A Baybayin Word Recognition System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

'14 Oct 28 P6:23
SIXTEENTH CONGRESS Of ) THE REPUBLIC OF THE PHJUPPINES ) Second Regular Session ) '14 OCT 28 P6:23 SENATE S.B. NO. 2440 Introduced by SENATOR LOREN LEGARDA AN ACT DECLARING "BAYBAYIN" AS THE NATIONAL WRITING SYSTEM OF THE PHILIPPINES, PROVIDING FOR ITS PROMOTION, PROTECTION, PRESERVATION AND CONSERVATION, AND FOR OTHER PURPOSES EXPLANATORY NOTE The "Baybayin" is an ancient Philippine system of writing composed of a set of 17 cursive characters or letters which represents either a single consonant or vowel or a complete syllable. It started to spread throughout the country in the 16th century. However, today, there is a shortage of proof of the existence of "baybayin" scripts due to the fact that prior to the arrival of Spaniards in the Philippines, Filipino scribers would engrave mainly on bamboo poles or tree barks and frail materials that decay qUickly. To recognize our traditional writing systems which are objects of national importance and considered as a National Cultural Treasure, the "Baybayin", an indigenous national writing script which will be Tagalog-based national written language and one of the existing native written languages, is hereby declared collectively as the "Baybayin" National Writing Script of the country. Hence, it should be promoted, protected, preserved and conserved for posterity for the next generation. This bill, therefore, seeks to declare "baybayin" as the National Writing Script of the Philippines. It shall mandate the NCCA to promote, protect, preserve and conserve the script through the following (a) -

Recognition of Baybayin Symbols (Ancient Pre-Colonial Philippine Writing System) Using Image Processing
ISSN 2278-3091 Volume 9, No.1, January – February 2020 Mark Jovic A. Daday et al., International Journal of Advanced Trends in Computer Science and Engineering, 9(1), January – February 2020, 594 – 598 International Journal of Advanced Trends in Computer Science and Engineering Available Online at http://www.warse.org/IJATCSE/static/pdf/file/ijatcse83912020.pdf https://doi.org/10.30534/ijatcse/2020/83912020 Recognition of Baybayin Symbols (Ancient Pre-Colonial Philippine Writing System) using Image Processing Mark Jovic A. Daday1, Arnel C. Fajardo2, Ruji P. Medina3 1 Technological Institute of the Philippines, Quezon City, Philippines, [email protected] 2 School of Computer Science Manuel L. Quezon University, Diliman, Quezon City, Philippines, [email protected] 3 Technological Institute of the Philippines, Quezon City, Philippines, [email protected] because of the recognition problems encountered. Due to its ABSTRACT problem faces throughout recognition, computer is incapable to take out the features correctly when scanning them in [4]. The goal of this paper is to accomplish an Optical Character Recognition (OCR) that gives an extremely contribution to Alternatively, unusual modern methods for a several the advancement of technology in terms of image recognition concealed datasets of text and images were faced into more in Machine Learning. The researcher introduces the experiments, that directs to a compilation of multiple type of Feed-Forward Neural Network with Dropout Method font and unusual ruin degree in [5]. The goal of this paper is to (FFNNDM) and Convolutional Neural Network with Dropout accomplish an OCR system for the Baybayin handwriting Method (CNNDM) for the recognition of the Baybayin symbols or so called (“Alibata) an ancient and national symbols. -

Optical Character Recognition System for Baybayin Scripts Using Support Vector Machine
Optical character recognition system for Baybayin scripts using support vector machine Rodney Pino, Renier Mendoza and Rachelle Sambayan Institute of Mathematics, University of the Philippines Diliman, Quezon City, Metro Manila, Philippines ABSTRACT In 2018, the Philippine Congress signed House Bill 1022 declaring the Baybayin script as the Philippines' national writing system. In this regard, it is highly probable that the Baybayin and Latin scripts would appear in a single document. In this work, we propose a system that discriminates the characters of both scripts. The proposed system considers the normalization of an individual character to identify if it belongs to Baybayin or Latin script and further classify them as to what unit they represent. This gives us four classification problems, namely: (1) Baybayin and Latin script recognition, (2) Baybayin character classification, (3) Latin character classification, and (4) Baybayin diacritical marks classification. To the best of our knowledge, this is the first study that makes use of Support Vector Machine (SVM) for Baybayin script recognition. This work also provides a new dataset for Baybayin, its diacritics, and Latin characters. Classification problems (1) and (4) use binary SVM while (2) and (3) apply the multiclass SVM classification. On average, our numerical experiments yield satisfactory results: (1) has 98.5% accuracy, 98.5% precision, 98.49% recall, and 98.5% F1 Score; (2) has 96.51% accuracy, 95.62% precision, 95.61% recall, and 95.62% F1 Score; (3) has 95.8% accuracy, 95.85% precision, 95.8% recall, and 95.83% F1 Score; and (4) has 100% accuracy, 100% precision, 100% recall, and 100% F1 Score. -

Recognition of Baybayin (Ancient Philippine Character) Handwritten Letters Using VGG16 Deep Convolutional Neural Network Model
ISSN 2347 - 3983 Lyndon R. Bague et al., International JournalVolume of Emerging 8. No. Trends 9, September in Engineering 2020 Research, 8(9), September 2020, 5233 – 5237 International Journal of Emerging Trends in Engineering Research Available Online at http://www.warse.org/IJETER/static/pdf/file/ijeter55892020.pdf https://doi.org/10.30534/ijeter/2020/ 55892020 Recognition of Baybayin (Ancient Philippine Character) Handwritten Letters Using VGG16 Deep Convolutional Neural Network Model Lyndon R. Bague1, Romeo Jr. L. Jorda2, Benedicto N. Fortaleza3, Andrea DM. Evanculla4, Mark Angelo V. Paez5, Jessica S. Velasco6 1Department of Electrical Engineering, Technological University of the Philippines, Manila, Philippines 2,4,5,6Department of Electronics Engineering, Technological University of the Philippines, Manila, Philippines 3Department of Mechanical Engineering, Technological University of the Philippines, Manila, Philippines 1,2,3,4,5,6Center for Engineering Design, Fabrication, and Innovation, College of Engineering, Technological University of the Philippines, Manila, Philippines of this proposed study is to translate baybayin characters ABSTRACT (based on the original 1593 Doctrina Christiana) into its corresponding Tagalog word equivalent. We proposed a system that can convert 45 handwritten baybayin Philippine character/s into their corresponding The proposed software employed Deep Convolutional Neural Tagalog word/s equivalent through convolutional neural Network (DCNN) model with VGG16 as the architecture and network (CNN) using Keras. The implemented architecture image processing module using OpenCV library to perform utilizes smaller, more compact type of VGG16 network. The character recognition. There are two (2) ways to input data classification used 1500 images from each 45 baybayin into the system, real – time translation by using web camera characters. -

I Learned the Palawan Script Directly from My Grand-Aunt Upo Majiling
The Last Script Writer, recreating the Palawán Script in Cinema Kanakan-Balintagos 1. Introduction. a. Learning the Script I learned the Palawan Script directly from my grand-aunt Upo Majiling. She fondly called the script simply as Aborlan, for it originated from Aborlan she says. I belatedly discovered that I have indigenous Palawán blood. Coming from the first generation of the Palawán , born in the city of Manila. My mother belongs to a lineage of Tungkul or Shaman-Chieftains in South Palawan. She was sent to Manila to study as part of the Philippine Government's program called “Minority Scolarships”, sending brilliant indigenous children to Manila to be “educated”. The indigenous people of South Palawan were called Palawán before the whole region was called Palawan. Surat Inaborlan became the general term of the Philippine National Museum for the Palawan Script, perhaps as not to confuse with the municipality of Aborlan. The Palawán script is one of a number of closely related scripts used in the Philippines until the 17th Century AD. It is thought to have descended from the Kawi script of Java, Bali and Sumatra, which in turn descended from the Pallava script, one of the southern Indian scripts . b. Writing the Script- double meanings “Script” as Screenplay & “Script” as the Ancient Script. In the period of 1995- 2002, I lived with my tribe and learned the culture of my people. I presented two ritual-dramas in the University of the Philippines & the Cultural Center of the Philippines, namely “Ibun, Palawan's Child” ( 1999) & “Palawan Banar, Palawan Truths” (2002) repectively. -

An Introduction to Baybayin
Baybayin practice worksheets Baybayin.com | BaybayinBook.com | BaybayinSchool.com All rights reserved. No part of thiese worksheets may be reproduced or used in any way without the written permission except for reviews or articles. The title, author (Christian Cabuay) and website (Baybayin.com), must be credited. Salamat Christian Cabuay [email protected] Copyright © 2009 Introduction The following worksheets are meant to accompany the Introduction to Baybayin book and tutorials on Baybayin.com. It’s important to read those resources 1st to understand some of the basic rules of the script as well as cultural context. One of the most difficult things in Baybayin is getting used to the way the strokes are written. Most of the 17 characters can be easily mastered if you practice 4 basic strokes. They appear in most of the characters in some form. Please note that the example characters are based on my personal Baybayin writing style. Each person may write it differently. Use my style only a guideline and develop your own personal style and stroke preference overtime. © Baybayin.com | [email protected] La | Ka | Ha © Baybayin.com | [email protected] Ga | La | Sa | Nga © Baybayin.com | [email protected] Ya | Pa | A | Ma | Sa | Wa © Baybayin.com | [email protected] E/I | La | Na © Baybayin.com | [email protected] A © Baybayin.com | [email protected] E/I © Baybayin.com | [email protected] O/U © Baybayin.com | [email protected] Ba © Baybayin.com | [email protected] Ka © Baybayin.com | [email protected] Da © Baybayin.com | [email protected] Ga © Baybayin.com | [email protected] Ha © Baybayin.com | [email protected] La © Baybayin.com | [email protected] Ma © Baybayin.com | [email protected] Na © Baybayin.com | [email protected] Nga © Baybayin.com | [email protected] Pa © Baybayin.com | [email protected] Sa © Baybayin.com | [email protected] Ta © Baybayin.com | [email protected] Wa © Baybayin.com | [email protected] Ya © Baybayin.com | [email protected]. -

Appendix 3 Why “D” Is “R”: Understanding the Filipino Language and Society by Tracing the History of Its Letters
1 Appendix 3 Why “D” is “R”: Understanding the Filipino Language and Society by Tracing the History of Its Letters Filipino language learners and even native speakers get confused: when do we use din, and when do we use rin? Or for that matter, dito and rito, doon and roon? What is the difference between d and r? To understand this, we need to know that in the ancient Tagalog script, the baybayin, there was only one symbol for d and r. But studying the baybayin and the path that Filipino orthography has taken tells us more than the history of d and r. It also tells us about the history of colonialism and the nationalist movement for independence. The Baybayin The baybayin1 had seventeen basic symbols. Fourteen of these were consonant symbols with the inherent “a” sound (see the chart below): ka, ga, nga, ta, da, na pa, ba, ma, ya, la, wa, sa, and ha. Three symbols represented vowel sounds. To change the sound of the consonant symbols, diacritical marks called kudlit (or corlit) were used. With one of these marks placed above a consonant symbol, the sound became an “i” vowel sound; placed below the symbol, it became a “u” vowel sound. For example, the syllable for ba without diacritical marks, became bi with a kudlit above, and bu with a kudlit below. Here is how these syllables looked: ba bi/be bo/bu Each symbol, shown in the chart (see page 3), signifies a syllable that has a consonant and a vowel. In writing a syllable, however, that has for its components, a consonant, a vowel and a consonant (CVC), the final consonant is simply dropped. -

The Baybayin “Ra”—ᜍ Its Origins and a Plea for Its Formal Recognition
The baybayin “ra”—ᜍ its origins and a plea for its formal recognition Fredrick R. Brennan <[email protected]> July 18, 2019 Special thanks to: Deborah Anderson,∗ for her much needed expertise and review Renan Pagador, without whom this request would not have been possible Jayson Villaruz, for his help in finding materials Norman de los Santos, for his kind support of this proposal and expertise And finally, all the staff at Ateneo de Manila University’s Rizal Library for graciously allowingmeto browse their Filipiniana archives ᜍᜍᜍᜍ See with what large letters I am writing to you with my own hand! Galatians 6:11 ∗Script Encoding Initiative/Universal Scripts Project, UC Berkeley Quick summary If this proposal is accepted, the following characters will exist: • U+170D ᜍ TAGALOG LETTER RA • U+171F ᜟ TAGALOG LETTER ARCHAIC RA 3 Contents Introduction 6 0.1 Linguistic details ........................... 6 Unicode considerations 8 0.2 Characters ............................... 8 0.3 A note on ᜟ’s name .......................... 9 0.4 Properties ............................... 9 0.4.1 Character remarks ...................... 9 0.5 Collation ................................ 10 History 11 0.6 The Zambales ‘ra’, ᜟ ......................... 11 0.6.1 Mariano Dario Canseco’s Palatitikan kayumanggi (1966) . 13 0.6.2 Panitik Silangan, September 1963 .............. 16 0.7 The modern ‘ra’, ᜍ .......................... 17 0.7.1 The Bikol ‘ra’, ᜍ ........................ 17 0.7.2 Rizaleo ‘ra’—ᜍ ........................ 19 Further evidence 22 0.8 Printed materials ........................... 22 0.8.1 Jeremiah Cordial’s The Seventh Moon, 2018 ........ 22 0.8.2 Jean-Paul G. Potet’s Baybáyin: L'Alphabet Syllabique des Tagals, 2012 (French edition) ................ 23 0.8.3 Kalem (Anak Bathala), №1, 2013, BHM Publishing, graphic novel ............................. -

Baybayin New Applied Typography
Baybayin New Applied Typography BAYBAYIN NEW BAYBAYIN VOWELS BAYBAYIN CONSONANTS Inspired by the Philippine writing system Baybayin during the pre-colonial In terms of Baybayin’s characteristics, this is an abugida system that uses For example, the words dunong (knowledge) & marunong (knowledgeable) period, a customized typeface entitled ‘Baybayin New’ was developed. consonant-vowel combinations. Written in its basic form, each character is and even raw for daw (he/she said) and rin for din (also, too) after vowels. a consonant ending with the vowel ‘A’. A mark is placed either above the As these languages have separate symbols for ‘D’ and ‘R,’ this variant of the This decorative & display typeface can be applied to posters, product consonant to produce an ‘E’ or ‘I’ sound or below the consonant to produce script is not used for Ilokano, Pangasinan, Bikolano, & other local languages packaging and visual novelty items (komiks) and more. an ‘O’ or ‘U’ sound. A kudlit mark is placed to produce consonants ending to name a few. with the other vowel sounds except stand-alone vowels since vowels have The term baybay means ‘to spell out’ in Filipino. Baybayin was attributed to their own glyphs. Reintroducing the basic elements of Baybayin allows continuous modern the name ‘Alibata’ which was coined after the Arabic alphabet’s arrangement practice of the language forms in the past. This development of contemporary of letters. There are several theories relating to the origins of Baybayin. Meanwhile, allophones ‘D’ or ‘R’ has only one symbol, wherein ‘D’ occurred typography is easily used and understood not only by Filipinos but alsoby the These include Kawi from Java, Old Sumatran scripts from Malay, Makassarese in initial, final, pre-consonantal or post-consonantal positions and ‘R’ in people from foreign countries to be recognized globally. -
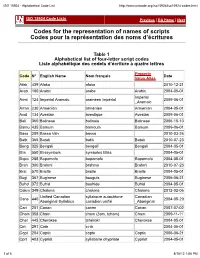
ISO 15924 - Alphabetical Code List
ISO 15924 - Alphabetical Code List http://www.unicode.org/iso15924/iso15924-codes.html ISO 15924 Code Lists Previous | RA Home | Next Codes for the representation of names of scripts Codes pour la représentation des noms d’écritures Table 1 Alphabetical list of four-letter script codes Liste alphabétique des codets d’écriture à quatre lettres Property Code N° English Name Nom français Date Value Alias Afak 439 Afaka afaka 2010-12-21 Arab 160 Arabic arabe Arabic 2004-05-01 Imperial Armi 124 Imperial Aramaic araméen impérial 2009-06-01 _Aramaic Armn 230 Armenian arménien Armenian 2004-05-01 Avst 134 Avestan avestique Avestan 2009-06-01 Bali 360 Balinese balinais Balinese 2006-10-10 Bamu 435 Bamum bamoum Bamum 2009-06-01 Bass 259 Bassa Vah bassa 2010-03-26 Batk 365 Batak batik Batak 2010-07-23 Beng 325 Bengali bengalî Bengali 2004-05-01 Blis 550 Blissymbols symboles Bliss 2004-05-01 Bopo 285 Bopomofo bopomofo Bopomofo 2004-05-01 Brah 300 Brahmi brahma Brahmi 2010-07-23 Brai 570 Braille braille Braille 2004-05-01 Bugi 367 Buginese bouguis Buginese 2006-06-21 Buhd 372 Buhid bouhide Buhid 2004-05-01 Cakm 349 Chakma chakma Chakma 2012-02-06 Unified Canadian syllabaire autochtone Canadian Cans 440 2004-05-29 Aboriginal Syllabics canadien unifié _Aboriginal Cari 201 Carian carien Carian 2007-07-02 Cham 358 Cham cham (čam, tcham) Cham 2009-11-11 Cher 445 Cherokee tchérokî Cherokee 2004-05-01 Cirt 291 Cirth cirth 2004-05-01 Copt 204 Coptic copte Coptic 2006-06-21 Cprt 403 Cypriot syllabaire chypriote Cypriot 2004-05-01 1 of 6 8/16/12 1:56 PM ISO -
Unicode Reference Lists: Other Script Sources
Other Script Sources File last updated October 2020 General ALA-LC Romanization Tables: Transliteration Schemes for Non-Roman Scripts, Approved by the Library of Congress and the American Library Association. Tables compiled and edited by Randall K. Barry. Washington, DC: Library of Congress, 1997. ISBN 0-8444-0940-5. Adlam Barry, Ibrahima Ishagha. 2006. Hè’lma wallifandè fin èkkitago’l bèbèrè Pular: Guide pra- tique pour apprendre l’alphabet Pulaar. Conakry, 2006. Ahom Barua, Bimala Kanta, and N.N. Deodhari Phukan. Ahom Lexicons, Based on Original Tai Manuscripts. Guwahati: Department of Historical and Antiquarian Studies, 1964. Hazarika, Nagen, ed. Lik Tai K hwam Tai (Tai letters and Tai words). Souvenir of the 8th Annual conference of Ban Ok Pup Lik Mioung Tai. Eastern Tai Literary Association, 1990. Kar, Babul. Tai Ahom Alphabet Book. Sepon, Assam: Tai Literature Associate, 2005. Alchemical Symbols Berthelot, Marcelin. Collection des anciens alchimistes grecs. 3 vols. Paris: G. Steinheil, 1888. Berthelot, Marcelin. La chimie au moyen âge. 3 vols. Osnabrück: O. Zeller, 1967. Lüdy-Tenger, Fritz. Alchemistische und chemische Zeichen. Würzburg: JAL-reprint, 1973. Schneider, Wolfgang. Lexikon alchemistisch-pharmazeutischer Symbole. Weinheim/Berg- str.: Verlag Chemie, 1962. Anatolian Hieroglyphs Hawkins, John David, and Halet Çambel. Corpus of Hieroglyphic Luwian Inscriptions. Ber- lin and New York: Walter de Gruyter, 2000. ISBN 3-11-010864-X. Herbordt, Suzanne. Die Prinzen- und Beamtensiegel der hethitischen Grossreichszeit auf Tonbullen aus dem Ni!antepe-Archiv in Hattusa. Mit Kommentaren zu den Siegelin- schriften und Hieroglyphen von J. David Hawkins. Mainz am Rhein: Verlag Philipp von Zabern, 2005. ISBN: 3-8053-3311-0. -

LANGUAGES of INDIA WHITE PAPER Languages of India I
LANGUAGES OF INDIA WHITE PAPER Languages of India i About Andovar Andovar is a global provider of multilingual content solutions. Our services range from text translation and content creation, through audio and video recording, to turnkey localization of websites, software, eLearning and games. Our headquarters is in Singapore, and offices in Thailand, Colombia, USA and India. About This White Paper Andovar opened an office in Kolkata in 2014 to better serve our international clients and to add Indian language translation and audio recording to our suite of services. This white paper is an attempt to understand the localization situation when it comes to the major languages spoken in India. This has proven to be a challenging task. Not only are there dozens of languages and over ten scripts in everyday use in India, but it is also a rapidly developing country, with a huge and growing economy and new intiatives related to languages, encoding and translation technology support appear almost monthly. Not much has been written to date to give a holistic overview of the localization landscape and hopefully this white paper will be a useful reference to language professionals, even if it is far from perfect. As such, there may be mistakes or missing information which will be added in future updates. Please contact [email protected] with any questions or suggestions. The data on number or speakers and native speakers of Indian languages is unreliable, with different sources following different conventions when deciding what is a language and what is merely a dialect*. Our first source is the Indian Census from 2001 (www.censusindia.gov.in/Census_Data_2001/), which provided comprehensive information about the whole country, but is now outdated.