Rethinking Star Selection for Celestial Navigation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Basic Principles of Celestial Navigation James A
Basic principles of celestial navigation James A. Van Allena) Department of Physics and Astronomy, The University of Iowa, Iowa City, Iowa 52242 ͑Received 16 January 2004; accepted 10 June 2004͒ Celestial navigation is a technique for determining one’s geographic position by the observation of identified stars, identified planets, the Sun, and the Moon. This subject has a multitude of refinements which, although valuable to a professional navigator, tend to obscure the basic principles. I describe these principles, give an analytical solution of the classical two-star-sight problem without any dependence on prior knowledge of position, and include several examples. Some approximations and simplifications are made in the interest of clarity. © 2004 American Association of Physics Teachers. ͓DOI: 10.1119/1.1778391͔ I. INTRODUCTION longitude ⌳ is between 0° and 360°, although often it is convenient to take the longitude westward of the prime me- Celestial navigation is a technique for determining one’s ridian to be between 0° and Ϫ180°. The longitude of P also geographic position by the observation of identified stars, can be specified by the plane angle in the equatorial plane identified planets, the Sun, and the Moon. Its basic principles whose vertex is at O with one radial line through the point at are a combination of rudimentary astronomical knowledge 1–3 which the meridian through P intersects the equatorial plane and spherical trigonometry. and the other radial line through the point G at which the Anyone who has been on a ship that is remote from any prime meridian intersects the equatorial plane ͑see Fig. -

Pulsarplane D5.4 Final Report
NLR-CR-2015-243-PT16 PulsarPlane D5.4 Final Report Authors: H. Hesselink, P. Buist, B. Oving, H. Zelle, R. Verbeek, A. Nooroozi, C. Verhoeven, R. Heusdens, N. Gaubitch, S. Engelen, A. Kestilä, J. Fernandes, D. Brito, G. Tavares, H. Kabakchiev, D. Kabakchiev, B. Vasilev, V. Behar, M. Bentum Customer EC Contract number ACP2-GA-2013-335063 Owner PulsarPlane consortium Classification Public Date July 2015 PROJECT FINAL REPORT Grant Agreement number: 335063 Project acronym: PulsarPlane Project title: PulsarPlane Funding Scheme: FP7 L0 Period covered: from September 2013 to May 2015 Name of the scientific representative of the project's co-ordinator, Title and Organisation: H.H. (Henk) Hesselink Sr. R&D Engineer National Aerospace Laboratory, NLR Tel: +31.88.511.3445 Fax: +31.88.511.3210 E-mail: [email protected] Project website address: www.pulsarplane.eu Summary Contents 1 Introduction 4 1.1 Structure of the document 4 1.2 Acknowledgements 4 2 Final publishable summary report 5 2.1 Executive summary 5 2.2 Summary description of project context and objectives 6 2.2.1 Introduction 6 2.2.2 Description of PulsarPlane concept 6 2.2.3 Detection 8 2.2.4 Navigation 8 2.3 Main S&T results/foregrounds 9 2.3.1 Navigation based on signals from radio pulsars 9 2.3.2 Pulsar signal simulator 11 2.3.3 Antenna 13 2.3.4 Receiver 15 2.3.5 Signal processing 22 2.3.6 Navigation 24 2.3.7 Operating a pulsar navigation system 30 2.3.8 Performance 31 2.4 Potential impact and the main dissemination activities and exploitation of results 33 2.4.1 Feasibility 34 2.4.2 Costs, benefits and impact 35 2.4.3 Environmental impact 36 2.5 Public website 37 2.6 Project logo 37 2.7 Diagrams or photographs illustrating and promoting the work of the project 38 2.8 List of all beneficiaries with the corresponding contact names 39 3 Use and dissemination of foreground 41 4 Report on societal implications 46 5 Final report on the distribution of the European Union financial contribution 53 1 Introduction This document is the final report of the PulsarPlane project. -

Celestial Navigation At
Celestial Navigation at Sea Agenda • Moments in History • LOP (Bearing “Line of Position”) -- in piloting and celestial navigation • DR Navigation: Cornerstone of Navigation at Sea • Ocean Navigation: Combining DR Navigation with a fix of celestial body • Tools of the Celestial Navigator (a Selection, including Sextant) • Sextant Basics • Celestial Geometry • Time Categories and Time Zones (West and East) • From Measured Altitude Angles (the Sun) to LOP • Plotting a Sun Fix • Landfall Strategies: From NGA-Ocean Plotting Sheet to Coastal Chart Disclaimer! M0MENTS IN HISTORY 1731 John Hadley (English) and Thomas Godfrey (Am. Colonies) invent the Sextant 1736 John Harrison (English) invents the Marine Chronometer. Longitude can now be calculated (Time/Speed/Distance) 1766 First Nautical Almanac by Nevil Maskelyne (English) 1830 U.S. Naval Observatory founded (Nautical Almanac) An Ancient Practice, again Alive Today! Celestial Navigation Today • To no-one’s surprise, for most boaters today, navigation = electronics to navigate. • The Navy has long relied on it’s GPS-based Voyage Management System. (GPS had first been developed as a U.S. military “tool”.) • If celestial navigation comes to mind, it may bring up romantic notions or longing: Sailing or navigating “by the stars” • Yet, some study, teach and practice Celestial Navigation to keep the skill alive—and, once again, to keep our nation safe Celestial Navigation comes up in literature and film to this day: • Master and Commander with Russell Crowe and Paul Bettany. Film based on: • The “Aubrey and Maturin” novels by Patrick O’Brian • Horatio Hornblower novels by C. S. Forester • The Horatio Hornblower TV series, etc. • Airborne by William F. -

Lunar Distances Final
A (NOT SO) BRIEF HISTORY OF LUNAR DISTANCES: LUNAR LONGITUDE DETERMINATION AT SEA BEFORE THE CHRONOMETER Richard de Grijs Department of Physics and Astronomy, Macquarie University, Balaclava Road, Sydney, NSW 2109, Australia Email: [email protected] Abstract: Longitude determination at sea gained increasing commercial importance in the late Middle Ages, spawned by a commensurate increase in long-distance merchant shipping activity. Prior to the successful development of an accurate marine timepiece in the late-eighteenth century, marine navigators relied predominantly on the Moon for their time and longitude determinations. Lunar eclipses had been used for relative position determinations since Antiquity, but their rare occurrences precludes their routine use as reliable way markers. Measuring lunar distances, using the projected positions on the sky of the Moon and bright reference objects—the Sun or one or more bright stars—became the method of choice. It gained in profile and importance through the British Board of Longitude’s endorsement in 1765 of the establishment of a Nautical Almanac. Numerous ‘projectors’ jumped onto the bandwagon, leading to a proliferation of lunar ephemeris tables. Chronometers became both more affordable and more commonplace by the mid-nineteenth century, signaling the beginning of the end for the lunar distance method as a means to determine one’s longitude at sea. Keywords: lunar eclipses, lunar distance method, longitude determination, almanacs, ephemeris tables 1 THE MOON AS A RELIABLE GUIDE FOR NAVIGATION As European nations increasingly ventured beyond their home waters from the late Middle Ages onwards, developing the means to determine one’s position at sea, out of view of familiar shorelines, became an increasingly pressing problem. -

Celestial Navigation Practical Theory and Application of Principles
Celestial Navigation Practical Theory and Application of Principles By Ron Davidson 1 Contents Preface .................................................................................................................................................................................. 3 The Essence of Celestial Navigation ...................................................................................................................................... 4 Altitudes and Co-Altitudes .................................................................................................................................................... 6 The Concepts at Work ........................................................................................................................................................ 12 A Bit of History .................................................................................................................................................................... 12 The Mariner’s Angle ........................................................................................................................................................ 13 The Equal-Altitude Line of Position (Circle of Position) ................................................................................................... 14 Using the Nautical Almanac ............................................................................................................................................ 15 The Limitations of Mechanical Methods ........................................................................................................................ -

Spacecraft Navigation Using X-Ray Pulsars
JOURNAL OF GUIDANCE,CONTROL, AND DYNAMICS Vol. 29, No. 1, January–February 2006 Spacecraft Navigation Using X-Ray Pulsars Suneel I. Sheikh∗ and Darryll J. Pines† University of Maryland, College Park, Maryland 20742 and Paul S. Ray,‡ Kent S. Wood,§ Michael N. Lovellette,¶ and Michael T. Wolff∗∗ U.S. Naval Research Laboratory, Washington, D.C. 20375 The feasibility of determining spacecraft time and position using x-ray pulsars is explored. Pulsars are rapidly rotating neutron stars that generate pulsed electromagnetic radiation. A detailed analysis of eight x-ray pulsars is presented to quantify expected spacecraft position accuracy based on described pulsar properties, detector parameters, and pulsar observation times. In addition, a time transformation equation is developed to provide comparisons of measured and predicted pulse time of arrival for accurate time and position determination. This model is used in a new pulsar navigation approach that provides corrections to estimated spacecraft position. This approach is evaluated using recorded flight data obtained from the unconventional stellar aspect x-ray timing experiment. Results from these data provide first demonstration of position determination using the Crab pulsar. Introduction sources, including neutron stars, that provide stable, predictable, and HROUGHOUT history, celestial sources have been utilized unique signatures, may provide new answers to navigating through- T for vehicle navigation. Many ships have successfully sailed out the solar system and beyond. the Earth’s oceans using only these celestial aides. Additionally, ve- This paper describes the utilization of pulsar sources, specifically hicles operating in the space environment may make use of celestial those emitting in the x-ray band, as navigation aides for spacecraft. -

Navigation: the Mariner's Quadrant
Navigation: The Mariner's Quadrant The quadrant is a very simple tool that allows the user to determine his or her latitude by measuring the altitude of a heavenly body. When used in celestial navigation or astronomy, altitude means the angle of elevation between the horizon and celestial bodies like the sun, planets, moon, or stars. The quadrant takes it name from its shape, which is a quarter of a circle. Invented by the Greeks around 240 B.C., several different types of quadrants have been used over the past 2500 years. Early quadrants used a 90 degree arc and a string Quadrants were often designed for bob to determine the angle of elevation to the sun, Polaris, and other celestial bodies. a specific use. Artillery officers used a simplified quadrant known as a gunner’s quadrant for aiming their guns and measuring distance. Astronomers used a far more complicated version of the quadrant that was engraved with geometrical and square lines showing the sun's path through the signs of the zodiac. Although average seamen would not have had much use for the complicated quadrants used by astronomers, they found that a simplified version was very useful for determining their latitude at sea. Cut from a piece of metal plate or wood, the mariner’s quadrant had a radius of about 6-8 inches. It had a pair of rectangular plates with pinhole sights on one of the straight edges for sighting. The only scale needed was the degree marks on the curved edge. It was light and easy to handle. -

Chapter 16 Instruments for Celestial Navigation
CHAPTER 16 INSTRUMENTS FOR CELESTIAL NAVIGATION THE MARINE SEXTANT 1600. Description and Use In Figure 1601, AB is a ray of light from a celestial body. The index mirror of the sextant is at B, the horizon glass at C, The marine sextant measures the angle between two and the eye of the observer at D. Construction lines EF and points by bringing the direct image from one point and a CF are perpendicular to the index mirror and horizon glass, double-reflected image from the other into coincidence. Its respectively. Lines BG and CG are parallel to these mirrors. principal use is to measure the altitudes of celestial bodies Therefore, angles BFC and BGC are equal because their above the visible sea horizon. It may also be used to measure sides are mutually perpendicular. Angle BGC is the vertical angles to find the range from an object of known inclination of the two reflecting surfaces. The ray of light AB height. Sometimes it is turned on its side and used for is reflected at mirror B, proceeds to mirror C, where it is measuring the angular distance between two terrestrial again reflected, and then continues on to the eye of the objects. observer at D. Since the angle of reflection is equal to the angle of incidence, A marine sextant can measure angles up to approxi- ABE = EBC, and ABC = 2EBC. ° mately 120 . Originally, the term “sextant” was applied to BCF = FCD, and BCD = 2BCF. the navigator’s double-reflecting, altitude-measuring ° instrument only if its arc was 60 in length, or 1/6 of a Since an exterior angle of a triangle equals the sum of ° ° circle, permitting measurement of angles from 0 to 120 . -

Intro to Celestial Navigation
Introduction to Celestial Navigation Capt. Alison Osinski 2 Introduction to Celestial Navigation Wow, I lost my charts, and the GPS has quit working. Even I don’t know where I am. Was is celestial navigation? Navigation at sea based on the observation of the apparent position of celestial bodies to determine your position on earth. What you Need to use Celestial Navigation (Altitude Intercept Method of Sight Reduction) 1. A sextant is used to measure the altitude of a celestial object, by taking “sights” or angular measurements between the celestial body (sun, moon, stars, planets) and the visible horizon to find your position (latitude and longitude) on earth. Examples: Astra IIIB $699 Tamaya SPICA $1,899 Davis Master Mark 25 $239 3 Price range: Under $200 - $1,900 Metal sextants are more accurate, heavier, need fewer adjustments, and are more expensive than plastic sextants, but plastic sextants are good enough if you’re just going to use them occasionally, or stow them in your life raft or ditch bag. Spend the extra money on purchasing a sextant with a whole horizon rather than split image mirror. Traditional sextants had a split image mirror which divided the image in two. One side was silvered to give a reflected view of the celestial body. The other side of the mirror was clear to give a view of the horizon. The advantage of a split image mirror is that the image may be slightly brighter because more light is reflected through the telescope. This is an advantage if you are going to take most of your shots of stars at twilight. -

Navigation Education Lesson 8: Satellite Navigation
Navigating at the Speed of Satellites Unit Topic: Navigation Grade Level: 7th grade (with suggestions to scale for grades 6 to 8) Lesson No. 8 of 10 Lesson Subject(s): The Global Positioning System (GPS), time, position. Key Words: GPS, Satellite, Receiver, Speed of Light, Trilateration, Triangulation Lesson Abstract — Navigators have looked to the sky for direction for thousands of years. Today, celestial navigation has simply switched from natural objects to artificial satellites. A constellation of satellites, called the Global Positioning System (GPS), and hand-held receivers allow very accurate navigation. How do they work? The basic concepts of the system — trilateration and using the speed of light to calculate distances — will be investigated in this lesson. Lesson activities are: • State your Position – students discover how several GPS satellites are used to find a position. • It’s About Time – students act out the part of the GPS signal traveling to the receiver to learn how travel time is converted to distance. Lesson Opening Topics / Motivation — The idea of using satellites for navigation began with the launch of Sputnik 1 on October 4, 1957. Scientists at Johns Hopkins University's Applied Physics Laboratory monitored the satellite. They noticed that when the transmitted radio frequency was plotted on a graph, a characteristic curve of a Doppler shift appeared. By studying the change in radio frequency as the satellite passed overhead, they were able to figure out the orbit of Sputnik. It turns out that you can use this same concept in reverse. If the satellite orbit is known, measurements of frequency shift can be used to find a location on the earth. -
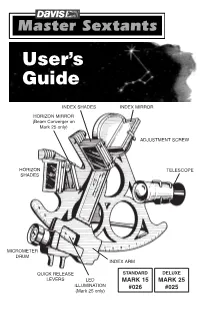
Sextant User's Guide
Master Sextant User’s Guide 00026.710, Rev. F October 2008 Total pages 24 Trim to 5.5 x 8.5" Black ink only User’s Guide INDEX SHADES INDEX MIRROR HORIZON MIRROR (Beam Converger on Mark 25 only) ADJUSTMENT SCREW HORIZON TELESCOPE SHADES MICROMETER DRUM INDEX ARM QUICK RELEASE STANDARD DELUXE LEVERS LED MARK 15 MARK 25 ILLUMINATION #026 #025 (Mark 25 only) Page 1 (front cover) Replacement Parts Contact your local dealer or Davis Instruments to order replacement parts or factory overhaul. Mark 25 Sextant, product #025 R014A Sextant case R014B Foam set for case R025A Index shade assembly (4 shades) R025B Sun shade assembly (3 shades) R025C 3× telescope R026J Extra copy of these instructions R025F Beam converger with index mirror, springs, screws, nuts R025G Sight tube R026D Vinyl eye cup R026G 8 springs, 3 screws, 4 nuts R025X Overhaul Mark 15 Sextant, product #026 R014A Sextant case R014B Foam set for case R026A Index shade assembly (4 shades) R026B Sun shade assembly (3 shades) R026C 3× telescope R026D Vinyl eye cup R026G 8 springs, 3 screws, 4 nuts R026H Index and horizon mirror with springs, screws, nuts R026J Extra copy of these instructions R026X Overhaul R026Y Sight tube Master Sextants User’s Guide Products #025, #026 © 2008 Davis Instruments Corp. All rights reserved. 00026.710, Rev. F October 2008 USING YOUR DAVIS SEXTANT This booklet gives the following information about your new Davis Sextant: • Operating the sextant • Finding the altitude of the sun using the sextant • Using sextant readings to calculate location • Other uses for the sextant To get the most benefit from your sextant, we suggest you familiarize yourself with the meridian transit method of navigation. -

Bowditch on Cel
These are Chapters from Bowditch’s American Practical Navigator click a link to go to that chapter CELESTIAL NAVIGATION CHAPTER 15. NAVIGATIONAL ASTRONOMY 225 CHAPTER 16. INSTRUMENTS FOR CELESTIAL NAVIGATION 273 CHAPTER 17. AZIMUTHS AND AMPLITUDES 283 CHAPTER 18. TIME 287 CHAPTER 19. THE ALMANACS 299 CHAPTER 20. SIGHT REDUCTION 307 School of Navigation www.starpath.com Starpath Electronic Bowditch CHAPTER 15 NAVIGATIONAL ASTRONOMY PRELIMINARY CONSIDERATIONS 1500. Definition ing principally with celestial coordinates, time, and the apparent motions of celestial bodies, is the branch of as- Astronomy predicts the future positions and motions tronomy most important to the navigator. The symbols of celestial bodies and seeks to understand and explain commonly recognized in navigational astronomy are their physical properties. Navigational astronomy, deal- given in Table 1500. Table 1500. Astronomical symbols. 225 226 NAVIGATIONAL ASTRONOMY 1501. The Celestial Sphere server at some distant point in space. When discussing the rising or setting of a body on a local horizon, we must locate Looking at the sky on a dark night, imagine that celes- the observer at a particular point on the earth because the tial bodies are located on the inner surface of a vast, earth- setting sun for one observer may be the rising sun for centered sphere. This model is useful since we are only in- another. terested in the relative positions and motions of celestial Motion on the celestial sphere results from the motions bodies on this imaginary surface. Understanding the con- in space of both the celestial body and the earth. Without cept of the celestial sphere is most important when special instruments, motions toward and away from the discussing sight reduction in Chapter 20.