The (Adverse) Incentive Effects of Competing with Superstars
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Auction - Sale 632: Golf Books by the Shelf 01/04/2018 11:00 AM PST
Auction - Sale 632: Golf Books by the Shelf 01/04/2018 11:00 AM PST Lot Title/Description Lot Title/Description 1 24 Golf Books 3 32 Golf Books Includes:Allen, Peter. Famous Fairways. London: Stanley Paul, Includes:Balata, Billy. Being The Ball. Phoenix, Arizona: B.T.B. 1968.Allison, Willie. The First Golf Review. London: Bonar Books, Entertainment, 2000.Beard, Frank. Shaving Strokes. New York: Grosset 1950.Alliss, Peter. A Golfer’s Travels. London: Boxtree, 1997.Alliss, & Dunlap, 1970.Canfield, Jack. Chicken Soup For The Golfer’s Soul: Peter. Bedside Golf. London: Collins, 1980.Alliss, Peter. More Bedside The 2nd Round. Florida: Health Communications, 2002.Canfield, Jack. Golf. London: Collins, 1984.Alliss, Peter. Yet More Bedside Golf. Chicken Soup For The Soul. Cos Cob, Connecticut: Chicken Soup For London: Collins, 1985.Ballesteros, Severiano. Seve. Connecticut: Golf The Soul Publishing, 2008.Canfield, Jack. Chicken Soup For The Soul Digest, 1982.Cotton, Henry. Thanks For The Game. London: Sidgwick & And Golf Digest Present THE GOLF BOOK. Cos Cob, Connecticut: Jackson, 1980.Crane, Malcolm. The Story Of Ladies’ Golf. London: Chicken Soup For The Soul Publishing, 2009.Canfield, Jack. Chicken Stanley Paul, 1991.Critchley, Bruce. Golf And All Its Glory. London: B B Soup For The Woman Golfer’s Soul. Florida: Health Communications, C Books, 1993.Follmer, Lucille. Your Sports Are Showing. : Pellegrini & 2007.Coyne, John. The Caddie Who Won The Masters. Oakland, Cudahy, 1949.Greene, Susan. Consider It Golf. SIGNED. Michigan: California: Peace Corps Writers Book, 2011.Ferguson, Allan Mcalister. Excel, 2000.Greene, Susan. Count On Golf. SIGNED. Michigan: Excel, Golf In Scotland. -

Summary As Introducedxx (2/6/2018)
Legislative Analysis LIQUOR LICENSE FOR PGA TOUR Phone: (517) 373-8080 http://www.house.mi.gov/hfa CHAMPIONS TOURNAMENT Analysis available at House Bill 5190 as introduced http://www.legislature.mi.gov Sponsor: Rep. Tim Sneller Committee: Regulatory Reform Complete to 2-6-17 SUMMARY: House Bill 5190 would amend the Michigan Liquor Control Code to include the Professional Golfers’ Association (PGA) Tour Champions Tournament as a sports-related event of national prominence eligible to receive a national sporting event license that allows the sale of alcohol on the premises concerning a national sporting event. Eligibility for the license would be for Tour events in 2018, 2019, and 2020. The PGA Championship and Champions Tour is a men’s professional senior golf tournament affiliated with the PGA Tour. MCL 436.1517a BACKGROUND INFORMATION: The Michigan Liquor Control Code allows special liquor licenses to be issued for the duration of national sporting events under certain circumstances, including if the national sporting event is conducted under the auspices of a national sanctioning body and the Liquor Control Commission determines that the event will attract a substantial number of tourists from outside the state. Past events have included the 2004 Ryder Cup, 2006 NFL Super Bowl, 2008 PGA Championship, 2009 NCAA Final Four, and the U.S. Golf Association Amateur Championship in 2016. In 2018, Michigan will host two PGA Tour Champions Tournament events: The Kitchen Aid Senior PGA Championship, May 24 to 26, in Benton Harbor, and The Ally Challenge, September 14 to 16, at the Warwick Hills Golf and Country Club in Grand Blanc. -

Information Guide
RAMBLINWRECK.COM / @GT_GOLF 1 GEORGIA TECH TV ROSTER Anders Albertson Bo Andrews Drew Czuchry Michael Hines Jr. • Woodstock, Ga. Sr. • Raleigh, N.C. Sr. • Auburn, Ga. So. • Acworth, Ga. Seth Reeves Ollie Schniederjans Richard Werenski Vincent Whaley Sr. • Duluth, Ga. Jr. • Powder Springs, Ga. Sr. • South Hadley, Mass. Fr. • McKinney, Texas Bruce Heppler Brennan Webb Head Coach Assistant Coach 2 GEORGIA TECH GOLF 2013-14 GEORGIA TECH GOLF INFORMATION GUIDE Quick Facts Offi cial Name Georgia Institute of Technology Location Atlanta, Ga. Founded 1885 Enrollment 21,000 Colors Old Gold and White Nicknames Yellow Jackets, Rambling Wreck Offi cial Athletics Website Ramblinwreck.com Conference Atlantic Coast (ACC) PAGEAGE INDEX President Dr. G.P. “Bud” Peterson 2012-132012-13 Outlook 2 InternationalInternational Competition 3939 Director of Athletics Mike Bobinski 2011-122011-12 Final Statistics 3 LetterwinnersLetterwinners 51 Faculty Athletics Rep. Dr. Sue Ann Bidstrup Allen ACC Championship HistoryHistory 48 NationalNational Collegiate Champions 3636 Head Coach Bruce Heppler (19th year) ACC Championship Teams 6666 NationalNational Honors 3535 Offi ce Phone (404) 894-0961 Administration 1717 NCAANCAA Championship History 4444 Email [email protected] All-AmericansAll-Americans 34 ProfessionalProfessional Golf Champions 3232 Administrative Coordinator Brennan Webb (2nd year) All-America Scholars 2929 Roster/Schedule/MediaRoster/Schedule/Media Information 1 All-Conference Selections 3737 Team Awards 4040 Offi ce Phone (404) 894-4423 Amateur,Amateur, Professional ChChampionsampions 38 Team HistoryHistory At-A-Glance 5522 Email [email protected] CarpetCarpet Capital CollegiateCollegiate 20 Tech’s All-Time Greats 22-3322-33 Golf Offi ce Fax (404) 385-0463 GeorgiaGeorgia Tech Players and Coaches ....................................................................................................... -

Better '09 for State's PGA Tour Pros?
GEORGIAPGA.COM GOLFFOREGEORGIA.COM «« FEBRUARY 2009 Better ’09 for state’s PGA Tour pros? Love, Howell off to quick early starts By Mike Blum nament in ’08, as did former Georgia sixth in regular season points for the ’09 opener, placing him within range of or most of Georgia’s contingent Bulldog Ryuji Imada . FedEdCup and ninth on the final money the top 50 in the World Rankings and a on the PGA Tour, the 2008 The rest of Georgia’s PGA Tour mem - list with almost $4 million. Masters berth. season was not a particularly bers had to wait another week or two to Cink’s ‘08 season was divided into two Imada scored his first PGA Tour win in F memorable one, although there start their ’09 campaigns, with a common disparate halves; before and after his win in four seasons in Atlanta, but will not get the were some exceptions. theme the hope that this year will be a Hartford. Other than his participation on opportunity to defend his title in the Duluth’s Stewart Cink more successful one than 2008. the Ryder Cup team, Cink’s post-victory defunct AT&T Classic. Imada had a pair and Sea Island’s Davis On the surface, Cink’s ‘08 season was an highlights were non-existent. And as well of runner-up finishes among three top- Love opened the extremely successful one. He scored his as he played the first six months of the fives early in ’08 and a near win in the Fall 2009 season in the first win in five years in Hartford, the site season, he let a win get away in Tampa and Series, ending the season 13th in earnings Mercedes-Benz of his first PGA Tour victory as a rookie in did not put up much of a fight in the with over $3 million. -

2000-2009 Section History.Pub
A Chronicle of the Philadelphia Section PGA and its Members by Peter C. Trenham 2000 to 2009 2000 Jack Connelly was elected president of the PGA of America and John DiMarco won the New Jersey Open 2001 Terry Hatch won the stroke play and the match play tournaments at the PGA winter activities in Port St. Lucie 2002 The Section hosted the PGA of America national meeting at the Wyndham Franklin Plaza Hotel in Philadelphia 2003 Jim Furyk won the U.S. Open, Greg Farrow won the N.J. Open, Tom Carter won 3 times on the Nationwide Tour 2004 Pete Oakley won the Senior British Open 2005 Will Reilly was the PGA of America’s “ Junior Golf Leader” and Rich Steinmetz was on the PGA Cup Team 2006 Jim Furyk played on his fifth straight Ryder Cup Team, won the Vardon Trophy and two PGA Tour events 2007 In October the Philadelphia PGA and the Variety Club broke ground on the Variety Club’s 3-hole golf course 2008 Tom Carpus won the PGA of America’s Horton Smith Award and Hugh Reilly received the President Plaque 2009 Mark Sheftic finished second in the PGA Professional National Championship and played on the PGA Cup Team 2000 Jim Furyk won the Doral Open on the Doral Golf Resort’s Blue Course in the first week of March. The course nicknamed the “ Blue Monster” had been toughened in 1996 by adding 27 bunkers, which most of the play- ers didn’t care for. In 1999 the course had been reworked to its original Dick Wilson design, but now most of the players thought the course was too easy. -

2015 Travelers Championship Broadcast Window & Pre-Tournament Notes
2015 Travelers Championship Broadcast Window & Pre-Tournament Notes ShotLink Keys to Victory for Kevin Streelman Kevin Streelman caught fire on his last 9 holes of the Travelers Championship including converting birdie on the final 7 holes of the event. Streelman would become the first winner to birdie the final 7 holes en route to victory. Kevin’s back 9 performance was spectacular, making over 109 feet of putts and gaining nearly 5 strokes on the field in Strokes Gained: Putting. Streelman closed with 10 consecutive one-putts becoming the first winner since Matt Kuchar (2002 The Honda Classic) to finish with 10 consecutive one-putts. Kevin Streelman Final Round Putting Comparison 2014 Travelers Championship Stat Front 9 Back 9 Streelman was over 4 strokes better on the back 9 than the Strokes Gained: Putting +.590 +4.723 front 9 in Strokes Gained: Putting. He needed 6 fewer putts One-Putts 15 9 on the back 9 and made 5 more putts over 5 feet than the front 9 including a 20’8” putt on hole 14 and a 37’1” putt on 7 Putts Made Over 5 Feet 2 the 16th hole. Total Feet of Putts Made 31'8" 109'4" Kevin Streelman gained +4.723 strokes on his final 9 holes in Strokes Gained: Putting marking the best 9 hole SG: Putting performance by a winner since 2004. Streelman joined a memorable group of champions including Russell Henley who birdied his final 5 holes en route to victory at the Sony Open in Hawaii and Stuart Appleby’s historical final round 59 at the 2010 Greenbrier Classic. -

Lucas Glover
Lucas Glover Representerar United States (USA) Född Status Proffs Huvudtour PGA Tour SGT-spelare Nej Aktuellt Ranking 2021 Lucas Glover har i år spelat 20 tävlingar. Han har klarat 13 kval. På dessa 20 starter har det blivit 2 topp-10-placeringar. Lucas Glover har vunnit 1 tävling(ar): John Deere Classic. Han har i år en snittscore om 70,56 efter att ha slagit 4657 slag på 66 ronder. Lucas Glover har på de senaste starterna placeringarna MC-57-MC-MC-38 varav senaste starten var BMW Championship. Han har i år som bästa score noterat 63 (-8) i Waste Management Phoenix Open på TPC Scottsdale. 27 av årets 66 ronder har varit under par. Vid 23 tillfällen har det noterats scorer på under 70 slag men också vid 4 tillfällen minst 75 slag. Årets tävlingar Plac Tävling Plac Tävling Plac Tävling 38 BMW Championship MC Palmetto Championship at Congaree 48 THE PLAYERS Championship Caves Valley Golf Club, PGA Tour Congaree Golf Club, PGA Tour TPC Deere Run, PGA Tour MC THE NORTHERN TRUST 37 the Memorial Tournament presented by Nationwide39 Puerto Rico Open Liberty National Golf Club, PGA Tour Torrey Pines (South), PGA Tour Grand Reserve Country Club, PGA Tour MC Wyndham Championship 8 Charles Schwab Challenge MC The Genesis Invitational Sedgefield Country Club, PGA Tour Course: Colonial Country Club, PGA Tour The Riviera Country Club, PGA Tour 57 World Golf Championships-FedEx St. Jude InvitationalMC Wells Fargo Championship 58 Waste Management Phoenix Open Liberty National Golf Club, PGA Tour Quail Hollow Club , PGA Tour TPC Scottsdale, PGA Tour MC -

SUMMARY AS ENACTED Senate Bill
NATIONAL SPORTING EVENT LICENSE S.B. 820: SUMMARY AS ENACTED Senate Bill 820 (as enacted) PUBLIC ACT 319 of 2020 Sponsor: Senator Kimberly LaSata Senate Committee: Regulatory Reform House Committee: Ways and Means Date Completed: 1-19-21 CONTENT The bill amends the Michigan Liquor Control Code to allow the Michigan Liquor Control Commission (MLCC) to issue a national sporting event license for the Professional Golfers' Association (PGA) Tour Champions Tournament. The Code allows the MLCC to issue national sporting event licenses for the sale of alcoholic liquor for consumption on the premises concerning a national sporting event, if the Commission finds that all of the following circumstances exist: -- The local governmental unit in which the event is to be conducted is the host governmental unit for that event. -- The premises to be licensed is located in a theme area or theme areas designated by the governing body of the host governmental unit in conjunction with the event or are operated in conjunction with the event. -- The event will attract a substantial number of tourists from outside of Michigan. -- The event is conducted under the auspices of a national sanctioning body. In addition, the applicant must be one of the following: -- A Michigan licensee for the sale of alcohol liquor for on-premises consumption. -- The promotor of the national sporting event or an affiliate of the promotor. -- A person who has entered into a written Commission-approved concession or catering agreement with the promotor or its affiliate. -- An organization qualified for licensure as a special licensee, as provided in the Code and rules. -

Pgasrs2.Chp:Corel VENTURA
Senior PGA Championship RecordBernhard Langer BERNHARD LANGER Year Place Score To Par 1st 2nd 3rd 4th Money 2008 2 288 +8 71 71 70 76 $216,000.00 ELIGIBILITY CODE: 3, 8, 10, 20 2009 T-17 284 +4 68 70 73 73 $24,000.00 Totals: Strokes Avg To Par 1st 2nd 3rd 4th Money ê Birth Date: Aug. 27, 1957 572 71.50 +12 69.5 70.5 71.5 74.5 $240,000.00 ê Birthplace: Anhausen, Germany êLanger has participated in two championships, playing eight rounds of golf. He has finished in the Top-3 one time, the Top-5 one time, the ê Age: 52 Ht.: 5’ 9" Wt.: 155 Top-10 one time, and the Top-25 two times, making two cuts. Rounds ê Home: Boca Raton, Fla. in 60s: one; Rounds under par: one; Rounds at par: two; Rounds over par: five. ê Turned Professional: 1972 êLowest Championship Score: 68 Highest Championship Score: 76 ê Joined PGA Tour: 1984 ê PGA Tour Playoff Record: 1-2 ê Joined Champions Tour: 2007 2010 Champions Tour RecordBernhard Langer ê Champions Tour Playoff Record: 2-0 Tournament Place To Par Score 1st 2nd 3rd Money ê Mitsubishi Elec. T-9 -12 204 68 68 68 $58,500.00 Joined PGA European Tour: 1976 ACE Group Classic T-4 -8 208 73 66 69 $86,400.00 PGA European Tour Playoff Record:8-6-2 Allianz Champ. Win -17 199 67 65 67 $255,000.00 Playoff: Beat John Cook with a eagle on first extra hole PGA Tour Victories: 3 - 1985 Sea Pines Heritage Classic, Masters, Toshiba Classic T-17 -6 207 70 72 65 $22,057.50 1993 Masters Cap Cana Champ. -
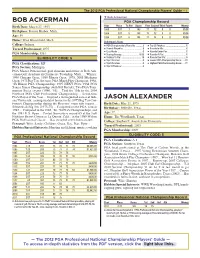
Cpc1.Chp:Corel VENTURA
The 2012 PGA Professional National Championship Players' Guide —1 q Bob Ackerman BOB ACKERMAN http://www.golfobserver.com/golfstats/golfstats.php?style=&tour=PGA&name=Bob+Ackerman&year=&tournament=PGA+Championship&in=SearPGA Championship Record ch Birth Date: March 27, 1953 Year Place To Par Score First Second Third Fourth Money 1985 CUT 7 149 77 72 0 0 $0.00 Birthplace: Benton Harbor, Mich. 1986 CUT 6 148 76 72 0 0 $0.00 Age: 59 1994 CUT 6 146 72 74 0 0 $0.00 Home: West Bloomfield, Mich. Ackerman’s Stats: College: Indiana ¢ PGA Championship’s Played In: .......... 3 ¢ Top 25 Finishes: ................................ 0 Turned Professional: 1975 ¢ Rounds Played In: .............................. 6 ¢ Rounds In 60s: .................................. 0 ¢ Cuts Made: ....................................... 0 ¢ Rounds Under Par: ............................ 0 PGA Membership: 1981 ¢ Scoring Average: .........................73.83 ¢ Rounds At Par: .................................. 0 ELIGIBILITY CODE: 5 ¢ Relation To Par: ............................... 19 ¢ Rounds Over Par: .............................. 6 ¢ Top 3 Finishes: .................................. 0 ¢ Lowest PGA Championship Score: ....72 PGA Classification: MP ¢ Top 5 Finishes: .................................. 0 ¢ Highest PGA Championship Score: ....77 PGA Section: Michigan ¢ Top 10 Finishes: ................................ 0 PGA Master Professional, golf clinician and owner of Bob Ack- erman Golf Academy in Commerce Township, Mich. … Winner, 1999 Chicago Open; 1989 Illinois -

The Rise and Fall of Tiger Woods and Its Effects on the Golf Industry and His Sponsors’ Performance
THE RISE AND FALL OF TIGER WOODS AND ITS EFFECTS ON THE GOLF INDUSTRY AND HIS SPONSORS’ PERFORMANCE by Griffin Gale Whiting Submitted in partial fulfillment of the requirements for Departmental Honors in the Department of Accounting Texas Christian University Fort Worth, Texas May 6, 2019 ii THE RISE AND FALL OF TIGER WOODS AND ITS EFFECTS ON THE GOLF INDUSTRY AND HIS SPONSORS’ PERFORMANCE Project Approved: Supervising Professor: Mark Wills, MAc Department of Accounting Swaminathan Kalpathy, Ph.D. Department of Finance iii ABSTRACT Tiger Woods is one of the greatest athletes of all time and his impact on the game of golf will be felt for generations. Woods has been the center of academic and nonacademic research, which mainly focuses on the significance of his endorsement of a certain company’s products or services. Throughout my research I noticed that Woods’ effect on the golf industry as a whole has not been sufficiently studied. The main purpose of this study is to attempt to understand the effect that Woods has had on the golf industry, but his impact on his major publicly traded sponsors are also analyzed. Mainly through the use of a multiple regression analysis along with other more qualitative research methods, it was discovered that Woods has had a signifigant impact on the health of the golf industry, but his effect on his major publicly traded sponsors is inconclusive. Although the results of this study are interesting, it is important to realize that this is preliminary research. More research is necessary, especially concerning Woods’ effect on the golf industry, to understand Tiger Woods and the game of golf. -

Marc Leishman
Marc Leishman Representerar Australien (AUS) Född Status Proffs Huvudtour PGA Tour SGT-spelare Nej Aktuellt Ranking 2021 Marc Leishman har i år spelat 17 tävlingar. Han har klarat 14 kval. På dessa 17 starter har det blivit 3 topp-10-placeringar. Som bäst har Marc Leishman en 3-plats i Travelers Championship. Han har i år en snittscore om 70,36 efter att ha slagit 4081 slag på 58 ronder. Marc Leishman har på de senaste starterna placeringarna 3-MC-36-47-51 varav senaste starten var BMW Championship. Han har i år som bästa score noterat 66 (-6) i AT&T Byron Nelson på TPC Craig Ranch. 36 av årets 58 ronder har varit under par. Vid 25 tillfällen har det noterats scorer på under 70 slag men också vid 6 tillfällen minst 75 slag. Marc Leishman har klarat kvalet i de 3 senaste tävlingarna. Kvalsviten i år löper från World Golf Championships-FedEx St. Jude Invitational (vecka 31/2021). Årets tävlingar Plac Tävling Plac Tävling Plac Tävling 51 BMW Championship 57 the Memorial Tournament presented by Nationwide39 World Golf Championships at The Concession Caves Valley Golf Club, PGA Tour Torrey Pines (South), PGA Tour The Concession Golf Club, PGA Tour 47 THE NORTHERN TRUST MC PGA Championship 32 The Genesis Invitational Liberty National Golf Club, PGA Tour Ocean Course at Kiawah Island, PGA Tour The Riviera Country Club, PGA Tour 36 World Golf Championships-FedEx St. Jude Invitational21 AT&T Byron Nelson 18 Farmers Insurance Open Liberty National Golf Club, PGA Tour TPC Craig Ranch, PGA Tour Torrey Pines (South), PGA Tour MC THE 149TH OPEN 5 The Masters 4 Sony Open in Hawaii Royal St George’s GC, European Tour Augusta National, PGA Tour Waialae Country Club, PGA Tour 3 Travelers Championship 28 World Golf Championships-Dell Technologies 24Match Sentry Play Tournament of Champions TPC River Highlands, PGA Tour Austin Country Club, PGA Tour Plantation Course at Kapalua, PGA Tour 64 U.S.