UNIVERSITY of CALIFORNIA RIVERSIDE Modeling
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
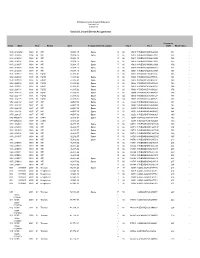
Vehicle List and Driver Assignments
Effingham County Board of Education Vehicle List 6/30/2013 Vehicle List and Driver Assignments Insurance Veh# Make Year Model Cost Assigned Driver/Location Tag # Vin # Car# Book Value 940 L0163292 1994 94 INT 39,994.15 Spare BB 66 15915 1HVBBACNXSH623821 151 - 941 L016393 1994 94 INT 39,994.15 Spare BB 66 15916 1HVBBACN1SH623822 153 - 942 L016394 1994 94 INT 39,994.15 BB 66 15917 1HVBBACN3SH623823 152 - 944 L016396 1994 94 INT 39,994.15 Spare BB 66 15918 1HVBBACN7SH623825 155 - 945 L016397 1994 94 INT 39,994.15 Spare BB 66 15919 1HVBBACN9SH623826 156 - 946 L016398 1994 94 INT 39,994.15 Spare BB 66 15920 1HVBBACNOSH623827 158 - 947 L016399 1994 94 INT 39,994.15 Spare BB 66 15921 1HVBBACN2SH623828 157 - 951 L020327 1995 95 FORD 41,995.62 BB 66 15923 1FDXB80C1SVA75535 165 - 952 L020328 1995 95 FORD 41,995.62 Spare BB 66 15924 1FDXB80C3SVA75536 164 - 953 L020329 1995 95 FORD 41,995.62 Spare BB 66 15925 1FDXB80C5SVA75537 168 - 954 L020330 1995 95 FORD 41,995.62 Spare BB 66 15926 1FDXB80CXSVA79843 169 - 956 L020332 1995 95 FORD 41,995.62 Spare BB 66 15928 1FDXB80C8SVA76228 166 - 962 L024118 1996 96 FORD 41,995.62 Spare BB 66 15963 1FDXB80C5VVA03628 176 - 963 L024119 1996 96 FORD 41,995.62 Spare BB 66 15964 1FDXB80C7VVA03629 175 - 964 L024117 1996 96 FORD 41,995.62 Spare BB 54 15965 1FDXB80C3VVA03627 177 - 965 L024116 1996 96 FORD 41,995.62 Spare BB 54 15966 1FDXB80C1VVA03626 178 - 970 L028102 1997 97 INT 44,597.30 Spare BB 66 16029 1HVBBABN8VH496962 181 - 971 L028103 1997 97 INT 44,597.30 Spare BB 66 16048 1HVBBABNXVH496963 182 - 973 L028105 -

A File in the Online Version of the Kouroo Contexture (Approximately
SETTING THE SCENE FOR THOREAU’S POEM: YET AGAIN WE ATTEMPT TO LIVE AS ADAM 11th Century 1010s 1020s 1030s 1040s 1050s 1060s 1070s 1080s 1090s 12th Century 1110s 1120s 1130s 1140s 1150s 1160s 1170s 1180s 1190s 13th Century 1210s 1220s 1230s 1240s 1250s 1260s 1270s 1280s 1290s 14th Century 1310s 1320s 1330s 1340s 1350s 1360s 1370s 1380s 1390s 15th Century 1410s 1420s 1430s 1440s 1450s 1460s 1470s 1480s 1490s 16th Century 1510s 1520s 1530s 1540s 1550s 1560s 1570s 1580s 1590s 17th Century 1610s 1620s 1630s 1640s 1650s 1660s 1670s 1680s 1690s 18th Century 1710s 1720s 1730s 1740s 1750s 1760s 1770s 1780s 1790s 19th Century 1810s Alas! how little does the memory of these human inhabitants enhance the beauty of the landscape! Again, perhaps, Nature will try, with me for a first settler, and my house raised last spring to be the oldest in the hamlet. To be a Christian is to be Christ- like. VAUDÈS OF LYON 1600 William Gilbert, court physician to Queen Elizabeth, described the earth’s magnetism in DE MAGNETE. Robert Cawdrey’s A TREASURIE OR STORE-HOUSE OF SIMILES. Lord Mountjoy assumed control of Crown forces, garrisoned Ireland, and destroyed food stocks. O’Neill asked for help from Spain. HDT WHAT? INDEX 1600 1600 In about this year Robert Dudley, being interested in stories he had heard about the bottomlessness of Eldon Hole in Derbyshire, thought to test the matter. George Bradley, a serf, was lowered on the end of a lengthy rope. Dudley’s little experiment with another man’s existence did not result in the establishment of the fact that holes in the ground indeed did have bottoms; instead it became itself a source of legend as spinners would elaborate a just-so story according to which serf George was raving mad when hauled back to the surface, with hair turned white, and a few days later would succumb to the shock of it all. -

Electric Actuators Vsi-1000 Series
ELECTRIC ACTUATORS TM VSI-1000 SERIES DESCRIPTION VSI-1000 Series Electric Actuators are used on Kele KBV Series butterfly valves to provide two-position (with or without battery backup) or proportional control in a NEMA 4X housing. The VSI-1000 Series comes standard on 8" and larger non-spring return assemblies and on 5" and larger two- position spring return assemblies. They can be ordered on smaller valve assemblies as an option. Standard fea- tures include 2 SPDT fully adjustable auxiliary switches KBV-2-6-E2SO (two-position only), manual override crank, and an inter- assembly includes nal heater to prevent condensation in outdoor installa- VSI-BB1020 actuator tions. SPECIFICATIONS FEATURES Power 120 VAC standard •Lightweight, compact design Models 1005 to 1020 12/24 VDC optional • Two-position or modulating control Models 1005 to 1040 24 VAC optional • Two-position battery-backed models Torque range 347-17,359 in-lb • NEMA 4X watertight, corrosion-resistant housing Motor 120 VAC, 1 phase, 60 Hz; • Integral position indicator enclosed, non-ventilated, high • Space heater standard starting torque, reversible induc- • Two 1/2" conduit connections tion, Class E insulation • Detachable manual override crank Thermal overload Auto reset, embedded • Terminal strip wiring Travel limit switches Cam operated, adjustable SPDT • Worm gear drive, no electro-mechanical brake for open/close stop required • Mounting orientation in any direction Position indicator High-visibility graduated dial • 4-20 mA or 500Ω optional feedback signal Conduit connections -

3.2 Precipitation Or Dry-Wet Reconstructions
Climate change in China during the past 2000 years: An overview Ge Quansheng , Zheng Jingyun Institute of Geographic Sciences and Natural Resources Research, Chinese Academy of Sciences, Beijing 100101, China Email: [email protected] Outline 1 Introduction 2 Historical Documents as Proxy 3 Reconstructions and Analyses 4 Summary and Prospects 1. Introduction: E Asia2K Climate System Socio-economic System •typical East Asian •dense population and rapid monsoon climate economic development • significant seasonal and • be susceptible to global inter-annual and inter- warming and extreme decadal variability climate events Climate change study in the past 2ka in East Asian is both beneficial and advantageous. • various types of natural proxy • Plenty of historical documents Fig. Active regional working groups under as proxy the past 2ka theme (PAGES 2009) 2. Historical Documents as Proxy Type Period Amount Chinese classical 1,531 kinds, 137 BC~1470 AD documents 32,251 volumes More than 8,000 1471~1911 (The Ming Local gazettes books (部), 110, and Qing Dynasty) 000 volumes Memos to the About 120,000 1736~1911 emperor pieces Archives of the 1912~1949 20,000 volumes Republic of China More than 200 Private diaries 1550~ books (部) Chinese classical documents AD 833, North China plain: Extreme drought event was occurred, crops were shriveling, no yields, people were in hungry…. Fig. Example for Ancient Chinese writings Local gazettes The 28th year of the Daoguang reign (1848 AD), the 6th (lunar) month, strong wind and heavy rain, the Yangtze River overflowed; the 7th month, strong wind Fig. Gazettes of Yangzhou Prefecture and thunder storm, field published in 1874 AD and houses submerged. -

Series 1000 Electric Actuators Series 1000 Electric Actuators Design Features
SERIES 1000 ELECTRIC ACTUATORS SERIES 1000 ELECTRIC ACTUATORS DESIGN FEATURES Series 1000 On-Off Rotary Electric Actuator Basic Actuator: Torque Output Range: 347in-lb to 17,359in-lb Housing: NEMA 4X, watertight, corrosion-resistant, robust aluminum die cast Electric Motor: 10VAC, single phase, 60Hz totally enclosed, non-ventilated, high starting torque, reversible induction type, Class F insulation Thermal Overload Motor Protection: Auto reset thermal switch embedded in the motor winding - trips when the maximum winding temperature is exceded Position Limit Switches: x SPDT for Open and Close travel limit - easily adjustable, cam operated Position Indicator: Mechanical dome type with visiable red/yellow closed/open indicator Terminal Strip: Refer to wiring diagrams for details Conduit Entries: 1 x 1/” NPT for power and control wiring Power Gears: Alloy steel spur gears to final stage aluminum bronze worm sector gear Break: An electro-mechanical brake is NOT required. The worm gear drive prevents back driving and hunting Bearings: High quality alloy steel sleeve and ball bearings Manual Override: Handle Adjustable Mechanical Stops Ambient Temperature Range: -31°F to +150°F Certification and Approvals:CE, NEMA4, CSA, NRTL Internal Heater Optional Features • 0V AC/1/50-60Hz power • 1/4V DC 1005 through 100 • Torque Limit Switches for Close direction of travel • Feedback Potentiometer - 1000ohm • DeClutchable Handwheel Override SERIES 1000 ELECTRIC ACTUATORS ON-OFF SPECIFICATIONS Series 1000 On-Off Actuator Specifications Model 1005 1010 1020 1040 1060 1100 1150 1200 Output Torque(in-lb) 347 868 1736 347 508 8680 13,019 17,359 Output Torque(Nm) 39.3 98.06 196.13 39.7 588.4 980.66 1471 1961.3 Duty Cycle 75% 75% 50% 50% 50% 50% 50% 50% Travel Speed at 5 5 5 5 50 50 50 50 60Hz(Sec) Maximum Current .35/.18 .41/. -

Legitimacy Through Literature: Political
LEGITIMACY THROUGH LITERATURE: POLITICAL CULTURE IN EARLY- ELEVENTH-CENTURY ROUEN A Dissertation Presented to the Faculty of the Graduate School of Cornell University in Partial Fulfillment of the Requirements of the Degree of Doctor of Philosophy by Corinna MaxineCarol Matlis May 2017 © 2017 Corinna MaxineCarol Matlis LEGITIMACY THROUGH LITERATURE: POLITICAL CULTURE IN EARLY- ELEVENTH-CENTURY ROUEN Corinna Maxine Carol Matlis Cornell University 2017 This dissertation examines the interplay between early-eleventh-century Norman literature and the Norman ducal family’s project of establishing its legitimacy to rule. The dissertation considers Dudo of Saint Quentin’s arcane history of the Norman dukes, Warner of Rouen’s two esoteric satires, and two further anonymous satires produced in Rouen c. 996-1026 (the reign of Duke Richard II). These works constitute the secular Norman literature during this period. Although the texts’ audiences are unknown, it is clear that the ducal family, local clerics, and potentially nobility throughout the region and France were among the works’ addressees. Despite their obscurity to modern readers, these texts spoke to the interests of the highest echelons of Norman society. Throughout my dissertation, I show how these texts were understood in their own time and how they spoke to contemporary social and political issues. Common themes emerge throughout the texts, despite their different genres: most importantly, the ducal family’s strategic marriages, and the desire for the appearance of a cultured court in order to balance the Normans’ reputation of physical might. Reading these Rouennais texts together offers new views of Norman political culture that have not been available without a close look at this literature as a whole. -

A Standardizing Process in Anglo-Saxon England
Loyola University Chicago Loyola eCommons Dissertations Theses and Dissertations 2015 Unius Regulae Ac Unius Patriae: A Standardizing Process in Anglo-Saxon England Daniel Matteuzzi O'gorman Loyola University Chicago Follow this and additional works at: https://ecommons.luc.edu/luc_diss Part of the Medieval History Commons Recommended Citation O'gorman, Daniel Matteuzzi, "Unius Regulae Ac Unius Patriae: A Standardizing Process in Anglo-Saxon England" (2015). Dissertations. 1485. https://ecommons.luc.edu/luc_diss/1485 This Dissertation is brought to you for free and open access by the Theses and Dissertations at Loyola eCommons. It has been accepted for inclusion in Dissertations by an authorized administrator of Loyola eCommons. For more information, please contact [email protected]. This work is licensed under a Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 License. Copyright © 2015 Daniel Matteuzzi O'gorman LOYOLA UNIVERSITY CHICAGO UNIUS REGULAE AC UNIUS PATRIAE: A STANDARDIZING PROCESS IN ANGLO-SAXON ENGLAND A DISSERTATION SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL IN CANDIDACY FOR THE DEGREE OF DOCTOR OF PHILOSOPHY PROGRAM IN HISTORY BY DANIEL M. O’GORMAN CHICAGO, IL MAY 2015 Copyright by Daniel M. O’Gorman, 2015 All rights reserved. ACKNOWLEDGEMENTS I would first of all like to thank Barbara Rosenwein, my advisor, for her dedication, patience and advice in the process of writing this dissertation. Without her support this process would not have been possible. Thank you to my committee members, Theresa Gross-Diaz, who took it upon herself to enable me to attend the Levison Memorial Conference in Durham; Leslie Dossey, whose questions opened up hitherto unforeseen aspects of this topic; and Allen Frantzen, who first broached the notion of my writing on ‘standards.’ Your guidance and expertise has been invaluable. -

Race, Class, Gender and Community College Persistence
Portland State University PDXScholar Dissertations and Theses Dissertations and Theses Spring 5-28-2014 Mediating Academic Success: Race, Class, Gender and Community College Persistence Schaylee Marie Esparza Portland State University Follow this and additional works at: https://pdxscholar.library.pdx.edu/open_access_etds Part of the Sociology Commons Let us know how access to this document benefits ou.y Recommended Citation Esparza, Schaylee Marie, "Mediating Academic Success: Race, Class, Gender and Community College Persistence" (2014). Dissertations and Theses. Paper 2019. https://doi.org/10.15760/etd.2018 This Thesis is brought to you for free and open access. It has been accepted for inclusion in Dissertations and Theses by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. Mediating Academic Success: Race, Class, Gender and Community College Persistence by Schaylee Marie Esparza A thesis submitted in partial fulfillment of the requirements for the degree of Master of Arts in Sociology Thesis Committee: José Padín, Chair Peter Collier Maura Kelly Portland State University 2014 © 2014 Schaylee Marie Esparza ABSTRACT Over the last forty years, the U.S. community college system has expanded, allowing disadvantaged groups greater access to higher education. With that expansion, a body of research has emerged examining community college students’ educational outcomes. However, the research is limited in understanding the academic persistence of low-income students and community college student in particular. The purpose of this comparative, qualitative study is to explore some of the unanswered questions about how low income white and Latino students’ experience academic persistence similarly and differently and understand how gender influences the challenges students may face during college. -

Life and Cult of Cnut the Holy the First Royal Saint of Denmark
Life and cult of Cnut the Holy The first royal saint of Denmark Edited by: Steffen Hope, Mikael Manøe Bjerregaard, Anne Hedeager Krag & Mads Runge Life and cult of Cnut the Holy The first royal saint of Denmark Life and cult of Cnut the Holy The first royal saint of Denmark Report from an interdisciplinary research seminar in Odense. November 6th to 7th 2017 Edited by: Steffen Hope, Mikael Manøe Bjerregaard, Anne Hedeager Krag & Mads Runge Kulturhistoriske studier i centralitet – Archaeological and Historical Studies in Centrality, vol. 4, 2019 Forskningscenter Centrum – Odense Bys Museer Syddansk Univeristetsforlag/University Press of Southern Denmark Report from an interdisciplinary research seminar in Odense. November 6th to 7th 2017 Published by Forskningscenter Centrum – Odense City Museums – University Press of Southern Denmark ISBN: 9788790267353 © The editors and the respective authors Editors: Steffen Hope, Mikael Manøe Bjerregaard, Anne Hedeager Krag & Mads Runge Graphic design: Bjørn Koch Klausen Frontcover: Detail from a St Oswald reliquary in the Hildesheim Cathedral Museum, c. 1185-89. © Dommuseum Hildesheim. Photo: Florian Monheim, 2016. Backcover: Reliquary containing the reamains of St Cnut in the crypt of St Cnut’s Church. Photo: Peter Helles Eriksen, 2017. Distribution: Odense City Museums Overgade 48 DK-5000 Odense C [email protected] www.museum.odense.dk University Press of Southern Denmark Campusvej 55 DK-5230 Odense M [email protected] www.universitypress.dk 4 Content Contributors ...........................................................................................................................................6 -

North American Cylinder
Section 2 Key Blanks dNesOigRneTd fHor loAckMs uEseRdIpCrimAaNrily Cin tYheLNIoNrthDAEmR erican Market. The lock manufacturers are listed in alphabetical order where possible. There are several symbols and suffixes used in this section. Below is a legend of their use. Special Key Machine Required Color Plastic Head Key -PC ACE - ALMET ACE ACORN ADAMS RITE N O R C T Y H L A I N M D E E R R I OD .377" - 9.6mm C ID .312"- 7.9mm A N (BRASS) ILCO 1137B A54B 999 Y1-PC 1054WB EZ — — Y1 — WR3 sec page ADAMS RITE ALMET 2 1 ILCO D1054K DE6-PC L1054B K1145 AE1 EZ DE6 — IN8 — — ALMET ILCO 1145A 1177N 1179 AR1-PC N1179 EZ SC4 NH1 AR1 — — ALMET - ARFE ALMET AMERICAN LOCK 1041CK — 1041CE — N A C I R R E E D M N I A L H Y T C R O N 5 PIN 6 PIN 1179A 1041B 1041C 1045 A1045 ILCO AR4 — AM1 AM3 — EZ sec page 2 2 AMERICAN LOCK AMEROCK A1041U 5 PIN 6 PIN 1046 1046A 1653 AK22W R1064E NA25-PC ILCO —— AM4 — NA25 — EZ ARCO ARFE 1130 1130R 1131 1131R 1635J 1635K 1635L 1635V ILCO —— —— — — — — EZ ARROW - BALDWIN ARROW N O R C T Y H L A I N M D E E R R I C A N 5 PIN 6 PIN ILCO DT22W DTL22W 755U 1179 AR1-PC N1179 EZ ——— AR1 — — sec page ARROW 2 3 A1179F A1179K A1179R A1179V ———— A1179G A1179L A1179S ——— A1179H A1179N A1179T ——— ILCO 1179A N1179A A1179E A1179J A1179P A1179U EZ AR4 — — ——— ARROW AUTH FLORENCE BALDWIN 5 PIN 6 PIN 5 PIN 6 PIN ILCO B1179-1C B1179-1D CH1C CH1D 1652 1510 1511 EZ — — — — AF1 BW2 — BARGMAN - BELLEVILLE BARGMAN BARROWS K1054B IN24 K1122B N — A C I R R E E D M N I A K1122C L — H Y T C R O N L1054M K1122N L1098M K1122D 1761B 1021A ILCO — — — BN1 — — EZ sec page 2 4 BARROWS BAUER 1021B 1021BA 1021N 1618 1618R ILCO — — — BAU1 BAU1R EZ BAUER BELLEVILLE 1648 1036 1036A 1036G 1036S ILCO BAU2 — — — — EZ BELLEVILLE - BEST BELLEVILLE BEST N O R C T Y H L A I N M D E E R R I C A N ILCO 1036SF 1036U 1114 A1114A A1114B A1114C EZ — — — BE2 — — sec page BEST 2 5 ILCO A1114D A1114DD A1114E A1114F A1114FM A1114G EZ — — — — — — BEST ILCO A1114H A1114J A1114K A1114L A1114M A1114Q EZ — — — — — — BEST - CHALLENGER BEST BOMMER CAM LOCK CANADIAN BLDR. -

Fleet Catalog Revision
Table of Contents ABC Body Quick Reference (Aluminum Body Corp.) 4 A. M. Haire Quick Reference 8 American Commercial Quick Reference (America’s 14 Body Company.) Babb Quick Reference 19 Continental Quick Reference 25 Delta FZ/Gindy/Vanco Quick Reference 29 Duralite Quick Reference 39 Grumman Quick Reference 45 Grumman V-Body Quick Reference 55 Jannell Quick Reference 60 Kidron Quick Reference 64 Marathon/Metro/Satellite Quick Reference 73 Mickey Quick Reference 78 Modern Wagon Quick Reference 84 Morgan Quick Reference 88 Supreme Quick Reference 106 Supreme Signature Series Quick Reference 121 U.S. Truck Body Quick Reference 125 Utilimaster Quick Reference 135 Top Rails 145 Bottom Rails 154 Rub Rails & End Caps 160 Posts 163 Connectors 170 Roof Bows 173 1 Table of Contents (Continued) Aluminum Castings 179 Aluminum Extrusions 204 Radius Posts & Panels 231 Steel Parts 240 Fiberglass Caps 257 Roll Up Doors & Parts 263 Rubber Dock Bumpers, Door Bumpers & Wheel 272 Chocks Hardware & Fasteners 283 Bumpers 284 Miscellaneous 297 Flooring 322 Ramps & Parts 324 Lights, Mirrors, Reflectors, Light Boxes 330 Lift Gate Parts 337 Tools & Equipment 341 Index 344 2 General Information The VIN number of a vehicle contains a code digit at the tenth place that identifies the year of manufacture. xxxxxxxxxXxxxxxxx B=1981 L=1990 X=1999 8=2008 C=1982 M=1991 Y=2000 9=2009 D=1983 N=1992 1=2001 A=2010 E=1984 P=1993 2=2002 B=2011 F=1985 R=1994 3=2003 C=2012 G=1986 S=1995 4=2004 D=2013 H=1987 T=1996 5=2005 E=2014 J=1988 V=1997 6=2006 F=2015 K=1989 W=1998 7=2007 G=2016 3 ABC Body Parts Quick Reference Guide (Aluminum Body Corp.) 4 Notes: Aluminum Body Corporation DISCLAIMER USE OF OEM OR MANUFACTURERS’ NAME AND/OR PART NUMBERS IS FOR IDENTIFICATION PURPOSES AND SIMPLIFICATION ONLY AND IN NO WAY IS MEANT TO IMPLY THAT FLEET PARTS’ ITEMS ARE AUTHORIZED OR IN ANY WAY AFFILIATED WITH THOSE MANUFACTURERS. -

Timetable 0T9NAAT
Cardiff Airport - Cardiff Service T9 (TCAT009) Bank Holiday Mondays (Inbound) Timetable valid from 7th October 2019 until further notice Operator: NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT Cardiff Airport (Terminal) 0010 0450 0510 0530 0550 0610 0630 0650 0710 0730 0750 0810 0830 0850 0910 0930 0950 1010 1030 Copthorne Hotel (Rhur Cross, Port Road) 0022s 0502s 0522s 0542s 0602s 0622s 0642s 0702s 0722s 0742s 0802s 0822s 0842s 0902s 0922s 0942s 1002s 1022s 1042s Cardiff Bay (Red Dragon Centre) 0040s 0520s 0540s 0600s 0620s 0640s 0700s 0720s 0740s 0800s 0820s 0840s 0900s 0920s 0940s 1000s 1020s 1040s 1100s Cardiff City Centre (Canal St) (Arr) 0045s 0525s 0545s 0605s 0625s 0645s 0705s 0725s 0745s 0805s 0825s 0845s 0905s 0925s 0945s 1005s 1025s 1045s 1105s Cardiff City Centre (Canal St) (Dep) -- 0530s 0550s 0610s 0630s 0650s 0710s 0730s 0750s 0810s 0830s 0850s 0910s 0930s 0950s 1010s 1030s 1050s 1110s Cardiff Centrail Rail Station -- 0531s 0551s 0611s 0631s 0651s 0711s 0731s 0751s 0811s 0831s 0851s 0911s 0931s 0951s 1011s 1031s 1051s 1111s Operator: NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT NADT Cardiff Airport (Terminal) 1050 1110 1130 1150 1210 1230 1250 1310 1330 1350 1410 1430 1450 1510 1530 1550 1610 1630 1650 Copthorne Hotel (Rhur Cross, Port Road) 1102s 1122s 1142s 1202s 1222s 1242s 1302s 1322s 1342s 1402s 1422s 1442s 1502s 1522s 1542s 1602s 1622s 1642s 1702s Cardiff Bay (Red Dragon Centre) 1120s 1140s 1200s 1220s 1240s 1300s 1320s 1340s