Anton Nikolaev and Nick Glaser
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

London Cries & Public Edifices
>m ^Victoria %S COLLECTION OF VICTORIAN BOOKS AT BRIGHAM YOUNG UNIVERSITY Victorian 914.21 L533L 1851 3 1197 22902 7856 A,AA A ,' s 7rs a' lEn! 31113 rf K* I 'r X ^i W\lf' ^ J.eU ^W^3 mmm y<i mm§ ft Hftij •: :ii v^ ANDON431IE GRMMT am &U<2<3Slg,SORS TT© KEWBgRy A.KfD HARRIS *S) A SORNER OF1 3-AjWTT PAUL'S 6HUR6H-TARD, LONDON UPB Tfffi TOWfiR QT LONDON. A POTS & KETTLES TO MERaBELLOWiS TO MEND. POTS AND KETTLES TO MEND !—COPPER OR BRASS TO MEND ! The Tinker is swinging his fire-pot to make it burn, having placed his soldering-iron in it, and is proceeding to some corner or post, there to repair the saucepan he carries.—We commence with the most in- teresting edifice in our capital, THE TOWER OF LONDON; the fortress, the palace, and prison, in which so many events, connected with the history of our country, have transpired. The building with four towers in the centre is said to have been erected by William the Conqueror, and is the oldest part of the fortress. The small bell- tower in the front of our picture is that of the church of St. Peter's, (the tower being a parish itself,) on the Tower Green, erected in the reign of Edward I. Our view is taken from Tower Hill, near which was the scaffold on which so many have fallen. To the left of the picture stood the grand storehouse of William III., destroyed by fire, Nov. 1841. The Regalia is deposited here, and exhibited to the public, as is also the Horse Armoury. -

The Construction of Northumberland House and the Patronage of Its Original Builder, Lord Henry Howard, 1603–14
The Antiquaries Journal, 90, 2010,pp1 of 60 r The Society of Antiquaries of London, 2010 doi:10.1017⁄s0003581510000016 THE CONSTRUCTION OF NORTHUMBERLAND HOUSE AND THE PATRONAGE OF ITS ORIGINAL BUILDER, LORD HENRY HOWARD, 1603–14 Manolo Guerci Manolo Guerci, Kent School of Architecture, University of Kent, Marlowe Building, Canterbury CT27NR, UK. E-mail: [email protected] This paper affords a complete analysis of the construction of the original Northampton (later Northumberland) House in the Strand (demolished in 1874), which has never been fully investigated. It begins with an examination of the little-known architectural patronage of its builder, Lord Henry Howard, 1st Earl of Northampton from 1603, one of the most interesting figures of the early Stuart era. With reference to the building of the contemporary Salisbury House by Sir Robert Cecil, 1st Earl of Salisbury, the only other Strand palace to be built in the early seventeenth century, textual and visual evidence are closely investigated. A rediscovered eleva- tional drawing of the original front of Northampton House is also discussed. By associating it with other sources, such as the first inventory of the house (transcribed in the Appendix), the inside and outside of Northampton House as Henry Howard left it in 1614 are re-configured for the first time. Northumberland House was the greatest representative of the old aristocratic mansions on the Strand – the almost uninterrupted series of waterfront palaces and large gardens that stretched from Westminster to the City of London, the political and economic centres of the country, respectively. Northumberland House was also the only one to have survived into the age of photography. -

Rapier House, Turnmill Street, London, EC I I'. L.Reruti,E
REDHEADS ADVERTISING LTD. SOMMERVILLE & MILNE 21 Eldon LTD. Square, Newcastle -on -Tyne, 1. 216 Bothwell Street, Glasgow, C.2. Scotland. REX PUBLICITY SERVICE LTD. Director S Manager: J. Bruce Omand. 131-134 New Bond Street, London, W.I. THE W. J. SOUTHCOMBE ADVERTISING Telephone: 'Mayfair 7571. AGENCY LTD. T.Y. Executive: R. C. Granger. 167 Strand, oLndon, W.C.2. Telephone: RIPLEY, PRESTON & CO. LTD. Temple Bar 4273. Ludgate House, 107-111 Fleet Street, Lon- SPOTTISWOODE ADVERTISING LTD. don, E.C.4. Telephone: Central 8672. 34 Brook Street, London, W.1. Telephone: T.V. Executive: Walter A. Clare. Hyde Park 1221 MAX RITSON & PARTNERS LTD. T.I Lxecutive: W. J. Barter. 33 Henrietta Street, London, W.C.2. Tele- HENRY SQUIRE & CO. LTD. phone: Temple Bar 3861. Canada House, Norfolk Street, London, W.C. T.V. Executive: Roy G. Clark. 2. Telephone: Temple Bar 9093. ROE TELEVISION LTD. I I'. L.reruti,e: S. Windridge. (F. John Roe Ltd.) 20 St. Ann's Square, STEELE'S ADVERTISING SERVICE LTD. Manchester & 73 Grosvenor Street, London, 34 Brook Street, London, W.1. W.1. Telephone: Grosvenor 8228. T.Y. Executives: Graham Roe, Derek J. Roe. STEPHENS ADVERTISING SERVICE LTD. Clarendon House, 11-12 Clifford Street, ROLES & PARKER LTD. New Bond Street, London, W.1. Telephone: Rapier House, Turnmill Street, London, E.C. Hyde Park 1. 1641. Telephone: Clerkenwell 0545. Executive: E. W. R. T.V. Executive: H. T. Parker. Galley. STRAND PUBLICITY LTD. G. S. ROYDS LTD. 10 Stanhope Row, London, W.1. Telephone: 160 Piccadilly, London, W1.. Telephone: Grosvenor 1352. Hyde Park 8238. -

Construction “Closing Date and Time”)
UNCLASSIFIED A2. TITLE A1. DEPARTMENTAL REPRESENTATIVE London Chancery Consolidation Project, United Kingdom A3. SOLICITATION NUMBER A4.PROJECT NUMBER A5.DATE Ms. Jane Bird ARD-LDN-CONST-13094/A B-LDN-135 October 20th, 2013 Project Director (Chancery Consolidation Project) A6. RFPR DOCUMENTS High Commission of Canada 1. Request for Pre-qualification Responses (“RFPR”) title page 2. Submission Requirements and Evaluations (Section “I” – “SR” provisions) Macdonald House, 1 Grosvenor Square 3. General Instructions (Section “II” – “GI” provisions) London, United Kingdom 4. Questionnaire (Section “III” – “Q” provisions) In the event of discrepancies, inconsistencies or ambiguities of the wording of these Telephone : +44 (0) 207 004 6052 documents, the document that appears first on the above list shall prevail. E-mail: [email protected] A7. RESPONSE DELIVERY In order for the Response to be valid, it must be received no later than 14:00 (2:00 pm) EST on November 15th 2013 (Ottawa, Ontario, Canada) (“Closing Date” or Construction “Closing Date and Time”). Best Value Evaluation The Response is only to be emailed to the following address; [email protected] Solicitation#: ARD-LDN-CONST-13094/A Respondents should ensure that their name, address, Closing Date, and solicitation PHASE 1 – Pre-qualification number is clearly marked on their email. Failure to comply may result in the Response of a 2-Phase Procurement being declared non-compliant and rejected from further consideration. Process A8. RESPONSE Please note SR2. Respondents must meet mandatory requirements and must obtain a for minimum rating of ‘100’. Up to six (6) Respondents with the highest score will be invited to advance to Phase 2 of the procurement process. -

An Examination of the Artist's Depiction of the City and Its Gardens 1745-1756
Durham E-Theses Public and private space in Canaletto's London: An examination of the artist's depiction of the city and its gardens 1745-1756 Hudson, Ferne Olivia How to cite: Hudson, Ferne Olivia (2000) Public and private space in Canaletto's London: An examination of the artist's depiction of the city and its gardens 1745-1756, Durham theses, Durham University. Available at Durham E-Theses Online: http://etheses.dur.ac.uk/4252/ Use policy The full-text may be used and/or reproduced, and given to third parties in any format or medium, without prior permission or charge, for personal research or study, educational, or not-for-prot purposes provided that: • a full bibliographic reference is made to the original source • a link is made to the metadata record in Durham E-Theses • the full-text is not changed in any way The full-text must not be sold in any format or medium without the formal permission of the copyright holders. Please consult the full Durham E-Theses policy for further details. Academic Support Oce, Durham University, University Oce, Old Elvet, Durham DH1 3HP e-mail: [email protected] Tel: +44 0191 334 6107 http://etheses.dur.ac.uk 2 Public and Private Space in Canaletto's London. An Examination of the Artist's Depiction of the City and its Gardens 1745-1756. The copyright of this thesis rests with the author. No quotation from it should be published in any form, including Electronic and the Internet, without the author's prior written consent. -

The Heart of the Empire
The heart of the Empire A self-guided walk along the Strand ww.discoverin w gbrita in.o the stories of our rg lands discovered th cape rough w s alks 2 Contents Introduction 4 Route map 5 Practical information 6 Commentary 8 Credits 30 © The Royal Geographical Society with the Institute of British Geographers, London, 2015 Discovering Britain is a project of the Royal Geographical Society (with IBG) The digital and print maps used for Discovering Britain are licensed to the RGS-IBG from Ordnance Survey Cover image: Detail of South Africa House © Mike jackson RGS-IBG Discovering Britain 3 The heart of the Empire Discover London’s Strand and its imperial connections At its height, Britain’s Empire covered one-quarter of the Earth’s land area and one-third of the world’s population. It was the largest Empire in history. If the Empire’s beating heart was London, then The Strand was one of its major arteries. This mile- long street beside the River Thames was home to some of the Empire’s administrative, legal and commercial functions. The days of Empire are long gone but its legacy remains in the landscape. A walk down this modern London street is a fascinating journey through Britain’s imperial history. This walk was created in 2012 by Mike Jackson and Gary Gray, both Fellows of the Royal Geographical Society (with IBG). It was originally part of a series that explored how our towns and cities have been shaped for many centuries by some of the 206 participating nations in the 2012 Olympic and Paralympic Games. -
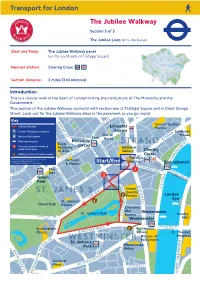
The Jubilee Walkway. Section 5 of 5
Transport for London. The Jubilee Walkway. Section 5 of 5. The Jubilee Loop (anti-clockwise). Start and finish: The Jubilee Walkway panel (on the south side of Trafalgar Square). Nearest station: Charing Cross . Section distance: 2 miles (3 kilometres). Introduction. This is a circular walk in the heart of London linking the institutions of The Monarchy and the Government. This section of the Jubilee Walkway connects with section one at Trafalgar Square and at Great George Street. Look out for the Jubilee Walkway discs in the pavement as you go round. Directions. This walk starts from Trafalgar Square. Did you know? Trafalgar Square was laid out in 1840 by Sir Charles Barry, architect of the new Houses of Parliament. The square, which is now a 'World Square', is a place for national rejoicing, celebrations and demonstrations. It is dominated by Nelson's Column with the 18-foot statue of Lord Nelson standing on top of the 171-foot column. It was erected in honour of his victory at Trafalgar. With Trafalgar Square behind you and keeping Canada House on the right, cross Cockspur Street and keep right. Go around the corner, passing the Ugandan High Commission to enter The Mall under the large stone Admiralty Arch - go through the right arch. Keep on the right-hand side of the broad avenue that is The Mall. Did you know? Admiralty Arch is the gateway between The Mall, which extends southwest, and Trafalgar Square to the northeast. The Mall was laid out as an avenue between 1660-1662 as part of Charles II's scheme for St James's Park. -

The Old War Office Building
MINISTRY OF DEFENCE The Old War Office Building A history The Old War Office Building …a building full of history Foreword by the Rt. Hon Geoff Hoon MP, Secretary of State for Defence The Old War Office Building has been a Whitehall landmark for nearly a century. No-one can fail to be impressed by its imposing Edwardian Baroque exterior and splendidly restored rooms and stairways. With the long-overdue modernisation of the MOD Main Building, Defence Ministers and other members of the Defence Council – the Department’s senior committee – have moved temporarily to the Old War Office. To mark the occasion I have asked for this short booklet, describing the history of the Old War Office Building, to be published. The booklet also includes a brief history of the site on which the building now stands, and of other historic MOD headquarters buildings in Central London. People know about the work that our Armed Forces do around the world as a force for good. Less well known is the work that we do to preserve our heritage and to look after the historic buildings that we occupy. I hope that this publication will help to raise awareness of that. The Old War Office Building has had a fascinating past, as you will see. People working within its walls played a key role in two World Wars and in the Cold War that followed. The building is full of history. Lawrence of Arabia once worked here. I am now occupying the office which Churchill, Lloyd-George and Profumo once had. -
![View Our Entertaining Brochure [PDF 6.6MB]](https://docslib.b-cdn.net/cover/9557/view-our-entertaining-brochure-pdf-6-6mb-1619557.webp)
View Our Entertaining Brochure [PDF 6.6MB]
YOUR EVENT AT THE NATIONAL GALLERY Phone: +44 20 7747 5931 · Email: [email protected] · Twitter: @NG_EventsLondon · Instagram: @ngevents We are one of the most visited galleries in the world. Located on Trafalgar Square, we have stunning views of Nelson’s Column, Westminster and beyond. Surround your guests with some of the world’s greatest paintings by artists such as Leonardo, Monet and Van Gogh. Our central location, magnificent architecture and spectacular spaces never fail to impress. 2 The Portico The Mosaic Central Hall Room 30 The Barry Annenberg Gallery A The Yves Saint The Wohl Room The National Café The National Terrace Rooms Court Laurent Room Dining Room East Wing East Wing East Wing East Wing East Wing East Wing North Wing North Wing West Wing East Wing Sainsbury Wing Page 4 Page 5 Page 6 Page 7 Page 8 Page 9 Page 10 Page 11 Page 12 Page 14 Page 15 3 THE PORTICO With unrivalled views overlooking Trafalgar Square, the Portico Terrace is our most impressive outdoor event space. Breakfast 100 · Reception 100 · Reception including foyer 250 · Dinner 60 Level 2 DID YOU KNOW … The relief above the Portico entrance shows two young women symbolising Europe and Asia. This relief was originally intended for John Nash’s Marble Arch. 4 · East Wing THE MOSAIC TERRACE Step inside the Gallery onto our historic mosaic floor, beautifully lit by a domed glass ceiling. This unique artwork by Boris Anrep combines an ancient technique with contemporary personalities of 1930’s Britain such as Greta Garbo and Virginia Woolf. -

Historical Portraits Book
HH Beechwood is proud to be The National Cemetery of Canada and a National Historic Site Life Celebrations ♦ Memorial Services ♦ Funerals ♦ Catered Receptions ♦ Cremations ♦ Urn & Casket Burials ♦ Monuments Beechwood operates on a not-for-profit basis and is not publicly funded. It is unique within the Ottawa community. In choosing Beechwood, many people take comfort in knowing that all funds are used for the maintenance, en- hancement and preservation of this National Historic Site. www.beechwoodottawa.ca 2017- v6 Published by Beechwood, Funeral, Cemetery & Cremation Services Ottawa, ON For all information requests please contact Beechwood, Funeral, Cemetery and Cremation Services 280 Beechwood Avenue, Ottawa ON K1L8A6 24 HOUR ASSISTANCE 613-741-9530 • Toll Free 866-990-9530 • FAX 613-741-8584 [email protected] The contents of this book may be used with the written permission of Beechwood, Funeral, Cemetery & Cremation Services www.beechwoodottawa.ca Owned by The Beechwood Cemetery Foundation and operated by The Beechwood Cemetery Company eechwood, established in 1873, is recognized as one of the most beautiful and historic cemeteries in Canada. It is the final resting place for over 75,000 Canadians from all walks of life, including im- portant politicians such as Governor General Ramon Hnatyshyn and Prime Minister Sir Robert Bor- den, Canadian Forces Veterans, War Dead, RCMP members and everyday Canadian heroes: our families and our loved ones. In late 1980s, Beechwood began producing a small booklet containing brief profiles for several dozen of the more significant and well-known individuals buried here. Since then, the cemetery has grown in national significance and importance, first by becoming the home of the National Military Cemetery of the Canadian Forces in 2001, being recognized as a National Historic Site in 2002 and finally by becoming the home of the RCMP National Memorial Cemetery in 2004. -

Northbank Book
STRANDS OF HISTORY Northbank Revealed Clive Aslet Strands of History Northbank Revealed by Clive Aslet First published in 2014 by Wild Research, 40 Great Smith Street, London SW1P 3BU www.wildsearch.org © Wild Research 2014 All rights reserved The Northbank BID West Wing, Somerset House, Strand, London WC2R 1LA www.thenorthbank.org ISBN 978-0-9576966-2-4 Printed in Poland by ? ‘Looking to Northumberland House, and turning your back upon Trafalgar Square, the Strand is perhaps the finest street in Europe, blending the architecture of many periods; and its river ways are a peculiar feature and rich with associations.’ Benjamin Disraeli, Tancred: or, The New Crusade, 1847 ‘I often shed tears in the motley Strand for fullness of joy at so much life... Have I not enough, without your mountains?’ Charles Lamb, turning down an invitation from William Wordsworth to visit him in the Lake District Contents Foreword 10 Chapter One: The River 14 Chapter Two: The Road 26 Chapter Three: Somerset House 40 Chapter Four: Trafalgar Square 50 Chapter Five: Structural Strand: Charing Cross Station and Victoria Embankment 58 Chapter Six: Serious Strand: The Law Courts 64 Chapter Seven: Playful Strand: Shopping, Hotels and Theatres 72 Chapter Eight: Crown Imperial: The Strand Improvement Scheme 82 Chapter Nine: Art Deco and Post War 94 Chapter Ten: The Future 100 Image Acknowledgements 108 Further Reading 110 About Wild Research 111 7 8 About the Author Acknowledgements Clive Aslet is an award-winning writer and Maecenas molestie eros at tempor malesuada. journalist, acknowledged as a leading authority Donec eu urna urna. -

The Architectural Transformation of Northumberland House Under the 7Th Duke of Somerset and the 1St Duke and Duchess of Northumberland, 1748–86
THE ARCHITECTURAL TRANSFORMATION OF NORTHUMBERLAND HOUSE UNDER THE 7TH DUKE OF SOMERSET AND THE 1ST DUKE AND DUCHESS OF NORTHUMBERLAND, 1748–86 Adriano Aymonino and Manolo Guerci Adriano Aymonino, Department of Art History and Heritage Studies, University of Buckingham, Yeomanry House, Hunter Street, Buckingham MK18 1EG, UK. Email: adriano.aymonino@ buckingham.ac.uk Manolo Guerci, Kent School of Architecture, University of Kent, Marlowe Building, Canterbury CT27NR, UK. Email: [email protected] The material contained in this file consists of two appendices that should be read in con- junction with the paper published by Adriano Aymonino and Manolo Guerci in volume 96 of the Antiquaries Journal (2016) under the title ‘The architectural transformation of Northumberland House under the 7th Duke of Somerset and the 1st Duke and Duchess of Northumberland, 1748–86’. The first appendix is a list of the craftsmen and builders who worked on Northumber- land House during this period and the second is a transcription of an unpublished inventory made in 1786 at the death of Sir Hugh Smithson (1712–86), 2nd Earl and later 1st Duke of Northumberland. Works referred to in the footnotes are listed in the bibliography at the end of this file, which also lists the published and unpublished sources referred to in the main paper, which can be found on Cambridge University Press’s online publishing platform, Cambridge Core: cambridge.org/core/; doi: 10.1017/s0003581516000676 APPENDIX 1 Craftsmen and builders employed at Northumberland House, 1748–58 Information on the craftsmen and builders employed at Northumberland House derives mostly from the detailed accounts dating from 1748 to 1767 of the 7th Duke of Somerset and Lord Northumberland with ‘Messrs.