CISC 3310 – Homework 2, Chapter 3 Answers 1. A. Yz + Z(Xy)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ISO Basic Latin Alphabet
ISO basic Latin alphabet The ISO basic Latin alphabet is a Latin-script alphabet and consists of two sets of 26 letters, codified in[1] various national and international standards and used widely in international communication. The two sets contain the following 26 letters each:[1][2] ISO basic Latin alphabet Uppercase Latin A B C D E F G H I J K L M N O P Q R S T U V W X Y Z alphabet Lowercase Latin a b c d e f g h i j k l m n o p q r s t u v w x y z alphabet Contents History Terminology Name for Unicode block that contains all letters Names for the two subsets Names for the letters Timeline for encoding standards Timeline for widely used computer codes supporting the alphabet Representation Usage Alphabets containing the same set of letters Column numbering See also References History By the 1960s it became apparent to thecomputer and telecommunications industries in the First World that a non-proprietary method of encoding characters was needed. The International Organization for Standardization (ISO) encapsulated the Latin script in their (ISO/IEC 646) 7-bit character-encoding standard. To achieve widespread acceptance, this encapsulation was based on popular usage. The standard was based on the already published American Standard Code for Information Interchange, better known as ASCII, which included in the character set the 26 × 2 letters of the English alphabet. Later standards issued by the ISO, for example ISO/IEC 8859 (8-bit character encoding) and ISO/IEC 10646 (Unicode Latin), have continued to define the 26 × 2 letters of the English alphabet as the basic Latin script with extensions to handle other letters in other languages.[1] Terminology Name for Unicode block that contains all letters The Unicode block that contains the alphabet is called "C0 Controls and Basic Latin". -
![B1. the Generating Functional Z[J]](https://docslib.b-cdn.net/cover/0425/b1-the-generating-functional-z-j-230425.webp)
B1. the Generating Functional Z[J]
B1. The generating functional Z[J] The generating functional Z[J] is a key object in quantum field theory - as we shall see it reduces in ordinary quantum mechanics to a limiting form of the 1-particle propagator G(x; x0jJ) when the particle is under thje influence of an external field J(t). However, before beginning, it is useful to look at another closely related object, viz., the generating functional Z¯(J) in ordinary probability theory. Recall that for a simple random variable φ, we can assign a probability distribution P (φ), so that the expectation value of any variable A(φ) that depends on φ is given by Z hAi = dφP (φ)A(φ); (1) where we have assumed the normalization condition Z dφP (φ) = 1: (2) Now let us consider the generating functional Z¯(J) defined by Z Z¯(J) = dφP (φ)eφ: (3) From this definition, it immediately follows that the "n-th moment" of the probability dis- tribution P (φ) is Z @nZ¯(J) g = hφni = dφP (φ)φn = j ; (4) n @J n J=0 and that we can expand Z¯(J) as 1 X J n Z Z¯(J) = dφP (φ)φn n! n=0 1 = g J n; (5) n! n ¯ so that Z(J) acts as a "generator" for the infinite sequence of moments gn of the probability distribution P (φ). For future reference it is also useful to recall how one may also expand the logarithm of Z¯(J); we write, Z¯(J) = exp[W¯ (J)] Z W¯ (J) = ln Z¯(J) = ln dφP (φ)eφ: (6) 1 Now suppose we make a power series expansion of W¯ (J), i.e., 1 X 1 W¯ (J) = C J n; (7) n! n n=0 where the Cn, known as "cumulants", are just @nW¯ (J) C = j : (8) n @J n J=0 The relationship between the cumulants Cn and moments gn is easily found. -

Percent R, X and Z Based on Transformer KVA
SHORT CIRCUIT FAULT CALCULATIONS Short circuit fault calculations as required to be performed on all electrical service entrances by National Electrical Code 110-9, 110-10. These calculations are made to assure that the service equipment will clear a fault in case of short circuit. To perform the fault calculations the following information must be obtained: 1. Available Power Company Short circuit KVA at transformer primary : Contact Power Company, may also be given in terms of R + jX. 2. Length of service drop from transformer to building, Type and size of conductor, ie., 250 MCM, aluminum. 3. Impedance of transformer, KVA size. A. %R = Percent Resistance B. %X = Percent Reactance C. %Z = Percent Impedance D. KVA = Kilovoltamp size of transformer. ( Obtain for each transformer if in Bank of 2 or 3) 4. If service entrance consists of several different sizes of conductors, each must be adjusted by (Ohms for 1 conductor) (Number of conductors) This must be done for R and X Three Phase Systems Wye Systems: 120/208V 3∅, 4 wire 277/480V 3∅ 4 wire Delta Systems: 120/240V 3∅, 4 wire 240V 3∅, 3 wire 480 V 3∅, 3 wire Single Phase Systems: Voltage 120/240V 1∅, 3 wire. Separate line to line and line to neutral calculations must be done for single phase systems. Voltage in equations (KV) is the secondary transformer voltage, line to line. Base KVA is 10,000 in all examples. Only those components actually in the system have to be included, each component must have an X and an R value. Neutral size is assumed to be the same size as the phase conductors. -

The Deloitte Global 2021 Millennial and Gen Z Survey
A call for accountability and action T HE D ELO IT T E GLOB A L 2021 M IL LE N N IA L AND GEN Z SUR V E Y 1 Contents 01 06 11 INTRODUCTION CHAPTER 1 CHAPTER 2 Impact of the COVID-19 The effect on mental health pandemic on daily life 15 27 33 CHAPTER 3 CHAPTER 4 CONCLUSION How the past year influenced Driven to act millennials’ and Gen Zs’ world outlooks 2 Introduction Millennials and Generation Zs came of age at the same time that online platforms and social media gave them the ability and power to share their opinions, influence distant people and institutions, and question authority in new ways. These forces have shaped their worldviews, values, and behaviors. Digital natives’ ability to connect, convene, and create disruption via their keyboards and smartphones has had global impact. From #MeToo to Black Lives Matter, from convening marches on climate change to the Arab Spring, from demanding eco-friendly products to challenging stakeholder capitalism, these generations are compelling real change in society and business. The lockdowns resulting from the COVID-19 pandemic curtailed millennials’ and Gen Zs’ activities but not their drive or their desire to be heard. In fact, the 2021 Deloitte Global Millennial Survey suggests that the pandemic, extreme climate events, and a charged sociopolitical atmosphere may have reinforced people’s passions and given them oxygen. 01 Urging accountability Last year’s report1 reflected the results of two Of course, that’s a generality—no group of people is surveys—one taken just before the pandemic and a homogeneous. -

Alphabets, Letters and Diacritics in European Languages (As They Appear in Geography)
1 Vigleik Leira (Norway): [email protected] Alphabets, Letters and Diacritics in European Languages (as they appear in Geography) To the best of my knowledge English seems to be the only language which makes use of a "clean" Latin alphabet, i.d. there is no use of diacritics or special letters of any kind. All the other languages based on Latin letters employ, to a larger or lesser degree, some diacritics and/or some special letters. The survey below is purely literal. It has nothing to say on the pronunciation of the different letters. Information on the phonetic/phonemic values of the graphic entities must be sought elsewhere, in language specific descriptions. The 26 letters a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z may be considered the standard European alphabet. In this article the word diacritic is used with this meaning: any sign placed above, through or below a standard letter (among the 26 given above); disregarding the cases where the resulting letter (e.g. å in Norwegian) is considered an ordinary letter in the alphabet of the language where it is used. Albanian The alphabet (36 letters): a, b, c, ç, d, dh, e, ë, f, g, gj, h, i, j, k, l, ll, m, n, nj, o, p, q, r, rr, s, sh, t, th, u, v, x, xh, y, z, zh. Missing standard letter: w. Letters with diacritics: ç, ë. Sequences treated as one letter: dh, gj, ll, rr, sh, th, xh, zh. -

Proposal for Generation Panel for Latin Script Label Generation Ruleset for the Root Zone
Generation Panel for Latin Script Label Generation Ruleset for the Root Zone Proposal for Generation Panel for Latin Script Label Generation Ruleset for the Root Zone Table of Contents 1. General Information 2 1.1 Use of Latin Script characters in domain names 3 1.2 Target Script for the Proposed Generation Panel 4 1.2.1 Diacritics 5 1.3 Countries with significant user communities using Latin script 6 2. Proposed Initial Composition of the Panel and Relationship with Past Work or Working Groups 7 3. Work Plan 13 3.1 Suggested Timeline with Significant Milestones 13 3.2 Sources for funding travel and logistics 16 3.3 Need for ICANN provided advisors 17 4. References 17 1 Generation Panel for Latin Script Label Generation Ruleset for the Root Zone 1. General Information The Latin script1 or Roman script is a major writing system of the world today, and the most widely used in terms of number of languages and number of speakers, with circa 70% of the world’s readers and writers making use of this script2 (Wikipedia). Historically, it is derived from the Greek alphabet, as is the Cyrillic script. The Greek alphabet is in turn derived from the Phoenician alphabet which dates to the mid-11th century BC and is itself based on older scripts. This explains why Latin, Cyrillic and Greek share some letters, which may become relevant to the ruleset in the form of cross-script variants. The Latin alphabet itself originated in Italy in the 7th Century BC. The original alphabet contained 21 upper case only letters: A, B, C, D, E, F, Z, H, I, K, L, M, N, O, P, Q, R, S, T, V and X. -

Z-R Relationships 1 Learning Objectives 2 Introduction
Z-R Relationships Weather Radar Applications ECE / METR 5683 Spring 2008 Prof. Chilson 1 Learning Objectives The following are the learning objectives for this assignment: • Learn how NEXRAD data stored in the NIDS format can be converted to the popular netCDF data format. • Familiarize yourself with the netCDF data format and how it is manipulated. • Discover how netCDF data can be imported into MATLAB • Explore and understand the errors and benefits associated with single-parameter rainfall estimation. 2 Introduction Remote measurement of the rainfall rate R is of considerable practical interest. For many years meteorologists have attempted to find a useful relation between the radar reflectivity factor Z and the rainfall rate R. Unfortunately, there is no single relation that can satisfy all meteorological phenomena - Battan (1973) lists no fewer than 69 separate Z − R relationships that have been proposed by various investigators. More importantly, observed drop size distributions, of which both Z and R are functions, can be expressed in an indefinite number of parameters. Single- parameter measurement of rainfall constrains the DSD to one free parameter, which may vary strongly in both space and time, and as a result most Z − R relationships are expressed as a power law: Z = aRb (1) in which Z is expressed in linear units (mm6 m−3) and R is in mm hr−1. Your task is to investigate the appropriateness (or lack thereof) of various Z − R relations which are implemented for the WSR-88D network. You will also begin to familiarize yourself with the netCDF data format, which is widely used in scientific applications because of its ability to embed metadata into the file itself, and its ease of integration with MATLAB. -

ALPHABET and PRONUNCIATION Old English (OE) Scribes Used Two
OLD ENGLISH (OE) ALPHABET AND PRONUNCIATION Old English (OE) scribes used two kinds of letters: the runes and the letters of the Latin alphabet. The bulk of the OE material — OE manuscripts — is written in the Latin script. The use of Latin letters in English differed in some points from their use in Latin, for the scribes made certain modifications and additions in order to indicate OE sounds which did not exist in Latin. Depending of the size and shape of the letters modern philologists distinguish between several scripts which superseded one another during the Middle Ages. Throughout the Roman period and in the Early Middle Ages capitals (scriptura catipalis) and uncial (scriptura uncialis) letters were used; in the 5th—7th c. the uncial became smaller and the cursive script began to replace it in everyday life, while in book-making a still smaller script, minuscule (scriptura minusculis), was employed. The variety used in Britain is known as the Irish, or insular minuscule. Insular minuscule script differed from the continental minuscule in the shape of some letters, namely d, f, g. From these letters only one is used in modern publications of OE texts as a distinctive feature of the OE alphabet – the letter Z (corresponding to the continental g). In the OE variety of the Latin alphabet i and j were not distinguished; nor were u and v; the letters k, q, x and w were not used until many years later. A new letter was devised by putting a stroke through d or ð, to indicate the voiceless and the voiced interdental [θ] and [ð]. -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6 -
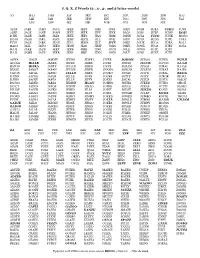
J, Q, X, Z Words (2-, 3-, 4-, and 5-Letter Words)
J, Q, X, Z Words (2-, 3-, 4-, and 5-letter words) JO HAJ JAM JAY JEU JIG JOE JOW JUN RAJ JAB JAR JEE JEW JIN JOG JOY JUS TAJ JAG JAW JET JIB JOB JOT JUG JUT AJAR JABS JAMS JAVA JEES JEST JIBS JINS JOEY JOSH JUBA JUKU JUTS AJEE JACK JANE JAWS JEEZ JETE JIFF JINX JOGS JOSS JUBE JUMP KOJI DJIN JADE JAPE JAYS JEFE JETS JIGS JISM JOHN JOTA JUCO JUNK MOJO DOJO JAGG JARL JAZZ JEHU JEUX JILL JIVE JOIN JOTS JUDO JUPE PUJA FUJI JAGS JARS JEAN JELL JEWS JILT JIVY JOKE JOUK JUGA JURA RAJA HADJ JAIL JATO JEED JEON JIAO JIMP JOBS JOKY JOWL JUGS JURY SOJA HAJI JAKE JAUK JEEP JERK JIBB JINK JOCK JOLE JOWS JUJU JUST HAJJ JAMB JAUP JEER JESS JIBE JINN JOES JOLT JOYS JUKE JUTE AJIVA HAJJI JAMMY JEERS JEWEL JIVER JOMON JUDOS JUPES PUNJI AJUGA HIJAB JANES JEFES JIBBS JIVES JONES JUCOS JUPON RAJAH BANJO HIJRA JANTY JEHAD JIBED JIVEY JORAM JUGAL JURAL RAJAS BIJOU JABOT JAPAN JEHUS JIBER JNANA JORUM JUGUM JURAT RAJES CAJON JACAL JAPED JELLO JIBES JOCKO JOTAS JUICE JUREL REJIG DJINN JACKS JAPER JELLS JIFFS JOCKS JOTTY JUICY JUROR RIOJA DJINS JACKY JAPES JELLY JIFFY JOEYS JOUAL JUJUS JUSTS SAJOU DOJOS JADED JARLS JEMMY JIGGY JOHNS JOUKS JUKED JUTES SHOJI EJECT JADES JATOS JENNY JIHAD JOINS JOULE JUKES JUTTY SLOJD ENJOY JAGER JAUKS JERID JILLS JOINT JOUST JUKUS KANJI SOJAS FJELD JAGGS JAUNT JERKS JILTS JOIST JOWAR JULEP KOJIS TAJES FJORD JAGGY JAUPS JERKY JIMMY JOKED JOWED JUMBO KOPJE THUJA FUJIS JAGRA JAVAS JERRY JIMPY JOKER JOWLS JUMPS MAJOR UNJAM GADJE JAILS JAWAN JESSE JINGO JOKES JOWLY JUMPY MOJOS GADJO JAKES JAWED JESTS JINKS JOKEY JOYED JUNCO MUJIK GANJA -

The Alphabets of the Bible: Latin and English John Carder
274 The Testimony, July 2004 The alphabets of the Bible: Latin and English John Carder N A PREVIOUS article we looked at the trans- • The first major change is in the third letter, formation of the Hebrew aleph-bet into the originally the Hebrew gimal and then the IGreek alphabet (Apr. 2004, p. 130). In turn Greek gamma. The Etruscan language had no the Greek was used as a basis for writing down G sound, so they changed that place in the many other languages. Always the spoken lan- alphabet to a K sound. guage came first and writing later. We complete The Greek symbol was rotated slightly our look at the alphabets of the Bible by briefly by the Romans and then rounded, like the B considering Latin, then our English alphabet in and D symbols. It became the Latin letter C which we normally read the Bible. and, incidentally, created the confusion which still exists in English. Our C can have a hard From Greek to Latin ‘k’ sound, as in ‘cold’, or a soft sound, as in The Greek alphabet spread to the Romans from ‘city’. the Greek colonies on the coast of Italy, espe- • In the sixth place, either the Etruscans or the cially Naples and district. (Naples, ‘Napoli’ in Romans revived the old Greek symbol di- Italian, is from the Greek ‘Neapolis’, meaning gamma, which had been dropped as a letter ‘new city’). There is evidence that the Etruscans but retained as a numeral. They gave it an ‘f’ were also involved in an intermediate stage. -

Continuous Stroke Printing
Children’s Rehabilitation Services CONTINUOUS STROKE PRINTING The more times a beginning writer has to lift a pencil, the harder it becomes to make a legible letter. Every pencil lift creates another opportunity to make a mistake. Fewer strokes means fewer steps to remember in forming each letter and decreases directionality confusion. It also increases the chances the student will develop the correct “motor memory” for the letter formation. The development of motor “memories” for the patterns used in printing is what helps the student’s printing to become fast and automatic, without sacrificing legibility. Continuous stroke printing may also help eliminate letter reversals. As the student is not lifting his/her pencil, there is less opportunity for confusion around which side of the “ball” to place the “stick” on (e.g., ‘b’ vs. ‘d’). Likewise, as the student does not have to pause and think about where to place each connecting stroke, the speed and flow of printing often improves. Which Letters Are Non-Lifting? Uppercase lifting letters include: A, E, F, H, I, J, K, Q, T, X, Y Uppercase non-lifting letters include: B, C, D, G, L, M, N, O, P, R, S, U, V, W, Z Lowercase lifting letters include: f, i, j, k, t, x, y Lowercase non-lifting letters include: a, b, c, d, e, g, h, l, m, n, o, p, q, r, s, u, v, w, z Please see the following page for a stroke directionality chart. Tips to Make Teaching Easier Continuous stroke Encourage the student to begin all uppercase letters from printing helps: the top and lowercase letters from the middle or top, as .