KOS.Content 01 | 2014
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Student Authored Textbook on Software Architectures
Software Architectures: Case Studies Authors: Students in Software Architectures course Computer Science and Computer Engineering Department University of Arkansas May 2014 Table of Contents Chapter 1 - HTML5 Chapter 2 – XML, XML Schema, XSLT, and XPath Chapter 3 – Design Patterns: Model-View-Controller Chapter 4 – Push Notification Services: Google and Apple Chapter 5 - Understanding Access Control and Digital Rights Management Chapter 6 – Service-Oriented Architectures, Enterprise Service Bus, Oracle and TIBCO Chapter 7 – Cloud Computing Architecture Chapter 8 – Architecture of SAP and Oracle Chapter 9 – Spatial and Temporal DBMS Extensions Chapter 10 – Multidimensional Databases Chapter 11 – Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Chapter 12 –Business Rules and DROOLS Chapter 13 – Complex Event Processing Chapter 14 – User Modeling Chapter 15 – The Semantic Web Chapter 16 – Linked Data, Ontologies, and DBpedia Chapter 17 – Radio Frequency Identification (RFID) Chapter 18 – Location Aware Applications Chapter 19 – The Architecture of Virtual Worlds Chapter 20 – Ethics of Big Data Chapter 21 – How Hardware Has Altered Software Architecture SOFTWARE ARCHITECTURES Chapter 1 – HTML5 Anh Au Summary In this chapter, we cover HTML5 and the specifications of HTML5. HTML takes a major part in defining the Web platform. We will cover high level concepts, the history of HTML, and famous HTML implementations. This chapter also covers how this system fits into a larger application architecture. Lastly, we will go over the high level architecture of HTML5 and cover HTML5 structures and technologies. Introduction High level concepts – what is the basic functionality of this system HyperText Markup Language (HTML) is the markup language used by to create, interpret, and annotate hypertext documents on any platform. -

Corporate Registry Registrar's Periodical Template
Service Alberta ____________________ Corporate Registry ____________________ Registrar’s Periodical REGISTRAR’S PERIODICAL, OCTOBER 15, 2009 SERVICE ALBERTA Corporate Registrations, Incorporations, and Continuations (Business Corporations Act, Cemetery Companies Act, Companies Act, Cooperatives Act, Credit Union Act, Loan and Trust Corporations Act, Religious Societies’ Land Act, Rural Utilities Act, Societies Act, Partnership Act) 0858562 B.C. LTD. Other Prov/Territory Corps 1487822 ALBERTA LTD. Numbered Alberta Registered 2009 SEP 08 Registered Address: 2700 Corporation Incorporated 2009 SEP 01 Registered COMMERCE PLACE, 10155 - 102 STREET, Address: 127 SENECA ROAD, SHERWOOD PARK EDMONTON ALBERTA, T5J 4G8. No: 2114889252. ALBERTA, T8A 4G6. No: 2014878223. 0859953 B.C. LTD. Other Prov/Territory Corps 1487828 ALBERTA LTD. Numbered Alberta Registered 2009 SEP 15 Registered Address: 1200, 700 - Corporation Incorporated 2009 SEP 01 Registered 2ND STREET SW, CALGARY ALBERTA, T2P 4V5. Address: 10040 87 AVE NW, EDMONTON No: 2114902543. ALBERTA, T6E 2N9. No: 2014878280. 101142932 SASKATCHEWAN LTD. Other 1487831 ALBERTA LTD. Numbered Alberta Prov/Territory Corps Registered 2009 SEP 11 Registered Corporation Incorporated 2009 SEP 01 Registered Address: 499 - 1 STREET SE, MEDICINE HAT Address: 3812 MACNEIL HEATH, EDMONTON ALBERTA, T1A 0A7. No: 2114895259. ALBERTA, T6R 0H5. No: 2014878314. 1481801 ALBERTA LTD. Numbered Alberta 1487832 ALBERTA LTD. Numbered Alberta Corporation Incorporated 2009 SEP 07 Registered Corporation Incorporated 2009 SEP 01 Registered Address: 1013 5TH AVENUE, WAINWRIGHT Address: 2056 TANNER WYND, EDMONTON ALBERTA, T9W 1L6. No: 2014818013. ALBERTA, T6R 2R4. No: 2014878322. 1485500 ALBERTA LTD. Numbered Alberta 1487845 ALBERTA LTD. Numbered Alberta Corporation Incorporated 2009 SEP 02 Registered Corporation Incorporated 2009 SEP 03 Registered Address: 2401 TD TOWER, 10088 102 AVENUE, Address: 4007-34A AVENUE NW, EDMONTON EDMONTON ALBERTA, T5J 2Z1. -

A South Vietnam Pocket Guide, 1962
ARMY UNIFORMS Of VtnN.AM 7 Ill VIETNAM I 1 rlmJJ- NINE RULES For Personnel of U.S. Military Assistance Command, Vietnam HOW MUCH DO YOU KNOW ABOUT VIETNAM ? The Victnameae have p!Ud • hetJvy price in ruff~ for t hC'lr Ion& fiaht a«Aintt the Commumst.. We mtlitsry attn .,-c in ViCUUU'D o.ow bccau'le their r;ovcr1'mcnt hai Mlccd ue to help iu toldiCTt iaM peopk in winnin& their ttnigglc. Tbc Viet Cone wi11 aucmpt to tum th«' Vietnamese people qainat you. You can defeat. them At c•u:ry lum Why Is It o (Lcn diftkull to by the strength, undcnl.And~. and gcn\!:n:l5ity you display with tell a Viet Cona from a loyol the people. Hett are the nine simple rules: South VictnA~ ? 8 " Remember we are spcdal e;ucats here; we make no demands And aedt no 1pccud U'eAtmc:nt. h 11uoc mam 110mcth1na to wear, "Join with the people! Underatand tbclr life, uee phruct from 1omethin& to or the of e11t , name t hci:r IAneuai:e. end honor their cu1tomt and lawt. t'U\ orglU\i..rotlon? ··Treat womm witb Politcuc!IS and ropc:c:l. ''Malec pcnonal friends am(lng the 110ldicn and common people. Why would a South V1ct.ruuneac be puzzled or off'cndcd J you u1cd " Always i;\vc tbc Vict..o.amcao tllc ril(ht oC way. the American gesture fot beckonini ''Be alert. lo MCUrity and ttady to tellct with your mlllt.ar)' hlm to come to )'OU] alcill. " Don't Al trfct attention by loud, rude. -

CMS, LMS, LCMS Kavramları
XI. Akademik Bilişim Konferansı, 11-13 Şubat 2009, Harran Üniversitesi, ŞANLIURFA CMS, LMS, LCMS Kavramları Özlem Ozan Eskişehir Osmangazi Üniversitesi, Bilgisayar ve Öğretim Teknolojileri Eğitimi Bölümü, ESKİŞEHİR Özet: eÖğrenme ve uzaktan eğitim uygulamalarının yaygınlaşmasıyla birlikte eğitim içeriği ve uygulamalarının elektronik ortamdaki yönetimi giderek önem kazanmıştır. Buna paralel olarak içerik ve uygulamaların nasıl yönetileceği tartışılmaya başlanmıştır. Eğitim öğretim süreçlerinin, içeriklerinin veya etkinliklerinin bir arada ya da ayrı ayrı yönetilebileceği pek çok farklı uygulama mevcuttur ancak bu bağlamda konuyla ilgili kavram kargaşası da süregelmektedir. Bu çalışmada, içerik yönetim sistemi (content management system-cms), öğrenme yönetim sistemi (learning management system-lms), ve öğrenme içerik yönetim sistemlerinin (learning content management system-lcms) kavramları irdelenecek ve bu bağlamda ulusal alan yazına katkı sağlanmaya çalışılacaktır. Giriş 1. İçerik Yönetim Sistemi Günümüz dünyasında, bilgi ve iletişim İçerik yönetim sistemleri (Content Management teknolojilerinin hızlı gelişimi ve özellikle Web Systems) günümüzde popüler olan ve çoğu 2.0 sürecinde içerik anlayışının ve öneminin zaman web sistemleri için kullanılan bir kavram artmasıyla, “İçerik Yönetimi” kavramı hemen olarak karşımıza çıkmaktadır. “İçerik” kavramı, hemen bütün alanlarda ihtiyaç duyulan ve Türk Dil Kurumunun Türkçe sözlüğünde bir tartışılan bir kavram haline gelmiştir. şeyin içinde bulunanların bütünü, muhtevası olarak tanımlanmaktadır[1]. -

Building Blocks of a Scalable Web Crawler
Building blocks of a scalable web crawler Marc Seeger Computer Science and Media Stuttgart Media University September 15, 2010 A Thesis Submitted in Fulfilment of the Requirements for a Degree of Master of Science in Computer Science and Media Primary thesis advisor: Prof. Walter Kriha Secondary thesis advisor: Dr. Dries Buytaert I I Abstract The purpose of this thesis was the investigation and implementation of a good architecture for collecting, analysing and managing website data on a scale of millions of domains. The final project is able to automatically collect data about websites and analyse the content management system they are using. To be able to do this efficiently, different possible storage back-ends were examined and a system was implemented that is able to gather and store data at a fast pace while still keeping it searchable. This thesis is a collection of the lessons learned while working on the project combined with the necessary knowledge that went into architectural decisions. It presents an overview of the different infrastructure possibilities and general approaches and as well as explaining the choices that have been made for the implemented system. II Acknowledgements I would like to thank Acquia and Dries Buytaert for allowing me to experience life in the USA while working on a great project. I would also like to thank Chris Brookins for showing me what agile project management is all about. Working at Acquia combined a great infrastructure and atmosphere with a pool of knowledgeable people. Both these things helped me immensely when trying to find and evaluate a matching architecture to this project. -

Chapter 3 – Design Patterns: Model-View- Controller
SOFTWARE ARCHITECTURES Chapter 3 – Design Patterns: Model-View- Controller Martin Mugisha Brief History Smalltalk programmers developed the concept of Model-View-Controllers, like most other software engineering concepts. These programmers were gathered at the Learning Research Group (LRG) of Xerox PARC based in Palo Alto, California. This group included Alan Kay, Dan Ingalls and Red Kaehler among others. C language which was developed at Bell Labs was already out there and thus they were a few design standards in place[ 1] . The arrival of Smalltalk would however change all these standards and set the future tone for programming. This language is where the concept of Model-View- Controller first emerged. However, Ted Kaehler is the one most credited for this design pattern. He had a paper in 1978 titled ‘A note on DynaBook requirements’. The first name however for it was not MVC but ‘Thing-Model-View-Set’. The aim of the MVC pattern was to mediate the way the user could interact with the software[ 1] . This pattern has been greatly accredited with the later development of modern Graphical User Interfaces(GUI). Without Kaehler, and his MVC, we would have still been using terminal to input our commands. Introduction Model-View-Controller is an architectural pattern that is used for implementing user interfaces. Software is divided into three inter connected parts. These are the Model, View, and Controller. These inter connection is aimed to separate internal representation of information from the way it is presented to accepted users[ 2] . fig 1 SOFTWARE ARCHITECTURES As shown in fig 1, the MVC has three components that interact to show us our unique information. -
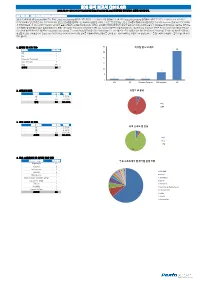
EDB 분석 보고서 (2016.09) 2016.09.01~2016.09.30 Exploit-DB( 공개된 취약점별로 분류한 정보입니다
EDB 분석 보고서 (2016.09) 2016.09.01~2016.09.30 Exploit-DB(http://exploit-db.com)에 공개된 취약점별로 분류한 정보입니다. 분석 내용 정리 (작성: 펜타시큐리티시스템 보안성평가팀) 2016년 9월에 공개된 Exploit-DB의 분석 결과, Cross Site Scripting 공격에 대한 취약점 보고 개수가 가장 많았습니다. 발견된 Cross Site Scripting 공격들의 대부분은 오픈소스 아이피 관리 시스템인 PHPIPAM에서 발견되었습니다. PHPIPAM 에서 발견된 공격들을 분석해보면, 파라미터 값을 변조하여 스크립트를 삽입하는 단순한 공격들의 형태가 대부분이었습니다. SQL Injection 공격 역시 PHPIAM에 서 발견되었는데, 이 역시 공격의 위험도와 난이도가 높은 형태들의 공격은 아니었습니다. 그러나, 취약점이 발견된 페이지가 상당히 많고 추가적인 공격에 노출될 수 있으므로 PHPIPAM을 사용하는 관리자는 시큐어코딩 및 보안업데이트가 필요해 보입니다. 또한, 이번 달에는 Exponent CMS에서 특이한 SQL Injection 취약점이 발견되었습니다. 대부분의 SQL Injection 공격은 Parameter의 value를 노리게 되는 데, 이번에 발견된 취약점은 일반적인 Parameter key, value의 구조가 아닌 URL경로에 공격하는 패턴이었습니다. 이는 일반적으로는 성공이 되지 않는 취약점이지만 사이트의 구조에 따라 얼마든지 공격이 성공할 수 있는 취약점입니다. Exponent CMS와 마찬가지로 사이트가 URL 경로를 이용해서 어떠한 행위를 한다면 반드시 주의해야 될 부분이므로 관련 공격코드를 참고하여 취약점에 노출되지 않도록 주의 해야 합니다. 30 1. 취약점 별 보고 개수 취약점 별 보고 개수 26 취약점 보고 개수 25 LFI 1 RFI 1 20 Directory Traversal 1 SQL Injection 7 15 XSS 26 총합계 36 10 7 5 1 1 1 0 LFI RFI Directory Traversal SQL Injection XSS 2. 위험도별 분류 위험도 별 분류 위험도 보고 개수 백분율 상 2 5.56% 2 중 34 94.44% 합계 36 100.00% 상 중 34 3. 공격 난이도 별 현황 공격 난이도 보고 개수 백분율 공격 난이도 별 현황 상 2 5.56% 중 1 2.78% 하 33 91.67% 2 1 총합계 36 100.00% 상 중 하 33 4. -

Implementación Basada En Software
Implementación basada en software libre de un portal web para apoyo en el proceso colaborativo de desarrollo de un videojuego para la enseñanza de la ingeniería de software 1 Francisco Ismael Maya-Sarasty & Daniel Arenas-Seleey Facultad de Ingeniería, Universidad Autónoma de Bucaramanga, Bucaramanga, Colombia. [email protected], [email protected] Resumen— Este documento presenta la implantación de un sistema de de un videojuego, partiendo de una investigación realizada en software libre alrededor del desarrollo de un videojuego educativo que la Universidad Autónoma de Bucaramanga que construyó un promueve la enseñanza de la Ingeniería de Software. Empezando con la realización de un análisis concienzudo de las características del software modelo para la educación de la Ingeniería de Software. A través necesario para crear un entorno que favorece el trabajo colaborativo de la lectura de ésta y otras investigaciones se crea un portal multidisciplinario, para luego instalar y configurar las soluciones seleccionadas web que se convierte en el sustento conceptual e informativo y terminar con un análisis del cumplimiento de directrices de usabilidad para para garantizar la continuidad del proceso de desarrollo de un portales web y directrices de jugabilidad para videojuegos. La contribución de crear un portal web (www.soengirpg.com) es la videojuego de rol, creando un entorno de compartición del activación del trabajo colaborativo que garantiza la continuidad de la conocimiento a través de la interacción de sus usuarios construcción de un videojuego sobre la Ingeniería de Software. Un sistema que mediante la utilización de foro, wiki, chat y un sistema de integra a todos los actores interesados, que requieren de un entorno donde versiones. -

Ree Croatian Folklore and Folklife Writings on Bosniak Coffee
Conveying Ćeif 1 Conveying Ćeif: -ree Croatian Folklore and Folklife Writings on Bosniak Coffee Culture Dorian Jurić McMaster University Fruitvale, Canada Abstract is article presents three short passages describing coffee and coffeehouse culture among Bosnian and Herzegovinian Muslims in the late nineteenth century. ese texts are Drawn from manuscripts collecteD by lay, Croatian folklore anD folklife collectors wHo submitteD tHem to two early collecting projects in Zagreb. e pieces are translateD Here for tHe first time into EnglisH anD placeD into historical and cultural context regarding the history of coffee culture in Bosnia and Herzegovina and the wider Ottoman Empire as well as the politics of folklore collection at the time. By using tHe Pan-Ottoman concept of ćeif as a theoretical lens, I argue that these early folklorists produced impressive folklife accounts of Bosniak foodways, but that these depictions inevitably enfolded both genuine interest and negative by-products of the wiDer politics of their era. IntroDuction Of all tHe comestibles to transition from localizeD context to global phenomenon, none can claim the same position of influence as coffee. Charting an astronomic trajectory over the course of 500 years, coffee moved from a wilD plant cultivated in modern-day Ethiopia to a global trade item that revolutionized religious observance, social interactions, political process, human rights, city planning, and the nature of labor practices. Fe history of that life-course is a dynamic tapestry of movement through various cultures and chronologies, full of social upHeaval, poetic inspiration, anD tHe vigorous remoDeling of public and private custom. is article is concerneD witH one of tHe earlier campaigns in coffee’s global conquest. -

ROILA : Robot Interaction Language
ROILA : RObot Interaction LAnguage Citation for published version (APA): Mubin, O. (2011). ROILA : RObot Interaction LAnguage. Technische Universiteit Eindhoven. https://doi.org/10.6100/IR712664 DOI: 10.6100/IR712664 Document status and date: Published: 01/01/2011 Document Version: Publisher’s PDF, also known as Version of Record (includes final page, issue and volume numbers) Please check the document version of this publication: • A submitted manuscript is the version of the article upon submission and before peer-review. There can be important differences between the submitted version and the official published version of record. People interested in the research are advised to contact the author for the final version of the publication, or visit the DOI to the publisher's website. • The final author version and the galley proof are versions of the publication after peer review. • The final published version features the final layout of the paper including the volume, issue and page numbers. Link to publication General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal. If the publication is distributed under the terms of Article 25fa of the Dutch Copyright Act, indicated by the “Taverne” license above, please follow below link for the End User Agreement: www.tue.nl/taverne Take down policy If you believe that this document breaches copyright please contact us at: [email protected] providing details and we will investigate your claim. -
Muzikološki Z B O R N I K L Ii /2
MUZIKOLOŠKI ZBORNIK MUSICOLOGICAL ANNUAL L II /2 ZVEZEK/VOLUME L J U B L J A N A 2 0 1 6 Marking the 70th Anniversary of ICTM and 20th Anniversary of CES Folk Slovenia. Music, Sound and Ecology Ob sedemdesetletnici ICTM in dvajsetletnici KED Folk Slovenija. Glasba, zvok in ekologija MZ_2016_2_FINAL.indd 1 8.12.2016 12:28:49 Izdaja • Published by Oddelek za muzikologijo Filozofske fakultete Univerze v Ljubljani Urednik številke • Volume edited by Svanibor Pettan (Ljubljana) Glavni in odgovorni urednik • Editor-in-chief Jernej Weiss (Ljubljana) Asistentka uredništva • Assistant Editor Tjaša Ribizel (Ljubljana) Uredniški odbor • Editorial Board Matjaž Barbo (Ljubljana) Aleš Nagode (Ljubljana) Svanibor Pettan (Ljubljana) Leon Stefanija (Ljubljana) Andrej Rijavec (Ljubljana), častni urednik • honorary editor Mednarodni uredniški svet • International Advisory Board Michael Beckermann (Columbia University, USA) Nikša Gligo (University of Zagreb, Croatia) Robert S. Hatten (Indiana University, USA) David Hiley (University of Regensburg, Germany) Thomas Hochradner (Mozarteum Salzburg, Austria) Bruno Nettl (University of Illinois, USA) Helmut Loos (University of Leipzig, Germany) Jim Samson (Royal Holloway University of London, UK) Lubomír Spurný (Masaryk University Brno, Czech Republic) Katarina Tomašević (Serbian Academy of Sciences and Arts, Serbia) John Tyrrell (Cardiff University, UK) Michael Walter (University of Graz, Austria) Uredništvo • Editorial Address Oddelek za muzikologijo Filozofska fakulteta Aškerčeva 2, SI-1000 Ljubljana, Slovenija -
Read PDF / Free Web Development Software ^ FVXD5G4WJ9FJ
JFULEKUCPAMS # Doc # Free web development software Free web development software Filesize: 9.56 MB Reviews Thorough guide for pdf enthusiasts. Better then never, though i am quite late in start reading this one. Its been printed in an remarkably simple way which is only soon after i finished reading through this pdf by which really altered me, change the way i believe. (Dr. Rowena Wiegand) DISCLAIMER | DMCA FBOSGSKKMM36 ~ PDF # Free web development software FREE WEB DEVELOPMENT SOFTWARE To download Free web development soware PDF, you should follow the button below and save the ebook or have access to additional information which might be relevant to FREE WEB DEVELOPMENT SOFTWARE book. Reference Series Books LLC Okt 2014, 2014. Taschenbuch. Condition: Neu. Neuware - Source: Wikipedia. Pages: 120. Chapters: Free HTML editors, Open source content management systems, PHP-Nuke, Zope, Slash, Drupal, MediaWiki, TkWWW, NetBeans, WordPress, Moodle, Web2py, SeaMonkey, SOBI2, Mambo, Midgard, Joomla, DotNetNuke, Aptana, SilverStripe, Eclipse, TWiki, MindTouch Deki, Plone, Kohana, Zend Framework, Cyn.in, Sakai Project, WorldWideWeb, Movable Type, Tiki Wiki CMS Groupware, Notepad++, TYPO3, OcPortal, Habari, Umbraco, CMS Made Simple, Phire CMS, Amaya, XOOPS, Textpattern, Plumi, Magnolia, Geeklog, PmWiki, PhpWebSite, TinyMCE, EZ Publish, Squiz, WaveMaker, Kajona, JEdit, ImpressCMS, Alfresco, VIVO, Scoop, BEdita, WikkaWiki, WebGUI, RenovatioCMS, MODx, Frog CMS, SharpForge, MojoMojo, E107, Exponent CMS, SPIP, Concrete5, Group-Oice, Quanta Plus, Agorum