Linguistic and Cultural Assimilation As a Human Capital Process∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Understanding the Value of Arts & Culture | the AHRC Cultural Value
Understanding the value of arts & culture The AHRC Cultural Value Project Geoffrey Crossick & Patrycja Kaszynska 2 Understanding the value of arts & culture The AHRC Cultural Value Project Geoffrey Crossick & Patrycja Kaszynska THE AHRC CULTURAL VALUE PROJECT CONTENTS Foreword 3 4. The engaged citizen: civic agency 58 & civic engagement Executive summary 6 Preconditions for political engagement 59 Civic space and civic engagement: three case studies 61 Part 1 Introduction Creative challenge: cultural industries, digging 63 and climate change 1. Rethinking the terms of the cultural 12 Culture, conflict and post-conflict: 66 value debate a double-edged sword? The Cultural Value Project 12 Culture and art: a brief intellectual history 14 5. Communities, Regeneration and Space 71 Cultural policy and the many lives of cultural value 16 Place, identity and public art 71 Beyond dichotomies: the view from 19 Urban regeneration 74 Cultural Value Project awards Creative places, creative quarters 77 Prioritising experience and methodological diversity 21 Community arts 81 Coda: arts, culture and rural communities 83 2. Cross-cutting themes 25 Modes of cultural engagement 25 6. Economy: impact, innovation and ecology 86 Arts and culture in an unequal society 29 The economic benefits of what? 87 Digital transformations 34 Ways of counting 89 Wellbeing and capabilities 37 Agglomeration and attractiveness 91 The innovation economy 92 Part 2 Components of Cultural Value Ecologies of culture 95 3. The reflective individual 42 7. Health, ageing and wellbeing 100 Cultural engagement and the self 43 Therapeutic, clinical and environmental 101 Case study: arts, culture and the criminal 47 interventions justice system Community-based arts and health 104 Cultural engagement and the other 49 Longer-term health benefits and subjective 106 Case study: professional and informal carers 51 wellbeing Culture and international influence 54 Ageing and dementia 108 Two cultures? 110 8. -

From the Chicago School to Post-Sub Cultural Carriage: a Review and Analysis of Contemporary Trends in Youth Culture Research
Journal of Social Sciences Original Research Paper From the Chicago School to Post-sub Cultural Carriage: A Review and Analysis of Contemporary Trends in Youth Culture Research Mohd. Aslam Bhat Centre of Central Asian Studies, University of Kashmir, J&K, India Article history Abstract: The historicity of youth culture studies is much challenging to Received: 10-01-2015 date exactly. Sociologists however, trace its genesis from Chicago School Revised: 30-09-2015 and then leap to Birmingham’s Centre for Contemporary Cultural Studies. Accepted: 17-02-2016 Theoretically it was, with the works of post subculturists that youth culture research gained ascendency. Global youth culture posture further revamped the field. This paper constructs a critical dialogue between the wide-ranging theories and research on youth culture and global/local relations in this sphere. It is revealed that the current ascendancy of post- subcultural studies margins the significance of sociological research to broader youth queries and does little to extend the case that youth studies should be more sociologically relevant and important. Youth lives in no island of its own and it is not all young people- who have the possibility of engaging in the consumerism, central to some post-sub-cultures. Conversely, youth and their cultures are framed within and to large extent shaped up by social divisions and inequalities. Against this backdrop, it is suggested that youth culture research would prove fruitful only when clubbed with ‘transition approach.’ Possibly this refit would not only facilitate to widen and thrive the significance of contemporary youth culture studies, rather may help in theoretical sophistication, empirical renovation and a more holistic sociology of youth. -

Culture and Materialism : Raymond Williams and the Marxist Debate
CULTURE AND MATERIALISM: RAYMOND WILLIAMS AND THE MARXIST DEBATE by David C. Robinson B.A. (Honours1, Queen's University, 1988 THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF ARTS (COMMUNICATIONS) in the ,Department of Communication @ David C. Robinson 1991 SIMON FRASER UNIVERSITY July, 1991 All rights reserved. This work may not be reproduced in whole or in part, by photocopy or other means, without permission of the author. APPROVAL NAME: David Robinson DEGREE: Master of Arts (Communication) TITLE OF THESIS: Culture and Materialism: Raymond Williams and the Marxist Debate EXAMINING COMMITTEE: CHAIR: Dr. Linda Harasim Dr. Richard S. Gruneau Professor Senior Supervisor Dr. Alison C. M. Beale Assistant Professor Supervisor " - Dr. Jerald Zaslove Associate Professor Department of English Examiner DATE APPROVED: PARTIAL COPYRIGHT LICENCE I hereby grant to Simon Fraser University the right to lend my thesis or dissertation (the title of which is shown below) to users of the Simon Fraser University Library, and to make partial or single copies only for such users or in response to a request from the library of any other university, or other educational institution, on its own behalf or for one of its users. I further agree that permission for multiple copying of this thesis for scholarly purposes may be granted by me or the Dean of Graduate Studies. It is understood that copying or publication of this thesis for financial gain shall not be allowed without my written permission. Title of Thesis/Dissertation: Culture and Materialism: Raymond Williams and the Marxist Debate Author : signature David C. -

A Qualitative Study of the Role of Culture Emerging from Undergraduate Italian Language Programs in the Midwest of the United States
Exploring Cultural Competence: A Qualitative Study of the Role of Culture Emerging from Undergraduate Italian Language Programs in the Midwest of the United States Dissertation Presented in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy in Graduate School of The Ohio State University By Alessia Colarossi, M.A. College of Education and Human Ecology The Ohio State University 2009 Dissertation Committee: Alan Hirvela, Advisor Frances James-Brown Janice M. Aski Karen Newman Copyright by Alessia Colarossi 2009 Abstract Despite the recognized importance of foreign language teaching and learning in current times, research is still lacking with respect to the understanding and transmission of foreign culture in undergraduate language programs at the college level. Furthermore, most of the research which has been conducted has been of a quantitative nature, and it has focused on linguistic aspects of learners of second or foreign languages in order to measure and better understand the mechanics of their learning and acquisition. This qualitative study was thus undertaken to draw attention to how foreign language programs, in this case Italian language programs, at the college level in the United States contribute to the understanding and diffusion of foreign cultures and how they comply with the national Foreign Language Standards (1999) with respect to the culturally oriented standards. Specifically, this study explored how three large Italian undergraduate programs at the elementary level defined and operationalized the notion of cultural competence; what aspects of cultural competence the Italian undergraduate programs at the elementary level emphasized; in what ways these programs attempted to teach culture and/or cultural competence, and to what extent, if any, the curricula of Italian programs were aligned with the Standards (1999) regarding culture and cultural competence. -

The Wisdom of and Science Behind Indigenous Cultural Practices
Article The Wisdom of and Science behind Indigenous Cultural Practices Rose Borunda * and Amy Murray College of Education, California State University, Sacramento, CA 95819, USA; [email protected] * Correspondence: [email protected] Received: 24 September 2018; Accepted: 22 January 2019; Published: 23 January 2019 Abstract: Conquest and colonization have systematically disrupted the processes by which Indigenous communities of the Americas transmit cultural knowledge and practices from one generation to the next. Even today, the extended arm of conquest and colonization that sustain oppression and culturicide continue to inflict trauma upon Indigenous people. Yet, current scientific research now attests to how Indigenous cultural practices promote healing and well-being within physical as well as mental health domains. This examination addresses Indigenous cultural practices related to storytelling, music, and dance. In drawing from evidence-based research, the case is made for not only restoring these practices where they have been disrupted for Indigenous people but that they have value for all people. The authors recommend reintroducing their use as a means to promote physical, spiritual, and mental well-being while recognizing that these practices originated from and exist for Indigenous people. Keywords: indigenous wisdom; disrupted attachment; cultural restoration; well-being In our tribal traditions when a woman carried a child, she was protected from anything disruptive such as violence. Everyone in the community ensured that the expectant woman experienced tranquility and calm so that when the child was born, the child would be even tempered and peaceful. Statement by Connie Reitman-Solas, Pomo Executive Director, Inter-tribal Council of California CSUS Multicultural Conference, 27 February 2017 1. -

The Joint Commission: Cultural Diversity
The Joint Commission: Cultural Diversity Cultural Diversity Lesson Information Purpose To provide healthcare workers with information to increase their knowledge and to help them meet the requirements of The Joint Commission, Occupational Safety & Health Administration, and other regulatory bodies, with the goal of providing safe, competent, and quality patient care. Abstract America is a nation of immigrants. Most Americans' ancestors came from other countries with different languages, customs, and systems of belief. Showing respect for your patients' cultural, spiritual, and psychosocial values demonstrates cultural competency.1 Cultural competency enables healthcare workers to understand their patient's expectations about the care, treatment, and services they receive. This lesson briefly describes the cultural differences that you may encounter when providing care to patients. Objectives Upon completion of this lesson, you will be able to: 1. Define the terms related to culture. 2. Recognize cultural differences among Americans. 3. List interventions that healthcare workers can use to meet the needs of culturally diverse patients. Consultants Contributors Dana Armstrong, RN, MSN Senior Clinical Systems Analyst Mississippi Baptist Health Systems Jackson, Mississippi Reviewers Jodi Nili, RN Quality Management Coordinator Community Regional Medical Center Fresno, California Stephanie Wiedenhoeft, RN, CPHRM, CPHQ Risk Manager Community Medical Centers Fresno, California Copyright © 2016 Elsevier, Inc. All rights reserved. All rights reserved. Except as specifically permitted herein, no part of this product may be reproduced or transmitted in any form or by any means, electronic or mechanical, including input into or storage in any information system, without permission in writing from the publisher. The Forms and Figures may be displayed and may be reproduced in print form for instructional purposes only, provided a proper copyright notice appears on the last page of each print-out. -

Sample IDI Intercultural Development Plan (IDP)
Intercultural Development Inventory® Intercultural Development Plan Prepared for: Carl M , Example Group Prepared by: IDI Qualified Administrator, IDI, LLC The Intercultural Development Inventory® (IDI®) is protected by copyright and is the proprietary IDI, LLC property of Mitchell R. Hammer, Ph.D., and IDI LLC. Intercultural Development Inventory and IDI are registered trademarks of Mitchell R. Hammer, Ph.D., and IDI, LLC. You may not use, copy, http://idiinventory.com/ display, distribute, modify, or reproduce any of the trademarks found in this Report except as [email protected] expressly authorized by IDI, LLC. Carl M , Example Group Page | 2 Your Intercultural Development Plan (IDP) Completing the Intercultural Development Inventory® (IDI®) and reviewing your own IDI Individual Profile Report provides key insights into how you make sense of cultural differences and commonalities. The next step is to systematically increase your intercultural competence—from where you are to where want to be—by designing and implementing your own Intercultural Development Plan® (IDP®). This IDP is specifically customized to your own IDI profile results and is an effective way for you to increase your skills in navigating cultural differences. After completing your IDP, you may consider taking the IDI again to determine your progress in increasing your intercultural competence. Should you select this option, a second customized IDP would then be produced based on your most recent IDI profile results, thus providing further intercultural development. By completing your Individual Development Plan, you can: • Gain insights concerning intercultural challenges you are facing and identify intercultural competence development goals that are important for you, • Gain increased understanding of how your Developmental Orientation impacts how you perceive and respond to cultural differences and commonalities, and • Identify and engage in targeted, developmental efforts that increase your intercultural competence in bridging across diverse communities. -

Assimilationist Language in Cherokee Women's Petitions: a Political Call to Reclaim Traditional Cherokee Culture
Utah State University DigitalCommons@USU All Graduate Plan B and other Reports Graduate Studies 5-2016 Assimilationist Language in Cherokee Women's Petitions: A Political Call to Reclaim Traditional Cherokee Culture Jillian Moore Bennion Utah State University Follow this and additional works at: https://digitalcommons.usu.edu/gradreports Part of the American Studies Commons Recommended Citation Bennion, Jillian Moore, "Assimilationist Language in Cherokee Women's Petitions: A Political Call to Reclaim Traditional Cherokee Culture" (2016). All Graduate Plan B and other Reports. 838. https://digitalcommons.usu.edu/gradreports/838 This Thesis is brought to you for free and open access by the Graduate Studies at DigitalCommons@USU. It has been accepted for inclusion in All Graduate Plan B and other Reports by an authorized administrator of DigitalCommons@USU. For more information, please contact [email protected]. Assimilationist Language in Cherokee Women’s Petitions: A Political Call to Reclaim Traditional Cherokee Culture Thesis Presented in Partial Fulfillment of the Requirements for the Degree Masters of Arts in American Studies in the Graduate School of Utah State University By Jillian Moore Bennion Graduate Program in American Studies Utah State University 2016 Thesis Committee: Keri Holt, Ph.D., Advisor Melody Graulich, Ph.D. Colleen O’Neill, Ph.D. ASSIMILATIONIST LANGUAGE IN CHEROKEE WOMEN’S PETITIONS: A POLITICAL CALL TO RECLAIM TRADITIONAL CHEROKEE CULTURE By Jillian M. Moore Bennion A thesis submitted in partial fulfillment of the requirements for the degree of MASTER OF ARTS in English Approved: ______________________ ______________________ Dr. Keri Holt Dr. Melody Graulich ______________________ Dr. Colleen O’Neill UTAH STATE UNIVERSITY Logan, Utah 2016 ii Copyright © Jillian M. -

Filipino Americans and Polyculturalism in Seattle, Wa
FILIPINO AMERICANS AND POLYCULTURALISM IN SEATTLE, WA THROUGH HIP HOP AND SPOKEN WORD By STEPHEN ALAN BISCHOFF A thesis submitted in partial fulfillment of the requirement for the degree of MASTER OF ARTS IN AMERICAN STUDIES WASHINGTON STATE UNIVERSITY Department of American Studies DECEMBER 2008 To the Faculty of Washington State University: The members of the Committee appointed to examine the thesis of STEPHEN ALAN BISCHOFF find it satisfactory and recommend that it be accepted. _____________________________________ Chair, Dr. John Streamas _____________________________________ Dr. Rory Ong _____________________________________ Dr. T.V. Reed ii ACKNOWLEDGEMENTS Since I joined the American Studies Graduate Program, there has been a host of faculty that has really helped me to learn what it takes to be in this field. The one professor that has really guided my development has been Dr. John Streamas. By connecting me to different resources and his challenging the confines of higher education so that it can improve, he has been an inspiration to finish this work. It is also important that I mention the help that other faculty members have given me. I appreciate the assistance I received anytime that I needed it from Dr. T.V. Reed and Dr. Rory Ong. A person that has kept me on point with deadlines and requirements has been Jean Wiegand with the American Studies Department. She gave many reminders and explained answers to my questions often more than once. Debbie Brudie and Rose Smetana assisted me as well in times of need in the Comparative Ethnic Studies office. My cohort over the years in the American Studies program have developed my thinking and inspired me with their own insight and work. -

Immigration and Acculturation
T h i r d E d i t i o n Shuang Liu, Zala VolČiČ & Cindy Gallois INTRODUCING Intercultural Communication • GLOBAL CULTURES AND CONTEXTS • LIU_aw.indd 6 00_LIU ET AL_FM.indd 3 05/06/2018 13:18 10/11/2018 12:50:50 PM 9 Immigration and Acculturation LEARNING OBJECTIVES At the end of this chapter, you should be able to: • Understand immigration as a major contributor to cultural diversity. • Explain culture shock and reverse culture shock. • Critically review acculturation models. • Identify the communication strategies that facilitate cross-cultural adaptation. 09_LIU ET AL_CH-09.indd 213 13/11/2018 4:02:17 PM 214 Introducing Intercultural Communication INTRODUCTION It goes without saying that our society is becoming more culturally and linguistically diverse by the day. An important contributor to cultural diversity is the migration of people. Some undertake voluntary migration and others are forced to do so: immigrants, refugees, asylum seekers, businesspeople, international students and so on. Globalization and communication technologies not only redefine the mobility of people in contemporary societies, they also delineate new parameters for interpreting immigration. Historically, immigration referred to the restricted cross-border movements of people, emphasizing the permanent relocation and settlement of usually unskilled, often indentured or contracted labourers who were displaced by political turmoil and thus had little option other than resettlement in a new country. Today, growing affluence and the emergence of a new group of skilled and educated people have fuelled a new global movement of migrants who are in search of better economic opportunities, an enhanced quality of life, greater political freedom and higher expectations. -

Deciphering the Cultural Code: Perceptual Congruence, Behavioral Conformity, and the Interpersonal Transmission of Culture
Deciphering the Cultural Code: Perceptual Congruence, Behavioral Conformity, and the Interpersonal Transmission of Culture Richard Lu University of California, Berkeley Jennifer A. Chatman University of California, Berkeley Amir Goldberg Stanford University Sameer B. Srivastava University of California, Berkeley Why are some people more successful than others at cultural adjustment? Research on organizational culture has mostly focused on value congruence as the core dimension of cultural fit. We develop a novel and comple- mentary conceptualization of cognitive cultural fit—perceptual congruence, or the degree to which a person can decipher the group's cultural code. We demonstrate that these two cognitive measures are associated with different outcomes: perceptual congruence equips people with the capacity to exhibit behavioral con- formity, whereas value congruence promotes long-term attachment to the organization. Moreover, all three fit measures|perceptual congruence, value congruence, and behavioral cultural fit—are positively related to individual performance. Finally, we show that behavioral cultural fit and perceptual congruence are both influenced by observations of others' behavior, whereas value congruence is less susceptible to peer influence. Drawing on email and survey data from a mid-sized technology firm, we use the tools of computational linguistics and machine learning to develop longitudinal measures of cognitive and behavioral cultural fit. We also take advantage of a reorganization that produced quasi-exogenous shifts in employees' interlocutors to identify the effects of peer influence on behavioral cultural fit. We discuss implications of these findings for research on cultural assimilation, the interplay of structure and culture, and the pairing of surveys with digital trace data. 1 Authors' names blinded for peer review 2 Article submitted to Organization Science; Introduction Whether assimilating to a country or adapting to a new school, people typically seek to fit in cul- turally with their social groups. -
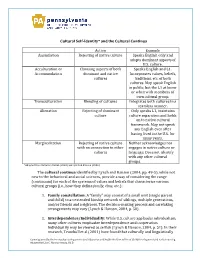
Cultural Self-Identity* and the Cultural Continua Action Example
Cultural Self-Identity* and the Cultural Continua Action Example Assimilation Rejecting of native culture Speaks English only and adopts dominant aspects of U.S. culture. Acculturation or Choosing aspects of both Speaks English and L1. Accommodation dominant and native Incorporates values, beliefs, cultures traditions, etc. of both cultures. May speak English in public, but the L1 at home or when with members of own cultural group. Transculturation Blending of cultures Integrates both cultures in a seamless manner. Alienation Rejecting of dominant Only speaks L1, maintains culture culture separation and holds on to native cultural framework. May not speak any English even after having lived in the U.S. for many years. Marginalization Rejecting of native culture Neither acknowledges nor with no connection to other engages in native culture or cultures language. Does not identify with any other cultural groups. *Adapted from Gutierez-Clellen (2004) and Lynch & Hanson (2004). The cultural continua identified by Lynch and Hanson (2004, pp. 49-5), while not new to the behavioral and social sciences, provide a way of considering the range (continuum) for each of the systems of values and beliefs that characterize various cultural groups (i.e., how they define family, time, etc.): 1. Family constellation: A “family” may consist of a small unit (single parent and child) to an extended kinship network of siblings, multiple generations, and/or friends and neighbors. The decision-making process and caretaking arrangements may vary (Lynch & Hanson, 2004, p. 50). 2. Interdependence/Individuality: While U.S. culture applauds individualism, many other cultures emphasize interdependence and cooperation. Individuality may be viewed as selfish (Lynch & Hanson, 2004, p.