Robot Trajectory Optimization Using Approximate Inference
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Celestial Mechanics of Newton
GENERAL I ARTICLE The Celestial Mechanics of Newton Dipankar Bhattacharya Newton's law of universal gravitation laid the physical foundation of celestial mechanics. This article reviews the steps towards the law of gravi tation, and highlights some applications to celes tial mechanics found in Newton's Principia. 1. Introduction Newton's Principia consists of three books; the third Dipankar Bhattacharya is at the Astrophysics Group dealing with the The System of the World puts forth of the Raman Research Newton's views on celestial mechanics. This third book Institute. His research is indeed the heart of Newton's "natural philosophy" interests cover all types of which draws heavily on the mathematical results derived cosmic explosions and in the first two books. Here he systematises his math their remnants. ematical findings and confronts them against a variety of observed phenomena culminating in a powerful and compelling development of the universal law of gravita tion. Newton lived in an era of exciting developments in Nat ural Philosophy. Some three decades before his birth J 0- hannes Kepler had announced his first two laws of plan etary motion (AD 1609), to be followed by the third law after a decade (AD 1619). These were empirical laws derived from accurate astronomical observations, and stirred the imagination of philosophers regarding their underlying cause. Mechanics of terrestrial bodies was also being developed around this time. Galileo's experiments were conducted in the early 17th century leading to the discovery of the Keywords laws of free fall and projectile motion. Galileo's Dialogue Celestial mechanics, astronomy, about the system of the world was published in 1632. -

Curriculum Overview Physics/Pre-AP 2018-2019 1St Nine Weeks
Curriculum Overview Physics/Pre-AP 2018-2019 1st Nine Weeks RESOURCES: Essential Physics (Ergopedia – online book) Physics Classroom http://www.physicsclassroom.com/ PHET Simulations https://phet.colorado.edu/ ONGOING TEKS: 1A, 1B, 2A, 2B, 2C, 2D, 2F, 2G, 2H, 2I, 2J,3E 1) SAFETY TEKS 1A, 1B Vocabulary Fume hood, fire blanket, fire extinguisher, goggle sanitizer, eye wash, safety shower, impact goggles, chemical safety goggles, fire exit, electrical safety cut off, apron, broken glass container, disposal alert, biological hazard, open flame alert, thermal safety, sharp object safety, fume safety, electrical safety, plant safety, animal safety, radioactive safety, clothing protection safety, fire safety, explosion safety, eye safety, poison safety, chemical safety Key Concepts The student will be able to determine if a situation in the physics lab is a safe practice and what appropriate safety equipment and safety warning signs may be needed in a physics lab. The student will be able to determine the proper disposal or recycling of materials in the physics lab. Essential Questions 1. How are safe practices in school, home or job applied? 2. What are the consequences for not using safety equipment or following safe practices? 2) SCIENCE OF PHYSICS: Glossary, Pages 35, 39 TEKS 2B, 2C Vocabulary Matter, energy, hypothesis, theory, objectivity, reproducibility, experiment, qualitative, quantitative, engineering, technology, science, pseudo-science, non-science Key Concepts The student will know that scientific hypotheses are tentative and testable statements that must be capable of being supported or not supported by observational evidence. The student will know that scientific theories are based on natural and physical phenomena and are capable of being tested by multiple independent researchers. -

Classical Particle Trajectories‡
1 Variational approach to a theory of CLASSICAL PARTICLE TRAJECTORIES ‡ Introduction. The problem central to the classical mechanics of a particle is usually construed to be to discover the function x(t) that describes—relative to an inertial Cartesian reference frame—the positions assumed by the particle at successive times t. This is the problem addressed by Newton, according to whom our analytical task is to discover the solution of the differential equation d2x(t) m = F (x(t)) dt2 that conforms to prescribed initial data x(0) = x0, x˙ (0) = v0. Here I explore an alternative approach to the same physical problem, which we cleave into two parts: we look first for the trajectory traced by the particle, and then—as a separate exercise—for its rate of progress along that trajectory. The discussion will cast new light on (among other things) an important but frequently misinterpreted variational principle, and upon a curious relationship between the “motion of particles” and the “motion of photons”—the one being, when you think about it, hardly more abstract than the other. ‡ The following material is based upon notes from a Reed College Physics Seminar “Geometrical Mechanics: Remarks commemorative of Heinrich Hertz” that was presented February . 2 Classical trajectories 1. “Transit time” in 1-dimensional mechanics. To describe (relative to an inertial frame) the 1-dimensional motion of a mass point m we were taught by Newton to write mx¨ = F (x) − d If F (x) is “conservative” F (x)= dx U(x) (which in the 1-dimensional case is automatic) then, by a familiar line of argument, ≡ 1 2 ˙ E 2 mx˙ + U(x) is conserved: E =0 Therefore the speed of the particle when at x can be described 2 − v(x)= m E U(x) (1) and is determined (see the Figure 1) by the “local depth E − U(x) of the potential lake.” Several useful conclusions are immediate. -

Failure of Engineering Artifacts: a Life Cycle Approach
Sci Eng Ethics DOI 10.1007/s11948-012-9360-0 ORIGINAL PAPER Failure of Engineering Artifacts: A Life Cycle Approach Luca Del Frate Received: 30 August 2011 / Accepted: 13 February 2012 Ó The Author(s) 2012. This article is published with open access at Springerlink.com Abstract Failure is a central notion both in ethics of engineering and in engi- neering practice. Engineers devote considerable resources to assure their products will not fail and considerable progress has been made in the development of tools and methods for understanding and avoiding failure. Engineering ethics, on the other hand, is concerned with the moral and social aspects related to the causes and consequences of technological failures. But what is meant by failure, and what does it mean that a failure has occurred? The subject of this paper is how engineers use and define this notion. Although a traditional definition of failure can be identified that is shared by a large part of the engineering community, the literature shows that engineers are willing to consider as failures also events and circumstance that are at odds with this traditional definition. These cases violate one or more of three assumptions made by the traditional approach to failure. An alternative approach, inspired by the notion of product life cycle, is proposed which dispenses with these assumptions. Besides being able to address the traditional cases of failure, it can deal successfully with the problematic cases. The adoption of a life cycle perspective allows the introduction of a clearer notion of failure and allows a classification of failure phenomena that takes into account the roles of stakeholders involved in the various stages of a product life cycle. -

An Extended Trajectory Mechanics Approach for Calculating 10.1002/2017WR021360 the Path of a Pressure Transient: Derivation and Illustration
Water Resources Research RESEARCH ARTICLE An Extended Trajectory Mechanics Approach for Calculating 10.1002/2017WR021360 the Path of a Pressure Transient: Derivation and Illustration Key Points: D. W. Vasco1 The technique described in this paper is useful for visualization and 1Lawrence Berkeley National Laboratory, University of California, Berkeley, Berkeley, CA, USA efficient inversion The trajectory-based approach is valid for an arbitrary porous medium Abstract Following an approach used in quantum dynamics, an exponential representation of the hydraulic head transforms the diffusion equation governing pressure propagation into an equivalent set of Correspondence to: ordinary differential equations. Using a reservoir simulator to determine one set of dependent variables D. W. Vasco, [email protected] leaves a reduced set of equations for the path of a pressure transient. Unlike the current approach for computing the path of a transient, based on a high-frequency asymptotic solution, the trajectories resulting Citation: from this new formulation are valid for arbitrary spatial variations in aquifer properties. For a medium Vasco, D. W. (2018). An extended containing interfaces and layers with sharp boundaries, the trajectory mechanics approach produces paths trajectory mechanics approach for that are compatible with travel time fields produced by a numerical simulator, while the asymptotic solution calculating the path of a pressure transient: Derivation and illustration. produces paths that bend too strongly into high permeability regions. The breakdown of the conventional Water Resources Research, 54. https:// asymptotic solution, due to the presence of sharp boundaries, has implications for model parameter doi.org/10.1002/2017WR021360 sensitivity calculations and the solution of the inverse problem. -

Celestial Mechanics Theory Meets the Nitty-Gritty of Trajectory Design
From SIAM News, Volume 37, Number 6, July/August 2004 Celestial Mechanics Theory Meets the Nitty-Gritty of Trajectory Design Capture Dynamics and Chaotic Motions in Celestial Mechanics: With Applications to the Construction of Low Energy Transfers. By Edward Belbruno, Princeton University Press, Princeton, New Jersey, 2004, xvii + 211 pages, $49.95. In January 1990, ISAS, Japan’s space research institute, launched a small spacecraft into low-earth orbit. There it separated into two even smaller craft, known as MUSES-A and MUSES-B. The plan was to send B into orbit around the moon, leaving its slightly larger twin A behind in earth orbit as a communications relay. When B malfunctioned, however, mission control wondered whether A might not be sent in its stead. It was less than obvious that this BOOK REVIEW could be done, since A was neither designed nor equipped for such a trip, and appeared to carry insufficient fuel. Yet the hope was that, by utilizing a trajectory more energy-efficient than the one By James Case planned for B, A might still reach the moon. Such a mission would have seemed impossible before 1986, the year Edward Belbruno discovered a class of surprisingly fuel-efficient earth–moon trajectories. When MUSES-B malfunctioned, Belbruno was ready and able to tailor such a trajectory to the needs of MUSES-A. This he did, in collaboration with J. Miller of the Jet Propulsion Laboratory, in June 1990. As a result, MUSES-A (renamed Hiten) left earth orbit on April 24, 1991, and settled into moon orbit on October 2 of that year. -

Glossary of Terms — Page 1 Air Gap: See Backflow Prevention Device
Glossary of Irrigation Terms Version 7/1/17 Edited by Eugene W. Rochester, CID Certification Consultant This document is in continuing development. You are encouraged to submit definitions along with their source to [email protected]. The terms in this glossary are presented in an effort to provide a foundation for common understanding in communications covering irrigation. The following provides additional information: • Items located within brackets, [ ], indicate the IA-preferred abbreviation or acronym for the term specified. • Items located within braces, { }, indicate quantitative IA-preferred units for the term specified. • General definitions of terms not used in mathematical equations are not flagged in any way. • Three dots (…) at the end of a definition indicate that the definition has been truncated. • Terms with strike-through are non-preferred usage. • References are provided for the convenience of the reader and do not infer original reference. Additional soil science terms may be found at www.soils.org/publications/soils-glossary#. A AC {hertz}: Abbreviation for alternating current. AC pipe: Asbestos-cement pipe was commonly used for buried pipelines. It combines strength with light weight and is immune to rust and corrosion. (James, 1988) (No longer made.) acceleration of gravity. See gravity (acceleration due to). acid precipitation: Atmospheric precipitation that is below pH 7 and is often composed of the hydrolyzed by-products from oxidized halogen, nitrogen, and sulfur substances. (Glossary of Soil Science Terms, 2013) acid soil: Soil with a pH value less than 7.0. (Glossary of Soil Science Terms, 2013) adhesion: Forces of attraction between unlike molecules, e.g. water and solid. -

Trajectory Design Tools for Libration and Cis-Lunar Environments
Trajectory Design Tools for Libration and Cis-Lunar Environments David C. Folta, Cassandra M. Webster, Natasha Bosanac, Andrew Cox, Davide Guzzetti, and Kathleen C. Howell National Aeronautics and Space Administration/ Goddard Space Flight Center, Greenbelt, MD, 20771 [email protected], [email protected] School of Aeronautics and Astronautics, Purdue University, West Lafayette, IN 47907 {nbosanac,cox50,dguzzett,howell}@purdue.edu ABSTRACT science orbit. WFIRST trajectory design is based on an optimal direct-transfer trajectory to a specific Sun- Innovative trajectory design tools are required to Earth L2 quasi-halo orbit. support challenging multi-body regimes with complex dynamics, uncertain perturbations, and the integration Trajectory design in support of lunar and libration of propulsion influences. Two distinctive tools, point missions is becoming more challenging as more Adaptive Trajectory Design and the General Mission complex mission designs are envisioned. To meet Analysis Tool have been developed and certified to these greater challenges, trajectory design software provide the astrodynamics community with the ability must be developed or enhanced to incorporate to design multi-body trajectories. In this paper we improved understanding of the Sun-Earth/Moon discuss the multi-body design process and the dynamical solution space and to encompass new capabilities of both tools. Demonstrable applications to optimal methods. Thus the support community needs confirmed missions, the Lunar IceCube Cubesat lunar to improve the efficiency and expand the capabilities mission and the Wide-Field Infrared Survey Telescope of current trajectory design approaches. For example, (WFIRST) Sun-Earth L2 mission, are presented. invariant manifolds, derived from dynamical systems theory, have been applied to the trajectory design of 1. -

Spiral Trajectories in Global Optimisation of Interplanetary and Orbital Transfers Final Report
Spiral Trajectories in Global Optimisation of Interplanetary and Orbital Transfers Final Report Authors: M. Vasile, O. Schütze, O. Junge, G. Radice, M. Dellnitz Affiliation: University of Glasgow, Department of Aerospace Engineering, James Watt South Building, G12 8QQ, Glasgow,UK ESA Research Fellow/Technical Officer: Dario Izzo Contacts: Massimiliano Vasile Tel: ++44 141-330-6465 Fax: ++44-141-330-5560 e-mail: [email protected] Dario Izzo, Ph.D., MSc Tel: +31(0)71 565 3511 Fax: +31(0)71 565 8018 e-mail: [email protected] Ariadna ID: AO4919 05/4106 Study Duration: 4 months Available on the ACT website http://www.esa.int/act Contract Number: 19699/06/NL/HE Table of Contents 1 Introduction...................................... ..................... 2 1.1 StudyObjectives ................................... ................ 3 2 Trajectory Model and Problem Formulation . ................... 5 2.1 The Exponential Sinusoid ............................ ................ 6 2.2 Gravity Assist Model for the Exponential Sinusoid . ................ 7 2.3 Problem Formulation............................... ................. 7 3 ProblemAnalysis.................................... ................... 8 3.1 Search Space Structure................................ .............. 8 3.2 Upper limit on k2 ................................................... 8 3.3 Solution of Lambert’s problem with the Exponential Sinusoid ............... 12 3.4 Convergence Analysis ............................... ................ 13 4 Optimality Analysis ................................ -

Glossary of Some Terms in Dynamical Systems Theory
Glossary of Some Terms in Dynamical Systems Theory A brief and simple description of basic terms in dynamical systems theory with illustrations is given in the alphabetic order. Only those terms are described which are used actively in the book. Rigorous results and their proofs can be found in many textbooks and monographs on dynamical systems theory and Hamiltonian chaos (see, e.g., [1, 6, 15]). Bifurcations Bifurcation means a qualitative change in the topology in the phase space under varying control parameters of a dynamical system under consideration. The number of stationary points and/or their stability may change when varying the parameters. Those values of the parameters, under which bifurcations occur, are called critical or bifurcation values. There are also bifurcations without changing the number of stationary points but with topology change in the phase space. One of the examples is a separatrix reconnection when a heteroclinic connection changes to a homoclinic one or vice versa. Cantori Some invariant tori in typical unperturbed Hamiltonian systems break down under a perturbation. Suppose that an invariant torus with the frequency f breaks down at a critical value of the perturbation frequency !.Iff =! is a rational number, then a chain of resonances or islands of stability appears at its place. If f =! is an irrational number, then a cantorus appears at the place of the corresponding invariant torus. Cantorus is a Cantor-like invariant set [7, 12] the motion on which is unstable and quasiperiodic. Cantorus resembles a closed curve with an infinite number of gaps. Therefore, cantori are fractal. Since the motion on a cantorus is unstable, it has stable and unstable manifolds. -

Topic 1 | Projectile Motion with Air Resistance
Topic 1 | Projectile Motion with Air Resistance v A Case Study in Computer Analysis In our study of projectile motion, we assumed that air-resistance effects are negli- gibly small. But in fact air resistance (often called air drag, or simply drag) has a major effect on the motion of many objects, including tennis balls, bicycle riders, and airplanes. In Section 5.3 we considered how a fluid resistance force affected a body falling straight down. We’d now like to extend this analysis to a projectile moving in a plane. It’s not difficult to include the force of air resistance in the equations for a pro- jectile, but solving them for the position and velocity as functions of time, or the shape of the path, can get quite complex. Fortunately, it is fairly easy to make quite precise numerical approximations to these solutions, using a computer. That’s what this section is about. (a) When we omitted air drag, the only force acting on a projectile with mass m y was its weight wùmg. The components of the projectile’s acceleration were simply 5 52 ax 0 ay g v The +x-axis is horizontal, and the +y-axis is vertically upward. We must now include the air drag force acting on the projectile. At the speed of a tossed tennis fx ball or faster, the magnitude f of the air drag force is approximately proportional x to the square of the projectile’s speed relative to the air: fy f 5 Dv2 (T1.1) 2 = 2 + 2 where v vx vy . -
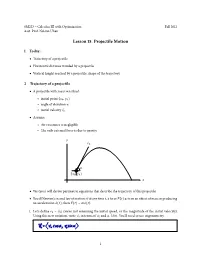
Lesson 15. Projectile Motion
SM223 – Calculus III with Optimization Fall 2012 Asst. Prof. Nelson Uhan Lesson 15. Projectile Motion 1 Today... Trajectory of a projectile ● Horizontal distance traveled by a projectile ● Vertical height reached by a projectile, shape of the trajectory ● 2 Trajectory of a projectile A projectile with mass m is %red ● initial point x0, y0 angle of elevation α ○ ( ) initial velocity v ○ 0 Assume:○ ⃗ ● Air resistance is negligible !e only external force is due to gravity ○ ○ y v0 ⃗ α x0, y0 ( ) x We (you) will derive parametric equations that describe the trajectory of this projectile ● Recall Newton’s second law of motion: if at any time t, a force F t acts on an object of mass m producing an acceleration a t , then F t ma t . ● ( ) ⃗ 1. Let’s de%ne v0 ⃗(v0) (we’re just( ) = renaming⃗( ) the initial speed, or the magnitude of the initial velocity). Using this new notation, write v0 in terms of v0 and α. Hint. You’ll need to use trigonometry. = ∣⃗ ∣ ⃗ 1 2. We need an expression for the acceleration a of the projectile. Since the only external force is due to gravity, which acts downward, we have that F t ma t 0, mg . Using this, write an expression for a t . ⃗ ⃗( ) = ⃗( ) = ⟨ − ⟩ ⃗( ) 3. Using your answer from part 2, write an expression for the velocity v t of the projectile. Hint 1. Recall that a t v t . Hint 2. Don’t forget the constant vector of integration. Hint 3. Since the ⃗( ) initial velocity is v0,wehave′ v 0 v0.