Gene Expression Predictors of Breast Cancer Outcomes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Imm Catalog.Pdf
$ Gene Symbol A B 3 C 4 D 9 E 10 F 11 G 12 H 13 I 14 J. K 17 L 18 M 19 N 20 O. P 22 R 26 S 27 T 30 U 32 V. W. X. Y. Z 33 A ® ® Gene Symbol Gene ID Antibody Monoclonal Antibody Polyclonal MaxPab Full-length Protein Partial-length Protein Antibody Pair KIt siRNA/Chimera Gene Symbol Gene ID Antibody Monoclonal Antibody Polyclonal MaxPab Full-length Protein Partial-length Protein Antibody Pair KIt siRNA/Chimera A1CF 29974 ● ● ADAMTS13 11093 ● ● ● ● ● A2M 2 ● ● ● ● ● ● ADAMTS20 80070 ● AACS 65985 ● ● ● ADAMTS5 11096 ● ● ● AANAT 15 ● ● ADAMTS8 11095 ● ● ● ● AATF 26574 ● ● ● ● ● ADAMTSL2 9719 ● AATK 9625 ● ● ● ● ADAMTSL4 54507 ● ● ABCA1 19 ● ● ● ● ● ADAR 103 ● ● ABCA5 23461 ● ● ADARB1 104 ● ● ● ● ABCA7 10347 ● ADARB2 105 ● ABCB9 23457 ● ● ● ● ● ADAT1 23536 ● ● ABCC4 10257 ● ● ● ● ADAT2 134637 ● ● ABCC5 10057 ● ● ● ● ● ADAT3 113179 ● ● ● ABCC8 6833 ● ● ● ● ADCY10 55811 ● ● ABCD2 225 ● ADD1 118 ● ● ● ● ● ● ABCD4 5826 ● ● ● ADD3 120 ● ● ● ABCG1 9619 ● ● ● ● ● ADH5 128 ● ● ● ● ● ● ABL1 25 ● ● ADIPOQ 9370 ● ● ● ● ● ABL2 27 ● ● ● ● ● ADK 132 ● ● ● ● ● ABO 28 ● ● ADM 133 ● ● ● ABP1 26 ● ● ● ● ● ADNP 23394 ● ● ● ● ABR 29 ● ● ● ● ● ADORA1 134 ● ● ACAA2 10449 ● ● ● ● ADORA2A 135 ● ● ● ● ● ● ● ACAN 176 ● ● ● ● ● ● ADORA2B 136 ● ● ACE 1636 ● ● ● ● ADRA1A 148 ● ● ● ● ACE2 59272 ● ● ADRA1B 147 ● ● ACER2 340485 ● ADRA2A 150 ● ● ACHE 43 ● ● ● ● ● ● ADRB1 153 ● ● ACIN1 22985 ● ● ● ADRB2 154 ● ● ● ● ● ACOX1 51 ● ● ● ● ● ADRB3 155 ● ● ● ● ACP5 54 ● ● ● ● ● ● ● ADRBK1 156 ● ● ● ● ACSF2 80221 ● ● ADRM1 11047 ● ● ● ● ACSF3 197322 ● ● AEBP1 165 ● ● ● ● ACSL4 2182 ● -

Cleveland Clinic Laboratories
Cleveland Clinic Laboratories Technical Update • May 2014 Cleveland Clinic Laboratories is dedicated to keeping you updated and informed about recent testing changes. That's why we are happy to provide this technical update on a monthly basis. Recently changed tests are bolded, and could include revisions to methodology, reference range, days performed or CPT code. For your convenience, tests are listed alphabetically and the order and billing codes are provided. If you wish to compare the new information with previous test demographics, refer to the Test Directory, which can be accessed at clevelandcliniclabs.com. Deleted tests and new tests are listed separately. Please update your database as necessary. For additional detail, contact Client Services at 216.444.5755 or 800.628.6816 or via email at [email protected]. Days Performed/Reported Specimen Requirement Special InformationComponent Change Test Discontinued Reference Range Test Update Name Change Methodology Order CodeBiling Code New Test Page # Summary of Changes CPT by Test Name 3 5-Hydroxyindolacetic Acid, Urine 3 11-Deoxycorticosterone Qt, Serum / Plasma 3 25-Hydroxyvitamin D2 and D3, Serum 9 Alpha-1 Antitrypsin (SERPINA1) Targeted Genotyping 3 Alpha-1-Antitrypsin Clearance 3 Alpha-1-Antitrypsin, Stool 3 Anti IgA Antibody 3 Anti Mullerian Hormone 3 Beta Galactosidase, Leukocytes 4 Bioavailable Testosterone / SHBG, Female & Child 4 BK Virus Quantitation, Urine 12 Buprenorphine & Metabolite, Confirmation / Quant, Urine 9 Buprenorphine Quant, Urine 4 Carnitine Free & Total, -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Genes in Eyecare Geneseyedoc 3 W.M
Genes in Eyecare geneseyedoc 3 W.M. Lyle and T.D. Williams 15 Mar 04 This information has been gathered from several sources; however, the principal source is V. A. McKusick’s Mendelian Inheritance in Man on CD-ROM. Baltimore, Johns Hopkins University Press, 1998. Other sources include McKusick’s, Mendelian Inheritance in Man. Catalogs of Human Genes and Genetic Disorders. Baltimore. Johns Hopkins University Press 1998 (12th edition). http://www.ncbi.nlm.nih.gov/Omim See also S.P.Daiger, L.S. Sullivan, and B.J.F. Rossiter Ret Net http://www.sph.uth.tmc.edu/Retnet disease.htm/. Also E.I. Traboulsi’s, Genetic Diseases of the Eye, New York, Oxford University Press, 1998. And Genetics in Primary Eyecare and Clinical Medicine by M.R. Seashore and R.S.Wappner, Appleton and Lange 1996. M. Ridley’s book Genome published in 2000 by Perennial provides additional information. Ridley estimates that we have 60,000 to 80,000 genes. See also R.M. Henig’s book The Monk in the Garden: The Lost and Found Genius of Gregor Mendel, published by Houghton Mifflin in 2001 which tells about the Father of Genetics. The 3rd edition of F. H. Roy’s book Ocular Syndromes and Systemic Diseases published by Lippincott Williams & Wilkins in 2002 facilitates differential diagnosis. Additional information is provided in D. Pavan-Langston’s Manual of Ocular Diagnosis and Therapy (5th edition) published by Lippincott Williams & Wilkins in 2002. M.A. Foote wrote Basic Human Genetics for Medical Writers in the AMWA Journal 2002;17:7-17. A compilation such as this might suggest that one gene = one disease. -

Expression Profiling of Ion Channel Genes Predicts Clinical Outcome in Breast Cancer
UCSF UC San Francisco Previously Published Works Title Expression profiling of ion channel genes predicts clinical outcome in breast cancer Permalink https://escholarship.org/uc/item/1zq9j4nw Journal Molecular Cancer, 12(1) ISSN 1476-4598 Authors Ko, Jae-Hong Ko, Eun A Gu, Wanjun et al. Publication Date 2013-09-22 DOI http://dx.doi.org/10.1186/1476-4598-12-106 Peer reviewed eScholarship.org Powered by the California Digital Library University of California Ko et al. Molecular Cancer 2013, 12:106 http://www.molecular-cancer.com/content/12/1/106 RESEARCH Open Access Expression profiling of ion channel genes predicts clinical outcome in breast cancer Jae-Hong Ko1, Eun A Ko2, Wanjun Gu3, Inja Lim1, Hyoweon Bang1* and Tong Zhou4,5* Abstract Background: Ion channels play a critical role in a wide variety of biological processes, including the development of human cancer. However, the overall impact of ion channels on tumorigenicity in breast cancer remains controversial. Methods: We conduct microarray meta-analysis on 280 ion channel genes. We identify candidate ion channels that are implicated in breast cancer based on gene expression profiling. We test the relationship between the expression of ion channel genes and p53 mutation status, ER status, and histological tumor grade in the discovery cohort. A molecular signature consisting of ion channel genes (IC30) is identified by Spearman’s rank correlation test conducted between tumor grade and gene expression. A risk scoring system is developed based on IC30. We test the prognostic power of IC30 in the discovery and seven validation cohorts by both Cox proportional hazard regression and log-rank test. -

Mucin Family Genes Are Downregulated in Colorectal
ooggeenneessii iinn ss && rrcc aa MM CC uu tt ff aa Journal ofJournal of oo gg Aziz et al., J Carcinogene Mutagene 2014, S10 ll ee ee aa aa nn nn nn nn ee ee rr rr ss ss uu uu ii ii ss ss oo oo DOI: 4172/2157-2518.S10-009 JJ JJ ISSN: 2157-2518 CarCarcinogenesiscinogenesis & Mutagenesis Research Article Article OpenOpen Access Access Mucin Family Genes are Downregulated in Colorectal Cancer Patients Mohammad Azhar Aziz*, Majed AlOtaibi, Abdulkareem AlAbdulrahman, Mohammed AlDrees and Ibrahim AlAbdulkarim Department of Medical Genomics, KIng Abdullah Intl. Med. Res. Ctr., King Saud Bin Abdul Aziz University for Health Sciences, Riyadh, Saudi Arabia Abstract Mucins are very well known to be associated with different types of cancer. Their role in colorectal cancer has been extensively studied without direct correlation with their change in expression levels. In the present study we employed the human exon array from Affymetrix to provide evidence that mucin family genes are downregulated in colorectal cancer tumor samples. We analyzed 92 samples taken from normal and tumor tissues. All mucin family genes except MUCL1 were downregulated with the fold change value ranging from -3.53 to 1.78 as calculated using AltAnalyze software. Maximum drop in RNA transcripts were observed for MUC2 with a fold change of -3.53. Further, we carried out Integromics analysis to analyze mucin genes using hierarchical clustering. MUC1 and MUC4 were found to be potential biomarkers for human colorectal cancer. Top upstream regulators were identified for mucin genes. Network analyses were carried out to further our understanding about potential mechanisms by which mucins can be involved in causing colorectal cancer. -
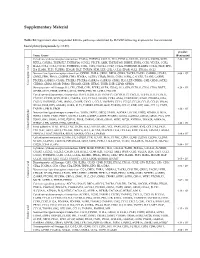
Supplementary Material
Supplementary Material Table S1: Significant downregulated KEGGs pathways identified by DAVID following exposure to five cinnamon- based phenylpropanoids (p < 0.05). p-value Term: Genes (Benjamini) Cytokine-cytokine receptor interaction: FASLG, TNFSF14, CXCL11, IL11, FLT3LG, CCL3L1, CCL3L3, CXCR6, XCR1, 2.43 × 105 RTEL1, CSF2RA, TNFRSF17, TNFRSF14, CCNL2, VEGFB, AMH, TNFRSF10B, INHBE, IFNB1, CCR3, VEGFA, CCR2, IL12A, CCL1, CCL3, CXCL5, TNFRSF25, CCR1, CSF1, CX3CL1, CCL7, CCL24, TNFRSF1B, IL12RB1, CCL21, FIGF, EPO, IL4, IL18R1, FLT1, TGFBR1, EDA2R, HGF, TNFSF8, KDR, LEP, GH2, CCL13, EPOR, XCL1, IFNA16, XCL2 Neuroactive ligand-receptor interaction: OPRM1, THRA, GRIK1, DRD2, GRIK2, TACR2, TACR1, GABRB1, LPAR4, 9.68 × 105 GRIK5, FPR1, PRSS1, GNRHR, FPR2, EDNRA, AGTR2, LTB4R, PRSS2, CNR1, S1PR4, CALCRL, TAAR5, GABRE, PTGER1, GABRG3, C5AR1, PTGER3, PTGER4, GABRA6, GABRA5, GRM1, PLG, LEP, CRHR1, GH2, GRM3, SSTR2, Chlorogenic acid Chlorogenic CHRM3, GRIA1, MC2R, P2RX2, TBXA2R, GHSR, HTR2C, TSHR, LHB, GLP1R, OPRD1 Hematopoietic cell lineage: IL4, CR1, CD8B, CSF1, FCER2, GYPA, ITGA2, IL11, GP9, FLT3LG, CD38, CD19, DNTT, 9.29 × 104 GP1BB, CD22, EPOR, CSF2RA, CD14, THPO, EPO, HLA-DRA, ITGA2B Cytokine-cytokine receptor interaction: IL6ST, IL21R, IL19, TNFSF15, CXCR3, IL15, CXCL11, TGFB1, IL11, FLT3LG, CXCL10, CCR10, XCR1, RTEL1, CSF2RA, IL21, CCNL2, VEGFB, CCR8, AMH, TNFRSF10C, IFNB1, PDGFRA, EDA, CXCL5, TNFRSF25, CSF1, IFNW1, CNTFR, CX3CL1, CCL5, TNFRSF4, CCL4, CCL27, CCL24, CCL25, CCL23, IFNA6, IFNA5, FIGF, EPO, AMHR2, IL2RA, FLT4, TGFBR2, EDA2R, -

Supplementary Table S2
1-high in cerebrotropic Gene P-value patients Definition BCHE 2.00E-04 1 Butyrylcholinesterase PLCB2 2.00E-04 -1 Phospholipase C, beta 2 SF3B1 2.00E-04 -1 Splicing factor 3b, subunit 1 BCHE 0.00022 1 Butyrylcholinesterase ZNF721 0.00028 -1 Zinc finger protein 721 GNAI1 0.00044 1 Guanine nucleotide binding protein (G protein), alpha inhibiting activity polypeptide 1 GNAI1 0.00049 1 Guanine nucleotide binding protein (G protein), alpha inhibiting activity polypeptide 1 PDE1B 0.00069 -1 Phosphodiesterase 1B, calmodulin-dependent MCOLN2 0.00085 -1 Mucolipin 2 PGCP 0.00116 1 Plasma glutamate carboxypeptidase TMX4 0.00116 1 Thioredoxin-related transmembrane protein 4 C10orf11 0.00142 1 Chromosome 10 open reading frame 11 TRIM14 0.00156 -1 Tripartite motif-containing 14 APOBEC3D 0.00173 -1 Apolipoprotein B mRNA editing enzyme, catalytic polypeptide-like 3D ANXA6 0.00185 -1 Annexin A6 NOS3 0.00209 -1 Nitric oxide synthase 3 SELI 0.00209 -1 Selenoprotein I NYNRIN 0.0023 -1 NYN domain and retroviral integrase containing ANKFY1 0.00253 -1 Ankyrin repeat and FYVE domain containing 1 APOBEC3F 0.00278 -1 Apolipoprotein B mRNA editing enzyme, catalytic polypeptide-like 3F EBI2 0.00278 -1 Epstein-Barr virus induced gene 2 ETHE1 0.00278 1 Ethylmalonic encephalopathy 1 PDE7A 0.00278 -1 Phosphodiesterase 7A HLA-DOA 0.00305 -1 Major histocompatibility complex, class II, DO alpha SOX13 0.00305 1 SRY (sex determining region Y)-box 13 ABHD2 3.34E-03 1 Abhydrolase domain containing 2 MOCS2 0.00334 1 Molybdenum cofactor synthesis 2 TTLL6 0.00365 -1 Tubulin tyrosine ligase-like family, member 6 SHANK3 0.00394 -1 SH3 and multiple ankyrin repeat domains 3 ADCY4 0.004 -1 Adenylate cyclase 4 CD3D 0.004 -1 CD3d molecule, delta (CD3-TCR complex) (CD3D), transcript variant 1, mRNA. -

The Correlation of Keratin Expression with In-Vitro Epithelial Cell Line Differentiation
The correlation of keratin expression with in-vitro epithelial cell line differentiation Deeqo Aden Thesis submitted to the University of London for Degree of Master of Philosophy (MPhil) Supervisors: Professor Ian. C. Mackenzie Professor Farida Fortune Centre for Clinical and Diagnostic Oral Science Barts and The London School of Medicine and Dentistry Queen Mary, University of London 2009 Contents Content pages ……………………………………………………………………......2 Abstract………………………………………………………………………….........6 Acknowledgements and Declaration……………………………………………...…7 List of Figures…………………………………………………………………………8 List of Tables………………………………………………………………………...12 Abbreviations….………………………………………………………………..…...14 Chapter 1: Literature review 16 1.1 Structure and function of the Oral Mucosa……………..…………….…..............17 1.2 Maintenance of the oral cavity...……………………………………….................20 1.2.1 Environmental Factors which damage the Oral Mucosa………. ….…………..21 1.3 Structure and function of the Oral Mucosa ………………...….……….………...21 1.3.1 Skin Barrier Formation………………………………………………….……...22 1.4 Comparison of Oral Mucosa and Skin…………………………………….……...24 1.5 Developmental and Experimental Models used in Oral mucosa and Skin...……..28 1.6 Keratinocytes…………………………………………………….….....................29 1.6.1 Desmosomes…………………………………………….…...............................29 1.6.2 Hemidesmosomes……………………………………….…...............................30 1.6.3 Tight Junctions………………………….……………….…...............................32 1.6.4 Gap Junctions………………………….……………….….................................32 -

Appendix 2. Significantly Differentially Regulated Genes in Term Compared with Second Trimester Amniotic Fluid Supernatant
Appendix 2. Significantly Differentially Regulated Genes in Term Compared With Second Trimester Amniotic Fluid Supernatant Fold Change in term vs second trimester Amniotic Affymetrix Duplicate Fluid Probe ID probes Symbol Entrez Gene Name 1019.9 217059_at D MUC7 mucin 7, secreted 424.5 211735_x_at D SFTPC surfactant protein C 416.2 206835_at STATH statherin 363.4 214387_x_at D SFTPC surfactant protein C 295.5 205982_x_at D SFTPC surfactant protein C 288.7 1553454_at RPTN repetin solute carrier family 34 (sodium 251.3 204124_at SLC34A2 phosphate), member 2 238.9 206786_at HTN3 histatin 3 161.5 220191_at GKN1 gastrokine 1 152.7 223678_s_at D SFTPA2 surfactant protein A2 130.9 207430_s_at D MSMB microseminoprotein, beta- 99.0 214199_at SFTPD surfactant protein D major histocompatibility complex, class II, 96.5 210982_s_at D HLA-DRA DR alpha 96.5 221133_s_at D CLDN18 claudin 18 94.4 238222_at GKN2 gastrokine 2 93.7 1557961_s_at D LOC100127983 uncharacterized LOC100127983 93.1 229584_at LRRK2 leucine-rich repeat kinase 2 HOXD cluster antisense RNA 1 (non- 88.6 242042_s_at D HOXD-AS1 protein coding) 86.0 205569_at LAMP3 lysosomal-associated membrane protein 3 85.4 232698_at BPIFB2 BPI fold containing family B, member 2 84.4 205979_at SCGB2A1 secretoglobin, family 2A, member 1 84.3 230469_at RTKN2 rhotekin 2 82.2 204130_at HSD11B2 hydroxysteroid (11-beta) dehydrogenase 2 81.9 222242_s_at KLK5 kallikrein-related peptidase 5 77.0 237281_at AKAP14 A kinase (PRKA) anchor protein 14 76.7 1553602_at MUCL1 mucin-like 1 76.3 216359_at D MUC7 mucin 7, -

Ion Channels
UC Davis UC Davis Previously Published Works Title THE CONCISE GUIDE TO PHARMACOLOGY 2019/20: Ion channels. Permalink https://escholarship.org/uc/item/1442g5hg Journal British journal of pharmacology, 176 Suppl 1(S1) ISSN 0007-1188 Authors Alexander, Stephen PH Mathie, Alistair Peters, John A et al. Publication Date 2019-12-01 DOI 10.1111/bph.14749 License https://creativecommons.org/licenses/by/4.0/ 4.0 Peer reviewed eScholarship.org Powered by the California Digital Library University of California S.P.H. Alexander et al. The Concise Guide to PHARMACOLOGY 2019/20: Ion channels. British Journal of Pharmacology (2019) 176, S142–S228 THE CONCISE GUIDE TO PHARMACOLOGY 2019/20: Ion channels Stephen PH Alexander1 , Alistair Mathie2 ,JohnAPeters3 , Emma L Veale2 , Jörg Striessnig4 , Eamonn Kelly5, Jane F Armstrong6 , Elena Faccenda6 ,SimonDHarding6 ,AdamJPawson6 , Joanna L Sharman6 , Christopher Southan6 , Jamie A Davies6 and CGTP Collaborators 1School of Life Sciences, University of Nottingham Medical School, Nottingham, NG7 2UH, UK 2Medway School of Pharmacy, The Universities of Greenwich and Kent at Medway, Anson Building, Central Avenue, Chatham Maritime, Chatham, Kent, ME4 4TB, UK 3Neuroscience Division, Medical Education Institute, Ninewells Hospital and Medical School, University of Dundee, Dundee, DD1 9SY, UK 4Pharmacology and Toxicology, Institute of Pharmacy, University of Innsbruck, A-6020 Innsbruck, Austria 5School of Physiology, Pharmacology and Neuroscience, University of Bristol, Bristol, BS8 1TD, UK 6Centre for Discovery Brain Science, University of Edinburgh, Edinburgh, EH8 9XD, UK Abstract The Concise Guide to PHARMACOLOGY 2019/20 is the fourth in this series of biennial publications. The Concise Guide provides concise overviews of the key properties of nearly 1800 human drug targets with an emphasis on selective pharmacology (where available), plus links to the open access knowledgebase source of drug targets and their ligands (www.guidetopharmacology.org), which provides more detailed views of target and ligand properties. -

Loss of Keratin 13 in Oral Carcinoma in Situ: a Comparative Study of Protein and Gene Expression Levels Using Paraffin Sections
Modern Pathology (2012) 25, 784–794 784 & 2012 USCAP, Inc. All rights reserved 0893-3952/12 $32.00 Loss of keratin 13 in oral carcinoma in situ: a comparative study of protein and gene expression levels using paraffin sections Hiroko Ida-Yonemochi1,2,3, Satoshi Maruyama3, Takanori Kobayashi3, Manabu Yamazaki1, Jun Cheng1 and Takashi Saku1,3 1Division of Oral Pathology, Department of Tissue Regeneration and Reconstruction, Niigata University Graduate School of Medical and Dental Sciences, Niigata, Japan; 2Division of Anatomy and Cell Biology of the Hard Tissue, Niigata University Graduate School of Medical and Dental Sciences, Niigata, Japan and 3Oral Pathology Section, Department of Surgical Pathology, Niigata University Hospital, Niigata, Japan Immunohistochemical loss of keratin (K)13 is one of the most valuable diagnostic criteria for discriminating carcinoma in situ (CIS) from non-malignancies in the oral mucosa while K13 is stably immunolocalized in the prickle cells of normal oral epithelium. To elucidate the molecular mechanism for the loss of K13, we compared the immunohistochemical profiles for K13 and K16 which is not expressed in normal epithelia, but instead enhanced in CIS, with their mRNA levels by in-situ hybridization in formalin-fixed paraffin sections prepared from 23 CIS cases of the tongue, which were surgically removed. Reverse transcriptase-PCR was also performed using RNA samples extracted from laser-microdissected epithelial fragments of the serial paraffin sections in seven of the cases. Although more enhanced expression levels for K16 were confirmed at both the protein and gene levels in CIS in these seven cases, the loss of K13 was associated with repressed mRNA levels in four cases, but not in the other three cases.