Transcriptional Effects of Copy Number Alterations in a Large Set of Human Cancers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
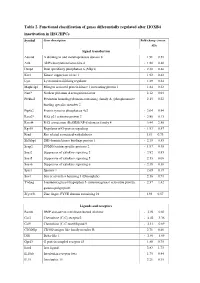
Table 2. Functional Classification of Genes Differentially Regulated After HOXB4 Inactivation in HSC/Hpcs
Table 2. Functional classification of genes differentially regulated after HOXB4 inactivation in HSC/HPCs Symbol Gene description Fold-change (mean ± SD) Signal transduction Adam8 A disintegrin and metalloprotease domain 8 1.91 ± 0.51 Arl4 ADP-ribosylation factor-like 4 - 1.80 ± 0.40 Dusp6 Dual specificity phosphatase 6 (Mkp3) - 2.30 ± 0.46 Ksr1 Kinase suppressor of ras 1 1.92 ± 0.42 Lyst Lysosomal trafficking regulator 1.89 ± 0.34 Mapk1ip1 Mitogen activated protein kinase 1 interacting protein 1 1.84 ± 0.22 Narf* Nuclear prelamin A recognition factor 2.12 ± 0.04 Plekha2 Pleckstrin homology domain-containing. family A. (phosphoinosite 2.15 ± 0.22 binding specific) member 2 Ptp4a2 Protein tyrosine phosphatase 4a2 - 2.04 ± 0.94 Rasa2* RAS p21 activator protein 2 - 2.80 ± 0.13 Rassf4 RAS association (RalGDS/AF-6) domain family 4 3.44 ± 2.56 Rgs18 Regulator of G-protein signaling - 1.93 ± 0.57 Rrad Ras-related associated with diabetes 1.81 ± 0.73 Sh3kbp1 SH3 domain kinase bindings protein 1 - 2.19 ± 0.53 Senp2 SUMO/sentrin specific protease 2 - 1.97 ± 0.49 Socs2 Suppressor of cytokine signaling 2 - 2.82 ± 0.85 Socs5 Suppressor of cytokine signaling 5 2.13 ± 0.08 Socs6 Suppressor of cytokine signaling 6 - 2.18 ± 0.38 Spry1 Sprouty 1 - 2.69 ± 0.19 Sos1 Son of sevenless homolog 1 (Drosophila) 2.16 ± 0.71 Ywhag 3-monooxygenase/tryptophan 5- monooxygenase activation protein. - 2.37 ± 1.42 gamma polypeptide Zfyve21 Zinc finger. FYVE domain containing 21 1.93 ± 0.57 Ligands and receptors Bambi BMP and activin membrane-bound inhibitor - 2.94 ± 0.62 -

Fish and Shellfish Immunology 95 (2019) 538–545
Fish and Shellfish Immunology 95 (2019) 538–545 Contents lists available at ScienceDirect Fish and Shellfish Immunology journal homepage: www.elsevier.com/locate/fsi Full length article Congenital asplenia due to a tlx1 mutation reduces resistance to Aeromonas T hydrophila infection in zebrafish ∗ Lang Xiea,b, Yixi Taoa,b, Ronghua Wua,b, Qin Yec, Hao Xua,b, Yun Lia,b, a Institute of Three Gorges Ecological Fisheries of Chongqing, College of Animal Science and Technology, Southwest University, Chongqing, 400715, China b Key Laboratory of Freshwater Fish Reproduction and Development (Ministry of Education), Key Laboratory of Aquatic Science of Chongqing, Southwest University, Chongqing, 400715, China c School of Chemistry and Chemical Engineering, Southwest University, Chongqing, 400715, China ARTICLE INFO ABSTRACT Keywords: It is documented that tlx1, an orphan homeobox gene, plays critical roles in the regulation of early spleen tlx1 knock-out developmental in mammalian species. However, there is no direct evidence supporting the functions of tlx1 in Congenital asplenia non-mammalian species, especially in fish. In this study, we demonstrated that tlx1 is expressed in the splenic Aeromonas hydrophila primordia as early as 52 hours post-fertilization (hpf) in zebrafish. A tlx1−/− homozygous mutant line was Disease resistance generated via CRISPR/Cas9 to elucidate the roles of tlx1 in spleen development in zebrafish. In the tlx1−/− background, tlx1−/− cells persisted in the splenic primordia until 52 hpf but were no longer detectable after 53 hpf, suggesting perturbation of early spleen development. The zebrafish also exhibited congenital asplenia caused by the tlx1 mutation. Asplenic zebrafish can survive and breed normally under standard laboratory conditions, but the survival rate of animals infected with Aeromonas hydrophila was significantly lower than that of wild-type (WT) zebrafish. -

TRANSCRIPTIONAL REGULATION of Hur in RENAL STRESS
TRANSCRIPTIONAL REGULATION OF HuR IN RENAL STRESS DISSERTATION Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Sudha Suman Govindaraju Graduate Program in Biochemistry The Ohio State University 2014 Dissertation Committee: Dr. Beth S. Lee, Ph.D., Advisor Dr. Kathleen Boris-Lawrie, Ph.D. Dr. Sissy M. Jhiang, Ph.D. Dr. Arthur R. Strauch, Ph.D Abstract HuR is a ubiquitously expressed RNA-binding protein that affects the post- transcriptional life of thousands of cellular mRNAs by regulating transcript stability and translation. HuR can post-transcriptionally regulate gene expression and modulate cellular responses to stress, differentiation, proliferation, apoptosis, senescence, inflammation, and the immune response. It is an important mediator of survival during cellular stress, but when inappropriately expressed, can promote oncogenic transformation. Not surprisingly, the expression of HuR itself is tightly regulated at multiple transcriptional and post-transcriptional levels. Previous studies demonstrated the existence of two alternate HuR transcripts that differ in their 5’ untranslated regions and have markedly different translatabilities. These forms were also found to be reciprocally expressed following cellular stress in kidney proximal tubule cell lines, and the shorter, more readily translatable variant was shown to be regulated by Smad 1/5/8 pathway and bone morphogenetic protein-7 (BMP-7) signaling. In this study, the factors that promote transcription of the longer alternate form were identified. NF-κB was shown to be important for expression of the long HuR mRNA, as was a newly identified region with potential for binding the Sp/KLF families of transcription factors. -

Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model
Downloaded from http://www.jimmunol.org/ by guest on September 25, 2021 T + is online at: average * The Journal of Immunology , 34 of which you can access for free at: 2016; 197:1477-1488; Prepublished online 1 July from submission to initial decision 4 weeks from acceptance to publication 2016; doi: 10.4049/jimmunol.1600589 http://www.jimmunol.org/content/197/4/1477 Molecular Profile of Tumor-Specific CD8 Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. Waugh, Sonia M. Leach, Brandon L. Moore, Tullia C. Bruno, Jonathan D. Buhrman and Jill E. Slansky J Immunol cites 95 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html http://www.jimmunol.org/content/suppl/2016/07/01/jimmunol.160058 9.DCSupplemental This article http://www.jimmunol.org/content/197/4/1477.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 25, 2021. The Journal of Immunology Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. -

Onc2010217.Pdf
Oncogene (2010) 29, 4671–4681 & 2010 Macmillan Publishers Limited All rights reserved 0950-9232/10 www.nature.com/onc ORIGINAL ARTICLE DEK oncoprotein regulates transcriptional modifiers and sustains tumor initiation activity in high-grade neuroendocrine carcinoma of the lung T Shibata1,2, A Kokubu1, M Miyamoto1, F Hosoda1, M Gotoh2, K Tsuta3, H Asamura4, Y Matsuno5, T Kondo6, I Imoto7,8, J Inazawa7,8 and S Hirohashi1,2 1Cancer Genomics Project, National Cancer Center Research Institute, Chuo-ku, Tokyo, Japan; 2Pathology Division, National Cancer Center Research Institute, Chuo-ku, Tokyo, Japan; 3Clinical Laboratory Division, National Cancer Center Hospital, Chuo-ku, Tokyo, Japan; 4Division of Thoracic Surgery, National Cancer Center Hospital, Chuo-ku, Tokyo, Japan; 5Department of Surgical Pathology, Hokkaido University Hospital, Sapporo, Hokkaido, Japan; 6Proteome Bioinfomatics Project, National Cancer Center Research Institute, Chuo-ku, Tokyo, Japan; 7Department of Molecular Cytogenetics, Medical Research Institute and Graduate School of Biomedical Science, Tokyo Medical and Dental University, Tokyo, Japan and 8Center of Excellence Program for Frontier Research on Molecular Destruction and Reconstitution of Tooth and Bone, Tokyo Medical and Dental University, Tokyo, Japan Lung cancer shows diverse histological subtypes. Large- Introduction cell neuroendocrine cell carcinoma and small-cell lung carcinoma show similar histological features and clinical Lung cancer is one of the most prevalent cancers behaviors, and can be classified as high-grade neuro- worldwide, and shows diverse histological subtypes, endocrine carcinoma (HGNEC) of the lung. Here we including adenocarcinoma, squamous cell carcinoma, elucidated the molecular classification of pulmonary large-cell carcinoma, large-cell neuroendocrine carcino- endocrine tumors by copy-number profiling. We compared ma (LCNEC) and small-cell lung carcinoma (SCLC; alterations of copy number with the clinical outcome of Travis and Brambilla, 2004). -

High-Resolution Analysis of Chromosomal Breakpoints and Genomic Instability Identifies PTPRD As a Candidate Tumor Suppressor Gene in Neuroblastoma
Research Article High-Resolution Analysis of Chromosomal Breakpoints and Genomic Instability Identifies PTPRD as a Candidate Tumor Suppressor Gene in Neuroblastoma Raymond L. Stallings,1 Prakash Nair,1 John M. Maris,2 Daniel Catchpoole,3 Michael McDermott,4 Anne O’Meara,5 and Fin Breatnach5 1Children’s Cancer Research Institute and Department of Pediatrics, University of Texas Health Science Center at San Antonio, San Antonio, Texas; 2Division of Oncology, Children’s Hospital of Philadelphia and Department of Pediatrics, University of Pennsylvania School of Medicine, Philadelphia, Pennsylvania; 3The Tumor Bank, Children’s Hospital at Westmead, Sydney, New South Wales, Australia; and Departments of 4Pathology and 5Oncology, Our Lady’s Hospital for Sick Children, Dublin, Ireland Abstract and death from disease. Patient age, tumor stage, and several Although neuroblastoma is characterized by numerous different genetic abnormalities are important factors that influence clinical outcome. Loss of 1p and 11q, gain of 17q, and amplification recurrent, large-scale chromosomal imbalances, the genes MYCN targeted by such imbalances have remained elusive. We have of the oncogene are particularly strong genetic indicators of poor disease outcome (2–5). Two of these abnormalities, loss of 11q applied whole-genome oligonucleotide array comparative MYCN genomic hybridization (median probe spacing 6 kb) to 56 and amplification, form the basis for dividing advanced- stage neuroblastomas into genetic subtypes due to their rather neuroblastoma tumors and cell lines to identify genes involved with disease pathogenesis. This set oftumors was selected for striking inverse distribution in tumors (6, 7). Many other recurrent having either 11q loss or MYCN amplification, abnormalities partial chromosomal imbalances, including loss of 3p, 4p, 9p, and that define the two most common genetic subtypes of 14q and gain of 1q, 2p, 7q, and 11p, have been identified by metastatic neuroblastoma. -

1714 Gene Comprehensive Cancer Panel Enriched for Clinically Actionable Genes with Additional Biologically Relevant Genes 400-500X Average Coverage on Tumor
xO GENE PANEL 1714 gene comprehensive cancer panel enriched for clinically actionable genes with additional biologically relevant genes 400-500x average coverage on tumor Genes A-C Genes D-F Genes G-I Genes J-L AATK ATAD2B BTG1 CDH7 CREM DACH1 EPHA1 FES G6PC3 HGF IL18RAP JADE1 LMO1 ABCA1 ATF1 BTG2 CDK1 CRHR1 DACH2 EPHA2 FEV G6PD HIF1A IL1R1 JAK1 LMO2 ABCB1 ATM BTG3 CDK10 CRK DAXX EPHA3 FGF1 GAB1 HIF1AN IL1R2 JAK2 LMO7 ABCB11 ATR BTK CDK11A CRKL DBH EPHA4 FGF10 GAB2 HIST1H1E IL1RAP JAK3 LMTK2 ABCB4 ATRX BTRC CDK11B CRLF2 DCC EPHA5 FGF11 GABPA HIST1H3B IL20RA JARID2 LMTK3 ABCC1 AURKA BUB1 CDK12 CRTC1 DCUN1D1 EPHA6 FGF12 GALNT12 HIST1H4E IL20RB JAZF1 LPHN2 ABCC2 AURKB BUB1B CDK13 CRTC2 DCUN1D2 EPHA7 FGF13 GATA1 HLA-A IL21R JMJD1C LPHN3 ABCG1 AURKC BUB3 CDK14 CRTC3 DDB2 EPHA8 FGF14 GATA2 HLA-B IL22RA1 JMJD4 LPP ABCG2 AXIN1 C11orf30 CDK15 CSF1 DDIT3 EPHB1 FGF16 GATA3 HLF IL22RA2 JMJD6 LRP1B ABI1 AXIN2 CACNA1C CDK16 CSF1R DDR1 EPHB2 FGF17 GATA5 HLTF IL23R JMJD7 LRP5 ABL1 AXL CACNA1S CDK17 CSF2RA DDR2 EPHB3 FGF18 GATA6 HMGA1 IL2RA JMJD8 LRP6 ABL2 B2M CACNB2 CDK18 CSF2RB DDX3X EPHB4 FGF19 GDNF HMGA2 IL2RB JUN LRRK2 ACE BABAM1 CADM2 CDK19 CSF3R DDX5 EPHB6 FGF2 GFI1 HMGCR IL2RG JUNB LSM1 ACSL6 BACH1 CALR CDK2 CSK DDX6 EPOR FGF20 GFI1B HNF1A IL3 JUND LTK ACTA2 BACH2 CAMTA1 CDK20 CSNK1D DEK ERBB2 FGF21 GFRA4 HNF1B IL3RA JUP LYL1 ACTC1 BAG4 CAPRIN2 CDK3 CSNK1E DHFR ERBB3 FGF22 GGCX HNRNPA3 IL4R KAT2A LYN ACVR1 BAI3 CARD10 CDK4 CTCF DHH ERBB4 FGF23 GHR HOXA10 IL5RA KAT2B LZTR1 ACVR1B BAP1 CARD11 CDK5 CTCFL DIAPH1 ERCC1 FGF3 GID4 HOXA11 IL6R KAT5 ACVR2A -

Novel and Highly Recurrent Chromosomal Alterations in Se´Zary Syndrome
Research Article Novel and Highly Recurrent Chromosomal Alterations in Se´zary Syndrome Maarten H. Vermeer,1 Remco van Doorn,1 Remco Dijkman,1 Xin Mao,3 Sean Whittaker,3 Pieter C. van Voorst Vader,4 Marie-Jeanne P. Gerritsen,5 Marie-Louise Geerts,6 Sylke Gellrich,7 Ola So¨derberg,8 Karl-Johan Leuchowius,8 Ulf Landegren,8 Jacoba J. Out-Luiting,1 Jeroen Knijnenburg,2 Marije IJszenga,2 Karoly Szuhai,2 Rein Willemze,1 and Cornelis P. Tensen1 Departments of 1Dermatology and 2Molecular Cell Biology, Leiden University Medical Center, Leiden, the Netherlands; 3Department of Dermatology, St Thomas’ Hospital, King’s College, London, United Kingdom; 4Department of Dermatology, University Medical Center Groningen, Groningen, the Netherlands; 5Department of Dermatology, Radboud University Nijmegen Medical Center, Nijmegen, the Netherlands; 6Department of Dermatology, Gent University Hospital, Gent, Belgium; 7Department of Dermatology, Charite, Berlin, Germany; and 8Department of Genetics and Pathology, Rudbeck Laboratory, University of Uppsala, Uppsala, Sweden Abstract Introduction This study was designed to identify highly recurrent genetic Se´zary syndrome (Sz) is an aggressive type of cutaneous T-cell alterations typical of Se´zary syndrome (Sz), an aggressive lymphoma/leukemia of skin-homing, CD4+ memory T cells and is cutaneous T-cell lymphoma/leukemia, possibly revealing characterized by erythroderma, generalized lymphadenopathy, and pathogenetic mechanisms and novel therapeutic targets. the presence of neoplastic T cells (Se´zary cells) in the skin, lymph High-resolution array-based comparative genomic hybridiza- nodes, and peripheral blood (1). Sz has a poor prognosis, with a tion was done on malignant T cells from 20 patients. disease-specific 5-year survival of f24% (1). -

Identification of Novel Mouse Delta1 Target Genes: Combination of Transcriptomics and Proteomics
Institut für Experimentelle Genetik GSF – Forschungszentrum für Umwelt und Gesundheit Identification of novel mouse Delta1 target genes: Combination of transcriptomics and proteomics Christine Hutterer Vollständiger Abdruck der von der Fakultät Wissenschaftszentrum Weihenstephan für Ernährung, Landnutzung und Umwelt der Technischen Universität München zur Erlangung des akademischen Grades eines Doktors der Naturwissenschaften genehmigten Dissertation. Vorsitzender: Univ.-Prof. Dr. A. Gierl Prüfer der Dissertation: 1. apl. Prof. Dr. J. Adamski 2. Univ.-Prof. Dr. W. Wurst Die Dissertation wurde am 31.01.2005 bei der Technischen Universität München eingereicht und durch die Fakultät Wissenschaftszentrum Weihenstephan für Ernährung, Landnutzung und Umwelt am 13.05.2005 angenommen. DANKSAGUNG Besonderer Dank gebührt Prof. Dr. Martin Hrabé de Angelis, Leiter des Instituts für experimentelle Genetik. Unter anderem durch seine Leidenschaft für die Wissenschaft wollte ich am IEG arbeiten. Ich möchte mich jedoch nicht nur für die wissenschaftlichen Ratschläge und Diskussionen bedanken, sondern auch für viele interessante nicht-wissenschaftliche Gespräche. Ebenfalls besonders bedanke ich mich bei meinem Doktorvater Dr. Jurek Adamski, dessen fachliche Meinung und positive Einstellung mich sehr motivierte. Großen Dank möchte ich der gesamten „Beckers-Arbeitsgruppe“ aussprechen. Allen voran Dr. Johannes Beckers, Leiter der Genregulation und Expression Profiling Arbeitsgruppe, für die Überlassung des Themas und die Betreuung meiner Doktorarbeit, die mir viel Entscheidungsfreiraum ließ, sowie für zahlreiche gute Ideen und lehrreiche Gespräche. Bei Tomek Mijalski möchte ich mich für seine stetige Hilfsbereitschaft und die entstandene Freundschaft besonders bedanken. Weiterhin bedanke ich mich ganz herzlich bei Dr. Sonja Becker für wertvolle Labortricks und Kniffe, die Durchsicht des Manuskripts und ihre herzliche Art. Vielen Dank an dieser Stelle auch an Kathrin Seidel für die gute technische Unterstützung im Labor und mit der Mausarbeit. -

Directing an Artificial Zinc Finger Protein to New Targets by Fusion to a Non-DNA Binding Domain
Directing an artificial zinc finger protein to new targets by fusion to a non-DNA binding domain Wooi Fang (Catheryn) Lim A thesis in fulfilment of the requirements for the degree of Doctor of Philosophy School of Biotechnology and Biomolecular Sciences Faculty of Science March 2016 Page | 0 THESIS/ DISSERTATION SHEET Page | i ORIGINALITY STATEMENT ‘I hereby declare that this submission is my own work and to the best of my knowledge it contains no materials previously published or written by another person, or substantial proportions of material which have been accepted for the award of any other degree or diploma at UNSW or any other educational institution, except where due acknowledgement is made in the thesis. Any contribution made to the research by others, with whom I have worked at UNSW or elsewhere, is explicitly acknowledged in the thesis. I also declare that the intellectual content of this thesis is the product of my own work, except to the extent that assistance from others in the project's design and conception or in style, presentation and linguistic expression is acknowledged.’ WOOI FANG LIM Signed …………………………………………….............. 31-03-2016 Date …………………………………………….............. Page | i COPYRIGHT STATEMENT ‘I hereby grant the University of New South Wales or its agents the right to archive and to make available my thesis or dissertation in whole or part in the University libraries in all forms of media, now or here after known, subject to the provisions of the Copyright Act 1968. I retain all proprietary rights, such as patent rights. I also retain the right to use in future works (such as articles or books) all or part of this thesis or dissertation. -

Genome-Wide Analysis Identifies Rag1 and Rag2 As Novel Notch1
fcell-09-703338 July 7, 2021 Time: 18:5 # 1 ORIGINAL RESEARCH published: 12 July 2021 doi: 10.3389/fcell.2021.703338 Genome-Wide Analysis Identifies Rag1 and Rag2 as Novel Notch1 Transcriptional Targets in Thymocytes Yang Dong1,2†, Hao Guo1,2†, Donghai Wang2, Rongfu Tu2, Guoliang Qing2* and Hudan Liu1,2* 1 Department of Hematology, Zhongnan Hospital of Wuhan University, Wuhan, China, 2 Frontier Science Center for Immunology and Metabolism, Medical Research Institute, Wuhan University, Wuhan, China Recombination activating genes 1 (Rag1) and Rag2 are expressed in immature lymphocytes and essential for generating the vast repertoire of antigen receptors. Yet, the mechanisms governing the transcription of Rag1 and Rag2 remain to be Edited by: Binghui Li, fully determined, particularly in thymocytes. Combining cDNA microarray and ChIP- Capital Medical University, China seq analysis, we identify Rag1 and Rag2 as novel Notch1 transcriptional targets in Reviewed by: acute T-cell lymphoblastic leukemia (T-ALL) cells. We further demonstrate that Notch1 Bo Li, Sun Yat-sen University, China transcriptional complexes directly bind the Rag1 and Rag2 locus in not only T-ALL Peng Li, but also primary double negative (DN) T-cell progenitors. Specifically, dimeric Notch1 Guangzhou Institutes of Biomedicine transcriptional complexes activate Rag1 and Rag2 through a novel cis-element bearing and Health, Chinese Academy of Sciences (CAS), China a sequence-paired site (SPS). In T-ALL and DN cells, dimerization-defective Notch1 *Correspondence: causes compromised Rag1 and Rag2 expression; conversely, dimerization-competent Guoliang Qing Notch1 achieves optimal upregulation of both. Collectively, these results reveal Notch1 [email protected] Hudan Liu dimerization-mediated transcription as one of the mechanisms for activating Rag1 and [email protected] Rag2 expression in both primary and transformed thymocytes. -

(DN2MT) Progenitor Is a Target Cell for Leukemic Transformation by The
Zweier-Renn et al., J Bone Marrow Res 2013, 1:1 Journal of Bone Marrow Research http://dx.doi.org/10.4172/jbmr.1000105 Research Article Open Access The DN2 Myeloid-T (DN2MT) Progenitor is a Target Cell for Leukemic Transformation by the TLX1 Oncogene Lynnsey A Zweier-Renn1,2, Irene Riz1, Teresa S Hawley3 and Robert G Hawley1,4* 1Department of Anatomy and Regenerative Biology, George Washington University, Washington, DC, USA 2Graduate Program in Biochemistry and Molecular Genetics, George Washington University, Washington, DC, USA 3Flow Cytometry Core Facility, George Washington University, Washington, DC, USA 4Sino-US Joint Laboratory of Translational Medicine, Jining Medical University Affiliated Hospital, Jining Medical University, Jining, Shandong, China Abstract Introduction: Inappropriate activation of the TLX1 (T-cell leukemia homeobox 1) gene by chromosomal translocation is a recurrent event in human T-cell Acute Lymphoblastic Leukemia (T-ALL). Ectopic expression of TLX1 in murine bone marrow progenitor cells using a conventional retroviral vector efficiently yields immortalized cell lines and induces T-ALL-like tumors in mice after long latency. Methods: To eliminate a potential contribution of retroviral insertional mutagenesis to TLX1 immortalizing and transforming function, we incorporated the TLX1 gene into an insulated self-inactivating retroviral vector. Results: Retrovirally transduced TLX1-expressing murine bone marrow progenitor cells had a growth/survival advantage and readily gave rise to immortalized cell lines. Extensive characterization of 15 newly established cell lines failed to reveal a common retroviral integration site. This comprehensive analysis greatly extends our previous study involving a limited number of cell lines, providing additional support for the view that constitutive TLX1 expression is sufficient to initiate the series of events culminating in hematopoietic progenitor cell immortalization.