The Typed Racket Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lecture Notes on Types for Part II of the Computer Science Tripos
Q Lecture Notes on Types for Part II of the Computer Science Tripos Prof. Andrew M. Pitts University of Cambridge Computer Laboratory c 2016 A. M. Pitts Contents Learning Guide i 1 Introduction 1 2 ML Polymorphism 6 2.1 Mini-ML type system . 6 2.2 Examples of type inference, by hand . 14 2.3 Principal type schemes . 16 2.4 A type inference algorithm . 18 3 Polymorphic Reference Types 25 3.1 The problem . 25 3.2 Restoring type soundness . 30 4 Polymorphic Lambda Calculus 33 4.1 From type schemes to polymorphic types . 33 4.2 The Polymorphic Lambda Calculus (PLC) type system . 37 4.3 PLC type inference . 42 4.4 Datatypes in PLC . 43 4.5 Existential types . 50 5 Dependent Types 53 5.1 Dependent functions . 53 5.2 Pure Type Systems . 57 5.3 System Fw .............................................. 63 6 Propositions as Types 67 6.1 Intuitionistic logics . 67 6.2 Curry-Howard correspondence . 69 6.3 Calculus of Constructions, lC ................................... 73 6.4 Inductive types . 76 7 Further Topics 81 References 84 Learning Guide These notes and slides are designed to accompany 12 lectures on type systems for Part II of the Cambridge University Computer Science Tripos. The course builds on the techniques intro- duced in the Part IB course on Semantics of Programming Languages for specifying type systems for programming languages and reasoning about their properties. The emphasis here is on type systems for functional languages and their connection to constructive logic. We pay par- ticular attention to the notion of parametric polymorphism (also known as generics), both because it has proven useful in practice and because its theory is quite subtle. -

Open C++ Tutorial∗
Open C++ Tutorial∗ Shigeru Chiba Institute of Information Science and Electronics University of Tsukuba [email protected] Copyright c 1998 by Shigeru Chiba. All Rights Reserved. 1 Introduction OpenC++ is an extensible language based on C++. The extended features of OpenC++ are specified by a meta-level program given at compile time. For dis- tinction, regular programs written in OpenC++ are called base-level programs. If no meta-level program is given, OpenC++ is identical to regular C++. The meta-level program extends OpenC++ through the interface called the OpenC++ MOP. The OpenC++ compiler consists of three stages: preprocessor, source-to-source translator from OpenC++ to C++, and the back-end C++ com- piler. The OpenC++ MOP is an interface to control the translator at the second stage. It allows to specify how an extended feature of OpenC++ is translated into regular C++ code. An extended feature of OpenC++ is supplied as an add-on software for the compiler. The add-on software consists of not only the meta-level program but also runtime support code. The runtime support code provides classes and functions used by the base-level program translated into C++. The base-level program in OpenC++ is first translated into C++ according to the meta-level program. Then it is linked with the runtime support code to be executable code. This flow is illustrated by Figure 1. The meta-level program is also written in OpenC++ since OpenC++ is a self- reflective language. It defines new metaobjects to control source-to-source transla- tion. The metaobjects are the meta-level representation of the base-level program and they perform the translation. -

Let's Get Functional
5 LET’S GET FUNCTIONAL I’ve mentioned several times that F# is a functional language, but as you’ve learned from previous chapters you can build rich applications in F# without using any functional techniques. Does that mean that F# isn’t really a functional language? No. F# is a general-purpose, multi paradigm language that allows you to program in the style most suited to your task. It is considered a functional-first lan- guage, meaning that its constructs encourage a functional style. In other words, when developing in F# you should favor functional approaches whenever possible and switch to other styles as appropriate. In this chapter, we’ll see what functional programming really is and how functions in F# differ from those in other languages. Once we’ve estab- lished that foundation, we’ll explore several data types commonly used with functional programming and take a brief side trip into lazy evaluation. The Book of F# © 2014 by Dave Fancher What Is Functional Programming? Functional programming takes a fundamentally different approach toward developing software than object-oriented programming. While object-oriented programming is primarily concerned with managing an ever-changing system state, functional programming emphasizes immutability and the application of deterministic functions. This difference drastically changes the way you build software, because in object-oriented programming you’re mostly concerned with defining classes (or structs), whereas in functional programming your focus is on defining functions with particular emphasis on their input and output. F# is an impure functional language where data is immutable by default, though you can still define mutable data or cause other side effects in your functions. -

Run-Time Type Information and Incremental Loading in C++
Run-time Type Information and Incremental Loading in C++ Murali Vemulapati Sriram Duvvuru Amar Gupta WP #3772 September 1993 PROFIT #93-11 Productivity From Information Technology "PROFIT" Research Initiative Sloan School of Management Massachusetts Institute of Technology Cambridge, MA 02139 USA (617)253-8584 Fax: (617)258-7579 Copyright Massachusetts Institute of Technology 1993. The research described herein has been supported (in whole or in part) by the Productivity From Information Technology (PROFIT) Research Initiative at MIT. This copy is for the exclusive use of PROFIT sponsor firms. Productivity From Information Technology (PROFIT) The Productivity From Information Technology (PROFIT) Initiative was established on October 23, 1992 by MIT President Charles Vest and Provost Mark Wrighton "to study the use of information technology in both the private and public sectors and to enhance productivity in areas ranging from finance to transportation, and from manufacturing to telecommunications." At the time of its inception, PROFIT took over the Composite Information Systems Laboratory and Handwritten Character Recognition Laboratory. These two laboratories are now involved in research re- lated to context mediation and imaging respectively. LABORATORY FOR ELEC RONICS A CENTERCFORENTER COORDINATION LABORATORY ) INFORMATION S RESEARCH RESE CH E53-310, MITAL"Room Cambridge, MA 02M142-1247 Tel: (617) 253-8584 E-Mail: [email protected] Run-time Type Information and Incremental Loading in C++ September 13, 1993 Abstract We present the design and implementation strategy for an integrated programming environment which facilitates specification, implementation and execution of persistent C++ programs. Our system is implemented in E, a persistent programming language based on C++. The environment provides type identity and type persistence, i.e., each user-defined class has a unique identity and persistence across compilations. -

Kodak Color Control Patches Kodak Gray
Kodak Color Control Patches 0 - - _,...,...,. Blue Green Yellow Red White 3/Color . Black Kodak Gray Scale A 1 2 a 4 s -- - --- - -- - -- - -- -- - A Study of Compile-time Metaobject Protocol :J/1\'-(Jt.-S~..)(:$/;:t::;i':_;·I'i f-.· 7 •[:]f-. :::JJl. (:~9 ~~Jf'?E By Shigeru Chiba chiba~is.s.u-tokyo.ac.jp November 1996 A Dissertation Submitted to Department of Information Science Graduate School of Science The Un iversity of Tokyo In Partial Fulfillment of the Requirements For the Degree of Doctor of Science. Copyright @1996 by Shigeru Chiba. All Rights Reserved. - - - ---- - ~-- -- -~ - - - ii A Metaobject Protocol for Enabling Better C++ Libraries Shigeru Chiba Department of Information Science The University of Tokyo chiba~is.s.u-tokyo.ac.jp Copyrighl @ 1996 by Shi geru Chiba. All Ri ghts Reserved. iii iv Abstract C++ cannot be used to implement control/data abstractions as a library if their implementations require specialized code for each user code. This problem limits programmers to write libraries in two ways: it makes some kinds of useful abstractions that inherently require such facilities impossi ble to implement, and it makes other abstractions difficult to implement efficiently. T he OpenC++ MOP addresses this problem by providing li braries the ability to pre-process a program in a context-sensitive and non-local way. That is, libraries can instantiate specialized code depending on how the library is used and, if needed, substitute it for the original user code. The basic protocol structure of the Open C++ MOP is based on that of the CLOS MOP, but the Open C++ MOP runs metaobjects only at compile time. -

1 Simply-Typed Lambda Calculus
CS 4110 – Programming Languages and Logics Lecture #18: Simply Typed λ-calculus A type is a collection of computational entities that share some common property. For example, the type int represents all expressions that evaluate to an integer, and the type int ! int represents all functions from integers to integers. The Pascal subrange type [1..100] represents all integers between 1 and 100. You can see types as a static approximation of the dynamic behaviors of terms and programs. Type systems are a lightweight formal method for reasoning about behavior of a program. Uses of type systems include: naming and organizing useful concepts; providing information (to the compiler or programmer) about data manipulated by a program; and ensuring that the run-time behavior of programs meet certain criteria. In this lecture, we’ll consider a type system for the lambda calculus that ensures that values are used correctly; for example, that a program never tries to add an integer to a function. The resulting language (lambda calculus plus the type system) is called the simply-typed lambda calculus (STLC). 1 Simply-typed lambda calculus The syntax of the simply-typed lambda calculus is similar to that of untyped lambda calculus, with the exception of abstractions. Since abstractions define functions tht take an argument, in the simply-typed lambda calculus, we explicitly state what the type of the argument is. That is, in an abstraction λx : τ: e, the τ is the expected type of the argument. The syntax of the simply-typed lambda calculus is as follows. It includes integer literals n, addition e1 + e2, and the unit value ¹º. -

Query Rewriting Using Views in a Typed Mediator
Язык СИНТЕЗ как ядро канонической информационной модели Л. А. Калиниченко ([email protected]) C. А. Ступников ([email protected]) Lecture outline Objectives of the language Frame language: semi-structured capabilities Type system of SYNTHESIS Classes and metaclasses Assertions Processes, workflows Formulae facilities of the language 2 History of the language . Preliminary draft version published in 1991 . First version published in 1993 . English version prepared in 1995 and extended in 1997 . Current version in English published in 2007 3 The SYNTHESIS is a multipurpose language The language is oriented on the following basic kinds of application: . serving as a kernel of the canonical information model; . providing facilities for unifying representation of heterogeneous information models of different kinds (of data, services, processes, ontologies); . providing sufficient modeling facilities for formalized definitions of mediators for various subject domains; . supporting mediation-based design of information systems; . providing modeling facilities for mediator and resource specifications for the mediation architecture; . serving for semantic reconciliation of the mediator and resource specifications to form compositions of resources refining mediator specifications; . serving as an interface for users during problem formulation and solving in various applications 4 Mediation orientation . Two different approaches to the problem of integrated representation of multiple information resources for an IS are distinguished: 1. moving from resources to problems (resource driven approach) 2. moving from an application to resources (application driven approach) The SYNTHESIS language is oriented on support of application-driven approach for mediation-based IS development. The mediator's layer is introduced to provide the users with the metainformation uniformly characterizing subject definitions in the canonical information model – providing application domain conceptual schema . -
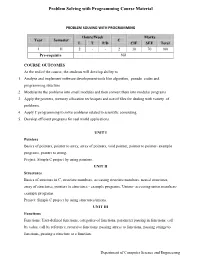
Problem Solving with Programming Course Material
Problem Solving with Programming Course Material PROBLEM SOLVING WITH PROGRAMMING Hours/Week Marks Year Semester C L T P/D CIE SEE Total I II 2 - - 2 30 70 100 Pre-requisite Nil COURSE OUTCOMES At the end of the course, the students will develop ability to 1. Analyze and implement software development tools like algorithm, pseudo codes and programming structure. 2. Modularize the problems into small modules and then convert them into modular programs 3. Apply the pointers, memory allocation techniques and use of files for dealing with variety of problems. 4. Apply C programming to solve problems related to scientific computing. 5. Develop efficient programs for real world applications. UNIT I Pointers Basics of pointers, pointer to array, array of pointers, void pointer, pointer to pointer- example programs, pointer to string. Project: Simple C project by using pointers. UNIT II Structures Basics of structure in C, structure members, accessing structure members, nested structures, array of structures, pointers to structures - example programs, Unions- accessing union members- example programs. Project: Simple C project by using structures/unions. UNIT III Functions Functions: User-defined functions, categories of functions, parameter passing in functions: call by value, call by reference, recursive functions. passing arrays to functions, passing strings to functions, passing a structure to a function. Department of Computer Science and Engineering Problem Solving with Programming Course Material Project: Simple C project by using functions. UNIT IV File Management Data Files, opening and closing a data file, creating a data file, processing a data file, unformatted data files. Project: Simple C project by using files. -

Solutions to Exercises
Solutions to Exercises Solutions for Chapter 2 Exercise 2.1 Provide a function to check if a character is alphanumeric, that is lower case, upper case or numeric. One solution is to follow the same approach as in the function isupper for each of the three possibilities and link them with the special operator \/ : isalpha c = (c >= ’A’ & c <= ’Z’) \/ (c >= ’a’ & c <= ’z’) \/ (c >= ’0’ & c <= ’9’) An second approach is to use continued relations: isalpha c = (’A’ <= c <= ’Z’) \/ (’a’ <= c <= ’z’) \/ (’0’ <= c <= ’9’) A final approach is to define the functions isupper, islower and isdigit and combine them: isalpha c = (isupper c) \/ (islower c) \/ (isdigit c) This approach shows the advantage of reusing existing simple functions to build more complex functions. 268 Solutions to Exercises 269 Exercise 2.2 What happens in the following application and why? myfst (3, (4 div 0)) The function evaluates to 3, the potential divide by zero error is ignored because Miranda only evaluates as much of its parameter as it needs. Exercise 2.3 Define a function dup which takes a single element of any type and returns a tuple with the element duplicated. The answer is just a direct translation of the specification into Miranda: dup :: * -> (*,*) dup x = (x, x) Exercise 2.4 Modify the function solomonGrundy so that Thursday and Friday may be treated with special significance. The pattern matching version is easily modified; all that is needed is to insert the extra cases somewhere before the default pattern: solomonGrundy "Monday" = "Born" solomonGrundy "Thursday" = "Ill" solomonGrundy "Friday" = "Worse" solomonGrundy "Sunday" = "Buried" solomonGrundy anyday = "Did something else" By contrast, a guarded conditional version is rather messy: solomonGrundy day = "Born", if day = "Monday" = "Ill", if day = "Thursday" = "Worse", if day = "Friday" = "Buried", if day = "Sunday" = "Did something else", otherwise Exercise 2.5 Define a function intmax which takes a number pair and returns the greater of its two components. -

The Gaudi Reflection Tool Crash Course
SDLT Single File Template 1 4. Sept. 2001 Version/Issue: 2/1 European Laboratory for Particle Physics Laboratoire Européen pour la Physique des Particules CH-1211 Genève 23 - Suisse The Gaudi Reflection Tool Crash Course Document Version: 1 Document Date: 4. Sept. 2001 Document Status: Draft Document Author: Stefan Roiser Abstract 1 Introduction The Gaudi Reflection Tool is a model for the metarepresentation of C++ classes. This model has to be filled with the corresponding information to each class that shall be represented through this model. Ideally the writing of this information and filling of the model will be done during the creation of the real classes. Once the model is filled with information a pointer to the real class will be enough to enter this model and retrieve information about the real class. If there are any relations to other classes, and the information about these corresponding classes is also part of the metamodel one can jump to these classes and also retrieve information about them. So an introspection of C++ classes from an external point of view can be realised quite easily. 2 The Meta Model The struture of the Gaudi Reflection Model is divided into four parts. These four parts are represented by four C++-classes. The corepart is the class called MetaClass. Within this class everything relevant to the real object will be stored. This information includes the name, a description, the author, the list of methods, members and constructors of this class etc. This class is also the entrypoint to the MetaModel. Using the MetaClass function forName and the Template page 1 SDLT Single File Template 2 The Meta Model Version/Issue: 2/1 string of the type of the real class as an argument, a pointer to the corresponding instance of MetaClass will be returned. -

Static Reflection
N3996- Static reflection Document number: N3996 Date: 2014-05-26 Project: Programming Language C++, SG7, Reflection Reply-to: Mat´uˇsChochl´ık([email protected]) Static reflection How to read this document The first two sections are devoted to the introduction to reflection and reflective programming, they contain some motivational examples and some experiences with usage of a library-based reflection utility. These can be skipped if you are knowledgeable about reflection. Section3 contains the rationale for the design decisions. The most important part is the technical specification in section4, the impact on the standard is discussed in section5, the issues that need to be resolved are listed in section7, and section6 mentions some implementation hints. Contents 1. Introduction4 2. Motivation and Scope6 2.1. Usefullness of reflection............................6 2.2. Motivational examples.............................7 2.2.1. Factory generator............................7 3. Design Decisions 11 3.1. Desired features................................. 11 3.2. Layered approach and extensibility...................... 11 3.2.1. Basic metaobjects........................... 12 3.2.2. Mirror.................................. 12 3.2.3. Puddle.................................. 12 3.2.4. Rubber................................. 13 3.2.5. Lagoon................................. 13 3.3. Class generators................................ 14 3.4. Compile-time vs. Run-time reflection..................... 16 4. Technical Specifications 16 4.1. Metaobject Concepts............................. -

Polymorphic Subtyping in O'haskell
Science of Computer Programming 43 (2002) 93–127 www.elsevier.com/locate/scico Polymorphic subtyping in O’Haskell Johan Nordlander Department of Computer Science and Engineering, Oregon Graduate Institute of Science and Technology, 20000 NW Walker Road, Beaverton, OR 97006, USA Abstract O’Haskell is a programming language derived from Haskell by the addition of concurrent reactive objects and subtyping. Because Haskell already encompasses an advanced type system with polymorphism and overloading, the type system of O’Haskell is much richer than what is the norm in almost any widespread object-oriented or functional language. Yet, there is strong evidence that O’Haskell is not a complex language to use, and that both Java and Haskell pro- grammers can easily ÿnd their way with its polymorphic subtyping system. This paper describes the type system of O’Haskell both formally and from a programmer’s point of view; the latter task is accomplished with the aid of an illustrative, real-world programming example: a strongly typed interface to the graphical toolkit Tk. c 2002 Elsevier Science B.V. All rights reserved. Keywords: Type inference; Subtyping; Polymorphism; Haskell; Graphical toolkit 1. Introduction The programming language O’Haskell is the result of a ÿnely tuned combination of ideas and concepts from functional, object-oriented, and concurrent programming, that has its origin in the purely functional language Haskell [36]. The name O’Haskell is a tribute to this parentage, where the O should be read as an indication of Objects,as well as a reactive breach with the tradition that views Input as an active operation on par with Output.