Tariq Alhindi | Jonas Pfeiffer | Smaranda Muresan
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Logical Fallacies Moorpark College Writing Center
Logical Fallacies Moorpark College Writing Center Ad hominem (Argument to the person): Attacking the person making the argument rather than the argument itself. We would take her position on child abuse more seriously if she weren’t so rude to the press. Ad populum appeal (appeal to the public): Draws on whatever people value such as nationality, religion, family. A vote for Joe Smith is a vote for the flag. Alleged certainty: Presents something as certain that is open to debate. Everyone knows that… Obviously, It is obvious that… Clearly, It is common knowledge that… Certainly, Ambiguity and equivocation: Statements that can be interpreted in more than one way. Q: Is she doing a good job? A: She is performing as expected. Appeal to fear: Uses scare tactics instead of legitimate evidence. Anyone who stages a protest against the government must be a terrorist; therefore, we must outlaw protests. Appeal to ignorance: Tries to make an incorrect argument based on the claim never having been proven false. Because no one has proven that food X does not cause cancer, we can assume that it is safe. Appeal to pity: Attempts to arouse sympathy rather than persuade with substantial evidence. He embezzled a million dollars, but his wife had just died and his child needed surgery. Begging the question/Circular Logic: Proof simply offers another version of the question itself. Wrestling is dangerous because it is unsafe. Card stacking: Ignores evidence from the one side while mounting evidence in favor of the other side. Users of hearty glue say that it works great! (What is missing: How many users? Great compared to what?) I should be allowed to go to the party because I did my math homework, I have a ride there and back, and it’s at my friend Jim’s house. -

The Nazi-Card-Card
ISSN 1751-8229 Volume Six, Number Three The Nazi-card-card Rasmus Ugilt, Aarhus University Introduction It should be made clear from the start that we all in fact already know the Nazi-card-card very well. At some point most of us have witnessed, or even been part of, a discussion that got just a little out of hand. In such situations it is not uncommon for one party to begin to draw up parallels between Germany in 1933 and his counterpart. Once this happens the counterpart will immediately play the Nazi-card-card and say something like, “Playing the Nazi-card are we? I never thought you would stoop that low. That is guaranteed to bring a quick end to any serious debate.” And just like that, the debate will in effect be over. It should be plain to anyone that it is just not right to make a Nazi of one’s opponent. The Nazi-card-card always wins. This tells us that it is in general unwise to play the Nazi-card, as it is bound to be immediately countered by the Nazi-card-card, but the lesson, I think, goes beyond mere rhetoric. Indeed, I believe that something quite profound and important goes on in situations like this, something which goes in a different direction to the perhaps more widely recognized Godwin’s Law, which could be formulated as follows: “As a discussion in an Internet forum grows longer, the probability of someone playing the Nazi-card approaches 1.” The more interesting law, I think, would be that 1 of the Nazi-card-card, which in similar language states: “The probability of someone playing the Nazi-card-card immediately after the Nazi-card has been played is always close to 1.” In the present work I seek to investigate and understand this curious second card. -

Fallacies in Reasoning
FALLACIES IN REASONING FALLACIES IN REASONING OR WHAT SHOULD I AVOID? The strength of your arguments is determined by the use of reliable evidence, sound reasoning and adaptation to the audience. In the process of argumentation, mistakes sometimes occur. Some are deliberate in order to deceive the audience. That brings us to fallacies. I. Definition: errors in reasoning, appeal, or language use that renders a conclusion invalid. II. Fallacies In Reasoning: A. Hasty Generalization-jumping to conclusions based on too few instances or on atypical instances of particular phenomena. This happens by trying to squeeze too much from an argument than is actually warranted. B. Transfer- extend reasoning beyond what is logically possible. There are three different types of transfer: 1.) Fallacy of composition- occur when a claim asserts that what is true of a part is true of the whole. 2.) Fallacy of division- error from arguing that what is true of the whole will be true of the parts. 3.) Fallacy of refutation- also known as the Straw Man. It occurs when an arguer attempts to direct attention to the successful refutation of an argument that was never raised or to restate a strong argument in a way that makes it appear weaker. Called a Straw Man because it focuses on an issue that is easy to overturn. A form of deception. C. Irrelevant Arguments- (Non Sequiturs) an argument that is irrelevant to the issue or in which the claim does not follow from the proof offered. It does not follow. D. Circular Reasoning- (Begging the Question) supports claims with reasons identical to the claims themselves. -
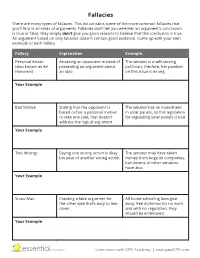
Fallacies There Are Many Types of Fallacies
Fallacies There are many types of fallacies. This list contains some of the more common fallacies that you’ll find in all kinds of arguments. Fallacies don’t tell you whether an argument’s conclusion is true or false; they simply don’t give you good reasons to believe that the conclusion is true. An argument based on only fallacies doesn’t contain good evidence. Come up with your own example of each fallacy. Fallacy Explanation Example Personal Attack Attacking an opponent instead of The senator is a self-serving (also known as Ad presenting an argument about politician; therfore, her position Hominem) an idea on this issue is wrong. Your Example Bad Motive Stating that the opponent is The senator has an investment based or has a personal motive in solar panels, so this legislation to take one side; that doesn’t for regulating solar panels is bad. address the logical argument Your Example Two Wrongs Saying one wrong action is okay The senator may have taken because of another wrong action money from large oil companies, but dozens of other senators have also. Your Example Straw Man Creating a fake argument for All home schooling laws give the other side that’s easy to tear away free diplomas for no work down and with no regulation; they should be eliminated. Your Example Learn more with GED Academy. | www.passGED.com Emotional Appeal Using emotion instead of We must fund this school district reasons and evidence to make bond if we care about our an argument children. Your Example Appeal to Fear Using the audience’s fear to try We must pass this law to to make them agree with the make prison sentences longer; claim otherwise your family might be attacked by criminals. -

The Thinker's Guide to Fallacies
The Thinker’s Guide to FALLACIES The Art of Mental Trickery and Manipulation RICHARD PAUL and LINDA ELDER ROWMAN & LITTLEFIELD Lanham • Boulder • New York • London 04 Fallacies TG 12.2012.indd 1 8/29/19 12:09 PM To understand the human mind, understand self-deception. Anon The word ‘fallacy’ derives from two Latin words, fallax (“deceptive”) and fallere (“to deceive”). This is an important concept in human life because much human thinking deceives itself while deceiving others. The human mind has no natural guide to the truth, nor does it naturally love the truth. What the human mind loves is itself, what serves it, what flatters it, what gives it what it wants, and what strikes down and destroys whatever “threatens” it. The study of fallacies can be pursued in at least two different ways. It can be approached traditionally: in which case one defines, explains, and exemplifies ways in which unsound arguments can be made to appear sound. Or it can be approached deeply, in which case one relates the construction of fallacies to the pursuit of human interests and irrational desires. Using the first approach, students gain little by memorizing the names and definitions of fallacies. They soon forget them. Their minds are left largely untouched and therefore unmoved. On the other hand, the second approach makes possible the acquisition of lifelong insights into how the mind – every mind – uses unsound arguments and intellectual “tricks” to further its ends. When we look closely at human decisions and human behavior, we can easily see that what counts in human life is not who is right, but who is winning. -

Two Kingdoms in the Third Reich Transcript
Two Kingdoms in the Third Reich Transcript Date: Thursday, 9 March 2017 - 1:00PM Location: Barnard's Inn Hall 9 March 2017 Two Kingdoms in the Third Reich Professor Alec Ryrie This is a series of lectures on ‘extreme Christianity’, and it does not get much more extreme than this. You are familiar with Godwin’s Law, also known as the reductio ad Hitlerum: the notion that every argument in the modern world eventually progresses to the point where someone invokes a Nazi comparison, and the whole thing then collapses. There is a reason for that. Thanks to the Nazis, since 1945 Western civilisation has had something which it had not had for at least two centuries before that: an all-but universally accepted reference point for evil. That is important for any attempt to understand our culture, but it is especially important from the point of view of the history of religion in the West. Because defining evil, the whole business of mapping out what morality is, is supposed to be the core business of any religious community. And in the case of Nazism, Europe’s main religious communities plainly failed to do this. The slow realisation of Nazism’s evil was an essentially secular event, and the fact that our public life is now organised around an essentially secular definition of evil seems to me to be a key fact in understanding the history of religion in modern times. Today I want to look at the sorry story of how German’s Christian communities responded to Nazism: a story of collaboration, enthusiastic enabling, and of strictly limited pushback. -

Fine-Tuned Neural Models for Propaganda Detection at the Sentence and Fragment Levels
Fine-Tuned Neural Models for Propaganda Detection at the Sentence and Fragment levels Tariq Alhindiy Jonas Pfeiffer∗ Smaranda Muresanyz yDepartment of Computer Science, Columbia University zData Science Institute, Columbia University ∗Ubiquitous Knowledge Processing Lab, Technische Universitat Darmstadt ftariq.a, [email protected] [email protected] Abstract pressed in a text fragment together with the be- ginning and the end of that text fragment. This This paper presents the CUNLP submission task is evaluated based on the prediction of the for the NLP4IF 2019 shared-task on Fine- type of propaganda technique and the intersec- Grained Propaganda Detection. Our system finished 5th out of 26 teams on the sentence- tion between the gold and the predicted spans. level classification task and 5th out of 11 teams The details to the evaluation measure used for the on the fragment-level classification task based FLC task are explained in Da San Martino et al. on our scores on the blind test set. We present (2019a). Both sub-tasks were automatically eval- our models, a discussion of our ablation stud- uated on a unified development set. The system ies and experiments, and an analysis of our performance was centrally assessed without dis- performance on all eighteen propaganda tech- tributing the gold labels, however allowing for an niques present in the corpus of the shared task. unlimited number of submissions. The final per- 1 Introduction formance on the test set was similarly evaluated, with the difference that the feedback was given Propaganda aims at influencing a target audience only after the submission was closed, simultane- with a specific group agenda using faulty reason- ously concluding the shared-task. -

On Playing the Nazi Card
Tob Control: first published as 10.1136/tc.2008.026344 on 25 September 2008. Downloaded from Editorial (1959); ‘‘scare stories’’ (1959); ‘‘time-worn On playing the Nazi card and much-criticized statistical charges’’ (1959); ‘‘extreme and unwarranted con- clusions’’ (1959); ‘‘foggy thinking’’ (1962); Professor Robert N Proctor ‘‘a rehash of previously inconclusive find- ings’’ (1962); ‘‘the easy answer to a Schneider and Glantz in this issue (see tobacco taxes helped prop up the Nazi state complex problem’’ (1962); ‘‘fanciful the- page 291) chronicle the industry’s long- (more than half of all storm-trooper ories’’ (1964); ‘‘propaganda blast’’ (1964); standing efforts to characterise tobacco income, for example, was from tobacco ‘‘statistical volleyball’’ (1965); ‘‘utterly control as ‘‘Nazi’’ or ‘‘fascist’’.1 The indus- taxes).2 They never point out that while without factual support’’ (1965); ‘‘exag- try’s rant has a certain superficial plausi- Nazi authorities tried to curtail smoking, gerations and misstatements of fact’’ bility: the Nazis had one of the world’s the industry was already powerful enough (1967); ‘‘guilt by association’’ (1968); strongest anti-cancer campaigns, one cen- to resist most of these encroachments. The ‘‘‘guesses, assumptions, and suspicions’’ tral feature of which was to curtail tobacco fact is that the Nazi war on tobacco was (1968); ‘‘worse than meaningless’’ (1969); use. Hitler himself stopped smoking in never waged as effectively as, say, the ‘‘claptrap’’ (1969); ‘‘a bum rap’’ (1969); 1919, throwing his cigarettes into the destruction of the Jews. Cigarettes were ‘‘colossal blunder’’ (1970); ‘‘one of the Danube in an act of defiance he later distributed to German soldiers throughout great scientific hoaxes of our time’’ credited for helping the triumph of the war, and cigarettes were still being (1970); ‘‘claims of the anti-cigarette Nazism. -

Propaganda Techniques
Propaganda Techniques Adapted from Wikipedia Ad hominem ( “to the person”) A Lan phrase which has come to mean aacking your opponent, as opposed to aacking their arguments. Ex. "Your fashion opinion isn't valid; you can't even afford new shoes." Ad nauseam (“to the point of nausea”) or Repe==on This argument approach uses =reless repe==on of an idea. An idea, especially a simple slogan, that is repeated enough =mes, may begin to be taken as the truth. This approach works best when media sources are limited and controlled by the propagator. Ex. Appeal to authority Appeals to authority; cite prominent figures to support a posi=on, idea, argument, or course of ac=on. Ex. “Even the President has smoked pot!” Appeal to fear Appeals to fear seek to build support by ins=lling anxie=es and panic in the general populaon. Ex. Joseph Goebbels exploited Theodore N. Kaufman's Germany Must Perish! to claim that the Allies sought the exterminaon of the German people. Appeal to prejudice • Using loaded or emo=ve terms to aach value or moral goodness to believing the proposion. • Ex: "Any hard-working taxpayer would have to agree that those who do not work, and who do not support the community do not deserve the community's support through social assistance." Bandwagon Bandwagon and "inevitable-victory" appeals aempt to persuade the target audience to join in and take the course of ac=on that "everyone else is taking”. Black-and-White fallacy • Presen=ng only two choices, with the product or idea being propagated as the be?er choice. -

The Field of Logical Reasoning
The Field of Logical Reasoning: (& The back 40 of Bad Arguments) Adapted from: An Illustrated Book of Bad Arguments: Learn the lost art of making sense by Ali Almossawi *Not, by any stretch of the imagination, the only source on this topic… Disclaimer This is not the only (or even best) approach to thinking, examining, analyzing creating policy, positions or arguments. “Logic no more explains how we think than grammar explains how we speak.” M. Minsky Other Ways… • Logical Reasoning comes from Age-Old disciplines/practices of REASON. • But REASON is only ONE human characteristic • Other methods/processes are drawn from the strengths of other characteristics Other Human Characteristics: • John Ralston Saul (Unconscious Civilization, 1995) lists SIX Human Characteristics • They are (alphabetically, so as not to create a hierarchy): • Common Sense • Intuition • Creativity • Memory • Ethics • Reason Reason is not Superior • While this presentation focuses on the practices of REASON, it is necessary to actively engage our collective notions rooted in: • Common Sense (everyday understandings) • Creativity (new, novel approaches) • Ethics (relative moral high-ground) • Intuition (gut instinct) • Memory (history, stories) …in order to have a holistic/inclusive approach to reasonable doubt and public participation. However: • Given the west’s weakness for Reason and the relative dominance of Reason in public policy, we need to equip ourselves and understand its use and misuse. • Enter: The Field of Logical Reasoning vs. Logical Fallacy Appeal to Hypocrisy Defending an error in one's reasoning by pointing out that one's opponent has made the same error. What’s a Logical Fallacy? • ALL logical fallacies are a form of Non- Sequitur • Non sequitur, in formal logic, is an argument in which its conclusion does not follow from its premises. -

Alabama State University Department of Languages and Literatures
ALABAMA STATE UNIVERSITY DEPARTMENT OF LANGUAGES AND LITERATURES COURSE SYLLABUS PHILOSOPHY 201 LOGICAL REASONING (PHL 201) (Revised 10/20/04 – Dr. Daniel Keller.) I. Faculty Listing: PHL 201: Logical Reasoning (3 credit hours) II. Description: To satisfactorily complete the course, a student must earn a grade of “C.” The course is designed to help students assess information and arguments and to improve their ability to reason in a clear and logical way. The course concentrates specifically on helping students learn some of the various uses of languages, understand how different kinds of inferences are drawn, and learn to recognize fallacies of ambiguity, presumption, and relevance. III. Purpose: Many students do not reason soundly and do not distinguish correct from incorrect reasoning. Hence, the aim of this course is to give students experience in learning to recognize and evaluate arguments; it also aims at teaching them to construct arguments that are reasonable and defensible. It is designed as a basic course to improve the reasoning skills of students. After completing this course successfully, students should show improvements in reading comprehension, writing, and test- taking skills. IV. Course Objectives: 1. Comprehend concepts 1-9 on the attached list. a) Define each concept b) Identify the meaning of each concept as it applies to logic. 2. Comprehend how these concepts function in logical reasoning. a) Given examples from the text of each concept, correctly identify the concept. b) Given new examples of each concept, correctly identify the concept. 3. Comprehend concepts 10-16 on the attached list. a) Define the concepts b) Identify the meaning of the concept as it applies to logic. -

Fallacy: a Defect in an Argument That Arises from a Mistake in Reasoning Or the Creation of an Illusion That Makes a Bad Argument Appear Good
Fallacy: A defect in an argument that arises from a mistake in reasoning or the creation of an illusion that makes a bad argument appear good. There are two kinds of fallacy: • Formal fallacy: Detectable by analyzing the form of an argument • Informal fallacy: Detectable only by analyzing the content of an argument Fallacies of Relevance: The premises are not relevant to the conclusion: • Appeal to force: Arguer threatens the reader/ listener. • Appeal to pity: Arguer elicits pity from the reader/ listener. • Appeal to the people (Ad Populum): Arguer incites a mob mentality ( direct form) or appeals to our desire for security, love, or respect ( indirect form). This fallacy includes appeal to fear, the bandwagon argument, appeal to vanity, appeal to snobbery, and appeal to tradition. • Argument against the person (Ad hominems): -Arguer personally attacks an opposing arguer by verbally abusing the opponent ( ad hominem abusive) – Presenting the opponent as predisposed to argue as he or she does ( ad hominen circumstantial), or by – Presenting the opponent as a hypocrite ( tu quoque). For ad hominem to occur, there must be two arguers. • Accident: A general rule is applied to a specific case it was not intended to cover. • Straw man: Arguer distorts an opponent’s argument and then attacks the distorted argument. N ote: For this fallacy to occur, there must be two arguers. • Missing the point: Arguer draws a conclusion different from the one supported by the premises. N ote: Do not cite this fallacy if another fallacy fits. • Red herring: Arguer leads the reader/ listener off the track. Fallacies of Weak Induction: The premises may be relevant to the conclusion, but they supply insufficient support for the conclusion: • Appeal to unqualified authority: Arguer cites an untrustworthy authority.