dr. Carl Smith Committee Member Committee Member ABSTRACT This research assessed green space morphology in Kuwait City, explaining its evolution from 1982 to 2014, through the use of geo-informatics, including remote sensing, geographic information systems (GIS), and cartography. -
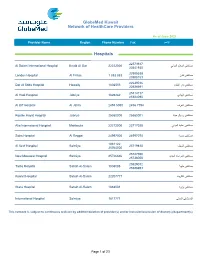
Globemed Kuwait Network of Providers Exc KSEC and BAYAN
GlobeMed Kuwait Network of HealthCare Providers As of June 2021 Phone ﺍﻻﺳﻡ ProviderProvider Name Name Region Region Phone Number FFaxax Number Number Hospitals 22573617 ﻣﺳﺗﺷﻔﻰ ﺍﻟﺳﻼﻡ ﺍﻟﺩﻭﻟﻲ Al Salam International Hospital Bnaid Al Gar 22232000 22541930 23905538 ﻣﺳﺗﺷﻔﻰ ﻟﻧﺩﻥ London Hospital Al Fintas 1 883 883 23900153 22639016 ﻣﺳﺗﺷﻔﻰ ﺩﺍﺭ ﺍﻟﺷﻔﺎء Dar Al Shifa Hospital Hawally 1802555 22626691 25314717 ﻣﺳﺗﺷﻔﻰ ﺍﻟﻬﺎﺩﻱ Al Hadi Hospital Jabriya 1828282 25324090 ﻣﺳﺗﺷﻔﻰ ﺍﻟﻌﺭﻑ Al Orf Hospital Al Jahra 2455 5050 2456 7794 ﻣﺳﺗﺷﻔﻰ ﺭﻭﻳﺎﻝ ﺣﻳﺎﺓ Royale Hayat Hospital Jabriya 25360000 25360001 ﻣﺳﺗﺷﻔﻰ ﻋﺎﻟﻳﺔ ﺍﻟﺩﻭﻟﻲ Alia International Hospital Mahboula 22272000 23717020 ﻣﺳﺗﺷﻔﻰ ﺳﺩﺭﺓ Sidra Hospital Al Reggai 24997000 24997070 1881122 ﻣﺳﺗﺷﻔﻰ ﺍﻟﺳﻳﻑ Al Seef Hospital Salmiya 25719810 25764000 25747590 ﻣﺳﺗﺷﻔﻰ ﺍﻟﻣﻭﺍﺳﺎﺓ ﺍﻟﺟﺩﻳﺩ New Mowasat Hospital Salmiya 25726666 25738055 25529012 ﻣﺳﺗﺷﻔﻰ ﻁﻳﺑﺔ Taiba Hospital Sabah Al-Salem 1808088 25528693 ﻣﺳﺗﺷﻔﻰ ﺍﻟﻛﻭﻳﺕ Kuwait Hospital Sabah Al-Salem 22207777 ﻣﺳﺗﺷﻔﻰ ﻭﺍﺭﺓ Wara Hospital Sabah Al-Salem 1888001 ﺍﻟﻣﺳﺗﺷﻔﻰ ﺍﻟﺩﻭﻟﻲ International Hospital Salmiya 1817771 This network is subject to continuous revision by addition/deletion of provider(s) and/or inclusion/exclusion of doctor(s)/department(s) Page 1 of 23 GlobeMed Kuwait Network of HealthCare Providers As of June 2021 Phone ﺍﻻﺳﻡ ProviderProvider Name Name Region Region Phone Number FaxFax Number Number Medical Centers ﻣﺳﺗﻭﺻﻑ ﻣﻳﺩﻳﻛﺎﻝ ﻭﻥ ﺍﻟﺗﺧﺻﺻﻲ Medical one Polyclinic Al Da'iyah 22573883 22574420 1886699 ﻋﻳﺎﺩﺓ ﻧﻭﺭ Noor Clinic Al Ageila 23845957 23845951 22620420 ﻣﺭﻛﺯ ﺍﻟﺷﻌﺏ ﺍﻟﺗﺧﺻﺻﻲ -

Findings and Discussions on Coastal Evolution of Kuwait, Review of Laws and Perspective of Developed Strategies
Journal of Image and Graphics, Volume 1, No.1, March, 2013 Findings and Discussions on Coastal Evolution of Kuwait, Review of Laws and Perspective of Developed Strategies S. Baby1, 2 1Birla Institute of Technology, Department of Remote Sensing & Geoinformatics, Mesra, India. 2GEO Environmental Consultation, Hawally, P. O. Box: 677, Al-Surra 4507, Kuwait. Email: [email protected] Abstract—The development, life style and supportive system nature of CML transformation from human intervention have exploited the coast more rather than the interior that took place in the coastal zone of Kuwait since early offshore land of Kuwait, thereby altering the morphological 1960s i.e. more than five (5) decades. During these landscape through built up structures, population migration, interlude of time the natural coastal landscape have coastline change, habitat change and land use apart from undergone tremendous change. natural process. As a result Kuwait’s coastal landscape has been subjected to tremendous evolution which was studied from remotely sensed images, historical pictures, aerial II. RESEARCH METHODS AND FRAMEWORK video survey and various visuals. Each of the section Here are general techniques and tools (referred from documents the research result in itself that was accomplished with specific purpose that takes the entire Baby (2010) [3] that were utilized for the research: studies to the ultimate goal of exploring the trend in coastal Data and Input Information: evolution. The important tool used for the study was 1) Primary information: (a) field work (b) Remote Sensing Techniques, Geographical Information reconnaissance survey with ground and aerial (flight) System, Interpretation of Images, Analytical Hierarchical survey and (c) remotely sensed data. -

Enduring Authority: Kinship, State Formation, and Resource Distribution in the Arab Gulf
Enduring Authority: Kinship, State Formation, and Resource Distribution in the Arab Gulf by Scott Weiner B.A. in International Relations, May 2008, Tufts University M.A. in Political Science, May 2013, The George Washington University A Dissertation submitted to The Faculty of The Columbian College of Arts and Sciences of The George Washington University in partial fulfillment of the requirements for the degree of Doctor of Philosophy May 15, 2016 Dissertation directed by Nathan J. Brown Professor of Political Science and International Affairs The Columbian College of Arts and Sciences of The George Washington University cer- tifies that Scott J. Weiner has passed the Final Examination for the degree of Doctor of philosophy as of March 25, 2016. This is the final and approved form of the dissertation. Enduring Authority: Kinship, State Formation, and Resource Distribution in the Arab Gulf Scott Weiner Dissertation Research Committee: Nathan J. Brown, Professor of Political Science and International Affairs, Dissertation Director. Marc Lynch, Professor, Professor of Political Science and International Affairs, Committee Member. Henry E. Hale, Professor of Political Science and International Affairs, Committee Member. !ii © Copyright 2016 by Scott Weiner All rights reserved !iii Acknowledgements The author wishes to acknowledge those without whom this dissertation would not have been written. Without the consistent support of Ronnie Olesker and Richard Eichenberg I would not have completed an undergraduate thesis or pursued a doctorate of Political Science. Jamal al-Kirnawi introduced me to the world of Bedouin tribal poli- tics. Kimberly Kagan provided invaluable advice on completing graduate studies that prepared me for the marathon of doctoral study.