Virtual Organization Clusters: Self-Provisioned Clouds on the Grid Michael Murphy Clemson University, [email protected]
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Evaluation of the CSF Firewall
Bachelor Thesis in Software Engineering, 15 credits May 2013 Evaluation of the CSF Firewall Ahmad Mudhar Contact Information: Ahmad Mudhar E-mail: [email protected] University advisor: Kari Rönkkö Nina Fogelström School of Computing Internet : www.bth.se/com Blekinge Institute of Technology Phone : +46 455 38 50 00 SE-371 79 Karlskrona Fax : +46 455 38 50 57 Sweden 1 Abstract The subject of web server security is vast, and it is becoming bigger as time passes by. Every year, researches, both private and public, are adding to the number of possible threats to the security of web servers, and coming up with possible solutions to them. A number of these solutions are considered to be expensive, complex, and incredibly time-consuming, while not able to create the perfect web to challenge any breach to the server security. In the study that follows, an attempt will be made to check whether a particular firewall can ensure a strong security measure and deal with some security breaches or severe threat to an existing web server. The research conducted has been done with the CSF Firewall, which provides a suit of scripts that ensure a portal’s security through a number of channels. The experiments conducted under the research provided extremely valuable insights about the application in hand, and the number of ways the CSF Firewall can help in safety of a portal against Secured Shell (SSH) attacks, dedicated to break the security of it, in its initial stages. It further goes to show how simple it is to actually detect the prospective attacks, and subsequently stop the Denial of Service (DoS) attacks, as well as the port scans made to the server, with the intent of breaching the security, by finding out an open port. -

Kosten Senken Dank Open Source?
View metadata, citation and similar papers at core.ac.uk brought to you by CORE Kosten senken dank Open Source? provided by Bern Open Repository andStrategien Information System (BORIS) | downloaded: 13.3.2017 https://doi.org/10.7892/boris.47380 source: 36 Nr. 01/02 | Februar 2014 Swiss IT Magazine Strategien Kosten senken dank Open Source? Mehr Geld im Portemonnaie und weniger Sorgen im Gepäck Der Einsatz von Open Source Software kann das IT-Budget schonen, wenn man richtig vorgeht. Viel wichtiger sind aber strategische Vorteile wie die digitale Nachhaltigkeit oder die Unabhängigkeit von Herstellern, die sich durch den konsequenten Einsatz von Open Source ergeben. V ON D R . M ATTHIAS S TÜR M ER ines vorweg: Open Source ist nicht gra- tis. Oder korrekt ausgedrückt: Der Download von Open Source Software (OSS) von den vielen Internet-Portalen wieE Github, Google Code, Sourceforge oder Freecode ist selbstverständlich kostenlos. Aber wenn Open-Source-Lösungen professionell eingeführt und betrieben werden, verursacht dies interne und/oder externe Kosten. Geschäftskritische Lösungen benötigen stets zuverlässige Wartung und Support, ansonsten steigt das Risiko erheblich, dass zentrale Infor- matiksysteme ausfallen oder wichtige Daten verloren gehen oder gestohlen werden. Für den sicheren Einsatz von Open Source Soft- ware braucht es deshalb entweder interne INHALT Ressourcen und Know-how, wie die entspre- chenden Systeme betrieben werden. Oder es MEHR GELD im PORTemoNNaie UND weNIGER SorgeN im GEPÄck 36 wird ein Service Level Agreement (SLA) bei- MarkTÜbersicHT: 152 SCHweiZer OPEN-SOUrce-SPEZialisTEN 40 spielsweise in Form einer Subscription mit einem kommerziellen Anbieter von Open- SpareN ODER NICHT spareN 48 Source-Lösungen abgeschlossen. -

The Programming Language Concurrent Pascal
IEEE TRANSACTIONS ON SOFTWARE ENGINEERING, VOL. SE-I, No.2, JUNE 1975 199 The Programming Language Concurrent Pascal PER BRINCH HANSEN Abstract-The paper describes a new programming language Disk buffer for structured programming of computer operating systems. It e.lt tends the sequential programming language Pascal with concurx:~t programming tools called processes and monitors. Section I eltplains these concepts informally by means of pictures illustrating a hier archical design of a simple spooling system. Section II uses the same enmple to introduce the language notation. The main contribu~on of Concurrent Pascal is to extend the monitor concept with an .ex Producer process Consumer process plicit hierarchy Of access' rights to shared data structures that can Fig. 1. Process communication. be stated in the program text and checked by a compiler. Index Terms-Abstract data types, access rights, classes, con current processes, concurrent programming languages, hierarchical operating systems, monitors, scheduling, structured multiprogram ming. Access rights Private data Sequential 1. THE PURPOSE OF CONCURRENT PASCAL program A. Background Fig. 2. Process. INCE 1972 I have been working on a new programming .. language for structured programming of computer S The next picture shows a process component in more operating systems. This language is called Concurrent detail (Fig. 2). Pascal. It extends the sequential programming language A process consists of a private data structure and a Pascal with concurrent programming tools called processes sequential program that can operate on the data. One and monitors [1J-[3]' process cannot operate on the private data of another This is an informal description of Concurrent Pascal. -

The Programmer As a Young Dog
The Programmer as a Young Dog (1976) This autobiographical sketch describes the beginning of the author’s career at the Danish computer company Regnecentralen from 1963 to 1970. (The title is inspired by James Joyce’s “A Portrait of the Artist as a Young Man” and Dylan Thomas’s “Portrait of the Artist as a Young Dog.”) After three years in Regnecentralen’s compiler group, the author got the chance to design the architecture of the RC 4000 computer. In 1967, he became Head of the Software Development group that designed the RC 4000 multiprogramming system. The article was written in memory of Niels Ivar Bech, the dynamic director of Regnecentralen, who inspired a generation of young Danes to make unique contributions to computing. I came to Regnecentralen in 1963 to work with Peter Naur and Jrn Jensen. The two of them worked so closely together that they hardly needed to say anything to solve a problem. I remember a discussion where Peter was writing something on the blackboard, when Jrn suddenly said “but Peter ...” and immediately was interrupted with the reply “yes, of course, Jrn.” I swear that nothing else was said. It made quite an impression on me, especially since I didn’t even know what the discussion was about in the rst place. After a two-year apprenticeship as a systems programmer, I wanted to travel abroad and work for IBM in Winchester in Southern England. At that time Henning Isaksson was planning to build a process control computer for Haldor Topse, Ltd. Henning had asked Niels Ivar Bech for a systems programmer for quite some time. -

Databits: an Electronic Newsletter for Information Managers
DataBits: An electronic newsletter for Information Managers Wade Sheldon (GCE) and Margaret O’Brien (SBC), co-editors Spring 2008 Issue Table of Contents Feature Articles The FCE LTER Website has a NEW look! - Linda Powell ......................................................1 Developing a Searchable Document and Imagery Archive for the GCE-LTER Web Site - Wade Sheldon....................................................................................................................5 Improving the Basic Keyword Search for Datasets by Employing Text Mining Techniques and Indexing - Hung V. Nguyen, Corinna Gries, Hasan Davulcu ..................9 Developing and Using APIs in System Design - James Connors, Mason Kortz ....................12 FinLTSER Network: New addition to the global LTER network - Helena Karasti ..............14 Commentary Using Xen and VMWare to Manage Virtual Machines: A New User’s Saga - John H. Porter.................................................................................................................18 Making Sense of Collaboration Software - James W Brunt....................................................20 Big Science and Local Meetings - Karen Baker, Sabine Grabner..........................................23 Preservation Metadata: Another Chapter in the Metadata Story - Lynn Yarmey ....................25 Data Quality: Yet Another Chapter in the Metadata Story - Lynn Yarmey.............................27 Good Tools and Programs Specifik, a Taxonomic Reference Tool to Support Synthesis of Vegetation -

Part Iii Harnessing Parallelism
PART III HARNESSING PARALLELISM The primary impetus behind the study of parallel programming, or concurrent programming as some would call it, was the necessity to write operating systems. While the first computers were simple enough to be considered sequential in nature, the advent of faster central processing units and the accompanying discrepancy in speed between the central processor and periph eral devices forced the consideration of possible concurrent activity of these mechanisms. The operating system was asked to control concurrent activity, and to control it in such a way that concurrent activity was maximized This desire for concurrent activity resulted in machine features such as the channel and the interrupt-the mechanism by which termination of an I/O activity is signaled The main problem with the interrupt, as far as the operating system designer was concerned, was its inherent unpredictability. Not knowing exactly when an interrupt could occur, the operating system had to be designed to expect an interrupt at any time. With the advent of multiprogramming and interactive, on-line processing, it became clear that the original motivation for parallelism-the control and exploitation of concurrent I/O-was only a special case, and some fundamen tal concepts began to emerge for study and use in more general parallel programming situations. Thus emerged the general idea of a set of processes executing concurrently, with the need for synchronization and mutual exclu sion (with respect to time) of some of their activities. The past 10-15 years have seen an enormous amount of activity in studying the general problem, a very small part of which is presented here. -

A Programmer's Story. the Life of a Computer Pioneer
A PROGRAMMER’S STORY The Life of a Computer Pioneer PER BRINCH HANSEN FOR CHARLES HAYDEN Copyright c 2004 by Per Brinch Hansen. All rights reserved. Per Brinch Hansen 5070 Pine Valley Drive, Fayetteville, NY 13066, USA CONTENTS Acknowledgments v 1 Learning to Read and Write 1938–57 1 Nobody ever writes two books – My parents – Hitler occupies Denmark – Talking in kindergarten – A visionary teacher – The class newspaper – “The topic” – An elite high school – Variety of teachers – Chemical experiments – Playing tennis with a champion – Listening to jazz – “Ulysses” and other novels. 2 Choosing a Career 1957–63 17 Advice from a professor – Technical University of Denmark – rsted’s inuence – Distant professors – Easter brew – Fired for being late – International exchange student – Masers and lasers – Radio talk — Graduation trip to Yugoslavia – An attractive tourist guide – Master of Science – Professional goals. 3 Learning from the Masters 1963–66 35 Regnecentralen – Algol 60 – Peter Naur and Jrn Jensen – Dask and Gier Algol – The mysterious Cobol 61 report – I join the compiler group – Playing roulette at Marienlyst resort – Jump- starting Siemens Cobol at Mogenstrup Inn – Negotiating salary – Compiler testing in Munich – Naur and Dijkstra smile in Stock- holm – The Cobol compiler is nished – Milena and I are married in Slovenia. 4 Young Man in a Hurr 1966–70 59 Naur’s vision of datalogy – Architect of the RC 4000 computer – Programming a real-time system – Working with Henning Isaks- son, Peter Kraft, and Charles Simonyi – Edsger Dijkstra’s inu- ence – Head of software development – Risking my future at Hotel Marina – The RC 4000 multiprogramming system – I meet Edsger Dijkstra, Niklaus Wirth, and Tony Hoare – The genius of Niels Ivar Bech. -

Neural Network FAQ, Part 1 of 7: Introduction
Neural Network FAQ, part 1 of 7: Introduction Archive-name: ai-faq/neural-nets/part1 Last-modified: 2002-05-17 URL: ftp://ftp.sas.com/pub/neural/FAQ.html Maintainer: [email protected] (Warren S. Sarle) Copyright 1997, 1998, 1999, 2000, 2001, 2002 by Warren S. Sarle, Cary, NC, USA. --------------------------------------------------------------- Additions, corrections, or improvements are always welcome. Anybody who is willing to contribute any information, please email me; if it is relevant, I will incorporate it. The monthly posting departs around the 28th of every month. --------------------------------------------------------------- This is the first of seven parts of a monthly posting to the Usenet newsgroup comp.ai.neural-nets (as well as comp.answers and news.answers, where it should be findable at any time). Its purpose is to provide basic information for individuals who are new to the field of neural networks or who are just beginning to read this group. It will help to avoid lengthy discussion of questions that often arise for beginners. SO, PLEASE, SEARCH THIS POSTING FIRST IF YOU HAVE A QUESTION and DON'T POST ANSWERS TO FAQs: POINT THE ASKER TO THIS POSTING The latest version of the FAQ is available as a hypertext document, readable by any WWW (World Wide Web) browser such as Netscape, under the URL: ftp://ftp.sas.com/pub/neural/FAQ.html. If you are reading the version of the FAQ posted in comp.ai.neural-nets, be sure to view it with a monospace font such as Courier. If you view it with a proportional font, tables and formulas will be mangled. -

Comparing User Experiences in Using Twiki & Mediawiki To
Liang, M., Chu, S., Siu, F., & Zhou, A. (2009). Comparing User Experiences in Using Twiki & Mediawiki to Facilitate Collaborative Learning. Proceedings of the 2009 International Conference on Knowledge Management [CD-ROM]. Hong Kong, Dec 3-4, 2009. COMPARING USER EXPERIENCES IN USING TWIKI & MEDIAWIKI TO FACILITATE COLLABORATIVE LEARNING MICHAEL LIANG* IT and Management Consulting Division, WiderWorld Company Ltd. [email protected] † SAM CHU , FELIX SIU and AUDREY ZHOU Faculty of Education, the University of Hong Kong † [email protected] This research seeks to determine the perceived effectiveness of using TWiki and MediaWiki in collaborative work and knowledge management; and to compare the use of TWiki and MediaWiki in terms of user experiences in the master’s level of study at the University of Hong Kong. Through a multiple case study approach, the study adopted a mixed methods research design which used both quantitative and qualitative methods to analyze findings from specific user groups in two study programmes. In the study, both wiki platforms were regarded as suitable tools for group work co-construction, which were found to be effective in improving group collaboration and work quality. Wikis were also viewed as enabling tools for knowledge management. MediaWiki was rated more favorably than TWiki, especially in the ease of use and enjoyment experienced. The paper should be of interest to educators who may want to explore wiki as a platform to enhance students’ collaborative group work. 1. Introduction Rote learning, which focuses on the direct transmission of knowledge from teachers to students using a traditional didactic approach, is the prevalent norm in education in many countries (Jang, 2007). -

Tutorial: Wikis in the Workplace" for Wiki Symposium, Montreal, Canada, 22 Oct 2007
This is the presentation material for the 3 hour session on "Tutorial: Wikis in the Workplace" for Wiki Symposium, Montreal, Canada, 22 Oct 2007. Slide 1: Tutorial: Wikis in the Workplace "Wikis have changed the way we run meetings, plan releases, document our product and generally communicate with each other" - Eric Baldeschwieler, Director of Software Development of Yahoo! • Wiki, a writable web: Communities can share content and organize it in a way most meaningful and useful to them • If extended with the right set of functionality, a wiki can be applied to the workplace to schedule, manage, document, and support daily activities • A structured wiki combines the benefits of a wiki and a database • This tutorial explains publishing wikis and structured wiki, covers its deployment, and shows some sample applications using TWiki, an open source enterprise wiki platform Presentation for Wiki Symposium, Montreal, Canada, 22 Oct 2007 -- Peter Thoeny - [email protected] - TWIKI.NET Slide 2: About Peter • Peter Thoeny - [email protected] • Founder of TWiki, the leading wiki for corporate collaboration, managing the open-sourced project for the last 9 years • Co-founder of TWIKI.NET , a company offering services and support for TWiki • Co-author of Wikis for Dummies book • Invented the concept of Structured Wikis - where free form wiki content can be structured with tailored wiki applications • Recognized thought-leader in Wikis and social software, featured in numerous articles and technology conferences including -
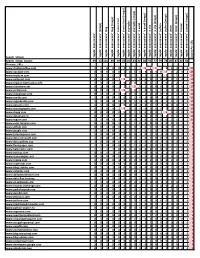
Regular Expressions Search String Counts
"regular expressions" (image) "regular expressions" blog"regular expressions" blog"regular (image) expressions" cheat"regular sheet expressions" cheat"regular sheet (image) expressions" examples "regular expressions" examples"regular (image) expressions" in "regular excel expressions" in (image) "regular excel expressions" in "regular vba expressions" in "regular vba (image) expressions" python"regular expressions" python"regular (image) expressions" tester"regular expressions" tester "regular (image) expressions" tutorial"regular expressions" tutorial"regular (image) Counts URL Per Search_Strings expressions""regular Search_String_Counts 99 91 101 89 99 85 ## 85 ## 80 96 77 99 78 ## 87 ## 86 Primary_URLs www.stackoverflow.com 1 1 0 0 0 0 1 1 1 6 1 5 1 2 1 3 1 0 25 www.youtube.com 0 3 0 0 0 1 0 3 0 3 0 4 0 5 0 2 0 4 25 www.medium.com 1 1 1 0 1 1 1 2 1 1 1 1 1 2 1 1 1 3 21 www.pinterest.com 0 0 0 0 1 9 0 1 0 0 0 1 0 4 0 1 0 2 19 www.regular-expressions.info 1 3 1 0 1 0 2 0 1 0 1 1 1 0 2 2 1 1 18 www.slideshare.net 0 1 0 0 1 2 0 5 0 1 0 0 0 3 0 2 0 2 17 www.scribd.com 0 0 0 2 1 8 0 0 0 0 0 1 0 2 0 0 0 1 15 www.slideplayer.com 0 1 0 1 0 1 0 4 0 1 0 0 0 3 0 2 0 2 15 www.oreilly.com 1 1 0 0 0 0 1 1 0 1 0 0 1 1 1 1 1 1 11 www.regexbuddy.com 1 3 0 0 0 0 0 1 0 0 0 0 1 1 1 2 1 0 11 www.amazon.com 1 1 0 0 1 0 0 0 1 0 1 1 1 0 0 0 1 2 10 www.cheatography.com 0 1 0 0 1 6 0 0 0 0 0 1 0 1 0 0 0 0 10 www.chegg.com 0 0 0 0 0 0 0 1 0 0 0 0 1 6 0 0 0 2 10 www.dataquest.io 0 1 1 1 1 1 0 0 1 0 0 0 1 1 1 0 1 0 10 www.regexr.com 1 1 0 0 1 1 0 0 1 0 1 0 0 0 -

Downloading from Naur's Website: 19
1 2017.04.16 Accepted for publication in Nuncius Hamburgensis, Band 20. Preprint of invited paper for Gudrun Wolfschmidt's book: Vom Abakus zum Computer - Begleitbuch zur Ausstellung "Geschichte der Rechentechnik", 2015-2019 GIER: A Danish computer from 1961 with a role in the modern revolution of astronomy By Erik Høg, lektor emeritus, Niels Bohr Institute, Copenhagen Abstract: A Danish computer, GIER, from 1961 played a vital role in the development of a new method for astrometric measurement. This method, photon counting astrometry, ultimately led to two satellites with a significant role in the modern revolution of astronomy. A GIER was installed at the Hamburg Observatory in 1964 where it was used to implement the entirely new method for the meas- urement of stellar positions by means of a meridian circle, then the fundamental instrument of as- trometry. An expedition to Perth in Western Australia with the instrument and the computer was a suc- cess. This method was also implemented in space in the first ever astrometric satellite Hipparcos launched by ESA in 1989. The Hipparcos results published in 1997 revolutionized astrometry with an impact in all branches of astronomy from the solar system and stellar structure to cosmic distances and the dynamics of the Milky Way. In turn, the results paved the way for a successor, the one million times more powerful Gaia astrometry satellite launched by ESA in 2013. Preparations for a Gaia suc- cessor in twenty years are making progress. Zusammenfassung: Eine elektronische Rechenmaschine, GIER, von 1961 aus Dänischer Herkunft spielte eine vitale Rolle bei der Entwiklung einer neuen astrometrischen Messmethode.