The RNA Atlas, a Single Nucleotide Resolution Map of the Human Transcriptome
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
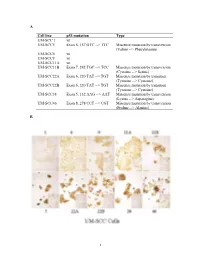
A Cell Line P53 Mutation Type UM
A Cell line p53 mutation Type UM-SCC 1 wt UM-SCC5 Exon 5, 157 GTC --> TTC Missense mutation by transversion (Valine --> Phenylalanine UM-SCC6 wt UM-SCC9 wt UM-SCC11A wt UM-SCC11B Exon 7, 242 TGC --> TCC Missense mutation by transversion (Cysteine --> Serine) UM-SCC22A Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC22B Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC38 Exon 5, 132 AAG --> AAT Missense mutation by transversion (Lysine --> Asparagine) UM-SCC46 Exon 8, 278 CCT --> CGT Missense mutation by transversion (Proline --> Alanine) B 1 Supplementary Methods Cell Lines and Cell Culture A panel of ten established HNSCC cell lines from the University of Michigan series (UM-SCC) was obtained from Dr. T. E. Carey at the University of Michigan, Ann Arbor, MI. The UM-SCC cell lines were derived from eight patients with SCC of the upper aerodigestive tract (supplemental Table 1). Patient age at tumor diagnosis ranged from 37 to 72 years. The cell lines selected were obtained from patients with stage I-IV tumors, distributed among oral, pharyngeal and laryngeal sites. All the patients had aggressive disease, with early recurrence and death within two years of therapy. Cell lines established from single isolates of a patient specimen are designated by a numeric designation, and where isolates from two time points or anatomical sites were obtained, the designation includes an alphabetical suffix (i.e., "A" or "B"). The cell lines were maintained in Eagle's minimal essential media supplemented with 10% fetal bovine serum and penicillin/streptomycin. -

MYC-Containing Amplicons in Acute Myeloid Leukemia: Genomic Structures, Evolution, and Transcriptional Consequences
Leukemia (2018) 32:2152–2166 https://doi.org/10.1038/s41375-018-0033-0 ARTICLE Acute myeloid leukemia Corrected: Correction MYC-containing amplicons in acute myeloid leukemia: genomic structures, evolution, and transcriptional consequences 1 1 2 2 1 Alberto L’Abbate ● Doron Tolomeo ● Ingrid Cifola ● Marco Severgnini ● Antonella Turchiano ● 3 3 1 1 1 Bartolomeo Augello ● Gabriella Squeo ● Pietro D’Addabbo ● Debora Traversa ● Giulia Daniele ● 1 1 3 3 4 Angelo Lonoce ● Mariella Pafundi ● Massimo Carella ● Orazio Palumbo ● Anna Dolnik ● 5 5 6 2 7 Dominique Muehlematter ● Jacqueline Schoumans ● Nadine Van Roy ● Gianluca De Bellis ● Giovanni Martinelli ● 3 4 8 1 Giuseppe Merla ● Lars Bullinger ● Claudia Haferlach ● Clelia Tiziana Storlazzi Received: 4 August 2017 / Revised: 27 October 2017 / Accepted: 13 November 2017 / Published online: 22 February 2018 © The Author(s) 2018. This article is published with open access Abstract Double minutes (dmin), homogeneously staining regions, and ring chromosomes are vehicles of gene amplification in cancer. The underlying mechanism leading to their formation as well as their structure and function in acute myeloid leukemia (AML) remain mysterious. We combined a range of high-resolution genomic methods to investigate the architecture and expression pattern of amplicons involving chromosome band 8q24 in 23 cases of AML (AML-amp). This 1234567890();,: revealed that different MYC-dmin architectures can coexist within the same leukemic cell population, indicating a step-wise evolution rather than a single event origin, such as through chromothripsis. This was supported also by the analysis of the chromothripsis criteria, that poorly matched the model in our samples. Furthermore, we found that dmin could evolve toward ring chromosomes stabilized by neocentromeres. -

Genome-Wide Screen of Cell-Cycle Regulators in Normal and Tumor Cells
bioRxiv preprint doi: https://doi.org/10.1101/060350; this version posted June 23, 2016. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Genome-wide screen of cell-cycle regulators in normal and tumor cells identifies a differential response to nucleosome depletion Maria Sokolova1, Mikko Turunen1, Oliver Mortusewicz3, Teemu Kivioja1, Patrick Herr3, Anna Vähärautio1, Mikael Björklund1, Minna Taipale2, Thomas Helleday3 and Jussi Taipale1,2,* 1Genome-Scale Biology Program, P.O. Box 63, FI-00014 University of Helsinki, Finland. 2Science for Life laboratory, Department of Biosciences and Nutrition, Karolinska Institutet, SE- 141 83 Stockholm, Sweden. 3Science for Life laboratory, Division of Translational Medicine and Chemical Biology, Department of Medical Biochemistry and Biophysics, Karolinska Institutet, S-171 21 Stockholm, Sweden To identify cell cycle regulators that enable cancer cells to replicate DNA and divide in an unrestricted manner, we performed a parallel genome-wide RNAi screen in normal and cancer cell lines. In addition to many shared regulators, we found that tumor and normal cells are differentially sensitive to loss of the histone genes transcriptional regulator CASP8AP2. In cancer cells, loss of CASP8AP2 leads to a failure to synthesize sufficient amount of histones in the S-phase of the cell cycle, resulting in slowing of individual replication forks. Despite this, DNA replication fails to arrest, and tumor cells progress in an elongated S-phase that lasts several days, finally resulting in death of most of the affected cells. -

A Yeast Phenomic Model for the Influence of Warburg Metabolism on Genetic Buffering of Doxorubicin Sean M
Santos and Hartman Cancer & Metabolism (2019) 7:9 https://doi.org/10.1186/s40170-019-0201-3 RESEARCH Open Access A yeast phenomic model for the influence of Warburg metabolism on genetic buffering of doxorubicin Sean M. Santos and John L. Hartman IV* Abstract Background: The influence of the Warburg phenomenon on chemotherapy response is unknown. Saccharomyces cerevisiae mimics the Warburg effect, repressing respiration in the presence of adequate glucose. Yeast phenomic experiments were conducted to assess potential influences of Warburg metabolism on gene-drug interaction underlying the cellular response to doxorubicin. Homologous genes from yeast phenomic and cancer pharmacogenomics data were analyzed to infer evolutionary conservation of gene-drug interaction and predict therapeutic relevance. Methods: Cell proliferation phenotypes (CPPs) of the yeast gene knockout/knockdown library were measured by quantitative high-throughput cell array phenotyping (Q-HTCP), treating with escalating doxorubicin concentrations under conditions of respiratory or glycolytic metabolism. Doxorubicin-gene interaction was quantified by departure of CPPs observed for the doxorubicin-treated mutant strain from that expected based on an interaction model. Recursive expectation-maximization clustering (REMc) and Gene Ontology (GO)-based analyses of interactions identified functional biological modules that differentially buffer or promote doxorubicin cytotoxicity with respect to Warburg metabolism. Yeast phenomic and cancer pharmacogenomics data were integrated to predict differential gene expression causally influencing doxorubicin anti-tumor efficacy. Results: Yeast compromised for genes functioning in chromatin organization, and several other cellular processes are more resistant to doxorubicin under glycolytic conditions. Thus, the Warburg transition appears to alleviate requirements for cellular functions that buffer doxorubicin cytotoxicity in a respiratory context. -

Deletions of IKZF1 and SPRED1 Are Associated with Poor Prognosis in A
Leukemia (2014) 28, 302–310 & 2014 Macmillan Publishers Limited All rights reserved 0887-6924/14 www.nature.com/leu ORIGINAL ARTICLE Deletions of IKZF1 and SPRED1 are associated with poor prognosis in a population-based series of pediatric B-cell precursor acute lymphoblastic leukemia diagnosed between 1992 and 2011 L Olsson1, A Castor2, M Behrendtz3, A Biloglav1, E Forestier4, K Paulsson1 and B Johansson1,5 Despite the favorable prognosis of childhood acute lymphoblastic leukemia (ALL), a substantial subset of patients relapses. As this occurs not only in the high risk but also in the standard/intermediate groups, the presently used risk stratification is suboptimal. The underlying mechanisms for treatment failure include the presence of genetic changes causing insensitivity to the therapy administered. To identify relapse-associated aberrations, we performed single-nucleotide polymorphism array analyses of 307 uniformly treated, consecutive pediatric ALL cases accrued during 1992–2011. Recurrent aberrations of 14 genes in patients who subsequently relapsed or had induction failure were detected. Of these, deletions/uniparental isodisomies of ADD3, ATP10A, EBF1, IKZF1, PAN3, RAG1, SPRED1 and TBL1XR1 were significantly more common in B-cell precursor ALL patients who relapsed compared with those remaining in complete remission. In univariate analyses, age (X10 years), white blood cell counts (4100 Â 109/l), t(9;22)(q34;q11), MLL rearrangements, near-haploidy and deletions of ATP10A, IKZF1, SPRED1 and the pseudoautosomal 1 regions on Xp/Yp were significantly associated with decreased 10-year event-free survival, with IKZF1 abnormalities being an independent risk factor in multivariate analysis irrespective of the risk group. Older age and deletions of IKZF1 and SPRED1 were also associated with poor overall survival. -

Identification of the Molecular Mechanisms Underlying Dilated Cardiomyopathy Via Bioinformatic Analysis of Gene Expression Profiles
EXPERIMENTAL AND THERAPEUTIC MEDICINE 13: 273-279, 2017 Identification of the molecular mechanisms underlying dilated cardiomyopathy via bioinformatic analysis of gene expression profiles HU ZHANG1, ZHUO YU2, JIANCHAO HE1, BAOTONG HUA2 and GUIMING ZHANG1 Departments of 1Cardiaovascular Surgery and 2Cardiology, The First Affiliated Hospital of Kunming Medical University, Kunming, Yunnan 650032, P.R. China Received March 26, 2015; Accepted April 21, 2016 DOI: 10.3892/etm.2016.3953 Abstract. In the present study, gene expression profiles of binding protein 3 (IGFBP3)], ‘muscle organ development’ patients with dilated cardiomyopathy (DCM) were re‑analyzed (SMAD7) and ‘regulation of cell migration’ [SMAD7, IGFBP3 with bioinformatics tools to investigate the molecular mecha- and insulin receptor (INSR)]. Notably, signal transducer and nisms underlying DCM. Gene expression dataset GSE3585 activator of transcription 3, SMAD7, INSR, CTGF, exportin 1, was downloaded from Gene Expression Omnibus, which IGFBP3 and phosphatidylinositol‑4,5‑bisphosphate 3‑kinase, included seven heart biopsy samples obtained from patients catalytic subunit alpha were hub nodes with the higher degree with DCM and five healthy controls. Differential analysis was in the PPI network. Therefore, the results of the present study performed using a Limma package in R to screen for differen- suggested that DEGs may alter the biological processes of tially expressed genes (DEGs). Functional enrichment analysis ‘nucleosome formation’, ‘cell adhesion’, ‘skeletal system devel- was subsequently conducted for DEGs using the Database opment’, ‘muscle organ development’ and ‘regulation of cell for Annotation, Visualization and Integration Discovery. A migration’ in the development of DCM. protein‑protein interaction (PPI) network was constructed using information from Search Tool for the Retrieval of Introduction Interacting Genes software. -

Role and Regulation of the P53-Homolog P73 in the Transformation of Normal Human Fibroblasts
Role and regulation of the p53-homolog p73 in the transformation of normal human fibroblasts Dissertation zur Erlangung des naturwissenschaftlichen Doktorgrades der Bayerischen Julius-Maximilians-Universität Würzburg vorgelegt von Lars Hofmann aus Aschaffenburg Würzburg 2007 Eingereicht am Mitglieder der Promotionskommission: Vorsitzender: Prof. Dr. Dr. Martin J. Müller Gutachter: Prof. Dr. Michael P. Schön Gutachter : Prof. Dr. Georg Krohne Tag des Promotionskolloquiums: Doktorurkunde ausgehändigt am Erklärung Hiermit erkläre ich, dass ich die vorliegende Arbeit selbständig angefertigt und keine anderen als die angegebenen Hilfsmittel und Quellen verwendet habe. Diese Arbeit wurde weder in gleicher noch in ähnlicher Form in einem anderen Prüfungsverfahren vorgelegt. Ich habe früher, außer den mit dem Zulassungsgesuch urkundlichen Graden, keine weiteren akademischen Grade erworben und zu erwerben gesucht. Würzburg, Lars Hofmann Content SUMMARY ................................................................................................................ IV ZUSAMMENFASSUNG ............................................................................................. V 1. INTRODUCTION ................................................................................................. 1 1.1. Molecular basics of cancer .......................................................................................... 1 1.2. Early research on tumorigenesis ................................................................................. 3 1.3. Developing -

A Mutation in Histone H2B Represents a New Class of Oncogenic Driver
Author Manuscript Published OnlineFirst on July 23, 2019; DOI: 10.1158/2159-8290.CD-19-0393 Author manuscripts have been peer reviewed and accepted for publication but have not yet been edited. A Mutation in Histone H2B Represents A New Class Of Oncogenic Driver Richard L. Bennett1, Aditya Bele1, Eliza C. Small2, Christine M. Will2, Behnam Nabet3, Jon A. Oyer2, Xiaoxiao Huang1,9, Rajarshi P. Ghosh4, Adrian T. Grzybowski5, Tao Yu6, Qiao Zhang7, Alberto Riva8, Tanmay P. Lele7, George C. Schatz9, Neil L. Kelleher9 Alexander J. Ruthenburg5, Jan Liphardt4 and Jonathan D. Licht1 * 1 Division of Hematology/Oncology, University of Florida Health Cancer Center, Gainesville, FL 2 Division of Hematology/Oncology, Northwestern University 3 Department of Cancer Biology, Dana Farber Cancer Institute and Department of Biological Chemistry and Molecular Pharmacology, Harvard Medical School 4 Department of Bioengineering, Stanford University 5 Department of Molecular Genetics and Cell Biology, The University of Chicago 6 Department of Chemistry, Tennessee Technological University 7 Department of Chemical Engineering, University of Florida 8 Bioinformatics Core, Interdisciplinary Center for Biotechnology Research, University of Florida 9 Department of Chemistry, Northwestern University, Evanston IL 60208 Running title: Histone mutations in cancer *Corresponding Author: Jonathan D. Licht, MD The University of Florida Health Cancer Center Cancer and Genetics Research Complex, Suite 145 2033 Mowry Road Gainesville, FL 32610 352-273-8143 [email protected] Disclosures: The authors have no conflicts of interest to declare Downloaded from cancerdiscovery.aacrjournals.org on September 27, 2021. © 2019 American Association for Cancer Research. Author Manuscript Published OnlineFirst on July 23, 2019; DOI: 10.1158/2159-8290.CD-19-0393 Author manuscripts have been peer reviewed and accepted for publication but have not yet been edited. -

A Mutation in Histone H2B Represents a New Class of Oncogenic Driver
Published OnlineFirst July 23, 2019; DOI: 10.1158/2159-8290.CD-19-0393 RESEARCH ARTICLE A Mutation in Histone H2B Represents a New Class of Oncogenic Driver Richard L. Bennett1, Aditya Bele1, Eliza C. Small2, Christine M. Will2, Behnam Nabet3, Jon A. Oyer2, Xiaoxiao Huang1,4, Rajarshi P. Ghosh5, Adrian T. Grzybowski6, Tao Yu7, Qiao Zhang8, Alberto Riva9, Tanmay P. Lele8, George C. Schatz4, Neil L. Kelleher4, Alexander J. Ruthenburg6, Jan Liphardt5, and Jonathan D. Licht1 Downloaded from cancerdiscovery.aacrjournals.org on September 30, 2021. © 2019 American Association for Cancer Research. Published OnlineFirst July 23, 2019; DOI: 10.1158/2159-8290.CD-19-0393 ABSTRACT By examination of the cancer genomics database, we identified a new set of mutations in core histones that frequently recur in cancer patient samples and are predicted to disrupt nucleosome stability. In support of this idea, we characterized a glutamate to lysine mutation of histone H2B at amino acid 76 (H2B-E76K), found particularly in bladder and head and neck cancers, that disrupts the interaction between H2B and H4. Although H2B-E76K forms dimers with H2A, it does not form stable histone octamers with H3 and H4 in vitro, and when recon- stituted with DNA forms unstable nucleosomes with increased sensitivity to nuclease. Expression of the equivalent H2B mutant in yeast restricted growth at high temperature and led to defective nucleosome-mediated gene repression. Significantly, H2B-E76K expression in the normal mammary epithelial cell line MCF10A increased cellular proliferation, cooperated with mutant PIK3CA to pro- mote colony formation, and caused a significant drift in gene expression and fundamental changes in chromatin accessibility, particularly at gene regulatory elements. -

The Human Canonical Core Histone Catalogue David Miguel Susano Pinto*, Andrew Flaus*,†
bioRxiv preprint doi: https://doi.org/10.1101/720235; this version posted July 30, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. The Human Canonical Core Histone Catalogue David Miguel Susano Pinto*, Andrew Flaus*,† Abstract Core histone proteins H2A, H2B, H3, and H4 are encoded by a large family of genes dis- tributed across the human genome. Canonical core histones contribute the majority of proteins to bulk chromatin packaging, and are encoded in 4 clusters by 65 coding genes comprising 17 for H2A, 18 for H2B, 15 for H3, and 15 for H4, along with at least 17 total pseudogenes. The canonical core histone genes display coding variation that gives rise to 11 H2A, 15 H2B, 4 H3, and 2 H4 unique protein isoforms. Although histone proteins are highly conserved overall, these isoforms represent a surprising and seldom recognised variation with amino acid identity as low as 77 % between canonical histone proteins of the same type. The gene sequence and protein isoform diversity also exceeds com- monly used subtype designations such as H2A.1 and H3.1, and exists in parallel with the well-known specialisation of variant histone proteins. RNA sequencing of histone transcripts shows evidence for differential expression of histone genes but the functional significance of this variation has not yet been investigated. To assist understanding of the implications of histone gene and protein diversity we have catalogued the entire human canonical core histone gene and protein complement. -

Epigenetic Regulation of Replication-Dependent Histone Mrna 3’ End Processing
Epigenetic Regulation of Replication-Dependent Histone mRNA 3’ End Processing Dissertation for the award of the degree “Doctor rerum naturalium (Dr. rer. nat.)” Division of Mathematics and Natural Sciences of the Georg-August-Universität Göttingen submitted by Judith Pirngruber born in Oldenburg, Germany Göttingen, 2010 Thesis Supervisor: Prof. Dr. Steven A. Johnsen Doctoral Committee: Prof. Dr. Steven A. Johnsen (1 st Referee) Molecular Oncology, University of Göttingen Medical School, Göttingen Prof. Dr. Heidi Hahn (2 nd Referee) Molecular Developmental Genetics, University of Göttingen Medical School, Göttingen Prof. Dr. Holger Reichardt Cellular and Molecular Immunology, University of Göttingen Medical School, Göttingen Date of the oral examination: 28 th April 2010 Affidavit I hereby declare that the PhD thesis entitled “Epigenetic Regulation of Replication- Dependent Histone mRNA 3’ End Processing” has been written independently and with no other sources and aids than quoted. ____________________________________ Judith Pirngruber March, 2010 Göttingen, Germany Für Opa Bruno „Opa, ich denk’ an Dich, wenn ich das Gänseliesel hochkletter’.“ Table of contents Table of contents List of Abbreviations ...........................................................................................I List of Figures ..................................................................................................... V List of Tables ...................................................................................................VII Abstract............................................................................................................VIII -

Targeting the DEK Oncogene in Head and Neck Squamous Cell Carcinoma: Functional and Transcriptional Consequences
Targeting the DEK oncogene in head and neck squamous cell carcinoma: functional and transcriptional consequences A dissertation submitted to the Graduate School of the University of Cincinnati in partial fulfillment of the requirements to the degree of Doctor of Philosophy (Ph.D.) in the Department of Cancer and Cell Biology of the College of Medicine March 2015 by Allie Kate Adams B.S. The Ohio State University, 2009 Dissertation Committee: Susanne I. Wells, Ph.D. (Chair) Keith A. Casper, M.D. Peter J. Stambrook, Ph.D. Ronald R. Waclaw, Ph.D. Susan E. Waltz, Ph.D. Kathryn A. Wikenheiser-Brokamp, M.D., Ph.D. Abstract Head and neck squamous cell carcinoma (HNSCC) is one of the most common malignancies worldwide with over 50,000 new cases in the United States each year. For many years tobacco and alcohol use were the main etiological factors; however, it is now widely accepted that human papillomavirus (HPV) infection accounts for at least one-quarter of all HNSCCs. HPV+ and HPV- HNSCCs are studied as separate diseases as their prognosis, treatment, and molecular signatures are distinct. Five-year survival rates of HNSCC hover around 40-50%, and novel therapeutic targets and biomarkers are necessary to improve patient outcomes. Here, we investigate the DEK oncogene and its function in regulating HNSCC development and signaling. DEK is overexpressed in many cancer types, with roles in molecular processes such as transcription, DNA repair, and replication, as well as phenotypes such as apoptosis, senescence, and proliferation. DEK had never been previously studied in this tumor type; therefore, our studies began with clinical specimens to examine DEK expression patterns in primary HNSCC tissue.