Molecular Codes Through Complex Formation in a Model of the Human Inner Kinetochore
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

View the Poster.Pdf
Identifying Novel Associations for Iron-Related Genes in High-Grade Ovarian Cancer Abigail Descoteaux*1, José W. Velázquez*2, Anna Konstorum3, Reinhard Laubenbacher3,4 1Vassar College, 2University of Puerto Rico at Cayey, 3Center for Quantitative Medicine, UConn Health, 4The Jackson Laboratory for Genomic Medicine *These authors contributed equally to this work Introduction Methods Testable Hypothesis § Iron can gain and lose electrons, making it enzymatically Microarray gene expression Adjacency matrix Community detection in a weighted, KEGG pathways Tumor cells promote an inflammatory microenvironment via [1] data from HGSOC clinical • Top 10,000 most variable genes undirected network • Manually curated biological pathways useful in cell replication, metabolism, and growth • Bicor derived from Pearson but • ORA: ask whether any known pathways • Order Statistics Local Optimization Method (OSLOM) recruitment of tumor-associated macrophages, that in turn samples less sensitive to outliers are significantly over-represented in the • Assembled unsupervised with respect to biology by locally § Cancer cells sequester iron by altering the expression of • The Cancer Genome Atlas (TCGA) • Correlation cut-off at 0.45 genes within the community secrete IL4 and CCL4 to promote an iron-influx phenotype in optimizing the statistical significance of clusters and using [1] • Affymetrix HGU133A (n=488) (FDR corrected, α=0.01) Pathway 2 several regulators of iron metabolism (Figure 1) • Tothill et al. [2] this as a fitness score ovarian cancer tumor cells. • • HGU133plus2 (n=217) Accounts for edge weight, overlapping communities, and Pathway 1 hierarchies a. Normal epithelial cell Fe3+ Fe3+ Pathway 3 Tumor-associated 3+ 3+ Tumor cells Fe Fe macrophages Hepcidin (HAMP) samples genes Biweight midcorrelation Over-representation (bicor) Hypothesis CSF1R Ferroportin OSLOM analysis (ORA) CCR1[8] (SLC40A1) generation and [7] genes genes 1. -

Gene Knockdown of CENPA Reduces Sphere Forming Ability and Stemness of Glioblastoma Initiating Cells
Neuroepigenetics 7 (2016) 6–18 Contents lists available at ScienceDirect Neuroepigenetics journal homepage: www.elsevier.com/locate/nepig Gene knockdown of CENPA reduces sphere forming ability and stemness of glioblastoma initiating cells Jinan Behnan a,1, Zanina Grieg b,c,1, Mrinal Joel b,c, Ingunn Ramsness c, Biljana Stangeland a,b,⁎ a Department of Molecular Medicine, Institute of Basic Medical Sciences, The Medical Faculty, University of Oslo, Oslo, Norway b Norwegian Center for Stem Cell Research, Department of Immunology and Transfusion Medicine, Oslo University Hospital, Oslo, Norway c Vilhelm Magnus Laboratory for Neurosurgical Research, Institute for Surgical Research and Department of Neurosurgery, Oslo University Hospital, Oslo, Norway article info abstract Article history: CENPA is a centromere-associated variant of histone H3 implicated in numerous malignancies. However, the Received 20 May 2016 role of this protein in glioblastoma (GBM) has not been demonstrated. GBM is one of the most aggressive Received in revised form 23 July 2016 human cancers. GBM initiating cells (GICs), contained within these tumors are deemed to convey Accepted 2 August 2016 characteristics such as invasiveness and resistance to therapy. Therefore, there is a strong rationale for targeting these cells. We investigated the expression of CENPA and other centromeric proteins (CENPs) in Keywords: fi CENPA GICs, GBM and variety of other cell types and tissues. Bioinformatics analysis identi ed the gene signature: fi Centromeric proteins high_CENP(AEFNM)/low_CENP(BCTQ) whose expression correlated with signi cantly worse GBM patient Glioblastoma survival. GBM Knockdown of CENPA reduced sphere forming ability, proliferation and cell viability of GICs. We also Brain tumor detected significant reduction in the expression of stemness marker SOX2 and the proliferation marker Glioblastoma initiating cells and therapeutic Ki67. -

IL21R Expressing CD14+CD16+ Monocytes Expand in Multiple
Plasma Cell Disorders SUPPLEMENTARY APPENDIX IL21R expressing CD14 +CD16 + monocytes expand in multiple myeloma patients leading to increased osteoclasts Marina Bolzoni, 1 Domenica Ronchetti, 2,3 Paola Storti, 1,4 Gaetano Donofrio, 5 Valentina Marchica, 1,4 Federica Costa, 1 Luca Agnelli, 2,3 Denise Toscani, 1 Rosanna Vescovini, 1 Katia Todoerti, 6 Sabrina Bonomini, 7 Gabriella Sammarelli, 1,7 Andrea Vecchi, 8 Daniela Guasco, 1 Fabrizio Accardi, 1,7 Benedetta Dalla Palma, 1,7 Barbara Gamberi, 9 Carlo Ferrari, 8 Antonino Neri, 2,3 Franco Aversa 1,4,7 and Nicola Giuliani 1,4,7 1Myeloma Unit, Dept. of Medicine and Surgery, University of Parma; 2Dept. of Oncology and Hemato-Oncology, University of Milan; 3Hematology Unit, “Fondazione IRCCS Ca’ Granda”, Ospedale Maggiore Policlinico, Milan; 4CoreLab, University Hospital of Parma; 5Dept. of Medical-Veterinary Science, University of Parma; 6Laboratory of Pre-clinical and Translational Research, IRCCS-CROB, Referral Cancer Center of Basilicata, Rionero in Vulture; 7Hematology and BMT Center, University Hospital of Parma; 8Infectious Disease Unit, University Hospital of Parma and 9“Dip. Oncologico e Tecnologie Avanzate”, IRCCS Arcispedale Santa Maria Nuova, Reggio Emilia, Italy ©2017 Ferrata Storti Foundation. This is an open-access paper. doi:10.3324/haematol. 2016.153841 Received: August 5, 2016. Accepted: December 23, 2016. Pre-published: January 5, 2017. Correspondence: [email protected] SUPPLEMENTAL METHODS Immunophenotype of BM CD14+ in patients with monoclonal gammopathies. Briefly, 100 μl of total BM aspirate was incubated in the dark with anti-human HLA-DR-PE (clone L243; BD), anti-human CD14-PerCP-Cy 5.5, anti-human CD16-PE-Cy7 (clone B73.1; BD) and anti-human CD45-APC-H 7 (clone 2D1; BD) for 20 min. -
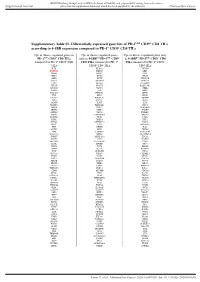
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

Research Article the Oncogenic Role of CENPA in Hepatocellular Carcinoma Development: Evidence from Bioinformatic Analysis
Hindawi BioMed Research International Volume 2020, Article ID 3040839, 8 pages https://doi.org/10.1155/2020/3040839 Research Article The Oncogenic Role of CENPA in Hepatocellular Carcinoma Development: Evidence from Bioinformatic Analysis Yuan Zhang ,1 Lei Yang ,2 Jia Shi ,1 Yunfei Lu ,1 Xiaorong Chen ,1 and Zongguo Yang 1 1Department of Integrative Medicine, Shanghai Public Health Clinical Center, Fudan University, Shanghai 201508, China 2Department of Acupuncture and Moxibustion, Dongzhimen Hospital, Beijing University of Chinese Medicine, Beijing 100007, China Correspondence should be addressed to Xiaorong Chen; [email protected] and Zongguo Yang; [email protected] Received 27 September 2019; Revised 14 March 2020; Accepted 20 March 2020; Published 8 April 2020 Academic Editor: Ali A. Khraibi Copyright © 2020 Yuan Zhang et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Objective. This study is aimed at investigating the predictive value of CENPA in hepatocellular carcinoma (HCC) development. Methods. Using integrated bioinformatic analysis, we evaluated the CENPA mRNA expression in tumor and adjacent tissues and correlated it with HCC survival and clinicopathological features. A Cox regression hazard model was also performed. Results. CENPA mRNA was significantly upregulated in tumor tissues compared with that in adjacent tissues, which were validated in The Cancer Genome Atlas (TCGA) and Gene Expression Omnibus (GEO) series (all P <0:01). In the Kaplan-Meier plotter platform, the high level of CENPA mRNA was significantly correlated with overall survival (OS), disease-free survival (DFS), recurrence-free survival (RFS), and progression-free survival (PFS) in HCC patients (all log rank P <0:01). -

Supplementary Table S1. Correlation Between the Mutant P53-Interacting Partners and PTTG3P, PTTG1 and PTTG2, Based on Data from Starbase V3.0 Database
Supplementary Table S1. Correlation between the mutant p53-interacting partners and PTTG3P, PTTG1 and PTTG2, based on data from StarBase v3.0 database. PTTG3P PTTG1 PTTG2 Gene ID Coefficient-R p-value Coefficient-R p-value Coefficient-R p-value NF-YA ENSG00000001167 −0.077 8.59e-2 −0.210 2.09e-6 −0.122 6.23e-3 NF-YB ENSG00000120837 0.176 7.12e-5 0.227 2.82e-7 0.094 3.59e-2 NF-YC ENSG00000066136 0.124 5.45e-3 0.124 5.40e-3 0.051 2.51e-1 Sp1 ENSG00000185591 −0.014 7.50e-1 −0.201 5.82e-6 −0.072 1.07e-1 Ets-1 ENSG00000134954 −0.096 3.14e-2 −0.257 4.83e-9 0.034 4.46e-1 VDR ENSG00000111424 −0.091 4.10e-2 −0.216 1.03e-6 0.014 7.48e-1 SREBP-2 ENSG00000198911 −0.064 1.53e-1 −0.147 9.27e-4 −0.073 1.01e-1 TopBP1 ENSG00000163781 0.067 1.36e-1 0.051 2.57e-1 −0.020 6.57e-1 Pin1 ENSG00000127445 0.250 1.40e-8 0.571 9.56e-45 0.187 2.52e-5 MRE11 ENSG00000020922 0.063 1.56e-1 −0.007 8.81e-1 −0.024 5.93e-1 PML ENSG00000140464 0.072 1.05e-1 0.217 9.36e-7 0.166 1.85e-4 p63 ENSG00000073282 −0.120 7.04e-3 −0.283 1.08e-10 −0.198 7.71e-6 p73 ENSG00000078900 0.104 2.03e-2 0.258 4.67e-9 0.097 3.02e-2 Supplementary Table S2. -

Loss of Inner Kinetochore Genes Is Associated with the Transition to an Unconventional Point Centromere in Budding Yeast
Loss of inner kinetochore genes is associated with the transition to an unconventional point centromere in budding yeast Nagarjun Vijay Computational Evolutionary Genomics Lab, Department of Biological Sciences, Indian Institute of Science Education and Research, Bhopal, Madhya Pradesh, India ABSTRACT Background: The genomic sequences of centromeres, as well as the set of proteins that recognize and interact with centromeres, are known to quickly diverge between lineages potentially contributing to post-zygotic reproductive isolation. However, the actual sequence of events and processes involved in the divergence of the kinetochore machinery is not known. The patterns of gene loss that occur during evolution concomitant with phenotypic changes have been used to understand the timing and order of molecular changes. Methods: I screened the high-quality genomes of twenty budding yeast species for the presence of well-studied kinetochore genes. Based on the conserved gene order and complete genome assemblies, I identified gene loss events. Subsequently, I searched the intergenic regions to identify any un-annotated genes or gene remnants to obtain additional evidence of gene loss. Results: My analysis identified the loss of four genes (NKP1, NKP2, CENPL/IML3 and CENPN/CHL4) of the inner kinetochore constitutive centromere-associated network (CCAN/also known as CTF19 complex in yeast) in both the Naumovozyma species for which genome assemblies are available. Surprisingly, this collective loss of four genes of the CCAN/CTF19 complex coincides with the emergence of Submitted 18 June 2020 unconventional centromeres in N. castellii and N. dairenensis. My study suggests a 11 September 2020 Accepted tentative link between the emergence of unconventional point centromeres and the Published 29 September 2020 turnover of kinetochore genes in budding yeast. -

Centromere Protein N May Be a Novel Malignant Prognostic Biomarker for Hepatocellular Carcinoma
Centromere protein N may be a novel malignant prognostic biomarker for hepatocellular carcinoma Qingqing Wang, Xiaoyan Yu, Zhewen Zheng, Fengxia Chen, Ningning Yang and Yunfeng Zhou Hubei Cancer Clinical Study Center, Hubei Key Laboratory of Tumor Biological Behaviors, Zhongnan Hospital, Wuhan University, Wuhan, China Department of Radiation Oncology and Medical Oncology, Zhongnan Hospital, Wuhan University, Wuhan, China ABSTRACT Background. Hepatocellular carcinoma (HCC) is one of the deadliest tumors. The majority of HCC is detected in the late stage, and the clinical results for HCC patients are poor. There is an urgent need to discover early diagnostic biomarkers and potential therapeutic targets for HCC. Methods. The GSE87630 and GSE112790 datasets from the Gene Expression Omnibus (GEO) database were downloaded to analyze the differentially expressed genes (DEGs) between HCC and normal tissues. R packages were used for Kyoto Encyclopedia of Genes and Genomes (KEGG) and Gene Ontology (GO) enrichment analyses of the DEGs. A Search Tool for Retrieval of Interacting Genes (STRING) database was used to develop a protein-protein interaction (PPI) network, and also cytoHubba, Molecular Complex Detection (MCODE), EMBL-EBI, CCLE, Gene Expression Profiling Interac- tive Analysis (GEPIA), and Oncomine analyses were performed to identify hub genes. Gene expression was verified with a third GEO dataset, GSE25097. The Cancer Genome Atlas (TCGA) database was used to explore the correlations between the hub genes and clinical indexes of HCC patients. The functions of the hub genes were enriched by gene set enrichment analysis (GSEA), and the biological significance of the hub genes was explored by real-time polymerase chain reaction (qRT-PCR), western blot, Submitted 4 January 2021 immunofluorescence, CCK-8, colony formation, Transwell and flow cytometry assays Accepted 3 April 2021 with loss-of-function experiments in vitro. -

Explorative Bioinformatic Analysis of Cardiomyocytes in 2D &3D in Vitro Culture System
EXPLORATIVE BIOINFORMATIC ANALYSIS OF CARDIOMYOCYTES IN 2D &3D IN VITRO CULTURE SYSTEM VERSION 2 Master Degree Project in Bioscience One years Level, 60 ECTS Sruthy Janardanan [email protected] Supervisor: Jane Synnergren [email protected] Examiner: Sanja Jurcevic [email protected] Abstract The in vitro cell culture models of human pluripotent stem cells (hPSC)-derived cardiomyocytes (CMs) have gained a predominant value in the field of drug discovery and is considered an attractive tool for cardiovascular disease modellings. However, despite several reports of different protocols for the hPSC-differentiation into CMs, the development of an efficient, controlled and reproducible 3D differentiation remains challenging. The main aim of this research study was to understand the changes in the gene expression as an impact of spatial orientation of hPSC-derived CMs in 2D(two-dimensional) and 3D(three-dimensional) culture conditions and to identify the topologically important Hub and Hub-Bottleneck proteins using centrality measures to gain new knowledge for standardizing the pre-clinical models for the regeneration of CMs. The above-mentioned aim was achieved through an extensive bioinformatic analysis on the list of differentially expressed genes (DEGs) identified from RNA-sequencing (RNA-Seq). Functional annotation analysis of the DEGs from both 2D and 3D was performed using Cytoscape plug-in ClueGO. Followed by the topological analysis of the protein-protein interaction network (PPIN) using two centrality parameters; Degree and Betweeness in Cytoscape plug-in CenTiScaPe. The results obtained revealed that compared to 2D, DEGs in 3D are primarily associated with cell signalling suggesting the interaction between cells as an impact of the 3D microenvironment and topological analysis revealed 32 and 39 proteins as Hub and Hub-Bottleneck proteins, respectively in 3D indicating the possibility of utilizing those identified genes and their corresponding proteins as cardiac disease biomarkers in future by further research. -

WNT16 Is a New Marker of Senescence
Table S1. A. Complete list of 177 genes overexpressed in replicative senescence Value Gene Description UniGene RefSeq 2.440 WNT16 wingless-type MMTV integration site family, member 16 (WNT16), transcript variant 2, mRNA. Hs.272375 NM_016087 2.355 MMP10 matrix metallopeptidase 10 (stromelysin 2) (MMP10), mRNA. Hs.2258 NM_002425 2.344 MMP3 matrix metallopeptidase 3 (stromelysin 1, progelatinase) (MMP3), mRNA. Hs.375129 NM_002422 2.300 HIST1H2AC Histone cluster 1, H2ac Hs.484950 2.134 CLDN1 claudin 1 (CLDN1), mRNA. Hs.439060 NM_021101 2.119 TSPAN13 tetraspanin 13 (TSPAN13), mRNA. Hs.364544 NM_014399 2.112 HIST2H2BE histone cluster 2, H2be (HIST2H2BE), mRNA. Hs.2178 NM_003528 2.070 HIST2H2BE histone cluster 2, H2be (HIST2H2BE), mRNA. Hs.2178 NM_003528 2.026 DCBLD2 discoidin, CUB and LCCL domain containing 2 (DCBLD2), mRNA. Hs.203691 NM_080927 2.007 SERPINB2 serpin peptidase inhibitor, clade B (ovalbumin), member 2 (SERPINB2), mRNA. Hs.594481 NM_002575 2.004 HIST2H2BE histone cluster 2, H2be (HIST2H2BE), mRNA. Hs.2178 NM_003528 1.989 OBFC2A Oligonucleotide/oligosaccharide-binding fold containing 2A Hs.591610 1.962 HIST2H2BE histone cluster 2, H2be (HIST2H2BE), mRNA. Hs.2178 NM_003528 1.947 PLCB4 phospholipase C, beta 4 (PLCB4), transcript variant 2, mRNA. Hs.472101 NM_182797 1.934 PLCB4 phospholipase C, beta 4 (PLCB4), transcript variant 1, mRNA. Hs.472101 NM_000933 1.933 KRTAP1-5 keratin associated protein 1-5 (KRTAP1-5), mRNA. Hs.534499 NM_031957 1.894 HIST2H2BE histone cluster 2, H2be (HIST2H2BE), mRNA. Hs.2178 NM_003528 1.884 CYTL1 cytokine-like 1 (CYTL1), mRNA. Hs.13872 NM_018659 tumor necrosis factor receptor superfamily, member 10d, decoy with truncated death domain (TNFRSF10D), 1.848 TNFRSF10D Hs.213467 NM_003840 mRNA. -

Mitochondria Are Required for Pro‐Ageing Features of the Senescent Phenotype
Published online: February 4, 2016 Article Mitochondria are required for pro-ageing features of the senescent phenotype Clara Correia-Melo1,2, Francisco DM Marques1, Rhys Anderson1, Graeme Hewitt1, Rachael Hewitt3, John Cole3, Bernadette M Carroll1, Satomi Miwa1, Jodie Birch1, Alina Merz1, Michael D Rushton1, Michelle Charles1, Diana Jurk1, Stephen WG Tait3, Rafal Czapiewski1, Laura Greaves4, Glyn Nelson1, Mohammad Bohlooly-Y5, Sergio Rodriguez-Cuenca6, Antonio Vidal-Puig6, Derek Mann7, Gabriele Saretzki1, Giovanni Quarato8, Douglas R Green8, Peter D Adams3, Thomas von Zglinicki1, Viktor I Korolchuk1 & João F Passos1,* Abstract Introduction Cell senescence is an important tumour suppressor mechanism Cellular senescence, the irreversible loss of proliferative potential in and driver of ageing. Both functions are dependent on the develop- somatic cells, has been shown to not only play a major role in ment of the senescent phenotype, which involves an overproduc- tumour suppression, but also to contribute to age-related tissue tion of pro-inflammatory and pro-oxidant signals. However, the degeneration (Baker et al, 2011). While senescence can stably exact mechanisms regulating these phenotypes remain poorly repress cancer by irreversibly arresting damaged cells, senescent understood. Here, we show the critical role of mitochondria in cells have been shown to be detrimental in tissues, mainly by devel- cellular senescence. In multiple models of senescence, absence of oping a complex senescence-associated secretory phenotype (SASP) mitochondria reduced a spectrum of senescence effectors and (Coppe´ et al, 2008; Kuilman & Peeper, 2009) and producing phenotypes while preserving ATP production via enhanced glycoly- elevated levels of reactive oxygen species (ROS) (Passos et al, sis. Global transcriptomic analysis by RNA sequencing revealed 2010). -

How Does SUMO Participate in Spindle Organization?
cells Review How Does SUMO Participate in Spindle Organization? Ariane Abrieu * and Dimitris Liakopoulos * CRBM, CNRS UMR5237, Université de Montpellier, 1919 route de Mende, 34090 Montpellier, France * Correspondence: [email protected] (A.A.); [email protected] (D.L.) Received: 5 July 2019; Accepted: 30 July 2019; Published: 31 July 2019 Abstract: The ubiquitin-like protein SUMO is a regulator involved in most cellular mechanisms. Recent studies have discovered new modes of function for this protein. Of particular interest is the ability of SUMO to organize proteins in larger assemblies, as well as the role of SUMO-dependent ubiquitylation in their disassembly. These mechanisms have been largely described in the context of DNA repair, transcriptional regulation, or signaling, while much less is known on how SUMO facilitates organization of microtubule-dependent processes during mitosis. Remarkably however, SUMO has been known for a long time to modify kinetochore proteins, while more recently, extensive proteomic screens have identified a large number of microtubule- and spindle-associated proteins that are SUMOylated. The aim of this review is to focus on the possible role of SUMOylation in organization of the spindle and kinetochore complexes. We summarize mitotic and microtubule/spindle-associated proteins that have been identified as SUMO conjugates and present examples regarding their regulation by SUMO. Moreover, we discuss the possible contribution of SUMOylation in organization of larger protein assemblies on the spindle, as well as the role of SUMO-targeted ubiquitylation in control of kinetochore assembly and function. Finally, we propose future directions regarding the study of SUMOylation in regulation of spindle organization and examine the potential of SUMO and SUMO-mediated degradation as target for antimitotic-based therapies.