Data Exploration in Phylogenetic Inference: Scientific, Heuristic, Or Neither
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Phylogenetic Trees and Cladograms Are Graphical Representations (Models) of Evolutionary History That Can Be Tested
AP Biology Lab/Cladograms and Phylogenetic Trees Name _______________________________ Relationship to the AP Biology Curriculum Framework Big Idea 1: The process of evolution drives the diversity and unity of life. Essential knowledge 1.B.2: Phylogenetic trees and cladograms are graphical representations (models) of evolutionary history that can be tested. Learning Objectives: LO 1.17 The student is able to pose scientific questions about a group of organisms whose relatedness is described by a phylogenetic tree or cladogram in order to (1) identify shared characteristics, (2) make inferences about the evolutionary history of the group, and (3) identify character data that could extend or improve the phylogenetic tree. LO 1.18 The student is able to evaluate evidence provided by a data set in conjunction with a phylogenetic tree or a simple cladogram to determine evolutionary history and speciation. LO 1.19 The student is able create a phylogenetic tree or simple cladogram that correctly represents evolutionary history and speciation from a provided data set. [Introduction] Cladistics is the study of evolutionary classification. Cladograms show evolutionary relationships among organisms. Comparative morphology investigates characteristics for homology and analogy to determine which organisms share a recent common ancestor. A cladogram will begin by grouping organisms based on a characteristics displayed by ALL the members of the group. Subsequently, the larger group will contain increasingly smaller groups that share the traits of the groups before them. However, they also exhibit distinct changes as the new species evolve. Further, molecular evidence from genes which rarely mutate can provide molecular clocks that tell us how long ago organisms diverged, unlocking the secrets of organisms that may have similar convergent morphology but do not share a recent common ancestor. -

An Introduction to Phylogenetic Analysis
This article reprinted from: Kosinski, R.J. 2006. An introduction to phylogenetic analysis. Pages 57-106, in Tested Studies for Laboratory Teaching, Volume 27 (M.A. O'Donnell, Editor). Proceedings of the 27th Workshop/Conference of the Association for Biology Laboratory Education (ABLE), 383 pages. Compilation copyright © 2006 by the Association for Biology Laboratory Education (ABLE) ISBN 1-890444-09-X All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of the copyright owner. Use solely at one’s own institution with no intent for profit is excluded from the preceding copyright restriction, unless otherwise noted on the copyright notice of the individual chapter in this volume. Proper credit to this publication must be included in your laboratory outline for each use; a sample citation is given above. Upon obtaining permission or with the “sole use at one’s own institution” exclusion, ABLE strongly encourages individuals to use the exercises in this proceedings volume in their teaching program. Although the laboratory exercises in this proceedings volume have been tested and due consideration has been given to safety, individuals performing these exercises must assume all responsibilities for risk. The Association for Biology Laboratory Education (ABLE) disclaims any liability with regards to safety in connection with the use of the exercises in this volume. The focus of ABLE is to improve the undergraduate biology laboratory experience by promoting the development and dissemination of interesting, innovative, and reliable laboratory exercises. -

Interpreting Cladograms Notes
Interpreting Cladograms Notes INTERPRETING CLADOGRAMS BIG IDEA: PHYLOGENIES DEPICT ANCESTOR AND DESCENDENT RELATIONSHIPS AMONG ORGANISMS BASED ON HOMOLOGY THESE EVOLUTIONARY RELATIONSHIPS ARE REPRESENTED BY DIAGRAMS CALLED CLADOGRAMS (BRANCHING DIAGRAMS THAT ORGANIZE RELATIONSHIPS) What is a Cladogram ● A diagram which shows ● Is not an evolutionary ___________ among tree, ___________show organisms. how ancestors are related ● Lines branching off other to descendants or how lines. The lines can be much they have changed traced back to where they branch off. These branching off points represent a hypothetical ancestor. Parts of a Cladogram Reading Cladograms ● Read like a family tree: show ________of shared ancestry between lineages. • When an ancestral lineage______: speciation is indicated due to the “arrival” of some new trait. Each lineage has unique ____to itself alone and traits that are shared with other lineages. each lineage has _______that are unique to that lineage and ancestors that are shared with other lineages — common ancestors. Quick Question #1 ●What is a_________? ● A group that includes a common ancestor and all the descendants (living and extinct) of that ancestor. Reading Cladogram: Identifying Clades ● Using a cladogram, it is easy to tell if a group of lineages forms a clade. ● Imagine clipping a single branch off the phylogeny ● all of the organisms on that pruned branch make up a clade Quick Question #2 ● Looking at the image to the right: ● Is the green box a clade? ● The blue? ● The pink? ● The orange? Reading Cladograms: Clades ● Clades are nested within one another ● they form a nested hierarchy. ● A clade may include many thousands of species or just a few. -

Conceptual Issues in Phylogeny, Taxonomy, and Nomenclature
Contributions to Zoology, 66 (1) 3-41 (1996) SPB Academic Publishing bv, Amsterdam Conceptual issues in phylogeny, taxonomy, and nomenclature Alexandr P. Rasnitsyn Paleontological Institute, Russian Academy ofSciences, Profsoyuznaya Street 123, J17647 Moscow, Russia Keywords: Phylogeny, taxonomy, phenetics, cladistics, phylistics, principles of nomenclature, type concept, paleoentomology, Xyelidae (Vespida) Abstract On compare les trois approches taxonomiques principales développées jusqu’à présent, à savoir la phénétique, la cladis- tique et la phylistique (= systématique évolutionnaire). Ce Phylogenetic hypotheses are designed and tested (usually in dernier terme s’applique à une approche qui essaie de manière implicit form) on the basis ofa set ofpresumptions, that is, of à les traits fondamentaux de la taxonomic statements explicite représenter describing a certain order of things in nature. These traditionnelle en de leur et particulier son usage preuves ayant statements are to be accepted as such, no matter whatever source en même temps dans la similitude et dans les relations de evidence for them exists, but only in the absence ofreasonably parenté des taxons en question. L’approche phylistique pré- sound evidence pleading against them. A set ofthe most current sente certains avantages dans la recherche de réponses aux phylogenetic presumptions is discussed, and a factual example problèmes fondamentaux de la taxonomie. ofa practical realization of the approach is presented. L’auteur considère la nomenclature A is made of the three -
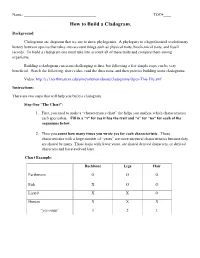
How to Build a Cladogram
Name: _____________________________________ TOC#____ How to Build a Cladogram. Background: Cladograms are diagrams that we use to show phylogenies. A phylogeny is a hypothesized evolutionary history between species that takes into account things such as physical traits, biochemical traits, and fossil records. To build a cladogram one must take into account all of these traits and compare them among organisms. Building a cladogram can seem challenging at first, but following a few simple steps can be very beneficial. Watch the following, short video, read the directions, and then practice building some cladograms. Video: http://ccl.northwestern.edu/simevolution/obonu/cladograms/Open-This-File.swf Instructions: There are two steps that will help you build a cladogram. Step One “The Chart”: 1. First, you need to make a “characteristics chart” the helps you analyze which characteristics each specieshas. Fill in a “x” for yes it has the trait and “o” for “no” for each of the organisms below. 2. Then you count how many times you wrote yes for each characteristic. Those characteristics with a large number of “yeses” are more ancestral characteristics because they are shared by many. Those traits with fewer yeses, are shared derived characters, or derived characters and have evolved later. Chart Example: Backbone Legs Hair Earthworm O O O Fish X O O Lizard X X O Human X X X “yes count” 3 2 1 Step Two “The Venn Diagram”: This step will help you to learn to build Cladograms, but once you figure it out, you may not always need to do this step. -

Phylogenetic Systematics As the Basis of Comparative Biology
SMITHSONIAN CONTRIBUTIONS TO BOTANY NUMBER 73 Phylogenetic Systematics as the Basis of Comparative Biology KA. Funk and Daniel R. Brooks SMITHSONIAN INSTITUTION PRESS Washington, D.C. 1990 ABSTRACT Funk, V.A. and Daniel R. Brooks. Phylogenetic Systematics as the Basis of Comparative Biology. Smithsonian Contributions to Botany, number 73, 45 pages, 102 figures, 12 tables, 199O.-Evolution is the unifying concept of biology. The study of evolution can be approached from a within-lineage (microevolution) or among-lineage (macroevolution) perspective. Phylogenetic systematics (cladistics) is the appropriate basis for all among-liieage studies in comparative biology. Phylogenetic systematics enhances studies in comparative biology in many ways. In the study of developmental constraints, the use of such phylogenies allows for the investigation of the possibility that ontogenetic changes (heterochrony) alone may be sufficient to explain the perceived magnitude of phenotypic change. Speciation via hybridization can be suggested, based on the character patterns of phylogenies. Phylogenetic systematics allows one to examine the potential of historical explanations for biogeographic patterns as well as modes of speciation. The historical components of coevolution, along with ecological and behavioral diversification, can be compared to the explanations of adaptation and natural selection. Because of the explanatory capabilities of phylogenetic systematics, studies in comparative biology that are not based on such phylogenies fail to reach their potential. OFFICIAL PUBLICATION DATE is handstamped in a limited number of initial copies and is recorded in the Institution's annual report, Srnithonhn Year. SERIES COVER DESIGN: Leaf clearing from the katsura tree Cercidiphyllumjaponicum Siebold and Zuccarini. Library of Cmgrcss Cataloging-in-PublicationDiaa Funk, V.A (Vicki A.), 1947- PhylogmttiC ryrtcmaticsas tk basis of canpamtive biology / V.A. -

Phylogenetic Systematics Using POY Final Final.Book
Dynamic Homology and Phylogenetic Systematics: A Unified Approach Using POY Ward Wheeler Lone Aagesen Division of Invertebrate Zoology Division of Invertebrate Zoology American Museum of Natural History American Museum of Natural History Claudia P. Arango Julián Faivovich Division of Invertebrate Zoology Division of Vertebrate Zoology American Museum of Natural History American Museum of Natural History Taran Grant Cyrille D’Haese Division of Vertebrate Zoology Département Systématique et Evolution American Museum of Natural History Museum National d'Histoire Naturelle Daniel Janies William Leo Smith Department of Biomedical Informatics Division of Vertebrate Zoology The Ohio State University American Museum of Natural History Andrés Varón Gonzalo Giribet Department of Computer Science Museum of Comparative Zoology City University of New York Department of Organismic & Evolutionary Biology Harvard University Published in cooperation with NASA Fundamental Space Biology, the U.S. Army Research Laboratory, and the U.S. Army Research Office Copyright 2006 by the American Museum of Natural History All rights reserved Printed in the United States of America Library of Congress Cataloging-in-Publication Data Dynamic homology and phylogenetic systematics : a unified approach using POY / Ward Wheeler ... [et al.]. p. cm. "Published in cooperation with NASA Fundamental Space Biology." Includes bibliographical references. ISBN 0-913424-58-7 (alk. paper) 1. Homology (Biology) 2. Animals--Classification. 3. Phylogeny. 4. POY. I. Wheeler, Ward. QH367.5.D96 -

Taxonomy and Classification Goals: Un Ders Tan D Traditi Onal and Hi Erarchi Cal Cl Assifi Cati Ons of Biodiversity, and What Information Classifications May Contain
Taxonomy and classification Goals: Un ders tan d tra ditional and hi erarchi cal cl assifi cati ons of biodiversity, and what information classifications may contain. Readings: 1. Chapter 1. Figure 1-1 from Pough et al. Taxonomy and classification (cont ’d) Some new words This is a cladogram. Each branching that are very poiiint is a nod dEhbhe. Each branch, starti ng important: at the node, is a clade. 9 Cladogram 9 Clade 9 Synapomorphy (Shared, derived character) 9 Monophyly; monophyletic 9 PhlParaphyly; parap hlihyletic 9 Polyphyly; polyphyletic Definitions of cladogram on the Web: A dichotomous phylogenetic tree that branches repeatedly, suggesting the classification of molecules or org anisms based on the time sequence in which evolutionary branches arise. xray.bmc.uu.se/~kenth/bioinfo/glossary.html A tree that depicts inferred historical branching relationships among entities. Unless otherwise stated, the depicted branch lengt hs in a cl ad ogram are arbi trary; onl y th e b ranchi ng ord er is significant. See phylogram. www.bcu.ubc.ca/~otto/EvolDisc/Glossary.html TAKE-HOME MESSAGE: Cladograms tell us about the his tory of the re lati onshi ps of organi sms. K ey word : Hi st ory. Historically, classification of organisms was mainlyypg a bookkeeping task. For this monumental job, Carrolus Linnaeus invented the s ystem of binomial nomenclature that we are all familiar with. (Did you know that his name was Carol Linne? He liidhilatinized his own name th e way h e named speci i!)es!) Merely giving species names and arranging them according to similar groups was acceptable while we thought species were static entities . -

Phylogenetics Laboratory: Reconstructing Evolutionary History
Phylogenetics Laboratory: Reconstructing Evolutionary History Kefyn M. Catley Laura R. Novick Western Carolina University Vanderbilt University © June, 2016 Acknowledgments The development of this laboratory was supported by the Institute of Education Sciences, U.S. Department of Education, through Grant R305A080621 to Vanderbilt University (L. R. Novick, Principal Investigator; K. M. Catley, Co-Investigator). The opinions expressed are those of the authors and do not represent views of the Institute or the U.S. Department of Education. This laboratory was designed for use in an introductory biology class for science majors. It can be completed during the standard 3-hour laboratory section with students working in small groups. The laboratory materials include a student laboratory manual (appended here), an instructors’ guide with answer key (appended here), and various specimens. These are the typical specimens found in a general undergraduate biology laboratory and include preserved wet specimens, dried material, and cased skeletons of the nine taxa used in the lab (Annelida, Arthropoda, Chordata, Cnidaria, Echinodermata, Mollusca, Nematoda, Platyhelminthes, and Porifera). One or more undergraduate biology textbooks with which students are familiar should be made available. Students may also be encouraged to search the internet for information concerning the characters. Alternatively (or in addition), instructors may choose to provide pictures of some of the characters from such sources. The specimens, organismal chapters of the textbooks, and internet sources are resources students may use to complete the character matrix in Part I of the lab. 1 Phylogenetics Laboratory: Reconstructing Evolutionary History Kefyn M. Catley Laura R. Novick Western Carolina University Vanderbilt University Version 1 © February, 2010 Version 2 © August, 2010 Version 3.1 © June, 2011 Version 3.2 © August, 2012 Version 3.3 © June, 2016 Introduction Phylogenetics is the study of the history of life as reflected in the evolutionary relationships among taxa. -

Parsimony, Synapomorphy, and Explanatory Power: a Reply to Duncan
Saether, O. A. 1983. The canalized evolutionary potential. Inconsistencies in phylogenetic reasoning. Syst. Zoo!. 32(4): 343-359. Sober, E. 1975. Simplicity. Clarendon Press, Oxford. Thomas, W. W. 1984. The systematics of Rhynchospora section Dichromena. Mem. N. Y. Bot. Gard. 37: 1-116. Wagner, W. H., Jr. 1961. Problems in the classification of ferns. In: Recent advances in botany, vol. 1, pp. 841-844. Univ. Toronto Press, Toronto. --. 1980. Origin and philosophy ofthe groundplan-divergence method ofcladistics. Syst. Bot. 5: 173-193. Wiley, E. O. 1981. Phylogenetics. The theory and practice ofphylogenetic systematics. John Wiley & Sons, New York. Steven P. Churchill, New York Botanical Garden. Bronx, NY 10458, U.S.A.: E. O. Wiley, Museum ofNatural History and Department ofSystematics and Ecology. University ofKansas, Lawrence. KS 66045. U.S.A.; and Larry A. Hauser. Department ofBotany, University ofIllinois. Urbana. IL 61801. U.S.A. PARSIMONY, SYNAPOMORPHY, AND EXPLANATORY POWER: A REPLY TO DUNCAN According to Duncan (1984), "directed character compatibility [clique] analysis is equivalent to Hennig's method," because Hennig restricts the term synapomorphy "to shared apornorphies that are postulated to be uniquely derived." The connection between Hennig's method and parsimony analysis, Duncan maintains, is a misconception that arose because "Farris, [Kluge and Eckardt] (1970) redefine synapomorphy to include shared non-uniquely derived characters, abandon Hennig's criterion that monophyly be based on shared uniquely derived character states, and arbitrarily impose the criterion of parsimony on Hennig's method." The crux of Duncan's argument, then, is his claim concerning Hennig's definition of synapomorphy. In the usual conception, if an apomorphic trait shared by two taxa is inherited from a common ancestor, then this constitutes synapomorphy. -

Phylogeny of Angiosperms
Unit 8: Phylogeny of Angiosperms • Terms and concepts ❖ primitive and advanced ❖ homology and analogy ❖ parallelism and convergence ❖ monophyly, Paraphyly, polyphyly ❖ clades • origin& evolution of angiosperms; • co-evolution of angiosperms and animals; • methods of illustrating evolutionary relationship (phylogenetic tree, cladogram). TAXONOMY & SYSTEMATICS • Nomenclature = the naming of organisms • Classification = the assignment of taxa to groups of organisms • Phylogeny = Evolutionary history of a group (Evolutionary patterns & relationships among organisms) Taxonomy = Nomenclature + Classification Systematics = Taxonomy + Phylogenetics Phylogeny-Terms • Phylogeny- the evolutionary history of a group of organisms/ study of the genealogy and evolutionary history of a taxonomic group. • Genealogy- study of ancestral relationships and lineages. • Lineage- A continuous line of descent; a series of organisms or genes connected by ancestor/ descendent relationships. • Relationships are depicted through a diagram better known as a phylogram Evolution • Changes in the genetic makeup of populations- evolution, may occur in lineages over time. • Descent with modification • Evolution may be recognized as a change from a pre-existing or ancestral character state (plesiomorphic) to a new character state, derived character state (apomorphy). • 2 mechanisms of evolutionary change- 1. Natural selection – non-random, directed by survival of the fittest and reproductive ability-through Adaptation 2. Genetic Drift- random, directed by chance events -

Biological Classification Cladistics Cladistics
Biological Classification Taxonomy & Linnaean Hierarchy Biological Classification • Levels called taxa (sing., taxon: “classification”) – The more similar two organisms are, the more levels “King Philip Came they have in common “Kings Play Chess On F • Taxonomy: naming & classifying a) Kingdom organisms b) Phylum (Division)* c) Class • Systematics: studying relationships Over F d) Order among taxonomic groups ine Gorreen Good Sand” Soup” e) Family* f) Genus g) Species *not in the original Linnaean hierarchy Carl Linné, 1737 IV. Phylogenetic Systems Problem: Divergence vs. Convergence • Classified based on presumed common ancestry — Homology vs. Analogy • Levels in common suggests a more recent divergence from a common ancestor. • But since we don’t actually know the ancestry above Similarity due to the level of genus or maybe family, dependent upon convergence is degrees of similarity. analogy. – Comparative morphology & anatomy – Comparative embryology (Similar – Comparative biochemistry — proteins & DNA adaptations to • Much disagreement may be debated regarding similar environments; which similarities and which differences are most not shared ancestry.) phylogenetically significant! Cladistics Cladistics More vocabulary: • Clade (“branch”) — replace traditional taxon • A true clade must be monophyletic – Groups of organisms presumed to be derived – must include an ancestor and all of the known from a common ancestor are organized by descendants of that ancestor. bifurcating (two-way splitting) of a branch • A grouping that only includes an ancestor and some of its descendants is paraphyletic. – Each bifurcation is based upon the acquisition • A grouping that includes organisms from different of a new, unique character (apomorphy). ancestries is polyphyletic. • Maximum parsimony: the branch pattern that • Derived apomorphic characters shared by can be created with the fewest required steps is members of a clade are synapomorphic.