Supplemental Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Reprogramming of Trna Modifications Controls the Oxidative Stress Response by Codon-Biased Translation of Proteins
Reprogramming of tRNA modifications controls the oxidative stress response by codon-biased translation of proteins The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation Chan, Clement T.Y. et al. “Reprogramming of tRNA Modifications Controls the Oxidative Stress Response by Codon-biased Translation of Proteins.” Nature Communications 3 (2012): 937. As Published http://dx.doi.org/10.1038/ncomms1938 Publisher Nature Publishing Group Version Author's final manuscript Citable link http://hdl.handle.net/1721.1/76775 Terms of Use Article is made available in accordance with the publisher's policy and may be subject to US copyright law. Please refer to the publisher's site for terms of use. Reprogramming of tRNA modifications controls the oxidative stress response by codon-biased translation of proteins Clement T.Y. Chan,1,2 Yan Ling Joy Pang,1 Wenjun Deng,1 I. Ramesh Babu,1 Madhu Dyavaiah,3 Thomas J. Begley3 and Peter C. Dedon1,4* 1Department of Biological Engineering, 2Department of Chemistry and 4Center for Environmental Health Sciences, Massachusetts Institute of Technology, Cambridge, MA 02139; 3College of Nanoscale Science and Engineering, University at Albany, SUNY, Albany, NY 12203 * Corresponding author: PCD, Department of Biological Engineering, NE47-277, Massachusetts Institute of Technology, 77 Massachusetts Avenue, Cambridge, MA 02139; tel 617-253-8017; fax 617-324-7554; email [email protected] 2 ABSTRACT Selective translation of survival proteins is an important facet of cellular stress response. We recently demonstrated that this translational control involves a stress-specific reprogramming of modified ribonucleosides in tRNA. -

Allele-Specific Expression of Ribosomal Protein Genes in Interspecific Hybrid Catfish
Allele-specific Expression of Ribosomal Protein Genes in Interspecific Hybrid Catfish by Ailu Chen A dissertation submitted to the Graduate Faculty of Auburn University in partial fulfillment of the requirements for the Degree of Doctor of Philosophy Auburn, Alabama August 1, 2015 Keywords: catfish, interspecific hybrids, allele-specific expression, ribosomal protein Copyright 2015 by Ailu Chen Approved by Zhanjiang Liu, Chair, Professor, School of Fisheries, Aquaculture and Aquatic Sciences Nannan Liu, Professor, Entomology and Plant Pathology Eric Peatman, Associate Professor, School of Fisheries, Aquaculture and Aquatic Sciences Aaron M. Rashotte, Associate Professor, Biological Sciences Abstract Interspecific hybridization results in a vast reservoir of allelic variations, which may potentially contribute to phenotypical enhancement in the hybrids. Whether the allelic variations are related to the downstream phenotypic differences of interspecific hybrid is still an open question. The recently developed genome-wide allele-specific approaches that harness high- throughput sequencing technology allow direct quantification of allelic variations and gene expression patterns. In this work, I investigated allele-specific expression (ASE) pattern using RNA-Seq datasets generated from interspecific catfish hybrids. The objective of the study is to determine the ASE genes and pathways in which they are involved. Specifically, my study investigated ASE-SNPs, ASE-genes, parent-of-origins of ASE allele and how ASE would possibly contribute to heterosis. My data showed that ASE was operating in the interspecific catfish system. Of the 66,251 and 177,841 SNPs identified from the datasets of the liver and gill, 5,420 (8.2%) and 13,390 (7.5%) SNPs were identified as significant ASE-SNPs, respectively. -

Figure S1. Quality Control Validation of MS Data. (A‑C) Mass Error Distribution of All Peptides Identified in the Acetylome
Figure S1. Quality control validation of MS data. (A‑C) Mass error distribution of all peptides identified in the acetylome, succi- nylome and quantitative proteome, respectively. (D‑F) Length distribution of peptides identified in the acetylome, succinylome and quantitative proteome, respectively. Figure S2. Comparison of modification level between breast cancer tissue and normal tissue. Comparison of acetylation level (A) and succinylation level (B) between breast cancer tissue and normal tissue. Data are medians and were analyzed using Wilcoxon Signed Rank Test. **P<0.01. Table SI. Protein sites whose acetylation and succinylation levels were both significantly upregulated in breast cancer tissues (fold change ≥1.5 compared with normal tissues). Protein ID Protein name Modification site P54868 HMCS2 310K Q15063 POSTN 549K Q99715 COCA1 1601K P51572 BAP31 72K P07237 PDLA1 328K Q06830 PRDX1 192K P48735 IDHP 180K P30101 PDIA3 417K P0DMV9 HS71B 526K Q01995 TAGL 21K P06748 NPM1 27K Q00325 MPCP 209K P00488 F13A 69K P02545 LMNA 260K P08133 ANXA6 478K P02452 CO1A1 751K Table SII. Protein sites whose acetylation and succinylation levels were both significantly downregulated in breast cancer tissues (fold change ≥1.5 compared with normal tissues). Protein ID Protein name Modification site RET4 P02753 30K PSG2 P07585 142K HBA P69905 12K IGKC P01834 80K HBA P69905 8K Table SIII. All proteins whose expression level were significantly upregulated in breast cancer tissues (fold change ≥1.5 compared with normal tissues). Protein ID Protein description -

Functional Control of HIV-1 Post-Transcriptional Gene Expression by Host Cell Factors
Functional control of HIV-1 post-transcriptional gene expression by host cell factors DISSERTATION Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Amit Sharma, B.Tech. Graduate Program in Molecular Genetics The Ohio State University 2012 Dissertation Committee Dr. Kathleen Boris-Lawrie, Advisor Dr. Anita Hopper Dr. Karin Musier-Forsyth Dr. Stephen Osmani Copyright by Amit Sharma 2012 Abstract Retroviruses are etiological agents of several human and animal immunosuppressive disorders. They are associated with certain types of cancer and are useful tools for gene transfer applications. All retroviruses encode a single primary transcript that encodes a complex proteome. The RNA genome is reverse transcribed into DNA, integrated into the host genome, and uses host cell factors to transcribe, process and traffic transcripts that encode viral proteins and act as virion precursor RNA, which is packaged into the progeny virions. The functionality of retroviral RNA is governed by ribonucleoprotein (RNP) complexes formed by host RNA helicases and other RNA- binding proteins. The 5’ leader of retroviral RNA undergoes alternative inter- and intra- molecular RNA-RNA and RNA-protein interactions to complete multiple steps of the viral life cycle. Retroviruses do not encode any RNA helicases and are dependent on host enzymes and RNA chaperones. Several members of the host RNA helicase superfamily are necessary for progressive steps during the retroviral replication. RNA helicase A (RHA) interacts with the redundant structural elements in the 5’ untranslated region (UTR) of retroviral and selected cellular mRNAs and this interaction is necessary to facilitate polyribosome formation and productive protein synthesis. -
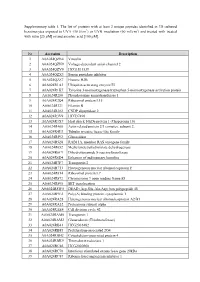
Supplementary Table 1. the List of Proteins with at Least 2 Unique
Supplementary table 1. The list of proteins with at least 2 unique peptides identified in 3D cultured keratinocytes exposed to UVA (30 J/cm2) or UVB irradiation (60 mJ/cm2) and treated with treated with rutin [25 µM] or/and ascorbic acid [100 µM]. Nr Accession Description 1 A0A024QZN4 Vinculin 2 A0A024QZN9 Voltage-dependent anion channel 2 3 A0A024QZV0 HCG1811539 4 A0A024QZX3 Serpin peptidase inhibitor 5 A0A024QZZ7 Histone H2B 6 A0A024R1A3 Ubiquitin-activating enzyme E1 7 A0A024R1K7 Tyrosine 3-monooxygenase/tryptophan 5-monooxygenase activation protein 8 A0A024R280 Phosphoserine aminotransferase 1 9 A0A024R2Q4 Ribosomal protein L15 10 A0A024R321 Filamin B 11 A0A024R382 CNDP dipeptidase 2 12 A0A024R3V9 HCG37498 13 A0A024R3X7 Heat shock 10kDa protein 1 (Chaperonin 10) 14 A0A024R408 Actin related protein 2/3 complex, subunit 2, 15 A0A024R4U3 Tubulin tyrosine ligase-like family 16 A0A024R592 Glucosidase 17 A0A024R5Z8 RAB11A, member RAS oncogene family 18 A0A024R652 Methylenetetrahydrofolate dehydrogenase 19 A0A024R6C9 Dihydrolipoamide S-succinyltransferase 20 A0A024R6D4 Enhancer of rudimentary homolog 21 A0A024R7F7 Transportin 2 22 A0A024R7T3 Heterogeneous nuclear ribonucleoprotein F 23 A0A024R814 Ribosomal protein L7 24 A0A024R872 Chromosome 9 open reading frame 88 25 A0A024R895 SET translocation 26 A0A024R8W0 DEAD (Asp-Glu-Ala-Asp) box polypeptide 48 27 A0A024R9E2 Poly(A) binding protein, cytoplasmic 1 28 A0A024RA28 Heterogeneous nuclear ribonucleoprotein A2/B1 29 A0A024RA52 Proteasome subunit alpha 30 A0A024RAE4 Cell division cycle 42 31 -

The MER41 Family of Hervs Is Uniquely Involved in the Immune-Mediated Regulation of Cognition/Behavior-Related Genes
bioRxiv preprint doi: https://doi.org/10.1101/434209; this version posted October 3, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. The MER41 family of HERVs is uniquely involved in the immune-mediated regulation of cognition/behavior-related genes: pathophysiological implications for autism spectrum disorders Serge Nataf*1, 2, 3, Juan Uriagereka4 and Antonio Benitez-Burraco 5 1CarMeN Laboratory, INSERM U1060, INRA U1397, INSA de Lyon, Lyon-Sud Faculty of Medicine, University of Lyon, Pierre-Bénite, France. 2 University of Lyon 1, Lyon, France. 3Banque de Tissus et de Cellules des Hospices Civils de Lyon, Hôpital Edouard Herriot, Lyon, France. 4Department of Linguistics and School of Languages, Literatures & Cultures, University of Maryland, College Park, USA. 5Department of Spanish, Linguistics, and Theory of Literature (Linguistics). Faculty of Philology. University of Seville, Seville, Spain * Corresponding author: [email protected] bioRxiv preprint doi: https://doi.org/10.1101/434209; this version posted October 3, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. ABSTRACT Interferon-gamma (IFNa prototypical T lymphocyte-derived pro-inflammatory cytokine, was recently shown to shape social behavior and neuronal connectivity in rodents. STAT1 (Signal Transducer And Activator Of Transcription 1) is a transcription factor (TF) crucially involved in the IFN pathway. -

Inhibition of the MID1 Protein Complex
Matthes et al. Cell Death Discovery (2018) 4:4 DOI 10.1038/s41420-017-0003-8 Cell Death Discovery ARTICLE Open Access Inhibition of the MID1 protein complex: a novel approach targeting APP protein synthesis Frank Matthes1,MoritzM.Hettich1, Judith Schilling1, Diana Flores-Dominguez1, Nelli Blank1, Thomas Wiglenda2, Alexander Buntru2,HannaWolf1, Stephanie Weber1,InaVorberg 1, Alina Dagane2, Gunnar Dittmar2,3,ErichWanker2, Dan Ehninger1 and Sybille Krauss1 Abstract Alzheimer’s disease (AD) is characterized by two neuropathological hallmarks: senile plaques, which are composed of amyloid-β (Aβ) peptides, and neurofibrillary tangles, which are composed of hyperphosphorylated tau protein. Aβ peptides are derived from sequential proteolytic cleavage of the amyloid precursor protein (APP). In this study, we identified a so far unknown mode of regulation of APP protein synthesis involving the MID1 protein complex: MID1 binds to and regulates the translation of APP mRNA. The underlying mode of action of MID1 involves the mTOR pathway. Thus, inhibition of the MID1 complex reduces the APP protein level in cultures of primary neurons. Based on this, we used one compound that we discovered previously to interfere with the MID1 complex, metformin, for in vivo experiments. Indeed, long-term treatment with metformin decreased APP protein expression levels and consequently Aβ in an AD mouse model. Importantly, we have initiated the metformin treatment late in life, at a time-point where mice were in an already progressed state of the disease, and could observe an improved behavioral phenotype. These 1234567890 1234567890 findings together with our previous observation, showing that inhibition of the MID1 complex by metformin also decreases tau phosphorylation, make the MID1 complex a particularly interesting drug target for treating AD. -

Electronic Supplementary Material (ESI) for Chemcomm. This Journal Is © the Royal Society of Chemistry 2015
Electronic Supplementary Material (ESI) for ChemComm. This journal is © The Royal Society of Chemistry 2015 tel26 Nuclear proteins identification ‐ Summary Accession Score Mass Matches tel26 Exp 1 Matches tel26 Exp 2 Protein(s) name* scr26 Exp1** scr26 Exp2** XRCC5_HUMAN 450 83222 39 49 X‐ray repair cross‐complementing protein 5 OS=Homo sapiens GN=XRCC5 PE=1 SV=3 yes yes XRCC6_HUMAN 444 70084 35 53 X‐ray repair cross‐complementing protein 6 OS=Homo sapiens GN=XRCC6 PE=1 SV=2 no no HMGB1_HUMAN 88 25049 9 25 High mobility group protein B1 OS=Homo sapiens GN=HMGB1 PE=1 SV=3 no no HMGB2_HUMAN 69 24190 4 17 High mobility group protein B2 OS=Homo sapiens GN=HMGB2 PE=1 SV=2 yes yes FUBP2_HUMAN 126 73355 9 9 Far upstream element‐binding protein 2 OS=Homo sapiens GN=KHSRP PE=1 SV=4 no no RFA1_HUMAN 67 68723 7 10 Replication protein A 70 kDa DNA‐binding subunit OS=Homo sapiens GN=RPA1 PE=1 SV=2 no no PPIA_HUMAN 95 18229 11 3 Peptidyl‐prolyl cis‐trans isomerase A OS=Homo sapiens GN=PPIA PE=1 SV=2 yes yes LMNB1_HUMAN 64 66653 6 8 Lamin‐B1 OS=Homo sapiens GN=LMNB1 PE=1 SV=2 no no ROAA_HUMAN 52 36316 3 10 Heterogeneous nuclear ribonucleoprotein A/B OS=Homo sapiens GN=HNRNPAB PE=1 SV=2 no no EHD4_HUMAN 70 61365 6 7 EH domain‐containing protein 4 OS=Homo sapiens GN=EHD4 PE=1 SV=1 no no FUBP1_HUMAN 49 67690 5 8 Far upstream element‐binding protein 1 OS=Homo sapiens GN=FUBP1 PE=1 SV=3 no yes MCM7_HUMAN 53 81884 5 7 DNA replication licensing factor MCM7 OS=Homo sapiens GN=MCM7 PE=1 SV=4 no no SEPT9_HUMAN 41 65646 3 9 Septin‐9 OS=Homo sapiens GN=SEPT9 PE=1 -

Human Social Genomics in the Multi-Ethnic Study of Atherosclerosis
Getting “Under the Skin”: Human Social Genomics in the Multi-Ethnic Study of Atherosclerosis by Kristen Monét Brown A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Epidemiological Science) in the University of Michigan 2017 Doctoral Committee: Professor Ana V. Diez-Roux, Co-Chair, Drexel University Professor Sharon R. Kardia, Co-Chair Professor Bhramar Mukherjee Assistant Professor Belinda Needham Assistant Professor Jennifer A. Smith © Kristen Monét Brown, 2017 [email protected] ORCID iD: 0000-0002-9955-0568 Dedication I dedicate this dissertation to my grandmother, Gertrude Delores Hampton. Nanny, no one wanted to see me become “Dr. Brown” more than you. I know that you are standing over the bannister of heaven smiling and beaming with pride. I love you more than my words could ever fully express. ii Acknowledgements First, I give honor to God, who is the head of my life. Truly, without Him, none of this would be possible. Countless times throughout this doctoral journey I have relied my favorite scripture, “And we know that all things work together for good, to them that love God, to them who are called according to His purpose (Romans 8:28).” Secondly, I acknowledge my parents, James and Marilyn Brown. From an early age, you two instilled in me the value of education and have been my biggest cheerleaders throughout my entire life. I thank you for your unconditional love, encouragement, sacrifices, and support. I would not be here today without you. I truly thank God that out of the all of the people in the world that He could have chosen to be my parents, that He chose the two of you. -

DEAH)/RNA Helicase a Helicases Sense Microbial DNA in Human Plasmacytoid Dendritic Cells
Aspartate-glutamate-alanine-histidine box motif (DEAH)/RNA helicase A helicases sense microbial DNA in human plasmacytoid dendritic cells Taeil Kima, Shwetha Pazhoora, Musheng Baoa, Zhiqiang Zhanga, Shino Hanabuchia, Valeria Facchinettia, Laura Bovera, Joel Plumasb, Laurence Chaperotb, Jun Qinc, and Yong-Jun Liua,1 aDepartment of Immunology, Center for Cancer Immunology Research, University of Texas M. D. Anderson Cancer Center, Houston, TX 77030; bDepartment of Research and Development, Etablissement Français du Sang Rhône-Alpes Grenoble, 38701 La Tronche, France; and cDepartment of Biochemistry, Baylor College of Medicine, Houston, TX 77030 Edited by Ralph M. Steinman, The Rockefeller University, New York, NY, and approved July 14, 2010 (received for review May 10, 2010) Toll-like receptor 9 (TLR9) senses microbial DNA and triggers type I Microbial nucleic acids, including their genomic DNA/RNA IFN responses in plasmacytoid dendritic cells (pDCs). Previous and replicating intermediates, work as strong PAMPs (13), so studies suggest the presence of myeloid differentiation primary finding PRR-sensing pathogenic nucleic acids and investigating response gene 88 (MyD88)-dependent DNA sensors other than their signaling pathway is of general interest. Cytosolic RNA is TLR9 in pDCs. Using MS, we investigated C-phosphate-G (CpG)- recognized by RLRs, including RIG-I, melanoma differentiation- binding proteins from human pDCs, pDC-cell lines, and interferon associated gene 5 (MDA5), and laboratory of genetics and physi- regulatory factor 7 (IRF7)-expressing B-cell lines. CpG-A selectively ology 2 (LGP2). RIG-I senses 5′-triphosphate dsRNA and ssRNA bound the aspartate-glutamate-any amino acid-aspartate/histi- or short dsRNA with blunt ends. -

Integrative Analysis of Disease Signatures Shows Inflammation Disrupts Juvenile Experience-Dependent Cortical Plasticity
New Research Development Integrative Analysis of Disease Signatures Shows Inflammation Disrupts Juvenile Experience- Dependent Cortical Plasticity Milo R. Smith1,2,3,4,5,6,7,8, Poromendro Burman1,3,4,5,8, Masato Sadahiro1,3,4,5,6,8, Brian A. Kidd,2,7 Joel T. Dudley,2,7 and Hirofumi Morishita1,3,4,5,8 DOI:http://dx.doi.org/10.1523/ENEURO.0240-16.2016 1Department of Neuroscience, Icahn School of Medicine at Mount Sinai, New York, New York 10029, 2Department of Genetics and Genomic Sciences, Icahn School of Medicine at Mount Sinai, New York, New York 10029, 3Department of Psychiatry, Icahn School of Medicine at Mount Sinai, New York, New York 10029, 4Department of Ophthalmology, Icahn School of Medicine at Mount Sinai, New York, New York 10029, 5Mindich Child Health and Development Institute, Icahn School of Medicine at Mount Sinai, New York, New York 10029, 6Graduate School of Biomedical Sciences, Icahn School of Medicine at Mount Sinai, New York, New York 10029, 7Icahn Institute for Genomics and Multiscale Biology, Icahn School of Medicine at Mount Sinai, New York, New York 10029, and 8Friedman Brain Institute, Icahn School of Medicine at Mount Sinai, New York, New York 10029 Visual Abstract Throughout childhood and adolescence, periods of heightened neuroplasticity are critical for the development of healthy brain function and behavior. Given the high prevalence of neurodevelopmental disorders, such as autism, identifying disruptors of developmental plasticity represents an essential step for developing strategies for prevention and intervention. Applying a novel computational approach that systematically assessed connections between 436 transcriptional signatures of disease and multiple signatures of neuroplasticity, we identified inflammation as a common pathological process central to a diverse set of diseases predicted to dysregulate Significance Statement During childhood and adolescence, heightened neuroplasticity allows the brain to reorganize and adapt to its environment. -

Downregulation of Carnitine Acyl-Carnitine Translocase by Mirnas
Page 1 of 288 Diabetes 1 Downregulation of Carnitine acyl-carnitine translocase by miRNAs 132 and 212 amplifies glucose-stimulated insulin secretion Mufaddal S. Soni1, Mary E. Rabaglia1, Sushant Bhatnagar1, Jin Shang2, Olga Ilkayeva3, Randall Mynatt4, Yun-Ping Zhou2, Eric E. Schadt6, Nancy A.Thornberry2, Deborah M. Muoio5, Mark P. Keller1 and Alan D. Attie1 From the 1Department of Biochemistry, University of Wisconsin, Madison, Wisconsin; 2Department of Metabolic Disorders-Diabetes, Merck Research Laboratories, Rahway, New Jersey; 3Sarah W. Stedman Nutrition and Metabolism Center, Duke Institute of Molecular Physiology, 5Departments of Medicine and Pharmacology and Cancer Biology, Durham, North Carolina. 4Pennington Biomedical Research Center, Louisiana State University system, Baton Rouge, Louisiana; 6Institute for Genomics and Multiscale Biology, Mount Sinai School of Medicine, New York, New York. Corresponding author Alan D. Attie, 543A Biochemistry Addition, 433 Babcock Drive, Department of Biochemistry, University of Wisconsin-Madison, Madison, Wisconsin, (608) 262-1372 (Ph), (608) 263-9608 (fax), [email protected]. Running Title: Fatty acyl-carnitines enhance insulin secretion Abstract word count: 163 Main text Word count: 3960 Number of tables: 0 Number of figures: 5 Diabetes Publish Ahead of Print, published online June 26, 2014 Diabetes Page 2 of 288 2 ABSTRACT We previously demonstrated that micro-RNAs 132 and 212 are differentially upregulated in response to obesity in two mouse strains that differ in their susceptibility to obesity-induced diabetes. Here we show the overexpression of micro-RNAs 132 and 212 enhances insulin secretion (IS) in response to glucose and other secretagogues including non-fuel stimuli. We determined that carnitine acyl-carnitine translocase (CACT, Slc25a20) is a direct target of these miRNAs.