Control of Lineage Commitment in Acute Leukaemia
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Reconstituting Cell Dynamics with Synthetic Biology
REVIEW CELL BIOLOGY Toward total synthesis of cell function: Reconstituting cell dynamics with synthetic biology Allen K. Kim,1,2,3 Robert DeRose,1,2* Tasuku Ueno,4† Benjamin Lin,3,5,6† Toru Komatsu,4,7† Hideki Nakamura,1,2 Takanari Inoue1,2,3,7* Biological phenomena, such as cellular differentiation and phagocytosis, are fundamental processes that enable cells to fulfill important physiological roles in multicellular organisms. In the field of synthetic biology, the study of these behaviors relies on the use of a broad range of molecular tools that enable the real-time manipulation and measurement of key components in the underlying signaling pathways. This Review will focus on a subset of synthetic biology tools known as bottom-up techniques, which use technologies such as optogenetics and chemically induced dimerization to reconstitute cellular behavior Downloaded from in cells. These techniques have been crucial not only in revealing causal relationships within signaling networks but also in identifying the minimal signaling components that are necessary for a given cellular function. We discuss studies that used these systems in a broad range of cellular and molecular phenomena, including the time-dependent modulation of protein activity in cellular proliferation and dif- ferentiation, the reconstitution of phagocytosis, the reconstitution of chemotaxis, and the regulation of actin reorganization. Finally, we discuss the potential contribution of synthetic biology to medicine. http://stke.sciencemag.org/ Introduction lation of biomolecules with subcellular resolution. One of the ultimate One of the prevailing aspirations of synthetic biology is the intelligent de- goals of synthetic biology is the recapitulation of these behaviors in a sign of biological systems to perform a specific function, which is achieved cell-free system, in which all of the components are introduced in a through the assembly of modular components consisting of genes and pro- controlled manner. -

Evolutionary Origins of DNA Repair Pathways: Role of Oxygen Catastrophe in the Emergence of DNA Glycosylases
cells Review Evolutionary Origins of DNA Repair Pathways: Role of Oxygen Catastrophe in the Emergence of DNA Glycosylases Paulina Prorok 1 , Inga R. Grin 2,3, Bakhyt T. Matkarimov 4, Alexander A. Ishchenko 5 , Jacques Laval 5, Dmitry O. Zharkov 2,3,* and Murat Saparbaev 5,* 1 Department of Biology, Technical University of Darmstadt, 64287 Darmstadt, Germany; [email protected] 2 SB RAS Institute of Chemical Biology and Fundamental Medicine, 8 Lavrentieva Ave., 630090 Novosibirsk, Russia; [email protected] 3 Center for Advanced Biomedical Research, Department of Natural Sciences, Novosibirsk State University, 2 Pirogova St., 630090 Novosibirsk, Russia 4 National Laboratory Astana, Nazarbayev University, Nur-Sultan 010000, Kazakhstan; [email protected] 5 Groupe «Mechanisms of DNA Repair and Carcinogenesis», Equipe Labellisée LIGUE 2016, CNRS UMR9019, Université Paris-Saclay, Gustave Roussy Cancer Campus, F-94805 Villejuif, France; [email protected] (A.A.I.); [email protected] (J.L.) * Correspondence: [email protected] (D.O.Z.); [email protected] (M.S.); Tel.: +7-(383)-3635187 (D.O.Z.); +33-(1)-42115404 (M.S.) Abstract: It was proposed that the last universal common ancestor (LUCA) evolved under high temperatures in an oxygen-free environment, similar to those found in deep-sea vents and on volcanic slopes. Therefore, spontaneous DNA decay, such as base loss and cytosine deamination, was the Citation: Prorok, P.; Grin, I.R.; major factor affecting LUCA’s genome integrity. Cosmic radiation due to Earth’s weak magnetic field Matkarimov, B.T.; Ishchenko, A.A.; and alkylating metabolic radicals added to these threats. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -
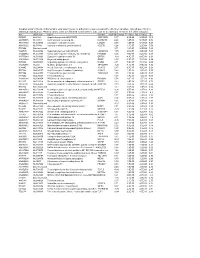
Supplementary File 2A Revised
Supplementary file 2A. Differentially expressed genes in aldosteronomas compared to all other samples, ranked according to statistical significance. Missing values were not allowed in aldosteronomas, but to a maximum of five in the other samples. Acc UGCluster Name Symbol log Fold Change P - Value Adj. P-Value B R99527 Hs.8162 Hypothetical protein MGC39372 MGC39372 2,17 6,3E-09 5,1E-05 10,2 AA398335 Hs.10414 Kelch domain containing 8A KLHDC8A 2,26 1,2E-08 5,1E-05 9,56 AA441933 Hs.519075 Leiomodin 1 (smooth muscle) LMOD1 2,33 1,3E-08 5,1E-05 9,54 AA630120 Hs.78781 Vascular endothelial growth factor B VEGFB 1,24 1,1E-07 2,9E-04 7,59 R07846 Data not found 3,71 1,2E-07 2,9E-04 7,49 W92795 Hs.434386 Hypothetical protein LOC201229 LOC201229 1,55 2,0E-07 4,0E-04 7,03 AA454564 Hs.323396 Family with sequence similarity 54, member B FAM54B 1,25 3,0E-07 5,2E-04 6,65 AA775249 Hs.513633 G protein-coupled receptor 56 GPR56 -1,63 4,3E-07 6,4E-04 6,33 AA012822 Hs.713814 Oxysterol bining protein OSBP 1,35 5,3E-07 7,1E-04 6,14 R45592 Hs.655271 Regulating synaptic membrane exocytosis 2 RIMS2 2,51 5,9E-07 7,1E-04 6,04 AA282936 Hs.240 M-phase phosphoprotein 1 MPHOSPH -1,40 8,1E-07 8,9E-04 5,74 N34945 Hs.234898 Acetyl-Coenzyme A carboxylase beta ACACB 0,87 9,7E-07 9,8E-04 5,58 R07322 Hs.464137 Acyl-Coenzyme A oxidase 1, palmitoyl ACOX1 0,82 1,3E-06 1,2E-03 5,35 R77144 Hs.488835 Transmembrane protein 120A TMEM120A 1,55 1,7E-06 1,4E-03 5,07 H68542 Hs.420009 Transcribed locus 1,07 1,7E-06 1,4E-03 5,06 AA410184 Hs.696454 PBX/knotted 1 homeobox 2 PKNOX2 1,78 2,0E-06 -

Lysine Methylation Regulators Moonlighting Outside the Epigenome Evan Cornett, Laure Ferry, Pierre-Antoine Defossez, Scott Rothbart
Lysine Methylation Regulators Moonlighting outside the Epigenome Evan Cornett, Laure Ferry, Pierre-Antoine Defossez, Scott Rothbart To cite this version: Evan Cornett, Laure Ferry, Pierre-Antoine Defossez, Scott Rothbart. Lysine Methylation Regulators Moonlighting outside the Epigenome. Molecular Cell, Elsevier, 2019, 10.1016/j.molcel.2019.08.026. hal-02359890 HAL Id: hal-02359890 https://hal.archives-ouvertes.fr/hal-02359890 Submitted on 14 Nov 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Lysine methylation regulators moonlighting outside the epigenome Evan M. Cornett1, Laure Ferry2, Pierre-Antoine Defossez2, and Scott B. RothBart1* 1Center for Epigenetics, Van Andel Research Institute, Grand Rapids, MI 49503, USA. 2Université de Paris, Epigenetics and Cell Fate, CNRS, F-75013 Paris, France. *Correspondence: [email protected], 616-234-5367 ABSTRACT Landmark discoveries made nearly two decades ago identified known transcriptional regulators as histone lysine methyltransferases; since then the field of lysine methylation signaling has Been dominated By studies of how this small chemical posttranslational modification regulates gene expression and other chromatin-Based processes. However, recent advances in mass spectrometry-Based proteomics have revealed that histones are just a suBset of the thousands of eukaryotic proteins marked By lysine methylation. -

Gene Expression Signatures of Sporadic ALS Motor Neuron Populations
bioRxiv preprint doi: https://doi.org/10.1101/038448; this version posted February 1, 2016. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Gene Expression Signatures of Sporadic ALS Motor Neuron Populations Ranjan Batra1,2, §, Kasey Hutt1, § , Anthony Vu1, §, Stuart J. Rabin3, Michael W. Baughn2, Ryan T. Libby3 , Shawn Hoon4, John Ravits2,*, Gene W. Yeo1,2,4,5,* Affiliations: 1Department of Cellular and Molecular Medicine, Stem cell Program and Institute for Genomic Medicine, University of California at San Diego, La Jolla, California, USA 2Department of Neurosciences, University of California at San Diego, La Jolla 3 Neurogenomics Lab, Benaroya Research Institute, Seattle, WA, USA 4Department of Physiology, Yong Loo Lin School of Medicine, National University of Singapore, Singapore 5Molecular Engineering Laboratory, A*STAR, Singapore §These authors contributed equally to this work *Corresponding authors: [email protected], [email protected] bioRxiv preprint doi: https://doi.org/10.1101/038448; this version posted February 1, 2016. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Abstract Background: Amyotrophic lateral sclerosis (ALS) is a fatal neurodegenerative disease primarily affecting motor neurons (MNs) to cause progressive paralysis. Ninety percent of cases are sporadic (sALS) and ten percent are familial (fALS). The molecular mechanisms underlying neurodegeneration remain elusive and there is a lack of promising biomarkers that define ALS phenotypes and progression. To date, most expression studies have focused on either complex whole tissues that contain cells other than MNs or induced pluripotent derived MNs (iMNs). -

Supplementary Figure 1: Specificity of Anti-TIGIT Antibody 1G9. TIGIT-Specific Antibodies Were Generated in TIGIT-/- Mice (Clone 1G9)
Supplementary Figure 1: Specificity of anti-TIGIT antibody 1G9. TIGIT-specific antibodies were generated in TIGIT-/- mice (clone 1G9). (A) 1G9 was titrated in an ELISA against recombinant mouse TIGIT or a control protein. (B) Anti-TIGIT antibody 1G9 was used to stain P815 cells transfected with mouse TIGIT (solid line) or the parental untransfected cell line as control (shaded histogram) and samples were analyzed by flow cytometry. (C) Primary T cells from B6 or TIGIT-/- mice were activated for 48h and stained using anti-TIGIT antibody 1G9 (solid line) or an isotype control (shaded histogram) and analyzed by flow cytometry. Samples are gated on the CD4+ population. Representative examples of 5 (A) or over 10 (B and C) independent experiments are shown. Supplementary Figure 2: TIGIT acts on APCs and on T cells. (A) CD4+ T cells were isolated and labeled with CFSE. Wild type B6 or TIGIT-/- CD4+ T cells were stimulated with anti-CD3 in the presence of irradiated APCs from wild type B6 or TIGIT-/- mice. Proliferation was analyzed after 60h using flow cytometry. (B) CD45.1 B6 recipients received 105 CD62L+CD4+ 2D2 or 2D2 x TIGIT-/- cells i.v. one day before s.c. immunization with 100μg MOG35-55 peptide in CFA. On day 7 spleens and lymph nodes (LN) were harvested and frequencies and absolute numbers of transferred CD45.2+ T cells were determined by flow cytometry (B; n=4). (C-E) TIGIT-specific antibodies were generated in Armenian hamsters (clone 4D4). (C) 4D4 was titrated in an ELISA against recombinant mouse TIGIT or a control protein. -

The RNA Helicase RHAU (DHX36) Unwinds a G4-Quadruplex in Human Telomerase RNA and Promotes the Formation of the P1 Helix Template Boundary E
4110–4124 Nucleic Acids Research, 2012, Vol. 40, No. 9 Published online 11 January 2012 doi:10.1093/nar/gkr1306 The RNA helicase RHAU (DHX36) unwinds a G4-quadruplex in human telomerase RNA and promotes the formation of the P1 helix template boundary E. P. Booy1,2, M. Meier1,2, N. Okun1, S. K. Novakowski1, S. Xiong1, J. Stetefeld1,2 and S. A. McKenna1,2,* 1Department of Chemistry, University of Manitoba, Winnipeg, Manitoba, Canada and 2Manitoba Group in Protein Structure and Function, University of Manitoba, Winnipeg, Manitoba, Canada R3N 2N2 Received November 4, 2011; Revised December 8, 2011; Accepted December 20, 2011 ABSTRACT (ATP)-dependent RNA helicase that belongs to the DExH/D family of RNA modifying enzymes. Proteins in Human telomerase RNA (hTR) contains several guan- 0 this family participate in a wide range of functions ine tracts at its 5 -end that can form a G4-quadruplex including RNA splicing, messenger RNA (mRNA) stabil- structure. Previous evidence suggests that a ity, ribosome assembly, microRNA processing, ribo- G4-quadruplex within this region disrupts the forma- nucleoprotein remodeling and RNA trafficking (1–4). tion of an important structure within hTR known as RHAU is primarily expressed in the nucleus and this the P1 helix, a critical element in defining the localization is dependent upon a region within the template boundary for reverse transcription. RNA N-terminus of the protein (5). In 2004, Tran et al. (6) associated with AU-rich element (RHAU) is an identified DHX36 as a protein from HeLa cell lysates RNA helicase that has specificity for DNA and RNA that bound with high affinity to the AU-rich element G4-quadruplexes. -

The Proteasomal Deubiquitinating Enzyme PSMD14 Regulates Macroautophagy by Controlling Golgi-To-ER Retrograde Transport
Supplementary Materials The proteasomal deubiquitinating enzyme PSMD14 regulates macroautophagy by controlling Golgi-to-ER retrograde transport Bustamante HA., et al. Figure S1. siRNA sequences directed against human PSMD14 used for Validation Stage. Figure S2. Primer pairs sequences used for RT-qPCR. Figure S3. The PSMD14 DUB inhibitor CZM increases the Golgi apparatus area. Immunofluorescence microscopy analysis of the Golgi area in parental H4 cells treated for 4 h either with the vehicle (DMSO; Control) or CZM. The Golgi marker GM130 was used to determine the region of interest in each condition. Statistical significance was determined by Student's t-test. Bars represent the mean ± SEM (n =43 cells). ***P <0.001. Figure S4. CZM causes the accumulation of KDELR1-GFP at the Golgi apparatus. HeLa cells expressing KDELR1-GFP were either left untreated or treated with CZM for 30, 60 or 90 min. Cells were fixed and representative confocal images were acquired. Figure S5. Effect of CZM on proteasome activity. Parental H4 cells were treated either with the vehicle (DMSO; Control), CZM or MG132, for 90 min. Protein extracts were used to measure in vitro the Chymotrypsin-like peptidase activity of the proteasome. The enzymatic activity was quantified according to the cleavage of the fluorogenic substrate Suc-LLVY-AMC to AMC, and normalized to that of control cells. The statistical significance was determined by One-Way ANOVA, followed by Tukey’s test. Bars represent the mean ± SD of biological replicates (n=3). **P <0.01; n.s., not significant. Figure S6. Effect of CZM and MG132 on basal macroautophagy. (A) Immunofluorescence microscopy analysis of the subcellular localization of LC3 in parental H4 cells treated with either with the vehicle (DMSO; Control), CZM for 4 h or MG132 for 6 h. -

Molecular Signatures Differentiate Immune States in Type 1 Diabetes Families
Page 1 of 65 Diabetes Molecular signatures differentiate immune states in Type 1 diabetes families Yi-Guang Chen1, Susanne M. Cabrera1, Shuang Jia1, Mary L. Kaldunski1, Joanna Kramer1, Sami Cheong2, Rhonda Geoffrey1, Mark F. Roethle1, Jeffrey E. Woodliff3, Carla J. Greenbaum4, Xujing Wang5, and Martin J. Hessner1 1The Max McGee National Research Center for Juvenile Diabetes, Children's Research Institute of Children's Hospital of Wisconsin, and Department of Pediatrics at the Medical College of Wisconsin Milwaukee, WI 53226, USA. 2The Department of Mathematical Sciences, University of Wisconsin-Milwaukee, Milwaukee, WI 53211, USA. 3Flow Cytometry & Cell Separation Facility, Bindley Bioscience Center, Purdue University, West Lafayette, IN 47907, USA. 4Diabetes Research Program, Benaroya Research Institute, Seattle, WA, 98101, USA. 5Systems Biology Center, the National Heart, Lung, and Blood Institute, the National Institutes of Health, Bethesda, MD 20824, USA. Corresponding author: Martin J. Hessner, Ph.D., The Department of Pediatrics, The Medical College of Wisconsin, Milwaukee, WI 53226, USA Tel: 011-1-414-955-4496; Fax: 011-1-414-955-6663; E-mail: [email protected]. Running title: Innate Inflammation in T1D Families Word count: 3999 Number of Tables: 1 Number of Figures: 7 1 For Peer Review Only Diabetes Publish Ahead of Print, published online April 23, 2014 Diabetes Page 2 of 65 ABSTRACT Mechanisms associated with Type 1 diabetes (T1D) development remain incompletely defined. Employing a sensitive array-based bioassay where patient plasma is used to induce transcriptional responses in healthy leukocytes, we previously reported disease-specific, partially IL-1 dependent, signatures associated with pre and recent onset (RO) T1D relative to unrelated healthy controls (uHC). -

Target Gene Gene Description Validation Diana Miranda
Supplemental Table S1. Mmu-miR-183-5p in silico predicted targets. TARGET GENE GENE DESCRIPTION VALIDATION DIANA MIRANDA MIRBRIDGE PICTAR PITA RNA22 TARGETSCAN TOTAL_HIT AP3M1 adaptor-related protein complex 3, mu 1 subunit V V V V V V V 7 BTG1 B-cell translocation gene 1, anti-proliferative V V V V V V V 7 CLCN3 chloride channel, voltage-sensitive 3 V V V V V V V 7 CTDSPL CTD (carboxy-terminal domain, RNA polymerase II, polypeptide A) small phosphatase-like V V V V V V V 7 DUSP10 dual specificity phosphatase 10 V V V V V V V 7 MAP3K4 mitogen-activated protein kinase kinase kinase 4 V V V V V V V 7 PDCD4 programmed cell death 4 (neoplastic transformation inhibitor) V V V V V V V 7 PPP2R5C protein phosphatase 2, regulatory subunit B', gamma V V V V V V V 7 PTPN4 protein tyrosine phosphatase, non-receptor type 4 (megakaryocyte) V V V V V V V 7 EZR ezrin V V V V V V 6 FOXO1 forkhead box O1 V V V V V V 6 ANKRD13C ankyrin repeat domain 13C V V V V V V 6 ARHGAP6 Rho GTPase activating protein 6 V V V V V V 6 BACH2 BTB and CNC homology 1, basic leucine zipper transcription factor 2 V V V V V V 6 BNIP3L BCL2/adenovirus E1B 19kDa interacting protein 3-like V V V V V V 6 BRMS1L breast cancer metastasis-suppressor 1-like V V V V V V 6 CDK5R1 cyclin-dependent kinase 5, regulatory subunit 1 (p35) V V V V V V 6 CTDSP1 CTD (carboxy-terminal domain, RNA polymerase II, polypeptide A) small phosphatase 1 V V V V V V 6 DCX doublecortin V V V V V V 6 ENAH enabled homolog (Drosophila) V V V V V V 6 EPHA4 EPH receptor A4 V V V V V V 6 FOXP1 forkhead box P1 V -

Transcript-Specific Cytoplasmic Degradation of YRA1 Pre-Mrna Mediated by the Yeast EDC3 Protein: a Dissertation
University of Massachusetts Medical School eScholarship@UMMS GSBS Dissertations and Theses Graduate School of Biomedical Sciences 2007-12-17 Transcript-Specific Cytoplasmic Degradation of YRA1 Pre-mRNA Mediated by the Yeast EDC3 Protein: A Dissertation Shuyun Dong University of Massachusetts Medical School Let us know how access to this document benefits ou.y Follow this and additional works at: https://escholarship.umassmed.edu/gsbs_diss Part of the Amino Acids, Peptides, and Proteins Commons, Biochemistry Commons, Bioinformatics Commons, Cells Commons, Computational Biology Commons, Fungi Commons, Genetic Phenomena Commons, Genetics Commons, Genomics Commons, Molecular Biology Commons, Molecular Genetics Commons, and the Nucleic Acids, Nucleotides, and Nucleosides Commons Repository Citation Dong S. (2007). Transcript-Specific Cytoplasmic Degradation of YRA1 Pre-mRNA Mediated by the Yeast EDC3 Protein: A Dissertation. GSBS Dissertations and Theses. https://doi.org/10.13028/ckcv-mt21. Retrieved from https://escholarship.umassmed.edu/gsbs_diss/352 This material is brought to you by eScholarship@UMMS. It has been accepted for inclusion in GSBS Dissertations and Theses by an authorized administrator of eScholarship@UMMS. For more information, please contact [email protected]. A Dissertation Presented By Shuyun Dong Submitted to the Faculty of the University of Massachusetts Graduate School of Biomedical School, Worcester In partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY IN BIOMEDICAL SCIENCE December