The Definitive Guide to Windows Software Deployment
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

List of TCP and UDP Port Numbers
List of TCP and UDP port numbers From Wikipedia, the free encyclopedia Jump to: navigation, search This is a list of Internet socket port numbers used by protocols of the Transport Layer of the Internet Protocol Suite for the establishment of host-to-host communications. Originally, these port numbers were used by the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP), but are used also for the Stream Control Transmission Protocol (SCTP), and the Datagram Congestion Control Protocol (DCCP). SCTP and DCCP services usually use a port number that matches the service of the corresponding TCP or UDP implementation if they exist. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[1] However, many unofficial uses of both well- known and registered port numbers occur in practice. Contents [hide] y 1 Table legend y 2 Well-known ports: 0±1023 y 3 Registered ports: 1024±49151 y 4 Dynamic, private or ephemeral ports: 49152±65535 y 5 See also y 6 References y 7 External links [edit] Table legend Color coding of table entries Official Port/application combination is registered with IANA Unofficial Port/application combination is not registered with IANA Conflict Port is in use for multiple applications [edit] Well-known ports: 0±1023 The port numbers in the range from 0 to 1023 are the well-known ports. They are used by system processes that provide widely-used types of network services. On Unix-like operating systems, a process must execute with superuser privileges to be able to bind a network socket to an IP address using one of the well-known ports. -

List of TCP and UDP Port Numbers
List of TCP and UDP port numbers From Wikipedia, the free encyclopedia Jump to: navigation, search In computer networking, the protocols of the Transport Layer of the Internet Protocol Suite, most notably the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP), but also other protocols, use a numerical identifier for the data structures of the endpoints for host-to- host communications. Such an endpoint is known as a port and the identifier is the port number. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[1] Contents [hide] y 1 Table legend y 2 Well-known ports: 0±1023 y 3 Registered ports: 1024±49151 y 4 Dynamic, private or ephemeral ports: 49152±65535 y 5 See also y 6 References y 7 External links [edit] Table legend Color coding of table entries Official Port/application combination is registered with IANA Unofficial Port/application combination is not registered with IANA Conflict Port is in use for multiple applications [edit] Well-known ports: 0±1023 According to IANA "The Well Known Ports are assigned by the IANA and on most systems can only be used by system (or root) processes or by programs executed by privileged users. Ports are used in the TCP [RFC793] to name the ends of logical connections which carry long term conversations. For the purpose of providing services to unknown callers, a service contact port is defined. This list specifies the port used by the server process as its contact port. The contact port is sometimes called the well-known port."[1] Port TCP UDP Description Status 0 UDP Reserved Official When running a server on port 0, the system will run it on a random 0 TCP UDP port from 1-65535 or 1024-65535 depending on the privileges of Official the user. -

The Definitive Guide to Windows Installer Technology for System
The Definitive Guidetmtm To Windows Installer Technology for System Administrators Darwin Sanoy and Jeremy Moskowitz Introduction Introduction to Realtimepublishers by Sean Daily, Series Editor The book you are about to enjoy represents an entirely new modality of publishing and a major first in the industry. The founding concept behind Realtimepublishers.com is the idea of providing readers with high-quality books about today’s most critical technology topics—at no cost to the reader. Although this feat may sound difficult to achieve, it is made possible through the vision and generosity of a corporate sponsor who agrees to bear the book’s production expenses and host the book on its Web site for the benefit of its Web site visitors. It should be pointed out that the free nature of these publications does not in any way diminish their quality. Without reservation, I can tell you that the book that you’re now reading is the equivalent of any similar printed book you might find at your local bookstore—with the notable exception that it won’t cost you $30 to $80. The Realtimepublishers publishing model also provides other significant benefits. For example, the electronic nature of this book makes activities such as chapter updates and additions or the release of a new edition possible in a far shorter timeframe than is the case with conventional printed books. Because we publish our titles in “real-time”—that is, as chapters are written or revised by the author—you benefit from receiving the information immediately rather than having to wait months or years to receive a complete product. -
Macro Maker Software
Macro maker software click here to download MacroMaker latest version: Create all sorts of macros to automate repetitive tasks. Luckily the program has an extensive documentation that teaches you the. Pulover's Macro Creator is a full featured automation tool for Windows and it's free for Reproduce your macros with automatic window activation. ; Version Update: May 7, ; Software of the day on SOFTPEDIA April 30, Macro Recorder - the best macro program for Windows. Not just a keyboard and mouse recorder but a powerful automation tool that converts macros to EXE files Pricing · Free Macro Recorder · Basic Video Tutorial · FAQ. This is a very handy freeware macro maker that suffers from an unfortunate error. MacroMaker's complex interface really isn't that difficult to master. It's. Current version for download , released 03/20/ MacroMaker is truly a free piece of software for personal home use, but the author would not refuse a. The terms used in Macro Dollar are slightly different compared to the rest because this program is created by a Frenchman. For example, the. Pulovers Macro Creator is a Free Automation Tool and Script Generator. It is based Macros can be executed from the program itself or you ca. Free keyboard macro program. Supports hotkeys for keyboard, mouse, and joystick. Can expand abbreviations as you type them (AutoText). Macro software that feature macro recorder (mouse recorder), task scheduler, autocomplete, autofill web forms, and many commands for any task automation. Macro Express&; is the premier Windows automation macro utility. Record, edit and play back mouse and keyboard macros. -

Jeff Eisenberg Systems Engineer, the Galecia Group 707.763.6869 [email protected]
Jeff Eisenberg Systems Engineer, The Galecia Group 707.763.6869 [email protected] • Nine years of experience in network engineering, design, integration, and administration • Excellent at providing security needs assessments and solutions • Strong enterprise integration techniques – server-side and client-side • Special interest in designing secure networks with emphasis on end user experience • Special skill at streamlining complicated, disorganized networks, and implementing best practice methods Relevant Experience Infopeople (Federally funded project administered by California State Library) • Designed and documented fully customizable public access computers to allow for different needs of public law libraries throughout California. • Designed secure wireless laptop labs provided by Gates Foundation grants with automated rollout procedure and customized emergency restore disks. • Provide engineering support to Infopeople Contra Costa County Library General network upgrade and network segmentation for public access LAN. Designed high-security stand- alone public access computers, documentation, rollout and emergency restore procedure. Network Engineer, eBenefits Inc. (Online human resource management) Set up security and integrated SF site with co-location site at Exodus. Design involved 3 logical networks, 111 servers, 6 different development environments, clustering, load balancing, web and database log shipping, Site Server application deployment, SNMP monitoring, VPN connectivity, managed switches, and access restriction through Cisco ACLs. Designed and implemented a low maintenance, stable corporate network from ground zero. Design used Windows 2000 Active Directory and tight security policies to support corporate, development, and visitor kiosk environments. Design included redundant DNS and DHCP, Exchange, Backup Exec, and fault tolerant hardware. Set up remote access using Citrix over MS Terminal Server and customized web access using Nfuse and SSL secure transmission. -

List of TCP and UDP Port Numbers
List of TCP and UDP port numbers From Wikipedia, the free encyclopedia Jump to: navigation, search In computer networking, the protocols of the Transport Layer of the Internet Protocol Suite, most notably the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP), but also other protocols, use a numerical identifier for the data structures of the endpoints for host-to-host communications. Such an endpoint is known as a port and the identifier is the port number. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[1] Contents • [hide]1 Table legend • 2 Well- known ports: 0–1023 • 3 Registe red ports: 1024– 49151 • 4 Dynami c and/or private ports: 49152– 65535 • 5 See also • 6 Referen ces • 7 Externa l links [edit] Table legend Color coding of table entries Official Port/application combination is registered with IANA Unofficial Port/application combination is not registered with IANA Conflict Port is in use for multiple applications [edit] Well-known ports: 0–1023 Port Description Status 0/TCP,U Reserved Official DP 1/TCP,U TCP Port Service Multiplexer Official DP 2/TCP,U Management Utility Official DP 3/TCP,U Compression Process Official DP 5/TCP,U Remote Job Entry Official DP 7/TCP,U Echo Official DP 9/TCP,U Discard Official DP 11/TCP, Active Users Official UDP 13/TCP, DAYTIME - (RFC 867) Official UDP 17/TCP, Quote of the Day Official UDP 18/TCP, Message Send Protocol Official UDP 19/TCP, Character Generator Official UDP 20/TCP FTP -

List of New Applications Added in ARL #2576
List of New Applications Added in ARL #2576 Application Name Publisher NetCmdlets 4.0 /n software NetCmdlets 3.1 /n software SecureBlackbox.NET 8.0 /n software NetCmdlets 3.0 /n software EldoS SFTP Net Drive 1.0 /n software Tenup 20190117 1010data Tendo 20151112 1010data Tendo 20160205 1010data Tendo 20190905 1010data Tendo 20170723 1010data Tendo 20161207 1010data 1042-S Pro 2016 Professional 1099 Pro Manager (10ZiG Manager) 3.0 10ZIG Technology DataParser 7.5 17a-4 1E Agent 7.2 1E SyncBackSE 8.2 2BrightSparks 2c8 Modeling Tool 4.2 2conciliate Business Solutions TaxACT 2017 2nd Story Software TaxACT 2018 2nd Story Software Complete Anatomy 5.0 3D4Medical Clean-Trace Hygiene Management 1.3 3M Core Grouping Software 2019 3M Core Grouping Software Client 2019 3M DWG DXF Converter 1.1 3nity Softwares Studio 3T 2020.9 3T Software Labs MongoChef 4.5 3T Software Labs MP4 to MP3 Converter 6.8 4Media Software Studio SendLater 3.4 4Team Disk Dril 3.7 508 Software Disk Dril 1.0 508 Software Disk Dril 3.5 508 Software Disk Dril 3.6 508 Software DoublePane 1.7 5am Code 7-PDF Maker 1.5 7-PDF Network Utility 2.2 8x8 Virtual Office Desktop 6.1 8x8 Virtual Office Desktop 6.4 8x8 Virtual Office Desktop 5.6 8x8 Virtual Office Desktop 6.7 8x8 ASAP Utilities 7.8 A Must in Every Office SafeSign 3.5 A.E.T. Europe BestSRQ Services 2015 A.M. Best Company BestESP Services Workstation 2012 A.M. Best Company BestESP Services Workstation A.M. -

Opsi Getting Started Opsi-Version 3.4
Documentation as of: 06/16/2010 opsi Getting Started opsi-Version 3.4 installation manual opsi-server start-up first steps open pc server integration uib gmbh Bonifaziusplatz 1B, 55118 Mainz Tel.: +49 6131-275610 www.uib.de [email protected] Table of Contents 1. INTRODUCTION................................................................................................................6 1.1 Steps for installation and starting.........................................................................................................................6 1.1 Hardware requirement...........................................................................................................................................6 2. INSTALLATION.................................................................................................................7 2.1 opsi-server base installation....................................................................................................................................7 2.1.1 Starting of a VMware-Machine..........................................................................................................................7 2.1.1.1 First Start....................................................................................................................................................7 2.1.1.2 Language configuration..............................................................................................................................8 2.1.1.3 „1stboot“....................................................................................................................................................8 -
Official 2 TCP UDP Compr
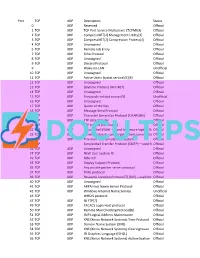
Port TCP UDP Description Status 0 UDP Reserved Official 1 TCP UDP TCP Port Service Multiplexer (TCPMUX) Official 2 TCP UDP CompressNET[2] Management Utility[3] Official 3 TCP UDP CompressNET[2] Compression Process[4] Official 4 TCP UDP Unassigned Official 5 TCP UDP Remote Job Entry Official 7 TCP UDP Echo Protocol Official 8 TCP UDP Unassigned Official 9 TCP UDP Discard Protocol Official 9 UDP Wake-on-LAN Unofficial 10 TCP UDP Unassigned Official 11 TCP UDP Active Users (systat service)[5][6] Official 12 TCP UDP Unassigned Official 13 TCP UDP Daytime Protocol (RFC 867) Official 14 TCP UDP Unassigned Official 15 TCP UDP Previously netstat service[5] Unofficial 16 TCP UDP Unassigned Official 17 TCP UDP Quote of the Day Official 18 TCP UDP Message Send Protocol Official 19 TCP UDP Character Generator Protocol (CHARGEN) Official 20 TCP UDP FTP data transfer Official 21 TCP FTP control (command) Official 22 TCP UDP Secure Shell (SSH) — used for secure logins, file Officialtransfers (scp, sftp) and port forwarding 23 TCP UDP Telnet protocol—unencrypted text communicationsOfficial 24 TCP UDP Priv-mail : any private mail system. Official 25 TCP Simple Mail Transfer Protocol (SMTP)—used forOfficial e-mail routing between mail servers 26 TCP UDP Unassigned Official 27 TCP UDP NSW User System FE Official 29 TCP UDP MSG ICP Official 33 TCP UDP Display Support Protocol Official 35 TCP UDP Any private printer server protocol Official 37 TCP UDP TIME protocol Official 39 TCP UDP Resource Location Protocol*7+ (RLP)—used for determiningOfficial the location -

Operativni Sistem Projektovan Da Povezuje
1 OPERATIVNI SISTEM PROJEKTOVAN DA POVEZUJE Windows NT Umre`avanje: Tehni~ki pregled Nakon ~itanja ovog poglavlja, razume}ete osnovne karakteristike Windows NT 4.0, posebno one koje se odnose na povezivanje u mre`u. Tako|e }ete razumeti osnovne koncepte koji }e se koris- titi u ovoj knjizi, a koji uklju~uju: n Koncepte jezgra operativnog sistema, uklju~uju}i mikrokernel, arhitekturu klijent/server, prenosivost, objektnu orjentaciju, slojevite drajvere ure|aja i fajl sisteme koji se mogu instalirati. n Mre`e i njihova svojstva, uklju~uju}i i preusmerava~e (redirekcije) mre`e. n Klju~ne razlike izme|u Windows NT radne stanice, koja je pogodna da se koristi kao klijent mre`e, i Windows NT servera. n Kriti~ni odnos izme|u NT servera i Interneta. n Opredeljivanje za dobijanje dozvole pristupa kao klijent NT servera ili za konkurentno povezivanje. Windows NT 4.0 u vi{e aspekata predstavlja novinu, bez obzira {to deli dora|eni korisni~ki inter- fejs sa Windows 95. Iako osnovne karakteristike ovog operativnog sistema, a koje se odnose na povezivanje u mre`u, nisu mnogo izmenjene - izuzev karakteristika koje se odnose na Internet (toliko obimne u ovom tre}em izdanju, da smo im posvetili ~itavo novo Poglavlje 7) - svega je dodato nekoliko novih. Me|u njima je i jedan novi, mnogo kvalitetniji oblik pristupa mre`i iz daljine (~ija klijent komponenta se sada zove Dial Up Network-ing, kao kod Windows 95); zatim novi Netware 4.x-kompatibilni preusmerava~ (redirektor) mre`e koji podr`ava Novell Directory Service1 (NDS) stabla i NetWare log-in skriptove, -

Formatting Syntax Formatting Syntax
2021/01/28 22:10 1/15 Formatting Syntax Formatting Syntax DokuWiki supports some simple markup language, which tries to make the datafiles to be as readable as possible. This page contains all possible syntax you may use when editing the pages. Simply have a look at the source of this page by pressing “Edit this page”. If you want to try something, just use the playground page. The simpler markup is easily accessible via quickbuttons, too. Basic Text Formatting DokuWiki supports bold, italic, underlined and monospaced texts. Of course you can combine all these. DokuWiki supports **bold**, //italic//, __underlined__ and ''monospaced'' texts. Of course you can **__//''combine''//__** all these. superscript You can use subscript and , too. You can use <sub>subscript</sub> and <sup>superscript</sup>, too. You can mark something as deleted as well. You can mark something as <del>deleted</del> as well. Paragraphs are created from blank lines. If you want to force a newline without a paragraph, you can use two backslashes followed by a whitespace or the end of line. This is some text with some linebreaks Note that the two backslashes are only recognized at the end of a line or followed by a whitespace \\this happens without it. This is some text with some linebreaks\\ Note that the two backslashes are only recognized at the end of a line\\ or followed by\\ a whitespace \\this happens without it. You should use forced newlines only if really needed. Links DokuWiki supports multiple ways of creating links. Computer Science Courses - https://courses.cs.purdue.edu/ Last update: 2020/05/01 06:38 wiki:syntax https://courses.cs.purdue.edu/wiki:syntax External External links are recognized automagically: http://www.google.com or simply www.google.com - You can set the link text as well: This Link points to google. -

1 SAP GUI Scripting API
DEVELOPER GUIDE | PUBLIC Document Version: 7.60 PL4 – 2019-11-25 SAP GUI Scripting API company. All rights reserved. All rights company. affiliate THE BEST RUN 2019 SAP SE or an SAP SE or an SAP SAP 2019 © Content 1 SAP GUI Scripting API........................................................ 5 1.1 Requirements and Remarks......................................................7 1.2 Objects....................................................................8 GuiAbapEditor Object.......................................................15 GuiApoGrid Object.........................................................29 GuiApplication Object ......................................................37 GuiBarChart Object ........................................................47 GuiBox Object............................................................51 GuiButton Object..........................................................53 GuiCalendar Object ........................................................55 GuiChart Object...........................................................61 GuiCheckBox Object.......................................................65 GuiCollection Collection.....................................................68 GuiColorSelector Object.....................................................69 GuiComboBox Object ...................................................... 72 GuiComboBoxControl Object.................................................75 GuiComboBoxEntry Object...................................................78 GuiComponent