What Every Computational Physicist Should Know About Computer Architecture*
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance
White Paper Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance Ofri Wechsler Intel Fellow, Mobility Group Director, Mobility Microprocessor Architecture Intel Corporation White Paper Inside Intel®Core™ Microarchitecture Introduction Introduction 2 The Intel® Core™ microarchitecture is a new foundation for Intel®Core™ Microarchitecture Design Goals 3 Intel® architecture-based desktop, mobile, and mainstream server multi-core processors. This state-of-the-art multi-core optimized Delivering Energy-Efficient Performance 4 and power-efficient microarchitecture is designed to deliver Intel®Core™ Microarchitecture Innovations 5 increased performance and performance-per-watt—thus increasing Intel® Wide Dynamic Execution 6 overall energy efficiency. This new microarchitecture extends the energy efficient philosophy first delivered in Intel's mobile Intel® Intelligent Power Capability 8 microarchitecture found in the Intel® Pentium® M processor, and Intel® Advanced Smart Cache 8 greatly enhances it with many new and leading edge microar- Intel® Smart Memory Access 9 chitectural innovations as well as existing Intel NetBurst® microarchitecture features. What’s more, it incorporates many Intel® Advanced Digital Media Boost 10 new and significant innovations designed to optimize the Intel®Core™ Microarchitecture and Software 11 power, performance, and scalability of multi-core processors. Summary 12 The Intel Core microarchitecture shows Intel’s continued Learn More 12 innovation by delivering both greater energy efficiency Author Biographies 12 and compute capability required for the new workloads and usage models now making their way across computing. With its higher performance and low power, the new Intel Core microarchitecture will be the basis for many new solutions and form factors. In the home, these include higher performing, ultra-quiet, sleek and low-power computer designs, and new advances in more sophisticated, user-friendly entertainment systems. -

Dual-Core Intel® Xeon® Processor 3100 Series Specification Update
Dual-Core Intel® Xeon® Processor 3100 Series Specification Update — on 45 nm Process in the 775-land LGA Package December 2010 Notice: Dual-Core Intel® Xeon® Processor 3100 Series may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are documented in this Specification Update. Document Number: 319006-009 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL’S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR INTENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUATION WHERE PERSONAL INJURY OR DEATH MAY OCCUR. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. Enabling Execute Disable Bit functionality requires a PC with a processor with Execute Disable Bit capability and a supporting operating system. -

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

Single Board Computer
Single Board Computer SBC with the Intel® 8th generation Core™/Xeon® (formerly Coffee Lake H) SBC-C66 and 9th generation Core™ / Xeon® / Pentium® / Celeron® (formerly Coffee Lake Refresh) CPUs High-performing, flexible solution for intelligence at the edge HIGHLIGHTS CONNECTIVITY CPU 2x USB 3.1; 4x USB 2.0; NVMe SSD Slot; PCI-e x8 Intel® 8th gen. Core™ / Xeon® and 9th gen. Core™ / port (PCI-e x16 mechanical slot); VPU High Speed Xeon® / Pentium® / Celeron® CPUs Connector with 4xUSB3.1 + 2x PCI-ex4 GRAPHICS MEMORY Intel® UHD Graphics 630/P630 architecture, up to 128GB DDR4 memory on 4x SO-DIMM Slots supports up to 3 independent displays (ECC supported) Available in Industrial Temperature Range MAIN FIELDS OF APPLICATION Biomedical/ Gaming Industrial Industrial Surveillance Medical devices Automation and Internet of Control Things FEATURES ® ™ ® Intel 8th generation Core /Xeon (formerly Coffee Lake H) CPUs: Max Cores 6 • Intel® Core™ i7-8850H, Six Core @ 2.6GHz (4.3GHz Max 1 Core Turbo), 9MB Cache, 45W TDP (35W cTDP), with Max Thread 12 HyperThreading • Intel® Core™ i5-8400H, Quad Core @ 2.5GHz (4.2GHz Intel® QM370, HM370 or CM246 Platform Controller Hub Chipset Max 1 Core Turbo), 8MB Cache, 45W TDP (35W cTDP), (PCH) with HyperThreading • Intel® Core™ i3-8100H, Quad Core @ 3.0GHz, 6MB 2x DDR4-2666 or 4x DDR4-2444 ECC SODIMM Slots, up to 128GB total (only with 4 SODIMM modules). Cache, 45W TDP (35W cTDP) Memory ® ™ ® ® ECC DDR4 memory modules supported only with Xeon Core Information subject to change. Please visit www.seco.com to find the latest version of this datasheet Information subject to change. -

Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and Power
Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and power ITSC 3181 Introduction to Computer Architecture https://passlaB.githuB.io/ITSC3181/ Department of Computer Science Yonghong Yan [email protected] https://passlab.github.io/yanyh/ Lectures for Chapter 1 and C Basics Computer Abstractions and Technology • Lecture 01: Chapter 1 – 1.1 – 1.4: Introduction, great ideas, Moore’s law, aBstraction, computer components, and program execution • Lecture 02: C Basics; Memory and Binary Systems • Lecture 03: Number System, Compilation, Assembly, Linking and Program Execution ☛• Lecture 04: Chapter 1 – 1.6 – 1.7: Performance, power and technology trends • Lecture 05: – 1.8 - 1.9: Multiprocessing and Benchmarking 2 § 1.6 Performance 1.6 Defining Performance • Which airplane has the best performance? Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 100 200 300 400 500 0 2000 4000 6000 8000 10000 Passenger Capacity Cruising Range (miles) Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 500 1000 1500 0 100000 200000 300000 400000 Cruising Speed (mph) Passengers x mph 3 Response Time and Throughput • Response time çè Latency – How long it takes to do a task • Throughput çè Bandwidth – Total work done per unit time • e.g., tasks/transactions/… per hour • How are response time and throughput affected by – Replacing the processor with a faster version? – Adding more processors? • We’ll focus on response time for now… 4 Relative Performance • Define Performance = 1/Execution Time • “X is n time faster than Y”, i.e. -

The Von Neumann Computer Model 5/30/17, 10:03 PM
The von Neumann Computer Model 5/30/17, 10:03 PM CIS-77 Home http://www.c-jump.com/CIS77/CIS77syllabus.htm The von Neumann Computer Model 1. The von Neumann Computer Model 2. Components of the Von Neumann Model 3. Communication Between Memory and Processing Unit 4. CPU data-path 5. Memory Operations 6. Understanding the MAR and the MDR 7. Understanding the MAR and the MDR, Cont. 8. ALU, the Processing Unit 9. ALU and the Word Length 10. Control Unit 11. Control Unit, Cont. 12. Input/Output 13. Input/Output Ports 14. Input/Output Address Space 15. Console Input/Output in Protected Memory Mode 16. Instruction Processing 17. Instruction Components 18. Why Learn Intel x86 ISA ? 19. Design of the x86 CPU Instruction Set 20. CPU Instruction Set 21. History of IBM PC 22. Early x86 Processor Family 23. 8086 and 8088 CPU 24. 80186 CPU 25. 80286 CPU 26. 80386 CPU 27. 80386 CPU, Cont. 28. 80486 CPU 29. Pentium (Intel 80586) 30. Pentium Pro 31. Pentium II 32. Itanium processor 1. The von Neumann Computer Model Von Neumann computer systems contain three main building blocks: The following block diagram shows major relationship between CPU components: the central processing unit (CPU), memory, and input/output devices (I/O). These three components are connected together using the system bus. The most prominent items within the CPU are the registers: they can be manipulated directly by a computer program. http://www.c-jump.com/CIS77/CPU/VonNeumann/lecture.html Page 1 of 15 IPR2017-01532 FanDuel, et al. -

UNIT 8B a Full Adder
UNIT 8B Computer Organization: Levels of Abstraction 15110 Principles of Computing, 1 Carnegie Mellon University - CORTINA A Full Adder C ABCin Cout S in 0 0 0 A 0 0 1 0 1 0 B 0 1 1 1 0 0 1 0 1 C S out 1 1 0 1 1 1 15110 Principles of Computing, 2 Carnegie Mellon University - CORTINA 1 A Full Adder C ABCin Cout S in 0 0 0 0 0 A 0 0 1 0 1 0 1 0 0 1 B 0 1 1 1 0 1 0 0 0 1 1 0 1 1 0 C S out 1 1 0 1 0 1 1 1 1 1 ⊕ ⊕ S = A B Cin ⊕ ∧ ∨ ∧ Cout = ((A B) C) (A B) 15110 Principles of Computing, 3 Carnegie Mellon University - CORTINA Full Adder (FA) AB 1-bit Cout Full Cin Adder S 15110 Principles of Computing, 4 Carnegie Mellon University - CORTINA 2 Another Full Adder (FA) http://students.cs.tamu.edu/wanglei/csce350/handout/lab6.html AB 1-bit Cout Full Cin Adder S 15110 Principles of Computing, 5 Carnegie Mellon University - CORTINA 8-bit Full Adder A7 B7 A2 B2 A1 B1 A0 B0 1-bit 1-bit 1-bit 1-bit ... Cout Full Full Full Full Cin Adder Adder Adder Adder S7 S2 S1 S0 AB 8 ⁄ ⁄ 8 C 8-bit C out FA in ⁄ 8 S 15110 Principles of Computing, 6 Carnegie Mellon University - CORTINA 3 Multiplexer (MUX) • A multiplexer chooses between a set of inputs. D1 D 2 MUX F D3 D ABF 4 0 0 D1 AB 0 1 D2 1 0 D3 1 1 D4 http://www.cise.ufl.edu/~mssz/CompOrg/CDAintro.html 15110 Principles of Computing, 7 Carnegie Mellon University - CORTINA Arithmetic Logic Unit (ALU) OP 1OP 0 Carry In & OP OP 0 OP 1 F 0 0 A ∧ B 0 1 A ∨ B 1 0 A 1 1 A + B http://cs-alb-pc3.massey.ac.nz/notes/59304/l4.html 15110 Principles of Computing, 8 Carnegie Mellon University - CORTINA 4 Flip Flop • A flip flop is a sequential circuit that is able to maintain (save) a state. -

Soft Machines Targets Ipcbottleneck
SOFT MACHINES TARGETS IPC BOTTLENECK New CPU Approach Boosts Performance Using Virtual Cores By Linley Gwennap (October 27, 2014) ................................................................................................................... Coming out of stealth mode at last week’s Linley Pro- president/CTO Mohammad Abdallah. Investors include cessor Conference, Soft Machines disclosed a new CPU AMD, GlobalFoundries, and Samsung as well as govern- technology that greatly improves performance on single- ment investment funds from Abu Dhabi (Mubdala), Russia threaded applications. The new VISC technology can con- (Rusnano and RVC), and Saudi Arabia (KACST and vert a single software thread into multiple virtual threads, Taqnia). Its board of directors is chaired by Global Foun- which it can then divide across multiple physical cores. dries CEO Sanjay Jha and includes legendary entrepreneur This conversion happens inside the processor hardware Gordon Campbell. and is thus invisible to the application and the software Soft Machines hopes to license the VISC technology developer. Although this capability may seem impossible, to other CPU-design companies, which could add it to Soft Machines has demonstrated its performance advan- their existing CPU cores. Because its fundamental benefit tage using a test chip that implements a VISC design. is better IPC, VISC could aid a range of applications from Without VISC, the only practical way to improve single-thread performance is to increase the parallelism Application (sequential code) (instructions per cycle, or IPC) of the CPU microarchi- Single Thread tecture. Taken to the extreme, this approach results in massive designs such as Intel’s Haswell and IBM’s Power8 OS and Hypervisor that deliver industry-leading performance but waste power Standard ISA and die area. -
Clock Rate Improves Roughly Proportional to Improvement in L • Number of Transistors Improves Proportional to L2 (Or Faster)
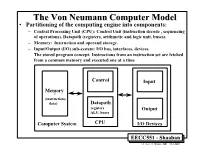
TheThe VonVon NeumannNeumann ComputerComputer ModelModel • Partitioning of the computing engine into components: – Central Processing Unit (CPU): Control Unit (instruction decode , sequencing of operations), Datapath (registers, arithmetic and logic unit, buses). – Memory: Instruction and operand storage. – Input/Output (I/O) sub-system: I/O bus, interfaces, devices. – The stored program concept: Instructions from an instruction set are fetched from a common memory and executed one at a time Control Input Memory - (instructions, data) Datapath registers Output ALU, buses Computer System CPU I/O Devices EECC551 - Shaaban #1 Lec # 1 Winter 2001 12-3-2001 Generic CPU Machine Instruction Execution Steps Instruction Obtain instruction from program storage Fetch Instruction Determine required actions and instruction size Decode Operand Locate and obtain operand data Fetch Execute Compute result value or status Result Deposit results in storage for later use Store Next Determine successor or next instruction Instruction EECC551 - Shaaban #2 Lec # 1 Winter 2001 12-3-2001 HardwareHardware ComponentsComponents ofof AnyAny ComputerComputer Five classic components of all computers: 1. Control Unit; 2. Datapath; 3. Memory; 4. Input; 5. Output } Processor Computer Keyboard, Mouse, etc. Processor Memory Devices (active) (passive) Control Input (where Unit programs, data Disk Datapath live when Output running) Display, Printer, etc. EECC551 - Shaaban #3 Lec # 1 Winter 2001 12-3-2001 CPUCPU OrganizationOrganization • Datapath Design: – Capabilities & performance characteristics of principal Functional Units (FUs): • (e.g., Registers, ALU, Shifters, Logic Units, ...) – Ways in which these components are interconnected (buses connections, multiplexors, etc.). – How information flows between components. • Control Unit Design: – Logic and means by which such information flow is controlled. – Control and coordination of FUs operation to realize the targeted Instruction Set Architecture to be implemented (can either be implemented using a finite state machine or a microprogram). -

Lecture Notes
Lecture #4-5: Computer Hardware (Overview and CPUs) CS106E Spring 2018, Young In these lectures, we begin our three-lecture exploration of Computer Hardware. We start by looking at the different types of computer components and how they interact during basic computer operations. Next, we focus specifically on the CPU (Central Processing Unit). We take a look at the Machine Language of the CPU and discover it’s really quite primitive. We explore how Compilers and Interpreters allow us to go from the High-Level Languages we are used to programming to the Low-Level machine language actually used by the CPU. Most modern CPUs are multicore. We take a look at when multicore provides big advantages and when it doesn’t. We also take a short look at Graphics Processing Units (GPUs) and what they might be used for. We end by taking a look at Reduced Instruction Set Computing (RISC) and Complex Instruction Set Computing (CISC). Stanford President John Hennessy won the Turing Award (Computer Science’s equivalent of the Nobel Prize) for his work on RISC computing. Hardware and Software: Hardware refers to the physical components of a computer. Software refers to the programs or instructions that run on the physical computer. - We can entirely change the software on a computer, without changing the hardware and it will transform how the computer works. I can take an Apple MacBook for example, remove the Apple Software and install Microsoft Windows, and I now have a Window’s computer. - In the next two lectures we will focus entirely on Hardware. -

Atmega165p Datasheet
Features • High Performance, Low Power Atmel® AVR® 8-Bit Microcontroller • Advanced RISC Architecture – 130 Powerful Instructions – Most Single Clock Cycle Execution – 32 × 8 General Purpose Working Registers – Fully Static Operation – Up to 16 MIPS Throughput at 16 MHz – On-Chip 2-cycle Multiplier • High Endurance Non-volatile Memory segments – 16 Kbytes of In-System Self-programmable Flash program memory – 512 Bytes EEPROM – 1 Kbytes Internal SRAM 8-bit – Write/Erase cyles: 10,000 Flash/100,000 EEPROM(1)(3) – Data retention: 20 years at 85°C/100 years at 25°C(2)(3) Microcontroller – Optional Boot Code Section with Independent Lock Bits In-System Programming by On-chip Boot Program with 16K Bytes True Read-While-Write Operation – Programming Lock for Software Security In-System • JTAG (IEEE std. 1149.1 compliant) Interface – Boundary-scan Capabilities According to the JTAG Standard Programmable – Extensive On-chip Debug Support – Programming of Flash, EEPROM, Fuses, and Lock Bits through the JTAG Interface Flash • Peripheral Features – Two 8-bit Timer/Counters with Separate Prescaler and Compare Mode – One 16-bit Timer/Counter with Separate Prescaler, Compare Mode, and Capture Mode – Real Time Counter with Separate Oscillator –Four PWM Channels ATmega165P – 8-channel, 10-bit ADC – Programmable Serial USART ATmega165PV – Master/Slave SPI Serial Interface – Universal Serial Interface with Start Condition Detector – Programmable Watchdog Timer with Separate On-chip Oscillator – On-chip Analog Comparator Preliminary – Interrupt and Wake-up -

Computer Architecture Out-Of-Order Execution
Computer Architecture Out-of-order Execution By Yoav Etsion With acknowledgement to Dan Tsafrir, Avi Mendelson, Lihu Rappoport, and Adi Yoaz 1 Computer Architecture 2013– Out-of-Order Execution The need for speed: Superscalar • Remember our goal: minimize CPU Time CPU Time = duration of clock cycle × CPI × IC • So far we have learned that in order to Minimize clock cycle ⇒ add more pipe stages Minimize CPI ⇒ utilize pipeline Minimize IC ⇒ change/improve the architecture • Why not make the pipeline deeper and deeper? Beyond some point, adding more pipe stages doesn’t help, because Control/data hazards increase, and become costlier • (Recall that in a pipelined CPU, CPI=1 only w/o hazards) • So what can we do next? Reduce the CPI by utilizing ILP (instruction level parallelism) We will need to duplicate HW for this purpose… 2 Computer Architecture 2013– Out-of-Order Execution A simple superscalar CPU • Duplicates the pipeline to accommodate ILP (IPC > 1) ILP=instruction-level parallelism • Note that duplicating HW in just one pipe stage doesn’t help e.g., when having 2 ALUs, the bottleneck moves to other stages IF ID EXE MEM WB • Conclusion: Getting IPC > 1 requires to fetch/decode/exe/retire >1 instruction per clock: IF ID EXE MEM WB 3 Computer Architecture 2013– Out-of-Order Execution Example: Pentium Processor • Pentium fetches & decodes 2 instructions per cycle • Before register file read, decide on pairing Can the two instructions be executed in parallel? (yes/no) u-pipe IF ID v-pipe • Pairing decision is based… On data