Primepcr™Assay Validation Report
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
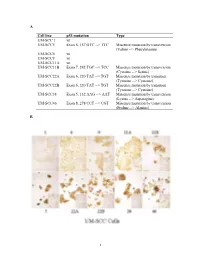
A Cell Line P53 Mutation Type UM
A Cell line p53 mutation Type UM-SCC 1 wt UM-SCC5 Exon 5, 157 GTC --> TTC Missense mutation by transversion (Valine --> Phenylalanine UM-SCC6 wt UM-SCC9 wt UM-SCC11A wt UM-SCC11B Exon 7, 242 TGC --> TCC Missense mutation by transversion (Cysteine --> Serine) UM-SCC22A Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC22B Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC38 Exon 5, 132 AAG --> AAT Missense mutation by transversion (Lysine --> Asparagine) UM-SCC46 Exon 8, 278 CCT --> CGT Missense mutation by transversion (Proline --> Alanine) B 1 Supplementary Methods Cell Lines and Cell Culture A panel of ten established HNSCC cell lines from the University of Michigan series (UM-SCC) was obtained from Dr. T. E. Carey at the University of Michigan, Ann Arbor, MI. The UM-SCC cell lines were derived from eight patients with SCC of the upper aerodigestive tract (supplemental Table 1). Patient age at tumor diagnosis ranged from 37 to 72 years. The cell lines selected were obtained from patients with stage I-IV tumors, distributed among oral, pharyngeal and laryngeal sites. All the patients had aggressive disease, with early recurrence and death within two years of therapy. Cell lines established from single isolates of a patient specimen are designated by a numeric designation, and where isolates from two time points or anatomical sites were obtained, the designation includes an alphabetical suffix (i.e., "A" or "B"). The cell lines were maintained in Eagle's minimal essential media supplemented with 10% fetal bovine serum and penicillin/streptomycin. -

Environmental Influences on Endothelial Gene Expression
ENDOTHELIAL CELL GENE EXPRESSION John Matthew Jeff Herbert Supervisors: Prof. Roy Bicknell and Dr. Victoria Heath PhD thesis University of Birmingham August 2012 University of Birmingham Research Archive e-theses repository This unpublished thesis/dissertation is copyright of the author and/or third parties. The intellectual property rights of the author or third parties in respect of this work are as defined by The Copyright Designs and Patents Act 1988 or as modified by any successor legislation. Any use made of information contained in this thesis/dissertation must be in accordance with that legislation and must be properly acknowledged. Further distribution or reproduction in any format is prohibited without the permission of the copyright holder. ABSTRACT Tumour angiogenesis is a vital process in the pathology of tumour development and metastasis. Targeting markers of tumour endothelium provide a means of targeted destruction of a tumours oxygen and nutrient supply via destruction of tumour vasculature, which in turn ultimately leads to beneficial consequences to patients. Although current anti -angiogenic and vascular targeting strategies help patients, more potently in combination with chemo therapy, there is still a need for more tumour endothelial marker discoveries as current treatments have cardiovascular and other side effects. For the first time, the analyses of in-vivo biotinylation of an embryonic system is performed to obtain putative vascular targets. Also for the first time, deep sequencing is applied to freshly isolated tumour and normal endothelial cells from lung, colon and bladder tissues for the identification of pan-vascular-targets. Integration of the proteomic, deep sequencing, public cDNA libraries and microarrays, delivers 5,892 putative vascular targets to the science community. -

HIST1H2AK (HIST1H2AG) Human Shrna Lentiviral Particle (Locus ID 8969) Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for TL304103V HIST1H2AK (HIST1H2AG) Human shRNA Lentiviral Particle (Locus ID 8969) Product data: Product Type: shRNA Lentiviral Particles Product Name: HIST1H2AK (HIST1H2AG) Human shRNA Lentiviral Particle (Locus ID 8969) Locus ID: 8969 Synonyms: H2A.1b; H2A/p; H2AC13; H2AC15; H2AC16; H2AC17; H2AFP; H2AG; HIST1H2AG; pH2A/f Vector: pGFP-C-shLenti (TR30023) Format: Lentiviral particles RefSeq: NM_021064, NM_021064.1, NM_021064.2, NM_021064.3, NM_021064.4, BC016677, BC016677.1, BC067782, NM_021064.5 Summary: Histones are basic nuclear proteins that are responsible for the nucleosome structure of the chromosomal fiber in eukaryotes. Two molecules of each of the four core histones (H2A, H2B, H3, and H4) form an octamer, around which approximately 146 bp of DNA is wrapped in repeating units, called nucleosomes. The linker histone, H1, interacts with linker DNA between nucleosomes and functions in the compaction of chromatin into higher order structures. This gene is intronless and encodes a replication-dependent histone that is a member of the histone H2A family. Transcripts from this gene lack polyA tails but instead contain a palindromic termination element. This gene is found in the histone microcluster on chromosome 6p21.33. [provided by RefSeq, Aug 2015] shRNA Design: These shRNA constructs were designed against multiple splice variants at this gene locus. To be certain that your variant of interest is targeted, please contact [email protected]. If you need a special design or shRNA sequence, please utilize our custom shRNA service. -

DNA Methylation Changes in Down Syndrome Derived Neural Ipscs Uncover Co-Dysregulation of ZNF and HOX3 Families of Transcription
Laan et al. Clinical Epigenetics (2020) 12:9 https://doi.org/10.1186/s13148-019-0803-1 RESEARCH Open Access DNA methylation changes in Down syndrome derived neural iPSCs uncover co- dysregulation of ZNF and HOX3 families of transcription factors Loora Laan1†, Joakim Klar1†, Maria Sobol1, Jan Hoeber1, Mansoureh Shahsavani2, Malin Kele2, Ambrin Fatima1, Muhammad Zakaria1, Göran Annerén1, Anna Falk2, Jens Schuster1 and Niklas Dahl1* Abstract Background: Down syndrome (DS) is characterized by neurodevelopmental abnormalities caused by partial or complete trisomy of human chromosome 21 (T21). Analysis of Down syndrome brain specimens has shown global epigenetic and transcriptional changes but their interplay during early neurogenesis remains largely unknown. We differentiated induced pluripotent stem cells (iPSCs) established from two DS patients with complete T21 and matched euploid donors into two distinct neural stages corresponding to early- and mid-gestational ages. Results: Using the Illumina Infinium 450K array, we assessed the DNA methylation pattern of known CpG regions and promoters across the genome in trisomic neural iPSC derivatives, and we identified a total of 500 stably and differentially methylated CpGs that were annotated to CpG islands of 151 genes. The genes were enriched within the DNA binding category, uncovering 37 factors of importance for transcriptional regulation and chromatin structure. In particular, we observed regional epigenetic changes of the transcription factor genes ZNF69, ZNF700 and ZNF763 as well as the HOXA3, HOXB3 and HOXD3 genes. A similar clustering of differential methylation was found in the CpG islands of the HIST1 genes suggesting effects on chromatin remodeling. Conclusions: The study shows that early established differential methylation in neural iPSC derivatives with T21 are associated with a set of genes relevant for DS brain development, providing a novel framework for further studies on epigenetic changes and transcriptional dysregulation during T21 neurogenesis. -

Integrating Single-Step GWAS and Bipartite Networks Reconstruction Provides Novel Insights Into Yearling Weight and Carcass Traits in Hanwoo Beef Cattle
animals Article Integrating Single-Step GWAS and Bipartite Networks Reconstruction Provides Novel Insights into Yearling Weight and Carcass Traits in Hanwoo Beef Cattle Masoumeh Naserkheil 1 , Abolfazl Bahrami 1 , Deukhwan Lee 2,* and Hossein Mehrban 3 1 Department of Animal Science, University College of Agriculture and Natural Resources, University of Tehran, Karaj 77871-31587, Iran; [email protected] (M.N.); [email protected] (A.B.) 2 Department of Animal Life and Environment Sciences, Hankyong National University, Jungang-ro 327, Anseong-si, Gyeonggi-do 17579, Korea 3 Department of Animal Science, Shahrekord University, Shahrekord 88186-34141, Iran; [email protected] * Correspondence: [email protected]; Tel.: +82-31-670-5091 Received: 25 August 2020; Accepted: 6 October 2020; Published: 9 October 2020 Simple Summary: Hanwoo is an indigenous cattle breed in Korea and popular for meat production owing to its rapid growth and high-quality meat. Its yearling weight and carcass traits (backfat thickness, carcass weight, eye muscle area, and marbling score) are economically important for the selection of young and proven bulls. In recent decades, the advent of high throughput genotyping technologies has made it possible to perform genome-wide association studies (GWAS) for the detection of genomic regions associated with traits of economic interest in different species. In this study, we conducted a weighted single-step genome-wide association study which combines all genotypes, phenotypes and pedigree data in one step (ssGBLUP). It allows for the use of all SNPs simultaneously along with all phenotypes from genotyped and ungenotyped animals. Our results revealed 33 relevant genomic regions related to the traits of interest. -

Genome-Wide Screen of Cell-Cycle Regulators in Normal and Tumor Cells
bioRxiv preprint doi: https://doi.org/10.1101/060350; this version posted June 23, 2016. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Genome-wide screen of cell-cycle regulators in normal and tumor cells identifies a differential response to nucleosome depletion Maria Sokolova1, Mikko Turunen1, Oliver Mortusewicz3, Teemu Kivioja1, Patrick Herr3, Anna Vähärautio1, Mikael Björklund1, Minna Taipale2, Thomas Helleday3 and Jussi Taipale1,2,* 1Genome-Scale Biology Program, P.O. Box 63, FI-00014 University of Helsinki, Finland. 2Science for Life laboratory, Department of Biosciences and Nutrition, Karolinska Institutet, SE- 141 83 Stockholm, Sweden. 3Science for Life laboratory, Division of Translational Medicine and Chemical Biology, Department of Medical Biochemistry and Biophysics, Karolinska Institutet, S-171 21 Stockholm, Sweden To identify cell cycle regulators that enable cancer cells to replicate DNA and divide in an unrestricted manner, we performed a parallel genome-wide RNAi screen in normal and cancer cell lines. In addition to many shared regulators, we found that tumor and normal cells are differentially sensitive to loss of the histone genes transcriptional regulator CASP8AP2. In cancer cells, loss of CASP8AP2 leads to a failure to synthesize sufficient amount of histones in the S-phase of the cell cycle, resulting in slowing of individual replication forks. Despite this, DNA replication fails to arrest, and tumor cells progress in an elongated S-phase that lasts several days, finally resulting in death of most of the affected cells. -

Multi-Sample Full-Length Transcriptome Analysis of 22 Breast Cancer Clinical
bioRxiv preprint doi: https://doi.org/10.1101/2020.07.15.199851; this version posted July 16, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-ND 4.0 International license. Multi-sample Full-length Transcriptome Analysis of 22 Breast Cancer Clinical Specimens with Long-Read Sequencing Shinichi Namba1, §, Toshihide Ueno1, Shinya Kojima1, Yosuke Tanaka1, Satoshi Inoue1, Fumishi Kishigami1, Noriko Maeda2, Tomoko Ogawa3, Shoichi Hazama4, Yuichi Shiraishi5, Hiroyuki Mano1, and Masahito Kawazu1* Author affiliations: 1Division of Cellular Signaling, 5Division of Genome Analysis Platform Development, Research Institute, National Cancer Center, Tokyo 104-0045, Japan; 2Department of Gastroenterological, Breast and Endocrine Surgery, 4Department of Translational Research and Developmental Therapeutics against Cancer, Yamaguchi University Graduate School of Medicine, Yamaguchi 755-8505, Japan; 3Department of Breast Surgery, Mie University Hospital, Mie 514-8507, Japan; § Present address, Department of Statistical Genetics, Osaka University Graduate School of Medicine, Osaka 565-0871, Japan; * Corresponding author E-mail:[email protected] (MK) bioRxiv preprint doi: https://doi.org/10.1101/2020.07.15.199851; this version posted July 16, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-ND 4.0 International license. Abstract Although transcriptome alteration is considered as one of the essential drivers of carcinogenesis, conventional short-read RNAseq technology has limited researchers from directly exploring full-length transcripts, only focusing on individual splice sites. -

Histone-Related Genes Are Hypermethylated in Lung Cancer
Published OnlineFirst October 1, 2019; DOI: 10.1158/0008-5472.CAN-19-1019 Cancer Genome and Epigenome Research Histone-Related Genes Are Hypermethylated in Lung Cancer and Hypermethylated HIST1H4F Could Serve as a Pan-Cancer Biomarker Shihua Dong1,Wei Li1, Lin Wang2, Jie Hu3,Yuanlin Song3, Baolong Zhang1, Xiaoguang Ren1, Shimeng Ji3, Jin Li1, Peng Xu1, Ying Liang1, Gang Chen4, Jia-Tao Lou2, and Wenqiang Yu1 Abstract Lung cancer is the leading cause of cancer-related deaths lated in all 17 tumor types from TCGA datasets (n ¼ 7,344), worldwide. Cytologic examination is the current "gold stan- which was further validated in nine different types of cancer dard" for lung cancer diagnosis, however, this has low sensi- (n ¼ 243). These results demonstrate that HIST1H4F can tivity. Here, we identified a typical methylation signature of function as a universal-cancer-only methylation (UCOM) histone genes in lung cancer by whole-genome DNA methyl- marker, which may aid in understanding general tumorigen- ation analysis, which was validated by The Cancer Genome esis and improve screening for early cancer diagnosis. Atlas (TCGA) lung cancer cohort (n ¼ 907) and was further confirmed in 265 bronchoalveolar lavage fluid samples with Significance: These findings identify a new biomarker for specificity and sensitivity of 96.7% and 87.0%, respectively. cancer detection and show that hypermethylation of histone- More importantly, HIST1H4F was universally hypermethy- related genes seems to persist across cancers. Introduction to its low specificity, LDCT is far from satisfactory as a screening tool for clinical application, similar to other currently used cancer Lung cancer is one of the most common malignant tumors and biomarkers, such as carcinoembryonic antigen (CEA), neuron- the leading cause of cancer-related deaths worldwide (1, 2). -

Brain Region-Dependent Gene Networks Associated with Selective Breeding for Increased Voluntary Wheel-Running Behavior
UC Riverside UC Riverside Previously Published Works Title Brain region-dependent gene networks associated with selective breeding for increased voluntary wheel-running behavior. Permalink https://escholarship.org/uc/item/8c49g8fd Journal PloS one, 13(8) ISSN 1932-6203 Authors Zhang, Pan Rhodes, Justin S Garland, Theodore et al. Publication Date 2018 DOI 10.1371/journal.pone.0201773 Peer reviewed eScholarship.org Powered by the California Digital Library University of California RESEARCH ARTICLE Brain region-dependent gene networks associated with selective breeding for increased voluntary wheel-running behavior Pan Zhang1,2, Justin S. Rhodes3,4, Theodore Garland, Jr.5, Sam D. Perez3, Bruce R. Southey2, Sandra L. Rodriguez-Zas2,6,7* 1 Illinois Informatics Institute, University of Illinois at Urbana-Champaign, Urbana, IL, United States of America, 2 Department of Animal Sciences, University of Illinois at Urbana-Champaign, Urbana, IL, United a1111111111 States of America, 3 Beckman Institute for Advanced Science and Technology, Urbana, IL, United States of a1111111111 America, 4 Center for Nutrition, Learning and Memory, University of Illinois at Urbana-Champaign, Urbana, a1111111111 IL, United States of America, 5 Department of Evolution, Ecology, and Organismal Biology, University of a1111111111 California, Riverside, CA, United States of America, 6 Department of Statistics, University of Illinois at Urbana-Champaign, Urbana, IL, United States of America, 7 Carle Woese Institute for Genomic Biology, a1111111111 University of Illinois at Urbana-Champaign, Urbana, IL, United States of America * [email protected] OPEN ACCESS Abstract Citation: Zhang P, Rhodes JS, Garland T, Jr., Perez SD, Southey BR, Rodriguez-Zas SL (2018) Brain Mouse lines selectively bred for high voluntary wheel-running behavior are helpful models region-dependent gene networks associated with for uncovering gene networks associated with increased motivation for physical activity and selective breeding for increased voluntary wheel- other reward-dependent behaviors. -

A Yeast Phenomic Model for the Influence of Warburg Metabolism on Genetic Buffering of Doxorubicin Sean M
Santos and Hartman Cancer & Metabolism (2019) 7:9 https://doi.org/10.1186/s40170-019-0201-3 RESEARCH Open Access A yeast phenomic model for the influence of Warburg metabolism on genetic buffering of doxorubicin Sean M. Santos and John L. Hartman IV* Abstract Background: The influence of the Warburg phenomenon on chemotherapy response is unknown. Saccharomyces cerevisiae mimics the Warburg effect, repressing respiration in the presence of adequate glucose. Yeast phenomic experiments were conducted to assess potential influences of Warburg metabolism on gene-drug interaction underlying the cellular response to doxorubicin. Homologous genes from yeast phenomic and cancer pharmacogenomics data were analyzed to infer evolutionary conservation of gene-drug interaction and predict therapeutic relevance. Methods: Cell proliferation phenotypes (CPPs) of the yeast gene knockout/knockdown library were measured by quantitative high-throughput cell array phenotyping (Q-HTCP), treating with escalating doxorubicin concentrations under conditions of respiratory or glycolytic metabolism. Doxorubicin-gene interaction was quantified by departure of CPPs observed for the doxorubicin-treated mutant strain from that expected based on an interaction model. Recursive expectation-maximization clustering (REMc) and Gene Ontology (GO)-based analyses of interactions identified functional biological modules that differentially buffer or promote doxorubicin cytotoxicity with respect to Warburg metabolism. Yeast phenomic and cancer pharmacogenomics data were integrated to predict differential gene expression causally influencing doxorubicin anti-tumor efficacy. Results: Yeast compromised for genes functioning in chromatin organization, and several other cellular processes are more resistant to doxorubicin under glycolytic conditions. Thus, the Warburg transition appears to alleviate requirements for cellular functions that buffer doxorubicin cytotoxicity in a respiratory context. -

Rap1-Mediated Chromatin and Gene Expression Changes at Senescence
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations 2019 Rap1-Mediated Chromatin And Gene Expression Changes At Senescence Shufei Song University of Pennsylvania Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Biochemistry Commons, and the Cell Biology Commons Recommended Citation Song, Shufei, "Rap1-Mediated Chromatin And Gene Expression Changes At Senescence" (2019). Publicly Accessible Penn Dissertations. 3557. https://repository.upenn.edu/edissertations/3557 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/3557 For more information, please contact [email protected]. Rap1-Mediated Chromatin And Gene Expression Changes At Senescence Abstract ABSTRACT RAP1-MEDIATED CHROMATIN AND GENE EXPRESSION CHANGES AT SENESCENCE The telomeric protein Rap1 has been extensively studied for its roles as a transcriptional activator and repressor. Indeed, in both yeast and mammals, Rap1 is known to bind throughout the genome to reorganize chromatin and regulate gene transcription. Previously, our lab published evidence that Rap1 plays important roles in cellular senescence. In telomerase-deficient S. cerevisiae, Rap1 relocalizes from telomeres and subtelomeres to new Rap1 target at senescence (NRTS). This leads to two types of histone loss: Rap1 lowers global histone levels by repressing histone gene transcription and it also results in local nucleosome displacement at the promoters of the activated NRTS. Here, I examine mechanisms of site-specific histone loss by presenting evidence that Rap1 can directly interact with histone tetramers H3/H4, and map this interaction to a three-amino-acid-patch within the DNA binding domain. Functional studies are performed in vivo using a mutant form of Rap1 with weakened histone interactions, and deficient promoter clearance as well as blunted gene activation is observed, indicating that direct Rap1-H3/H4 interactions are involved in nucleosome displacement. -

HIST1H2AK (HIST1H2AM) (NM 003514) Human Recombinant Protein Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for TP760612 HIST1H2AK (HIST1H2AM) (NM_003514) Human Recombinant Protein Product data: Product Type: Recombinant Proteins Description: Purified recombinant protein of Human histone cluster 1, H2am (HIST1H2AM), full length, with N-terminal HIS tag, expressed in E.Coli, 50ug Species: Human Expression Host: E. coli Tag: N-His Predicted MW: 13.9 kDa Concentration: >50 ug/mL as determined by microplate BCA method Purity: > 80% as determined by SDS-PAGE and Coomassie blue staining Buffer: 50mM Tris,8M Urea,pH8.0. Storage: Store at -80°C. Stability: Stable for 12 months from the date of receipt of the product under proper storage and handling conditions. Avoid repeated freeze-thaw cycles. RefSeq: NP_003505 Locus ID: 8336 UniProt ID: P0C0S8, A4FTV9 RefSeq Size: 487 Cytogenetics: 6p22.1 RefSeq ORF: 390 Synonyms: dJ193B12.1; H2A.1; H2A/n; H2AC11; H2AC13; H2AC15; H2AC16; H2AFN; HIST1H2AM This product is to be used for laboratory only. Not for diagnostic or therapeutic use. View online » ©2021 OriGene Technologies, Inc., 9620 Medical Center Drive, Ste 200, Rockville, MD 20850, US 1 / 2 HIST1H2AK (HIST1H2AM) (NM_003514) Human Recombinant Protein – TP760612 Summary: Histones are basic nuclear proteins that are responsible for the nucleosome structure of the chromosomal fiber in eukaryotes. Two molecules of each of the four core histones (H2A, H2B, H3, and H4) form an octamer, around which approximately 146 bp of DNA is wrapped in repeating units, called nucleosomes.