A Durable Hybrid RAM Disk with a Rapid Resilience for Sustainable Iot Devices
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Better Performance Through a Disk/Persistent-RAM Hybrid Design
The Conquest File System: Better Performance Through a Disk/Persistent-RAM Hybrid Design AN-I ANDY WANG Florida State University GEOFF KUENNING Harvey Mudd College PETER REIHER, GERALD POPEK University of California, Los Angeles ________________________________________________________________________ Modern file systems assume the use of disk, a system-wide performance bottleneck for over a decade. Current disk caching and RAM file systems either impose high overhead to access memory content or fail to provide mechanisms to achieve data persistence across reboots. The Conquest file system is based on the observation that memory is becoming inexpensive, which enables all file system services to be delivered from memory, except providing large storage capacity. Unlike caching, Conquest uses memory with battery backup as persistent storage, and provides specialized and separate data paths to memory and disk. Therefore, the memory data path contains no disk-related complexity. The disk data path consists of only optimizations for the specialized disk usage pattern. Compared to a memory-based file system, Conquest incurs little performance overhead. Compared to several disk-based file systems, Conquest achieves 1.3x to 19x faster memory performance, and 1.4x to 2.0x faster performance when exercising both memory and disk. Conquest realizes most of the benefits of persistent RAM at a fraction of the cost of a RAM-only solution. Conquest also demonstrates that disk-related optimizations impose high overheads for accessing memory content in a memory-rich environment. Categories and Subject Descriptors: D.4.2 [Operating Systems]: Storage Management—Storage Hierarchies; D.4.3 [Operating Systems]: File System Management—Access Methods and Directory Structures; D.4.8 [Operating Systems]: Performance—Measurements General Terms: Design, Experimentation, Measurement, and Performance Additional Key Words and Phrases: Persistent RAM, File Systems, Storage Management, and Performance Measurement ________________________________________________________________________ 1. -

Amigan Software
tali ► an Amiga Februar y 97 Issue No 3 Gaz te rip $3 Who said that there are no Amiga dealers left? Hardware Amiga A1200 HD, Amiga A4000 Cobra 33 68030 33, Mhz Cobra 33+ with 68882, Cobra 40 68EC030 40 Mhz, Cobra40+ with 68882, Ferret SCSI card for Cobra 1202 32 bit rami- clock, 1202+ with 16 or 33 Mhz 68882, Squirrel SCSI, Surf Squirrel SCSI plus RS@232, 2 Mb PCMCIA Ram A1200/A600, Spitfire SCSI A2000/3000/4000, Rapidfire SCSI + RAM A2000, Wildfire A2000 68060+ram+SCSI F/W+network, Megachip, 2Mb chip ram A500/A2000, Securekey Security card for A2000/3000/4000, Picasso Graphics cards, SCSI and IDE Hard drives. Accessories Green Mouse -320 DPI with pad, Hypermouse I1 400 DPI with pad, Pen mouse - super small, Joysticks, from Quickshot and Rocfire, GI 105 hand- scanner with touchup 4 and OCR Jr, Colourburst colour hand scanner with ADPRO loader & OCR Jr, Master 3A 880 K External Floppy drives, Rocgen Plus genlock, Electronic Design Genlocks and TBC, Neriki Genlocks Syquest EzDrives, External SCSI Cases with A500/A600/A1200 power lead included & CD, or hard drive option, A1200 3.5 IDE Kits, Monitor adaptors, ROM Switches, Air Freight Magazines with CD. Plus Much more Available. Software Over 70 titles in stock including games, productivity, CD rom titles, and Utilities, all at competative prices. Servicing We have a fully equiped workshop, and our techs have a total of over 50 Man years of experience as technicians in the computer industry. We do repairs and upgrades including specialist work. The Complete Amiga specialist. -

AMD Radeon™ Ramdisk User's Manual And
AMD Radeon™ RAMDisk User's Manual and FAQ Revision Tracker Revision Number Software Version Description Revision Date 04 V4.0.0 Initial Release October 2012 05 V4.1.x Version 4.1.x Update March 2013 06 V4.2.x Version 4.2.x Update June 2013 07 V4.3.x Version 4.3.x Update October 2013 08 V4.4.x Version 4.4.x Update December 2013 1 2 Table of Contents 1. Introduction to RAMDISK .......................................................................................................................... 5 What is RAMDisk? .................................................................................................................................... 5 How does it work? ..................................................................................................................................... 5 What is the benefit? .................................................................................................................................. 5 2. Screen-by-screen definition of settings .................................................................................................... 7 Menus and Start/Stop Buttons .................................................................................................................. 7 Settings Tab .............................................................................................................................................. 9 Advanced Settings Tab ........................................................................................................................... 15 -

Storage Systems and Technologies - Jai Menon and Clodoaldo Barrera
INFORMATION TECHNOLOGY AND COMMUNICATIONS RESOURCES FOR SUSTAINABLE DEVELOPMENT - Storage Systems and Technologies - Jai Menon and Clodoaldo Barrera STORAGE SYSTEMS AND TECHNOLOGIES Jai Menon IBM Academy of Technology, San Jose, CA, USA Clodoaldo Barrera IBM Systems Group, San Jose, CA, USA Keywords: Storage Systems, Hard disk drives, Tape Drives, Optical Drives, RAID, Storage Area Networks, Backup, Archive, Network Attached Storage, Copy Services, Disk Caching, Fiber Channel, Storage Switch, Storage Controllers, Disk subsystems, Information Lifecycle Management, NFS, CIFS, Storage Class Memories, Phase Change Memory, Flash Memory, SCSI, Caching, Non-Volatile Memory, Remote Copy, Storage Virtualization, Data De-duplication, File Systems, Archival Storage, Storage Software, Holographic Storage, Storage Class Memory, Long-Term data preservation Contents 1. Introduction 2. Storage devices 2.1. Storage Device Industry Overview 2.2. Hard Disk Drives 2.3. Digital Tape Drives 2.4. Optical Storage 2.5. Emerging Storage Technologies 2.5.1. Holographic Storage 2.5.2. Flash Storage 2.5.3. Storage Class Memories 3. Block Storage Systems 3.1. Storage System Functions – Current 3.2. Storage System Functions - Emerging 4. File and Archive Storage Systems 4.1. Network Attached Storage 4.2. Archive Storage Systems 5. Storage Networks 5.1. SAN Fabrics 5.2. IP FabricsUNESCO – EOLSS 5.3. Converged Networking 6. Storage SoftwareSAMPLE CHAPTERS 6.1. Data Backup 6.2. Data Archive 6.3. Information Lifecycle Management 6.4. Disaster Protection 7. Concluding Remarks Acknowledgements Glossary Bibliography Biographical Sketches ©Encyclopedia of Life Support Systems (EOLSS) INFORMATION TECHNOLOGY AND COMMUNICATIONS RESOURCES FOR SUSTAINABLE DEVELOPMENT - Storage Systems and Technologies - Jai Menon and Clodoaldo Barrera Summary Our world is increasingly becoming a data-centric world. -

Chapter 12: Mass-Storage Systems
Chapter 12: Mass-Storage Systems Overview of Mass Storage Structure Disk Structure Disk Attachment Disk Scheduling Disk Management Swap-Space Management RAID Structure Disk Attachment Stable-Storage Implementation Tertiary Storage Devices Operating System Issues Performance Issues Objectives Describe the physical structure of secondary and tertiary storage devices and the resulting effects on the uses of the devices Explain the performance characteristics of mass-storage devices Discuss operating-system services provided for mass storage, including RAID and HSM Overview of Mass Storage Structure Magnetic disks provide bulk of secondary storage of modern computers Drives rotate at 60 to 200 times per second Transfer rate is rate at which data flow between drive and computer Positioning time (random-access time) is time to move disk arm to desired cylinder (seek time) and time for desired sector to rotate under the disk head (rotational latency) Head crash results from disk head making contact with the disk surface That’s bad Disks can be removable Drive attached to computer via I/O bus Busses vary, including EIDE, ATA, SATA, USB, Fibre Channel, SCSI Host controller in computer uses bus to talk to disk controller built into drive or storage array Moving-head Disk Mechanism Overview of Mass Storage Structure (Cont.) Magnetic tape Was early secondary-storage medium Relatively permanent and holds large quantities of data Access time slow Random access ~1000 times slower than disk Mainly used for backup, storage of infrequently-used data, transfer medium between systems Kept in spool and wound or rewound past read-write head Once data under head, transfer rates comparable to disk 20-200GB typical storage Common technologies are 4mm, 8mm, 19mm, LTO-2 and SDLT Disk Structure Disk drives are addressed as large 1-dimensional arrays of logical blocks, where the logical block is the smallest unit of transfer. -
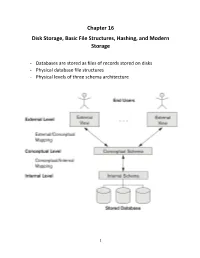
Chapter 16 Disk Storage, Basic File Structures, Hashing, and Modern Storage
Chapter 16 Disk Storage, Basic File Structures, Hashing, and Modern Storage - Databases are stored as files of records stored on disks - Physical database file structures - Physical levels of three schema architecture 1 - The collection of data in a DB must be stored on some storage medium. The DBMS software can retrieve, update, and process this data as needed - Storage media forms a hierarchy 2 -primary, secondary, tertiary, etc.. - offline storage, archiving databases (larger capacity, less cost, slower access, not directly accessible by CPU) Memory Hierarchies and Storage Devices - Cache, static RAM (Prefetch, Pipeline) - Dynamic RAM (main memory( Secondary and Tertiary Storage -mass storage (magnetic disks, CD, DVD (measured in KB, MB, TB, PB - programs are in main memory (DRAM) -permanent databases reside in secondary storage - main memory buffers are used to read and write to secondary storage - Flash memory: non volatile, NAND and NOR flash based - Optical disks: CDs (700MB) and DVDs (4.5 – 15GB), Blue Ray (54GB) - Magnetic Tapes and Juke Boxes Depending upon the intended use and application requirements, data is kept in one or more levels of hierarchy 3 Storage Organization of Database -Large amount of data that must persist for a long period of time (called persistent data) - parts of this data are accessed and processed repeatedly during the storage period - transient data during the period of execution - most DBs are stored on secondary storage (magnetic disks) - DB is too large to fit in main memory - permanent loss on disk is less likely - less cost on disk than primary storage 4 5 6 - A range of cylinders have the same number of sectors per arc. -

Use External Storage Devices Like Pen Drives, Cds, and Dvds
External Intel® Learn Easy Steps Activity Card Storage Devices Using external storage devices like Pen Drives, CDs, and DVDs loading Videos Since the advent of computers, there has been a need to transfer data between devices and/or store them permanently. You may want to look at a file that you have created or an image that you have taken today one year later. For this it has to be stored somewhere securely. Similarly, you may want to give a document you have created or a digital picture you have taken to someone you know. There are many ways of doing this – online and offline. While online data transfer or storage requires the use of Internet, offline storage can be managed with minimum resources. The only requirement in this case would be a storage device. Earlier data storage devices used to mainly be Floppy drives which had a small storage space. However, with the development of computer technology, we today have pen drives, CD/DVD devices and other removable media to store and transfer data. With these, you store/save/copy files and folders containing data, pictures, videos, audio, etc. from your computer and even transfer them to another computer. They are called secondary storage devices. To access the data stored in these devices, you have to attach them to a computer and access the stored data. Some of the examples of external storage devices are- Pen drives, CDs, and DVDs. Introduction to Pen Drive/CD/DVD A pen drive is a small self-powered drive that connects to a computer directly through a USB port. -

Olympus Optical Disc Archiving Systems & Discstor 900 Optical
Olympus Optical Disc Archiving Systems & DiscStor 900 Optical Disc Storage System Solution Overview All Pro Solutions, Inc. | 1351 E. Black Street, Rock Hill, SC 29730 USA | Tel: +1.803.980.4141 | Web: www.allprosolutions.com | Email: [email protected] The Company – All Pro Solutions, Inc. – Leading manufacturer of automated disc duplicating, printing & publishing systems. – Started in 1996 manufacturing floppy disk duplication systems. – Family-owned and operated. – In South Carolina since 2009. – Provides services like document scanning, imaging, converting. – Expanded into data storage and archiving industry. – Whatever the problem, we find a solution. All Pro Solutions, Inc. | 1351 E. Black Street, Rock Hill, SC 29730 USA | Tel: +1.803.980.4141 | Web: www.allprosolutions.com | Email: [email protected] The Challenge Worldwide Corporate Data Growth Unstructured text Structured data Source: IDC The Digital Universe 2010 80% of Corporate Data is Unstructured File Data Active Less Active Inactive Hot Cold 10% Warm 20% 70% All Pro Solutions, Inc. | 1351 E. Black Street, Rock Hill, SC 29730 USA | Tel: +1.803.980.4141 | Web: www.allprosolutions.com | Email: [email protected] The Solution Blu-Ray Disc – The ideal media for long-term archival • Longevity • Capacity - Extendable • Security • Removability • Data Migration • Accessibility • Compliance • Compatibility • Green Technology • Power Consumption Networked Client Workstations LAN Primary Network Servers All Pro Solutions, Inc. | 1351 E. Black Street, Rock Hill, SC 29730 USA | Tel: +1.803.980.4141 | Web: www.allprosolutions.com | Email: [email protected] The Solution Blu-Ray Disc – The ideal media for long-term archival • Longevity • Capacity - Extendable • Security • Removability • Data Migration • Accessibility • Compliance • Compatibility • Green Technology • Power Consumption Networked Client Workstations Olympus Archiving System LAN DiscStor 900 Storage System Primary Network Servers All Pro Solutions, Inc. -

Secure Data Storage – White Paper Storage Technologies 2008
1 Secure Data Storage – White Paper Storage Technologies 2008 Secure Data Storage - An overview of storage technology - Long time archiving from extensive data supplies requires more then only big storage capacity to be economical. Different requirements need different solutions! A technology comparison repays. Author: Dr. Klaus Engelhardt Dr. K. Engelhardt 2 Secure Data Storage – White Paper Storage Technologies 2008 Secure Data Storage - An overview of storage technology - Author: Dr. Klaus Engelhardt Audit-compliant storage of large amounts of data is a key task in the modern business world. It is a mistake to see this task merely as a matter of storage technology. Instead, companies must take account of essential strategic and economic parameters as well as legal regulations. Often one single technology alone is not sufficient to cover all needs. Thus storage management is seldom a question of one solution verses another, but a combination of solutions to achieve the best possible result. This can frequently be seen in the overly narrow emphasis in many projects on hard disk-based solutions, an approach that is heavily promoted in advertising, and one that imprudently neglects the considerable application benefits of optical storage media (as well as those of tape-based solutions). This overly simplistic perspective has caused many professional users, particularly in the field of long-term archiving, to encounter unnecessary technical difficulties and economic consequences. Even a simple energy efficiency analysis would provide many users with helpful insights. Within the ongoing energy debate there is a simple truth: it is one thing to talk about ‘green IT’, but finding and implementing a solution is a completely different matter. -

Control Design and Implementation of Hard Disk Drive Servos by Jianbin
Control Design and Implementation of Hard Disk Drive Servos by Jianbin Nie A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Engineering-Mechanical Engineering in the Graduate Division of the University of California, Berkeley Committee in charge: Professor Roberto Horowitz, Chair Professor Masayoshi Tomizuka Professor David Brillinger Spring 2011 Control Design and Implementation of Hard Disk Drive Servos ⃝c 2011 by Jianbin Nie 1 Abstract Control Design and Implementation of Hard Disk Drive Servos by Jianbin Nie Doctor of Philosophy in Engineering-Mechanical Engineering University of California, Berkeley Professor Roberto Horowitz, Chair In this dissertation, the design of servo control algorithms is investigated to produce high-density and cost-effective hard disk drives (HDDs). In order to sustain the continuing increase of HDD data storage density, dual-stage actuator servo systems using a secondary micro-actuator have been developed to improve the precision of read/write head positioning control by increasing their servo bandwidth. In this dissertation, the modeling and control design of dual-stage track-following servos are considered. Specifically, two track-following control algorithms for dual-stage HDDs are developed. The designed controllers were implemented and evaluated on a disk drive with a PZT-actuated suspension-based dual-stage servo system. Usually, the feedback position error signal (PES) in HDDs is sampled on some spec- ified servo sectors with an equidistant sampling interval, which implies that HDD servo systems with a regular sampling rate can be modeled as linear time-invariant (LTI) systems. However, sampling intervals for HDD servo systems are not always equidistant and, sometimes, an irregular sampling rate due to missing PES sampling data is unavoidable. -

Field Upgrade Instruction Guide (V2.X to V3.3) Revision 2 6/21/2004
Field Upgrade Instruction Guide (v2.x to v3.3) Revision 2 6/21/2004 FFiieelldd UUppggrraaddee IInnssttrruuccttiioonn GGuuiiddee (v2.x to v3.3) Revision 2 6/21/2004 Table of Contents Section 1: DocSTAR v3.3 Requirements & Installation CD ........................................ 3 Section 2: DocSTAR v3.3 Field Upgrade Kits (v2.x to v3.3)........................................ 5 Installation Procedure .................................................................................................... 7 Appendix A: DocSTAR Approved Scanner List......................................................... 13 Appendix B: ISIS Scanner Drivers found on the DocSTAR v3.3 CD........................ 16 Appendix C: Creating Windows 2000 Setup Boot Disks........................................... 17 Appendix D: Installing Windows 2000 Professional.................................................. 18 Appendix E: Installing Windows 2000 Server ............................................................ 23 Appendix F: Installing SQL Server 2000 (New Install)............................................... 28 Appendix G: Installing SQL Server 2000 (Upgrading an existing MSDE/SQL Server Database)....................................................................................................................... 31 DocSTAR Field Upgrade Instruction Guide – v2.x to v3.3 Section 1: DocSTAR v3.3 Requirements & Installation CD ) This section will familiarize you with the minimum requirements to upgrade to DocSTAR v3.3 Software and the contents of the DocSTAR -

Archiving Online Data to Optical Disk
ARCHIVING ONLINE DATA TO OPTICAL DISK By J. L. Porter, J. L. Kiesler, and D. A. Stedfast U.S. GEOLOGICAL SURVEY Open-File Report 90-575 Reston, Virginia 1990 U.S. DEPARTMENT OF THE INTERIOR MANUEL LUJAN, JR., Secretary U.S. GEOLOGICAL SURVEY Dallas L. Peck, Director For additional information Copies of this report can be write to: purchased from: Chief, Distributed Information System U.S. Geological Survey U.S. Geological Survey Books and Open-File Reports Section Mail Stop 445 Federal Center, Bldg. 810 12201 Sunrise Valley Drive Box 25425 Reston, Virginia 22092 Denver, Colorado 80225 CONTENTS Page Abstract ............................................................. 1 Introduction ......................................................... 2 Types of optical storage ............................................... 2 Storage media costs and alternative media used for data archival. ......... 3 Comparisons of storage media ......................................... 3 Magnetic compared to optical media ............................... 3 Compact disk read-only memory compared to write-once/read many media ................................... 6 Erasable compared to write-once/read many media ................. 7 Paper and microfiche compared to optical media .................... 8 Advantages of write-once/read-many optical storage ..................... 8 Archival procedure and results ........................................ 9 Summary ........................................................... 13 References ..........................................................