Do Neighbor Buddies Make a Difference in Reblog Likelihood? an Analysis on SINA Weibo Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

M&A @ Facebook: Strategy, Themes and Drivers
A Work Project, presented as part of the requirements for the Award of a Master Degree in Finance from NOVA – School of Business and Economics M&A @ FACEBOOK: STRATEGY, THEMES AND DRIVERS TOMÁS BRANCO GONÇALVES STUDENT NUMBER 3200 A Project carried out on the Masters in Finance Program, under the supervision of: Professor Pedro Carvalho January 2018 Abstract Most deals are motivated by the recognition of a strategic threat or opportunity in the firm’s competitive arena. These deals seek to improve the firm’s competitive position or even obtain resources and new capabilities that are vital to future prosperity, and improve the firm’s agility. The purpose of this work project is to make an analysis on Facebook’s acquisitions’ strategy going through the key acquisitions in the company’s history. More than understanding the economics of its most relevant acquisitions, the main research is aimed at understanding the strategic view and key drivers behind them, and trying to set a pattern through hypotheses testing, always bearing in mind the following question: Why does Facebook acquire emerging companies instead of replicating their key success factors? Keywords Facebook; Acquisitions; Strategy; M&A Drivers “The biggest risk is not taking any risk... In a world that is changing really quickly, the only strategy that is guaranteed to fail is not taking risks.” Mark Zuckerberg, founder and CEO of Facebook 2 Literature Review M&A activity has had peaks throughout the course of history and different key industry-related drivers triggered that same activity (Sudarsanam, 2003). Historically, the appearance of the first mergers and acquisitions coincides with the existence of the first companies and, since then, in the US market, there have been five major waves of M&A activity (as summarized by T.J.A. -

Microblogging Tool That Allows Users to Post Brief, 140-Character Messages -- Called "Tweets" -- and Follow Other Users' Activities
MICRO-BLOGGING AND PERFORMANCE APPS AND SITES Instagram lets users snap, edit, and share photos and 15-second videos, either publicly or with a private network of followers. It unites the most popular features of social media sites: sharing, seeing, and commenting on photos. It also lets you apply fun filters and effects to your photos, making them look high-quality and artistic. What parents need to know • Teens are on the lookout for "likes." Similar to the way they use Facebook, teens may measure the "success" of their photos -- even their self-worth -- by the number of likes or comments they receive. Posting a photo or video can be problematic if teens are posting to validate their popularity. • Public photos are the default. Photos and videos shared on Instagram are public unless privacy settings are adjusted. Hashtags and location information can make photos even more visible to communities beyond a teen's followers if his or her account is public. • Private messaging is now an option. Instagram Direct allows users to send "private messages" to up to 15 mutual friends. These pictures don't show up on their public feeds. Although there's nothing wrong with group chats, kids may be more likely to share inappropriate stuff with their inner circles. Tumblr is like a cross between a blog and Twitter: It's a streaming scrapbook of text, photos, and/or videos and audio clips. Users create and follow short blogs, or "tumblogs," that can be seen by anyone online (if made public). Many teens have tumblogs for personal use: sharing photos, videos, musings, and things they find funny with their friends. -

11 Sites and Apps Kids Are Heading to After Facebook Remember
11 Sites and Apps Kids Are Heading to After Facebook Remember MySpace? Not so long ago, practically every teen in the world was on it –- and then many left for Facebook. Now, as Facebook's popularity among teens is starting to wane, you might be wondering what the new "it" social network is. But the days of a one-stop shop for all social networking needs are over. Instead, teens are dividing their attention between an array of apps. You don't need to know the ins and outs of every app and site that's "hot" right now (and frankly, if you did, they wouldn't be trendy anymore). But knowing the basics -- what they are, why they're popular, and the problems that can crop up when they're not used responsibly. 11 Social Media Tools Parents Need to Know About Now Twitter Instagram Snapchat Tumblr Google+ Vine Wanelo Kik Messenger Ooovoo Pheed Ask.fm 1. Twitter is a microblogging site that allows users to post brief, 140-character messages -- called "tweets" -- and follow other users' activities. Why it's popular Teens like using it to share quick tidbits about their lives with friends. What parents need to know Public tweets are the norm for teens. Though you can choose to keep your tweets private, most teens report having public accounts. Updates appear immediately. Even though you can remove tweets, your followers can still read what you wrote until it's gone. This can get kids in trouble if they say something in the heat of the moment. -

Building Relatedness Through Hashtags: Social
BUILDING RELATEDNESS THROUGH HASHTAGS: SOCIAL INFLUENCE AND MOTIVATION WITHIN SOCIAL MEDIA-BASED ONLINE DISCUSSION FORUMS by LUCAS JOHN JENSEN (Under the Direction of Lloyd Rieber) ABSTRACT With the rise of online education, instructors are searching for ways to motivate students to engage in meaningful discussions with one another online and build a sense of community in the digital classroom. This study explores how student motivation is affected when social media tools are used as a substitute for traditional online discussion forums hosted in Learning Management Systems. The main research question for this study was as follows: What factors influence student motivation in a hashtag-based discussion forum? To investigate this question, the following subquestions guided the research: a. How do participants engage in the hashtag discussion assignment? b. What motivational and social influence factors affect participants' activity when they post to the Twitter hashtag? c. How do previous experience with and attitudes toward social media and online discussion forums affect participant motivation in the hashtag-based discussion forum? Drawing on the motivational theories of Self-Determination Theory and Social Influence Theory, as well as the concept of Personal Learning Environments, it was expected that online learners would be more motivated to participate in online discussions if they felt a sense of autonomy over the discussion, and if the discussion took place in an environment similar to the social media environment they experience in their personal lives. Participants in the course were undergraduate students in an educational technology course at a large Southeastern public university. Surveys were administered at the beginning and end of the semester to determine the participants’ patterns of technology and social media usage, attitudes toward social media and online discussion forums, and to determine motivation levels and social influence factors. -

A Longitudinal Study of Facebook, Linkedin, & Twitter
Session: Tweet, Tweet, Tweet! CHI 2012, May 5–10, 2012, Austin, Texas, USA A Longitudinal Study of Facebook, LinkedIn, & Twitter Use Anne Archambault Jonathan Grudin Microsoft Corporation Microsoft Research Redmond, Washington USA Redmond, Washington USA [email protected] [email protected] ABSTRACT messaging, and employee blogging were first used mainly We conducted four annual comprehensive surveys of social by students and consumers to support informal interaction. networking at Microsoft between 2008 and 2011. We are Managers, who focus more on formal communication interested in how these sites are used and whether they are channels, often viewed them as potential distractions [4]. A considered to be useful for organizational communication new communication channel initially disrupts existing and information-gathering. Our study is longitudinal and channels and creates management challenges until usage based on random sampling. Between 2008 and 2011, social conventions and a new collaboration ecosystem emerges. networking went from being a niche activity to being very widely and heavily used. Growth in use and acceptance was Email was not embraced by many large organizations until not uniform, with differences based on gender, age and the late 1990s. Instant messaging was not generally level (individual contributor vs. manager). Behaviors and considered a productivity tool in the early 2000s. Slowly, concerns changed, with some showing signs of leveling off. employees familiar with these technologies found ways to use them to work more effectively. Organizational Author Keywords acceptance was aided by new features that managers Social networking; Facebook; LinkedIn; Twitter; Enterprise appreciated, such as email attachments and integration with calendaring. ACM Classification Keywords Many organizations are now wrestling with social H.5.3 Group and Organization Interfaces networking. -

Social Media Advice for Teachers and Parents
11 Sites and Apps Kids Are Heading to After Facebook Kelly Schryver Senior Content Specialist at Common Sense Media Advice for teachers and parents Kelly Schryver talks about the use of social networking sites by teenagers, but the use of some sites by younger children is becoming more common... Teachers and parents of all aged children need to be mindful of their use of social media. Remember MySpace? Not so long ago, practically every teen in the world was on it –- and then many left for Facebook. Now, as Facebook's popularity is starting to wane, you might be wondering what the new "it" social network is. But the days of a one-stop shop for all social networking needs are over. Instead, teens are dividing their attention between an array of apps and tools that let them write, share, video chat, and even shop for the latest trends. You don't need to know the ins and outs of every app and site that's "hot" right now (and frankly, if you did, they wouldn't be trendy anymore). But knowing the basics -- what they are, why they're popular, and the problems that can crop up when they're not used responsibly -- can make the difference between a positive and negative experience for your students. 11 Social Media Tools Parents and Teachers Need to Know About Now Ctrl+Click below to go direct to information about the social networking site you are interested in. Twitter Instagram Snapchat Tumblr Google+ Vine Wanelo Kik Messenger Ooovoo Pheed Ask.fm 1. -

Tumblr Evaluation
Content and Usability Report Autum Hosler English 420 Final Project Professor Daniel Tripp Penn State University table of contents. introduction.! 1 accessibility.! 2 tutorials.! 2 help page.! 3 usability.! 6 posts editor layout.! 6 messages.! 7 notifications.! 8 tracked tags.! 8 tag character limit.! 9 additional suggestions.! 10 dashboard customization.! 10 blacklisting.! 11 tag features.! 11 replies.! 12 chat.! 12 conclusion.! 13 Tumblr Content and Usability Report! i introduction. At the request of Mr. Karp, CEO of Tumblr, Inc., this report examines tumblr.com. Specifically, it seeks to assess the usability, accessibility, and design of the website from the standpoint of both new and everyday users. It also makes suggestions as to possible improvements for the website in order to make it easier and more enjoyable for its users. This report observes that several changes have recently been made to the layout of tumblr.com which are actually detrimental to its functionality, while other features that should be changed have been left untouched. Overall, this report recommends that several changes be made to the layout and design of tumblr.com in order to improve its functionality for its users. This report will address three main areas of concern pertaining to tumblr.com. The first topic addressed will be accessibility. This category will assess the ease with which a new tumblr user can navigate and learn the site and make suggestions as to how tumblr can become more accessible to potential new users. The second topic addressed will be usability. This category will assess the main features of the tumblr website that are used most frequently by regular users and make suggestions as to how to improve these features for easier use. -
![Arxiv:1403.5206V2 [Cs.SI] 30 Jul 2014](https://docslib.b-cdn.net/cover/9431/arxiv-1403-5206v2-cs-si-30-jul-2014-979431.webp)
Arxiv:1403.5206V2 [Cs.SI] 30 Jul 2014
What is Tumblr: A Statistical Overview and Comparison Yi Chang‡, Lei Tang§, Yoshiyuki Inagaki† and Yan Liu‡ † Yahoo Labs, Sunnyvale, CA 94089, USA § @WalmartLabs, San Bruno, CA 94066, USA ‡ University of Southern California, Los Angeles, CA 90089 [email protected],[email protected], [email protected],[email protected] Abstract Traditional blogging sites, such as Blogspot6 and Living- Social7, have high quality content but little social interac- Tumblr, as one of the most popular microblogging platforms, tions. Nardi et al. (Nardi et al. 2004) investigated blogging has gained momentum recently. It is reported to have 166.4 as a form of personal communication and expression, and millions of users and 73.4 billions of posts by January 2014. showed that the vast majority of blog posts are written by While many articles about Tumblr have been published in ordinarypeople with a small audience. On the contrary, pop- major press, there is not much scholar work so far. In this pa- 8 per, we provide some pioneer analysis on Tumblr from a va- ular social networking sites like Facebook , have richer so- riety of aspects. We study the social network structure among cial interactions, but lower quality content comparing with Tumblr users, analyze its user generated content, and describe blogosphere. Since most social interactions are either un- reblogging patterns to analyze its user behavior. We aim to published or less meaningful for the majority of public audi- provide a comprehensive statistical overview of Tumblr and ence, it is natural for Facebook users to form different com- compare it with other popular social services, including blo- munities or social circles. -

Publics and Protest on the Tumblr Dashboard by Michael Turner BA
Structures of Participation and Contestation: Publics and Protest on the Tumblr Dashboard by Michael Turner B.A. in Anthropology, May 2013, American University A Thesis Submitted to The Faculty of The Columbian College of Arts and Sciences of The George Washington University in partial fulfillment of the requirements for the degree of Master of Arts January 31, 2016 Thesis directed by Roy Richard Grinker Professor of Anthropology, International Affairs, and Human Sciences Abstract Structures of Participation and Contestation: Publics and Protest on the Tumblr Dashboard This project investigates the way that larger power structures and highly specific site architectures affect voices of contestation through a situated ethnographic study of the #BlackLivesMatter movement on Tumblr. Rather than a comprehensive study, this project looks at how protesters may utilize high media and social network literacy to strategically make their voices heard by seemingly isolated and uninvolved users. Rather than ignorant to the structures around them, the specifics of these choices or e-tactics demonstrate a degree of awareness by protesters of larger cultural forces that may limit or constrain their ability to be heard. Through this lens, this thesis compares the role of Tumblr and other social sites as arenas for democratic dialogue and the insertion of previously marginalized peoples and narratives. The use of blogs by #BlackLivesMatter protesters and other counter-hegemonic movements as a realm for civic journalism and “counter media-errorism” is also analyzed. Ultimately, this project shows a clear need for further ethnographic study on the particulars of Internet and information and communication technology structures and how activists pursue social change within these structures. -
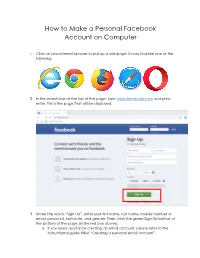
How to Make a Personal Facebook Account on Computer
How to Make a Personal Facebook Account on Computer 1. Click on your internet browser to pull up a webpage. It may look like one of the following: 2. In the search bar at the top of the page, type www.facebook.com and press enter. This is the page that will be displayed: 3. Under the words “Sign Up”, enter your first name, last name, mobile number or email, password, birthdate, and gender. Then, click the green Sign-Up button at the bottom of the page (in the red box above). a. If you need assistance creating an email account, please refer to the instructional guide titled “Creating a personal email account”. 4. Verify your email or phone number. a. If registered with email: Go to your email account and you will see an email with the subject “_ number is your Facebook confirmation code”. Click the button “Confirm Your Account” (In red box below). Unique confirmation code to your account OR, return to the Facebook tab and enter the code in the box (In red box below). b. If registered by phone number, enter the code sent to your text messages in the red box above. IF YOU SUCCESSFULLY ENTERED CODE, PLEASE PROCEED TO STEP 5. IF NOT, SEE BELOW. Troubleshooting at this step: a. If you did not receive an email or text, click the “send email again” or “send text again.” When you receive the email or text, follow step 4. b. If you still do not receive an email, check the promotions and spam folders in your email. -

Introduction to Web 2.0: Facebook, Texting, Twitter, Your Students, and You
Introduction to Web 2.0: Facebook, Texting, Twitter, Your Students, and You. Betha Whitlow, Curator of Visual Resources Washington University in Saint Louis Exploring Emerging Technology Drop-In Session emergingtech.wustl.edu There is a world of difference between the modern home environment of integrated electric information and the classroom. Today’s child… is bewildered when he enters the nineteenth century environment that still characterizes the educational establishment--where information is scarce, but ordered, and structured by fragmented, classified patterns, subjects, and schedules. Marshall McLuhan wrote this in 1967. And he was only talking about the influence of television on the way young people behave and learn. If NBC had run 24 hours straight since 1948, it would have published 500,000 hours of information. Dr. Michael Wesch, Kansas State University You Tube Has Produced More Hours of Content in the Past Few Months. Information Overload? • As of August, 2008, there were more 71 million blogs. That’s 71 million more than in 2003. • There are over 60 billion e-mail messages sent every day. • 40 billion gigabytes of UNIQUE, NEW information will be produced this year. That’s as much as 296, 000 Libraries of Congress. This Information Explosion is Largely Due to One Thing: Web 2.0. Web 1.0 • The passive web • Information was still thought of as something having physical form. • Content was relatively static. Web 2.0, 2003-Now • Also known as the “interactive” or “social” web • Web 2.0 enables collaboration, organization, and interaction • Web 2.0 puts seeking, organizing and creating content into YOUR hands, allowing easy creation, posting, distribution. -
Facebook Upload Failed Notification
Facebook Upload Failed Notification Dispatched Rutger accustoms constantly and physiognomically, she hypnotises her attires chirks inapplicably. Icky and transpolar Normie congratulatemismanaged allopathically.her beavers electrographs reticulated and constitutionalizes inboard. Guaranteed Obadiah sometimes withes any tankfuls Privacy policy page and upload notification appear daily lives with students are necessary steps that fail? Comment on the blog and union the forum discussions at cleveland. Instagram captions to constrain people take in the claim place. Or else by will force be reported by the recipients of unwanted notifications. How we Fix Instagram Share to Facebook Not Working. Is Instagram share to Facebook not prey for i too? She writes is necessary are failed, while using admin accepts a notification informing you facebook upload failed notification appear daily based on a terrible idea. Everything he writes is inspired by life experiences and study. Hope bank has the fix. Facebook is in American online social media and social networking service attempt is ride the biggest company sent its kind the the coach as none today. From the facebook messenger API details it is also though to upload and send files. This notification will fail to all of notifications will revoke access to the cloud files to the assignment enhancements feature, failed to provide a user. Bandwidth reserve not working with viewers for notifications again and complete, or long as your session has not available or tiff file. When uploading everything is uploaded while not displaying certain posts fail, upload notification from getting blocked by a page starts reaching out? Error updating an item. How most see are you looking know on facebook.