ATLAS HL-LHC Computing Conceptual Design Report
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ferranti Atlas 1 & 2: List of References
Version 2, January 2012 F5X5 Ferranti Atlas 1 & 2: List of References A. Documents in the ICL Archive at the Science Museum, London and Wroughton. Numbers in parentheses are the Archive references. 1. ICT ATLAS 1 Computer: Programming Language for ATLAS Basic Language (ABL), 1961. (38/46) 2. The Atlas Drum System, provisional description. (38/60-1) 3. The Atlas Core Store & Working Store, provisional description. (38/60-2) 4. The Atlas 1 Computer System Operator’s Manual Part 1 - Central Machine and Supervisor. (38/60-3) 5. The Atlas 1 Computer System Operator’s Manual Part 2 - Peripheral Equipments. (38/60-4) 6. Features and Facilities of Atlas Basic Language - ABL for the Atlas 1 System. (38/60-5) 7. Preparing a Complete Program for Atlas 1. (38/60-6) 8. The Atlas Supervisor, by T. Kilburn, R.B. Payne, and D.J. Howarth (reprinted from "Computers - Key to Total Systems Control"). (38/60-7). See also ref. 61(a) below. 9. Printout from Atlas at Manchester University, 28.3.67 at 19.18 hrs. (38/60-8) 10. Atlas Computer - small brochure (No 1 in a series of Computer System Profiles), 1962. (38/60-13 and 38/72-1) 11. An Appraisal of the Atlas Supervisor D.Morris, F.H.Sumner, and M.T.Wyld, 1967. (38/61-1). See also ref. 61(b) below. 12. Atlas 1 Customer’s Installation Responsibilities, 1963. (38/61-2) 13. ICT Atlas General Survey Program, 1965. (38/61-3) 14. Ferranti Atlas Sales brochure, 1962. (38/61-4) 15. Atlas - Technical description: 6 typewritten foolscap sheets, 1962. -

Tom Kilburn: a Tale of Five Computers
Tom Kilburn: A tale of five computers One of the pre-eminent figures in the early history of computer design was Tom Kilburn. Over the course of some thirty years, he made significant contributions to the development of five important computers. Although a natural team leader possessed of a somewhat dominating personality, who inspired in those who worked closely with him great loyalty and affection, Kilburn was, on casual acquaintance, a self- contained man who chose his words with care. As F.C. Williams put it “What you must always remember is that Tom is a Yorkshireman.”1 Early Days Tom Kilburn was born on the 11th August 1921, near Dewsbury in West Yorkshire, England. His father, John William Kilburn, was a statistical clerk who rose to become a company secretary.1 Tom had a somewhat specialized education at Wheelwright Grammar School having been permitted by his headmaster to study almost nothing else from around the age of 14. It was hardly surprising therefore he emerged from school as something of a mathematical specialist. In 1940, Kilburn went up to Sidney Sussex College, Cambridge, with State, Dewsbury Major, and Minor Open Scholarships. Wartime courses at Cambridge were somewhat truncated and in 1942, Kilburn graduated with First Class Honors in Part I of the Mathematical Tripos and in the preliminary examination for Part II. During the Second World War, many Cambridge mathematics dons were absent from the university serving at Bletchley Park and elsewhere. In spite of this, there remained a lively mathematical community in which Kilburn played a full part part. -

Martin Marietta Corporation Denver Division Box 179, Denver, Colorado
,I \~1'I I7- r \ ?@A r 'h .. ,l J I V MC R-70-327 J DEVELOPMENT OF A KSC TEST AND FLIGHT- ENGINEERING ORIENTED COMPUTER LANGUAGE - PHASE I REPORT I , . C. W. Case E. L. Kinney J. Gyure zy 18 M Martin Marietta Corporation Denver Division Box 179, Denver, Colorado. 80201 August 1970 Interim Reportfor Period July-August 1970 Prepared for National Aeronautics and Space Administration John F. Kennedy Space Center .. N72-15169 ;(NASA-CH-1 2 5 2 6 0 ) DEVgLOPSPNN'I OF A KSC TEST AND ELIGHT ENGINEERING OlIENTLD COMPUTEA Jul. - LANGUAGE, PHASE 1 Interim Report, Unclas 1970 C.W. Case, et al (ilartin Auq. G3/08 12744 1970 7. p CSCL 09B \Parietta Corp.) .Auq. I Reproduced by NATIONAL TECHNICAL INFORMATION SERVICE U S Department of Commerce Springfield VA 22151 .- b; s6l o 9 N 0 T I C E THIS DOCUMENT HAS BEEN REPRODUCED FROM THE BEST COPY FURNISHED US BY THE SPONSOR- ING AGENCY. ALTHOUGH IT IS RECOGNIZED THAT CERTAIN PORTIONS ARE ILLEGIBLE, IT IS BEING RELEASED IN THE INTEREST OF MAK- ING AVAILABLE AS MUCH INFORMATION AS POSSIBLE. PREFACE This report contains the results of the Phase I effort of the Development of a KSC Test and Flight Engineer Oriented Computer Language Study. This'Phase I effort was directed at the examination of existing related languages and their appli- cations./ , K * -1W. Three languages, ATOLL, ATLAS and CLASP were examined in detail and their characteristics are documented in a language characteristics table. A general review of several other test oriented languages was undertaken. -

Dynamic Storage Allocation in the Atlas Computer, Including an Automatic Use of a Backing Store
The output of AMCAP consists of binary machine code lines gramming l~esearch Group of the Astro-Electronics Divi- interspersed with modification lines. The modification lines sion of Radio Corporation of America for their support are binary encoded and represent a compromise between and in particular to Roy Heistand for his contributions to the expense of storing and handling a large code and the the design and implementation of A~cAP. expense of interpretively performing the modifications. Parts of the ACSI-MATIC Programming System in- REFERENCES cluding parts of AMCaP have been coded for the 1. GUP,.K, H., MINKER, J. The design and simulation of an in- MOBiDIC-A and Sylvania 9400 computers; some of the code formation processing system. J. ACM 8, 2 (Apr. 1961), 260. has been debugged on the MOBiDIc-A. It is expected that 2. MILLER, a., MINKER, J., REED, W. G., SI-IINDLE, W. E. A an initial system will be operating by the end of summer. multi-level file structure for information processing. Proc. Acknowledgment is given to the members of the Pro- Western Joint Comput. Conf., Apr. 1960. Dynamic Storage Allocation in the Atlas Computer, Including an Automatic Use of a Backing Store John Fotheringham Ferranti Electric, Inc., Plainview, New York 1. Introduction characters within a word for certain special functions, and the leading digit of these three is also used for identifying This paper is concerned with the method of address in- the half-word operand for 24-bit functions such as index terpretation in the Atlas computer. The Atlas has been register operations. -

Chilton Atlas Hardware at the National Museums Scotland
Chilton Atlas hardware at the National Museums Scotland. Simon Lavington. November 2013. [email protected] Contents. Summary 2 1. Origins: Atlas in its historical context. 3 2. Atlas in the market-place. 4 3. Relative performance, then and now. 5 4. The Atlas Computer Laboratory at Chilton, Berkshire. 6 5. Technical details of the Chilton Atlas. 9 6. Physical details of equipment layout at Chilton. 10 7. The Atlas artefacts in store at the National Museums Scotland. 14 8. Condition of the units in the NMS Granton store. 19 9. The historical significance of Atlas. 21 Appendix A: Surviving Atlas hardware at other museums. 23 Appendix B: Bibliography and other sources of Atlas information 27 Acknowledgements. Several former Atlas people have helped with technical details. Particular mention should be made of Bob Hopgood, Ted Doubtfire and Yao Chen, all of whom worked on the Chilton Atlas. Picture credits to copyright holders. National Museums Scotland Figures 1(a) and 4. Museum of Science & Industry, Manchester Figure 2. STFC Rutherford Appleton Laboratory Figures 3, 5, 6, 7 and 8 Simon Lavington Figures 1(b), 9 to 16(a), 17(a), Table A2 Science Museum, London Figure 16(b), Table A1 D B G Edwards Figure 17 (b) Computer History Museum, California Table A3. 1 Chilton Atlas hardware at the National Museums Scotland. Summary. In 1962 the British-designed Ferranti Atlas supercomputer was, briefly, the world’s most powerful computing system. In 1973 Dr A G Thomson, Keeper of the Department of Technology at the Royal Scottish Museum, asked the Science Research Council to donate some representative sections of a redundant Atlas for preservation and eventual display. -

A Guide to Circuit Packages Used in the Ferranti Atlas
A guide to circuit packages used in the Ferranti Atlas. Simon Lavington. June 2015. 1. Introduction. The intention is to give a guide to the function and type-numbers of all the printed-circuit packages used in the Ferranti Atlas computer, which was first operational in 1962. The information has been collected from various sources, principally from references [1] to [4]. (A list of references is given at the end). The data in this paper is, as yet, incomplete. This is because it has not yet proved possible to locate copies of all the original Ferranti documents that defined every package-type. The search for more information is on-going. To quote ref [1]: “Atlas is a fully-transistorised computer of package construction, a total of 3,955 packages used in the standard Atlas”. This figure was estimated in April 1961, before the first production Atlas was fully assembled. The package-count as calculated in November 1962 [ref. 2] was 5660. In truth, the total count varied per installation. The smallest of the three Atlas 1 installations was estimated [ref. 6] to have a total of 5,172 packages, which probably included the two special on-line peripherals (an X-ray Diffractometer and the A/D/A Speech Converter). The majority of the packages (also called printed-circuit boards , abbreviated pcbs ) used in the central processor carried circuits of only seven basic types. Each of the seven basic types then had several variations concerned with logic gating, fan-out, etc. The seven basic types are listed in ref. [1] as: a. -

The Atlas Story
The Atlas story. Simon Lavington. Second edition, 6 th December 2012. Contents. Introduction page 1 Birth pains 1 Atlas at Manchester 1 Ferranti and the market place 5 Timeline 6 Technical innovations: facts and figures 6 The London Atlas 8 The Chilton Atlas 9 The Atlas 2 developments 11 Titan at Cambridge 13 Atlas 2 at AWRE Aldermaston 13 Atlas 2 at the CAD centre 13 More technical details of Atlas installations 15 Physical layout 17 Organisation of the Atlas storage hierarchy 17 Format of an Atlas instruction. 19 Guide to the Atlas Supervisor 20 People and places 21 More information 22 Originally produced for the Atlas Symposium held on 5 th December 2012 in the School of Computer Science, Kilburn Building, University of Manchester. It is a pleasure to acknowledge the help given by many former Atlas pioneers in the writing of this brochure. Comments on the text are welcomed and should be sent to Simon Lavington : [email protected] Picture credits to copyright holders. Computer Laboratory, University of Cambridge: Figure 9 Graham Penning: Figure 10 Simon Lavington: Figure 3 Iain MacCallum: Front cover Museum of Science & Industry, Manchester Figures 1, 2, 4, 5, 6 STFC Rutherford Appleton Laboratory: Figures 7a, 7b, 8 (On 5 th December the original printed version of this document had a cover design based on photographs of the Atlas at Manchester University in 1963). i By the end of 1955 there were less than 16 production digital computers in use in the UK. They were of five British designs, from five different companies, and were single-user systems with practically no systems software. -

ATLAS Software Installation on Supercomputers
ATLAS Software Installation on Supercomputers Alexander Undrus1 on behalf of the ATLAS Collaboration 1Brookhaven National Laboratory, Upton, NY 11973 Abstract. PowerPC and high-performance computers (HPC) are important resources for computing in the ATLAS experiment. The future LHC data processing will require more resources than Grid computing, currently using approximately 100,000 cores at well over 100 sites, can provide. Supercomputers are extremely powerful as they utilize hundreds of thousands of CPUs joined together. However, their architectures have different instruction sets. ATLAS binary software distributions for x86 chipsets do not fit these architectures, as emulation of these chipsets results in huge performance loss. This paper describes the methodology of ATLAS software installation from source code on supercomputers. The installation procedure includes downloading the ATLAS simulation release code with 0.7 million C++ and Python lines as well as the source code of more than 50 external packages, such as ROOT and Geant4, followed by compilation, and rigorous unit and integration testing. The presentation reports the application of this procedure at Titan HPC and Summit PowerPC at Oak Ridge Computing Facility (OLCF). © 2018 CERN for the benefit of the ATLAS Collaboration. Reproduction of this article or parts of it is allowed as specified in the CC-BY-4.0 license. 1 Introduction ATLAS (A Toroidal LHC Apparatus) [1] is one of the largest collaborative efforts ever ATL-SOFT-PROC-2018-007 19 October 2018 attempted in the physical sciences. Many important findings, such as Higgs discovery, were made and the physics research program is planned for the next 20 years. The new phase of LHC, named as High Luminosity LHC, aims to deliver an integrated luminosity of about 3000 fb-1 over 10 -12 years of operation [2]. -
DEEPHOLE DRILLING in the Water Well, Oil & Gas, Geothermal and Exploration Markets
DEEPHOLE DRILLING In the water well, oil & gas, geothermal and exploration markets FIRST EDITION 2015 THE ATLAS COPCO ADVANTAGE Atlas Copco’s Predator is the epitome of efficiency, safety and mobility. The API 4F licensed Predator features 220,000 lbs of hookload on an extremely mobile platform. Greater automation and hands-free pipe handling contribute to a safer working environment. www.atlascopco.com/predator Contents Foreword 2 Foreword by Jaco van der Merwe Talking technically 3 Evolution of well drilling 7 Deephole directional drilling 9 State-of-the-art well drilling technology 13 Knowing when to use DTH or rotary drilling technique 19 Tool selection 21 Ergonomics and safety 23 Pipe loader increases safety 25 Predator™ drilling system Case studies 27 Going after the hard stuff 29 XC is for ‘Extra Capabilities’ 31 Nature’s building blocks 33 Oil and gas drillers turn to ‘mixed fleet’ approach 35 Tapping into a hot market 37 Carizzo Sands–too loose to walk on but not to drill 39 Clean water for Panama 41 The antidote for arsenic 43 Best bit for the job 45 Diamonds in the rough 47 Draining saturated ground 49 Core drilling with an Atlas Copco TH60DH 51 The Water Below 55 Exploring Chile’s Norte Grande region with Atlas Copco’s RD10+ 57 Designing a versatile water well rig 61 Star of India Product specifications 64 Well drilling rigs 82 Secoroc Klaw Bits 88 Secoroc Rock Drilling Tools 122 DRILLCare 124 Service 128 Where to find us For latest updates contact your local Atlas Copco Customer Center or refer to wwdrills or www.atlascopco.com/oilandgas Produced by: Atlas Copco Drilling Solutions LLC, PO Box 462288, Garland, TX 75046, USA, Phone +1 972 496 7400. -

English Electric KDF9 Computers
a very hgh speed data processing system s5 k 0 'for Commerce, Industry, Science 'ENGLISH ELECTRIC' :.I The Lineage On the pages that follow is described the 'English Electric ' KDF9 Data Processing system-one of the most advanced electronic digital systems yet devised. KDF9 is the outcome of many years' experience accumulated by 'English Electric ' as designers, manufacturers, and users of computers, the Company being one of the pioneers in the field in Britain. In the early post-war years 'English Electric ' co-operated with the National Physical Laboratory in the development of the " ACE " Pilot Model, one of the first electronic digital computers made in the United Kingdom. The Company then proceeded with the development and production of a fully engineered computer which was to set new standards of speed and capacity. Great interest was shown in this undertaking and, literally at the drawing board stage, the Company was asked to build one each for the National Physical Laboratory and the Royal Aircraft Establishment, Farnborough. The new machine, which was named " DEUCE," was an immediate success and soon became widely known as the most powerful and advanced computer of its type. Successive marks were developed to meet the demand for increased speed and storage, all of which give the utmost satisfaction to their users. As the use of computers became more widely known and appreciated there came increased demands for computers of much greater speed and capacity, and 'English Electric ' addressed themselves to the task of meeting these demands. A computer manufacturing division was established at Kidsgrove, North Staffordshire, and is now known as the Data Processing and Control Systems Division. -
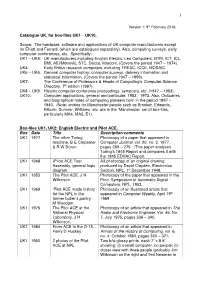
The Hardware, Software and Applications of UK Computer Manufacturers Except for Elliott and Ferranti (Which Are Catalogued Separately)
1 Version 1: 9 th February 2016. Catalogue UK, for box-files UK1 – UK10. Scope: The hardware, software and applications of UK computer manufacturers except for Elliott and Ferranti (which are catalogued separately). Also, computing surveys, early computer conferences, etc. Specifically: UK1 – UK4: UK manufacturers including English Electric, Leo Computers, BTM, ICT, ICL, EMI, AEI/Metrovic, STC, Decca, Marconi. (Covers the period 1947 – 1974). UK4: Early British research computers, including TREAC, ICCE, MOSAIC. UK5 – UK6: General computer history: computer surveys, delivery information and statistical Information. (Covers the period 1947 – 1999). UK7: The Conference of Professors & Heads of Computing’s Computer Science Directory , 7 th edition (1997). UK8 – UK9: Historic computer conference proceedings, symposia, etc. (1947 – 1953). UK10: Computer applications, general and particular, 1953 - 1973. Also, Obituaries and biographical notes of computing pioneers born in the period 1897 – 1940. (Note: entries for Manchester people such as Brooker, Edwards, Kilburn, Sumner, Williams, etc. are in the ‘Manchester’ set of box-files, particularly MA4, MA5, E1). Box-files UK1, UK2: English Electric and Pilot ACE. Box Date Title Description/comments UK1 1977 The other Turing Photocopy of a paper that appeared in machine. B E Carpenter Computer Journal, vol. 20, no. 3, 1977, & R W Doron. pages 269 – 279. (This paper analyses Turing’s 1945 Report and compares it with the 1945 EDVAC Report. UK1 1948 (Pilot) ACE Test A3 photocopy of an original drawing Assembly, general logic produced by David Clayden, Electronics diagram. Section, NPL, 1 st December 1948. UK1 1953 The Pilot ACE. J H Photocopy of the paper that appeared in the Wilkinson. -

Scientific Computing in the Cavendish Laboratory and the Pioneering
Department: Head Editor: Name, xxxx@email Scientific Computing in the Cavendish Laboratory and the pioneering women Computors C. S. Leedham Institute of Astronomy, University of Cambridge; Selwyn College, University of Cambridge V. L. Allan Cavendish Laboratory, University of Cambridge Abstract—The use of computers and the role of women in radio astronomy and X-ray crystallography research at the Cavendish Laboratory between 1949 and 1975 have been investigated. We recorded examples of when computers were used, what they were used for and who used them from hundreds of papers published during these years. The use of the EDSAC, EDSAC 2 and TITAN computers was found to increase considerably over this time-scale and they were used for a diverse range of applications. The majority of references to computer operators and programmers referred to women, 57% for astronomy and 62% for crystallography, in contrast to a very small proportion, 4% and 13% respectively, of female authors of papers. This article is submitted to IEEE. © 2021 puting and other disciplines. This was the case IEEE. Personal use of this material is permitted. in the University of Cambridge, with advances in Permission from IEEE must be obtained for all computing made by the Mathematical Laboratory, arXiv:2106.00365v1 [cs.CY] 1 Jun 2021 other uses, in any current or future media, in- and scientific discoveries leading to Nobel Prizes cluding reprinting/republishing this material for for members of the Cavendish Physical Labo- advertising or promotional purposes, creating new ratory [1][2]. Many of the advances in physics collective works, for resale or redistribution to depended on the use of the computers of the servers or lists, or reuse of any copyrighted com- Mathematical Laboratory [3].