Beyond the Remake of Shadow of the Colossus a Technical Perspective
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

(TMIIIP) Paid Projects Through August 31, 2020 Report Created 9/29/2020
Texas Moving Image Industry Incentive Program (TMIIIP) Paid Projects through August 31, 2020 Report Created 9/29/2020 Company Project Classification Grant Amount In-State Spending Date Paid Texas Jobs Electronic Arts Inc. SWTOR 24 Video Game $ 212,241.78 $ 2,122,417.76 8/19/2020 26 Tasmanian Devil LLC Tasmanian Devil Feature Film $ 19,507.74 $ 260,103.23 8/18/2020 61 Tool of North America LLC Dick's Sporting Goods - DecembeCommercial $ 25,660.00 $ 342,133.35 8/11/2020 53 Powerhouse Animation Studios, In Seis Manos (S01) Television $ 155,480.72 $ 1,554,807.21 8/10/2020 45 FlipNMove Productions Inc. Texas Flip N Move Season 7 Reality Television $ 603,570.00 $ 4,828,560.00 8/6/2020 519 FlipNMove Productions Inc. Texas Flip N Move Season 8 (13 E Reality Television $ 305,447.00 $ 2,443,576.00 8/6/2020 293 Nametag Films Dallas County Community CollegeCommercial $ 14,800.28 $ 296,005.60 8/4/2020 92 The Lost Husband, LLC The Lost Husband Feature Film $ 252,067.71 $ 2,016,541.67 8/3/2020 325 Armature Studio LLC Scramble Video Game $ 33,603.20 $ 672,063.91 8/3/2020 19 Daisy Cutter, LLC Hobby Lobby Christmas 2019 Commercial $ 10,229.82 $ 136,397.63 7/31/2020 31 TVM Productions, Inc. Queen Of The South - Season 2 Television $ 4,059,348.19 $ 18,041,547.51 5/1/2020 1353 Boss Fight Entertainment, Inc Zombie Boss Video Game $ 268,650.81 $ 2,149,206.51 4/30/2020 17 FlipNMove Productions Inc. -

Demon's Souls Free Download Pc Demon’S Souls PC Download Free
demon's souls free download pc Demon’s Souls PC Download Free. Demon’s Souls Pc Download – Everything you need to know. Demon’s Souls is a best action role-playing game that is created by Fromsoftware that is available for the PlayStation 3. This particular game is published by Sony computer Entertainment by February 2009. It is associated with little bit complicated gameplay where players has to make the control five different worlds from hub that is well known as Nexus. It is little bit complicated game where you will have to create genuine strategies. It is your responsibility to consider right platform where you can easily get Demon’s Souls Pc Download. You will able to make the access of both modes like single player and multiplayer. It is classic video game where you will have to create powerful character that will enable you to win the game. All you need to perform the role of adventurer. In the forthcoming pargraphs, we are going to discuss important information regarding Demon’s Souls. Demon’s Souls Download – Important things to know. If you want to get Demon’s Souls Download then user should find out right service provider that will able to offer the game with genuine features. In order to win such complicated game then a person should pay close attention on following important things. Gameplay. Demon’s Souls is one of the most complicated game where you will have to explore cursed land of Boletaria. In order to choose a player then a person should pay close attention on the character class. -
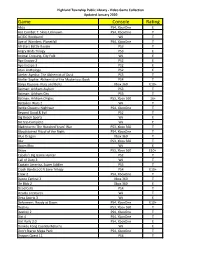
Game Console Rating
Highland Township Public Library - Video Game Collection Updated January 2020 Game Console Rating Abzu PS4, XboxOne E Ace Combat 7: Skies Unknown PS4, XboxOne T AC/DC Rockband Wii T Age of Wonders: Planetfall PS4, XboxOne T All-Stars Battle Royale PS3 T Angry Birds Trilogy PS3 E Animal Crossing, City Folk Wii E Ape Escape 2 PS2 E Ape Escape 3 PS2 E Atari Anthology PS2 E Atelier Ayesha: The Alchemist of Dusk PS3 T Atelier Sophie: Alchemist of the Mysterious Book PS4 T Banjo Kazooie- Nuts and Bolts Xbox 360 E10+ Batman: Arkham Asylum PS3 T Batman: Arkham City PS3 T Batman: Arkham Origins PS3, Xbox 360 16+ Battalion Wars 2 Wii T Battle Chasers: Nightwar PS4, XboxOne T Beyond Good & Evil PS2 T Big Beach Sports Wii E Bit Trip Complete Wii E Bladestorm: The Hundred Years' War PS3, Xbox 360 T Bloodstained Ritual of the Night PS4, XboxOne T Blue Dragon Xbox 360 T Blur PS3, Xbox 360 T Boom Blox Wii E Brave PS3, Xbox 360 E10+ Cabela's Big Game Hunter PS2 T Call of Duty 3 Wii T Captain America, Super Soldier PS3 T Crash Bandicoot N Sane Trilogy PS4 E10+ Crew 2 PS4, XboxOne T Dance Central 3 Xbox 360 T De Blob 2 Xbox 360 E Dead Cells PS4 T Deadly Creatures Wii T Deca Sports 3 Wii E Deformers: Ready at Dawn PS4, XboxOne E10+ Destiny PS3, Xbox 360 T Destiny 2 PS4, XboxOne T Dirt 4 PS4, XboxOne T Dirt Rally 2.0 PS4, XboxOne E Donkey Kong Country Returns Wii E Don't Starve Mega Pack PS4, XboxOne T Dragon Quest 11 PS4 T Highland Township Public Library - Video Game Collection Updated January 2020 Game Console Rating Dragon Quest Builders PS4 E10+ Dragon -

Press Start: Video Games and Art
Press Start: Video Games and Art BY ERIN GAVIN Throughout the history of art, there have been many times when a new artistic medium has struggled to be recognized as an art form. Media such as photography, not considered an art until almost one hundred years after its creation, were eventually accepted into the art world. In the past forty years, a new medium has been introduced and is increasingly becoming more integrated into the arts. Video games, and their rapid development, provide new opportunities for artists to convey a message, immersing the player in their work. However, video games still struggle to be recognized as an art form, and there is much debate as to whether or not they should be. Before I address the influences of video games on the art world, I would like to pose one question: What is art? One definition of art is: “the expression or application of human creative skill and imagination, typically in a visual form such as painting or sculpture, producing works to be appreciated primarily for their beauty or emotional power.”1 If this definition were the only criteria, then video games certainly fall under the category. It is not so simple, however. In modern times, the definition has become hazy. Many of today’s popular video games are most definitely not artistic, just as not every painting in existence is considered successful. Certain games are held at a higher regard than others. There is also the problem of whom and what defines works as art. Many gamers consider certain games as works of art while the average person might not believe so. -

The Connections Between ICO and Shadow of the Colossus: a Theory by J
The Connections between ICO and Shadow of the Colossus: A Theory by J. Dean Summary Over the years, there has been an attempt by many to connect the games Ico and Shadow of the Colossus in a manner not specified by the Fumito Ueda, creator of both games (and also of the upcoming game The Last Guardian, also set in the same universe). In this brief essay, I will attempt to present my own theory concerning the connections between Ico and SotC. While I may not be the only one who presents the following theories of connection between the two games, I will say at the outset that I did not read any of these ideas off any other websites or bloggers. The theories and conclusions I will be putting forth are my own, derived solely from my knowledge, observation, and experience with both games. Any resemblance to other theories and ideas put forth by other people is purely coincidental (Warning: spoilers are included in the following essays. If you have not yet played either game but wish to continue reading, consider yourself warned...). Facts and Theories 1.) In SotC, Wander (the protagonist) brings Mono (the dead woman) to Dormin in hopes of resurrection. Wander states that she had a "cursed fate." Theory: Mono is a daughter of the Queen from Ico. Remember that the Queen needed Yorda to pass on her spirit, meaning that Yorda was intended to be nothing more than a vessel for the Queen's possession when her body became too old. It is believed that the same fate awaited Mono, as the Queen (probably in an earlier incarnation) was saving Mono for such a purpose, particularly with regard to Wander's cryptic statement about Mono's fate. -

Recommended Resources from Fortugno
How Games Tell Stories with Nick Fortugno RECOMMENDED RESOURCES FROM NICK FORTUGNO Articles & Books ● MDA: A Formal Approach to Game Design and Game Research ● Rules of Play Game Textbook ● Game Design Workshop Textbook ● Flow: The Psychology of Optimal Experience Festivals ● Come Out and Play Festival Games ● The Waiting Game at ProPublica ● Rez ● Fallout 4 ● Red Dead Redemption 2 ● Dys4ia ● The Last of Us ● Shadow of the Colossus ● Kentucky Route Zero ● Gone Home ● Amnesia ● Pandemic: Legacy ● Once Upon A Time A SELECTION OF SUNDANCE NEW FRONTIER ALUMNI / SUPPORTED PROJECTS About New Frontier: New Frontier: Storytelling at the Intersection of Art & Technology ● Walden ● 1979 Revolution ● Laura Yilmaz ● Thin Air OTHER GAMING RESOURCES ● NYU Game Center - dedicated to the exploration of games as a cultural form and game design as creative practice ● Columbia Digital Storytelling Lab - focusing on a diverse range of creative and research practices originating in fields from the arts, humanities and technology 1 OTHER GAMING RESOURCES continued ● Kotaku - gaming reviews, news, tips and more ● Steam platform indie tag - the destination for playing, discussing, and creating games ● IndieCade Festival - International festival website committed to celebrating independent interactive games and media from around the globe ● Games for Change - the leading global advocate for the games as drivers of social impact ● Immerse - digest of nonfiction storytelling in emerging media ● Emily Short's Interactive Storytelling - essays and reviews on narrative in games and new media ● The Art of Storytelling in Gaming - blog post 2 . -

Worldbuilding Voices in the Soundscapes of Role-Playing Video Games
University of Huddersfield Repository Jennifer, Smith Worldbuilding Voices in the Soundscapes of Role Playing Video Games Original Citation Jennifer, Smith (2020) Worldbuilding Voices in the Soundscapes of Role Playing Video Games. Doctoral thesis, University of Huddersfield. This version is available at http://eprints.hud.ac.uk/id/eprint/35389/ The University Repository is a digital collection of the research output of the University, available on Open Access. Copyright and Moral Rights for the items on this site are retained by the individual author and/or other copyright owners. Users may access full items free of charge; copies of full text items generally can be reproduced, displayed or performed and given to third parties in any format or medium for personal research or study, educational or not-for-profit purposes without prior permission or charge, provided: • The authors, title and full bibliographic details is credited in any copy; • A hyperlink and/or URL is included for the original metadata page; and • The content is not changed in any way. For more information, including our policy and submission procedure, please contact the Repository Team at: [email protected]. http://eprints.hud.ac.uk/ Worldbuilding Voices in the Soundscapes of Role-Playing Video Games Jennifer Caron Smith A thesis submitted to the University of Huddersfield in partial fulfilment of the requirements for the degree of Doctor of Philosophy The University of Huddersfield October 2020 1 Copyright Statement i. The author of this thesis (including any appendices and/ or schedules to this thesis) owns any copyright in it (the “Copyright”) and s/he has given The University of Huddersfield the right to use such Copyright for any administrative, promotional, educational and/or teaching purposes. -

2006 DICE Program
Welcome to the Academy of Interactive Arts and Sciences’® fifth annual D.I.C.E. Summit™. The Academy is excited to provide the forum for the interactive enter- tainment industry’s best and brightest to discuss the trends, opportunities and chal- lenges that drive this dynamic business. For 2006, we have assembled an outstanding line-up of speakers who, over the next few days, will be addressing some of the most provocative topics that will impact the creation of tomorrow’s video games. The D.I.C.E. Summit is the event where many of the industry’s leaders are able to discuss, debate and exchange ideas that will impact the video game business in the coming years. It is also a time to reflect on the industry’s most recent accomplish- ments, and we encourage every Summit attendee to join us on Thursday evening Joseph Olin, President for the ninth annual Interactive Achievement Awards®, held at The Joint at the Academy of Interactive Hard Rock Hotel. The creators of the top video games of the year will be honored Arts & Sciences for setting new standards in interactive entertainment. Thank you for attending this year’s D.I.C.E. Summit. We hope that this year’s confer- ence will provide you with ideas that spark your creative efforts throughout the year. The Academy’s Board of Directors Since its inception in 1996, the Academy of Interactive Arts and Sciences has relied on the leadership and direction of its board of directors. These men and women, all leaders of the interactive software industry, have volunteered their time and resources to help the Academy advance its mission of promoting awareness of the art and science of interactive games and entertainment. -

Evan Liaw - Environment Artist
[email protected] | (281) 793-8145 | https://www.artstation.com/evanliaw Evan Liaw - Environment Artist SKILLS Material Specialist | Environment Modeling and World Building | High to Low Poly Modeling | Shaders (HLSL) Lighting | FX | Scripting (C/C++, Python) EXPERIENCE Playful Corp McKinney, TX — Environment Artist August 2016 - November 2018 ● Created a Substance pipeline that allowed contractors to quickly create materials plug-and-play style for Super Lucky’s Tale. ● Created materials, high-poly sculpts, and low-poly models for Super Lucky’s Tale. ● Provided all the material support for Star Child exploring styles ranging from hyper-realistic to stylized. ● Provided environment modeling, set dressing, FX and lighting support for Star Child. ● Helped set standards and best practices for both performance and quality for Star Child. ● Helped develop shaders and rendering tech for Star Child: Environment/FX shaders, elimination of specular aliasing in VR, and specular support for baked lighting and light probes. ● Provided Unity tools for Star Child: assetimporter, prefab generator, and composite height map exporter. Bluepoint Games Austin, TX — Environment Artist October 2013 - August 2016 ● Material and environment artist on Shadow of Colossus remake. ● Provided Substance templates for artists to generate materials from on Shadow of Colossus remake. All the temple materials in particular sourced from a single Substance graph. ● Created and maintained a library of material templates on Shadow of Colossus remake. ● Worked on visual bar prototypes for Shadow of Colossus remake. ● Provided texture, modeling, and technical support for remaster projects. Tripwire Interactive (Mod Community) — Character and Prop Artist July 2012 - March 2013 ● Created low-poly heads for characters and environment props on Rising Storm. -

An Assessment of the Literary and Aesthetic Value of Japanese Video Games
WANDERING THROUGH THE VIRTUAL WORLD: AN ASSESSMENT OF THE LITERARY AND AESTHETIC VALUE OF JAPANESE VIDEO GAMES A THESIS The Faculty of the Department of Asian Studies The Colorado College In Partial Fulfillment of the Requirements for the Degree Bachelor of Arts By Jonathan D. Curry May/2015 On my honor, I, Jonathan D. Curry, have not received unauthorized aid on this thesis. I have fully upheld the HONOR CODE of Colorado College. _______________________________________ JONATHAN D. CURRY 1 2 ACKNOWLEDGEMENTS I would like to express my deep gratitude for Professor Joan Ericson’s unrelenting support and insightful advice, not only during my thesis writing process but throughout my entire Colorado College career. You have helped me to achieve so many of my life goals, so I sincerely thank you. I would also like to sincerely thank Professor John Williams for his guidance in writing this thesis. You helped me find direction and purpose in my research and writing, an invaluable skill that will carry me through my future academic endeavors. I also want to give a huge thank you to my fellow Asian Studies majors. Congratulations, everyone! We made it! I know we are a small group, and we did not have many opportunities to spend time together, but I want you all to know that it has been an immense honor to work beside all of you. I would also like to acknowledge my father for his undying support for me in everything I have ever done, through thick and thin. I couldn’t have made it this far without you. -

Video Game Collection
Pokemon: Let’s Go Eevee Top-Down Turn-Based RPG | 28 hrs Pokemon: Let’s Go Pikachu Wallingford Public Library Top-Down Turn-Based RPG | 28 hrs Pokemon Shield Top-Down Turn-Based RPG | 32 hrs Animal Crossing New Horizons Coming Soon! Pokemon Sword Top-Down Turn-Based RPG | 32 hrs Captain Toad Sidescroll Platformer | 11 hrs Portal Knights Action RPG | 31 hrs Video GAme Celeste Sidescroll Platformer | 11 hrs Rime Puzzle Adventure | 9 hrs Child of Light/Valiant Hearts: Splatoon 2 Multiplayer Shooter | 12 hrs (story mode) • Child of Light Action RPG Platformer | 13 hrs Spyro Reignited Trilogy Platformer | 25 hrs • Valiant Hearts Puzzle Adventure | 7 hrs Super Mario Maker Platformer Creator | N/A Collection Civilization VI Turn-Based Strategy | 32 hrs Super Mario Odyssey Platformer | 26 hrs Crash Bandicoot N. Sane Trilogy Platformer | 20 hrs Super Mario Party Party Games | N/A Crash Team Racing Multiplayer | 8 hrs (story mode) Super Smash Bros. Ultimate Battle Royale | N/A Dark Souls Action RPG | 62 hrs Team Sonic Racing Multiplayer | 11 hrs (Story Mode) Dead Cells Sidescroll Platformer | 19 hrs Tokyo Mirage Sessions Encore Turn-Based RPG | 43 hrs Disgaea 1 Complete RPG | 56 hrs Undertale Sidescroll Turn-Based Puzzle RPG | 9 hrs Donkey Kong Tropical Freeze Platformer | 16 hrs Wandersong Musical Sidescroll Platformer | 10 hrs Dragon Quest Builders 2 Sandbox | 64 hrs The Witcher III: Wild Hunt Action RPG | 102 hrs Gone Home Narrative | 2 hrs includes Hearts of Stone 14 hours A Hat in Time Platformer | 13 hrs & Blood and Wine 31 hours Hollow Knight -

A Guide to the Videogame System
SYSTEM AND EXPERIENCE A Guide to the Videogame as a Complex System to Create an Experience for the Player A Master’s Thesis by Víctor Navarro Remesal Tutor: Asunción Huertas Roig Department of Communication Rovira i Virgili University (2009) © Víctor Navarro Remesal This Master’s Thesis was finished in September, 2009. All the graphic material belongs to its respective authors, and is shown here solely to illustrate the discourse. 1 ACKNOWLEDGEMENTS I would like to thank my tutor for her support, advice and interest in such a new and different topic. Gonzalo Frasca and Jesper Juul kindly answered my e-mails when I first found about ludology and started considering writing this thesis: thanks a lot. I also have to thank all the good people I met at the ECREA 2008 Summer School in Tartu, for giving me helpful advices and helping me to get used to the academic world. And, above all, for being such great folks. My friends, family and specially my girlfriend (thank you, Ariadna) have suffered my constant updates on the state of this thesis and my rants about all things academic. I am sure they missed me during my months of seclusion, though, so they should be the ones I thanked the most. Thanks, mates. Last but not least, I want to thank every game creator cited directly or indirectly in this work, particularly Ron Gilbert, Dave Grossman and Tim Schafer for Monkey Island, Fumito Ueda for Ico and Shadow of the Colossus and Hideo Kojima for the Metal Gear series. I would not have written this thesis if it were not for videogames like these.