Directing an Artificial Zinc Finger Protein to New Targets by Fusion to a Non-DNA Binding Domain
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
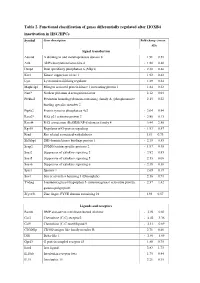
Table 2. Functional Classification of Genes Differentially Regulated After HOXB4 Inactivation in HSC/Hpcs
Table 2. Functional classification of genes differentially regulated after HOXB4 inactivation in HSC/HPCs Symbol Gene description Fold-change (mean ± SD) Signal transduction Adam8 A disintegrin and metalloprotease domain 8 1.91 ± 0.51 Arl4 ADP-ribosylation factor-like 4 - 1.80 ± 0.40 Dusp6 Dual specificity phosphatase 6 (Mkp3) - 2.30 ± 0.46 Ksr1 Kinase suppressor of ras 1 1.92 ± 0.42 Lyst Lysosomal trafficking regulator 1.89 ± 0.34 Mapk1ip1 Mitogen activated protein kinase 1 interacting protein 1 1.84 ± 0.22 Narf* Nuclear prelamin A recognition factor 2.12 ± 0.04 Plekha2 Pleckstrin homology domain-containing. family A. (phosphoinosite 2.15 ± 0.22 binding specific) member 2 Ptp4a2 Protein tyrosine phosphatase 4a2 - 2.04 ± 0.94 Rasa2* RAS p21 activator protein 2 - 2.80 ± 0.13 Rassf4 RAS association (RalGDS/AF-6) domain family 4 3.44 ± 2.56 Rgs18 Regulator of G-protein signaling - 1.93 ± 0.57 Rrad Ras-related associated with diabetes 1.81 ± 0.73 Sh3kbp1 SH3 domain kinase bindings protein 1 - 2.19 ± 0.53 Senp2 SUMO/sentrin specific protease 2 - 1.97 ± 0.49 Socs2 Suppressor of cytokine signaling 2 - 2.82 ± 0.85 Socs5 Suppressor of cytokine signaling 5 2.13 ± 0.08 Socs6 Suppressor of cytokine signaling 6 - 2.18 ± 0.38 Spry1 Sprouty 1 - 2.69 ± 0.19 Sos1 Son of sevenless homolog 1 (Drosophila) 2.16 ± 0.71 Ywhag 3-monooxygenase/tryptophan 5- monooxygenase activation protein. - 2.37 ± 1.42 gamma polypeptide Zfyve21 Zinc finger. FYVE domain containing 21 1.93 ± 0.57 Ligands and receptors Bambi BMP and activin membrane-bound inhibitor - 2.94 ± 0.62 -

TRANSCRIPTIONAL REGULATION of Hur in RENAL STRESS
TRANSCRIPTIONAL REGULATION OF HuR IN RENAL STRESS DISSERTATION Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Sudha Suman Govindaraju Graduate Program in Biochemistry The Ohio State University 2014 Dissertation Committee: Dr. Beth S. Lee, Ph.D., Advisor Dr. Kathleen Boris-Lawrie, Ph.D. Dr. Sissy M. Jhiang, Ph.D. Dr. Arthur R. Strauch, Ph.D Abstract HuR is a ubiquitously expressed RNA-binding protein that affects the post- transcriptional life of thousands of cellular mRNAs by regulating transcript stability and translation. HuR can post-transcriptionally regulate gene expression and modulate cellular responses to stress, differentiation, proliferation, apoptosis, senescence, inflammation, and the immune response. It is an important mediator of survival during cellular stress, but when inappropriately expressed, can promote oncogenic transformation. Not surprisingly, the expression of HuR itself is tightly regulated at multiple transcriptional and post-transcriptional levels. Previous studies demonstrated the existence of two alternate HuR transcripts that differ in their 5’ untranslated regions and have markedly different translatabilities. These forms were also found to be reciprocally expressed following cellular stress in kidney proximal tubule cell lines, and the shorter, more readily translatable variant was shown to be regulated by Smad 1/5/8 pathway and bone morphogenetic protein-7 (BMP-7) signaling. In this study, the factors that promote transcription of the longer alternate form were identified. NF-κB was shown to be important for expression of the long HuR mRNA, as was a newly identified region with potential for binding the Sp/KLF families of transcription factors. -

Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model
Downloaded from http://www.jimmunol.org/ by guest on September 25, 2021 T + is online at: average * The Journal of Immunology , 34 of which you can access for free at: 2016; 197:1477-1488; Prepublished online 1 July from submission to initial decision 4 weeks from acceptance to publication 2016; doi: 10.4049/jimmunol.1600589 http://www.jimmunol.org/content/197/4/1477 Molecular Profile of Tumor-Specific CD8 Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. Waugh, Sonia M. Leach, Brandon L. Moore, Tullia C. Bruno, Jonathan D. Buhrman and Jill E. Slansky J Immunol cites 95 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html http://www.jimmunol.org/content/suppl/2016/07/01/jimmunol.160058 9.DCSupplemental This article http://www.jimmunol.org/content/197/4/1477.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 25, 2021. The Journal of Immunology Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. -

Human Transcription Factor Protein-Protein Interactions in Health and Disease
HELKA GÖÖS GÖÖS HELKA Recent Publications in this Series 45/2019 Mgbeahuruike Eunice Ego Evaluation of the Medicinal Uses and Antimicrobial Activity of Piper guineense (Schumach & Thonn) 46/2019 Suvi Koskinen AND DISEASE IN HEALTH INTERACTIONS PROTEIN-PROTEIN FACTOR HUMAN TRANSCRIPTION Near-Occlusive Atherosclerotic Carotid Artery Disease: Study with Computed Tomography Angiography 47/2019 Flavia Fontana DISSERTATIONES SCHOLAE DOCTORALIS AD SANITATEM INVESTIGANDAM Biohybrid Cloaked Nanovaccines for Cancer Immunotherapy UNIVERSITATIS HELSINKIENSIS 48/2019 Marie Mennesson Kainate Receptor Auxiliary Subunits Neto1 and Neto2 in Anxiety and Fear-Related Behaviors 49/2019 Zehua Liu Porous Silicon-Based On-Demand Nanohybrids for Biomedical Applications 50/2019 Veer Singh Marwah Strategies to Improve Standardization and Robustness of Toxicogenomics Data Analysis HELKA GÖÖS 51/2019 Iryna Hlushchenko Actin Regulation in Dendritic Spines: From Synaptic Plasticity to Animal Behavior and Human HUMAN TRANSCRIPTION FACTOR PROTEIN-PROTEIN Neurodevelopmental Disorders 52/2019 Heini Liimatta INTERACTIONS IN HEALTH AND DISEASE Efectiveness of Preventive Home Visits among Community-Dwelling Older People 53/2019 Helena Karppinen Older People´s Views Related to Their End of Life: Will-to-Live, Wellbeing and Functioning 54/2019 Jenni Laitila Elucidating Nebulin Expression and Function in Health and Disease 55/2019 Katarzyna Ciuba Regulation of Contractile Actin Structures in Non-Muscle Cells 56/2019 Sami Blom Spatial Characterisation of Prostate Cancer by Multiplex -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

SOX12 Contributes to the Activation of the JAK2/STAT3 Pathway and Malignant Transformation of Esophageal Squamous Cell Carcinoma
ONCOLOGY REPORTS 45: 129-138, 2021 SOX12 contributes to the activation of the JAK2/STAT3 pathway and malignant transformation of esophageal squamous cell carcinoma CHUNGUANG LI1*, MAOLING ZHU2*, JI ZHU1, QIJUE LU1, BOWEN SHI1, BIN SUN3 and HEZHONG CHEN1 1Department of Thoracic Surgery, Changhai Hospital, Second Military Medical University, Shanghai 200438; 2Department of Gastroenterology, Yangpu Hospital, Tongji University School of Medicine, Shanghai 200090; 3Molecular Oncology Laboratory, Eastern Hepatobiliary Surgery Hospital, Second Military Medical University, Shanghai 200438, P.R. China Received May 15, 2020; Accepted October 6, 2020 DOI: 10.3892/or.2020.7863 Abstract. As a crucial transcription factor, sex-determining cells in vitro. Recombinant protein of SOX12 could restore the region Y box 12 (SOX12) is closely related with tumorigenesis aggressive phenotype of ESCC cells. Furthermore, knockdown and malignant transformation in various malignant tumor of the expression of SOX12 inhibited the activation of the Janus types. To date, the specific function of SOX12 in esophageal kinase 2 (JAK2)/signal transducer and activator of transcrip- squamous cell carcinoma (ESCC) has remained largely tion 3 (STAT3) signaling pathway by decreasing the expression elusive and requires further investigation. The present study of the JAK2/STAT3 signaling pathway. Recombinant protein aimed to determine whether aberrant expression of SOX12 is of SOX12 could recover the activation of the JAK2/STAT3 associated with malignant development of ESCC. The expres- signaling pathway. Analysis of the clinical data revealed that sion level of SOX12 in ESCC cells and tissues was analyzed overexpression of SOX12 indicated shorter overall survival by RT-qPCR and western blotting. Short hairpin RNA time (OS; P=0.0341) and disease-free survival time (DFS; (shRNA) targeting SOX12 was transfected into ESCC cells to P=0.04). -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -

Supplemental Information
Supplemental information Dissection of the genomic structure of the miR-183/96/182 gene. Previously, we showed that the miR-183/96/182 cluster is an intergenic miRNA cluster, located in a ~60-kb interval between the genes encoding nuclear respiratory factor-1 (Nrf1) and ubiquitin-conjugating enzyme E2H (Ube2h) on mouse chr6qA3.3 (1). To start to uncover the genomic structure of the miR- 183/96/182 gene, we first studied genomic features around miR-183/96/182 in the UCSC genome browser (http://genome.UCSC.edu/), and identified two CpG islands 3.4-6.5 kb 5’ of pre-miR-183, the most 5’ miRNA of the cluster (Fig. 1A; Fig. S1 and Seq. S1). A cDNA clone, AK044220, located at 3.2-4.6 kb 5’ to pre-miR-183, encompasses the second CpG island (Fig. 1A; Fig. S1). We hypothesized that this cDNA clone was derived from 5’ exon(s) of the primary transcript of the miR-183/96/182 gene, as CpG islands are often associated with promoters (2). Supporting this hypothesis, multiple expressed sequences detected by gene-trap clones, including clone D016D06 (3, 4), were co-localized with the cDNA clone AK044220 (Fig. 1A; Fig. S1). Clone D016D06, deposited by the German GeneTrap Consortium (GGTC) (http://tikus.gsf.de) (3, 4), was derived from insertion of a retroviral construct, rFlpROSAβgeo in 129S2 ES cells (Fig. 1A and C). The rFlpROSAβgeo construct carries a promoterless reporter gene, the β−geo cassette - an in-frame fusion of the β-galactosidase and neomycin resistance (Neor) gene (5), with a splicing acceptor (SA) immediately upstream, and a polyA signal downstream of the β−geo cassette (Fig. -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Appendix 2. Significantly Differentially Regulated Genes in Term Compared with Second Trimester Amniotic Fluid Supernatant
Appendix 2. Significantly Differentially Regulated Genes in Term Compared With Second Trimester Amniotic Fluid Supernatant Fold Change in term vs second trimester Amniotic Affymetrix Duplicate Fluid Probe ID probes Symbol Entrez Gene Name 1019.9 217059_at D MUC7 mucin 7, secreted 424.5 211735_x_at D SFTPC surfactant protein C 416.2 206835_at STATH statherin 363.4 214387_x_at D SFTPC surfactant protein C 295.5 205982_x_at D SFTPC surfactant protein C 288.7 1553454_at RPTN repetin solute carrier family 34 (sodium 251.3 204124_at SLC34A2 phosphate), member 2 238.9 206786_at HTN3 histatin 3 161.5 220191_at GKN1 gastrokine 1 152.7 223678_s_at D SFTPA2 surfactant protein A2 130.9 207430_s_at D MSMB microseminoprotein, beta- 99.0 214199_at SFTPD surfactant protein D major histocompatibility complex, class II, 96.5 210982_s_at D HLA-DRA DR alpha 96.5 221133_s_at D CLDN18 claudin 18 94.4 238222_at GKN2 gastrokine 2 93.7 1557961_s_at D LOC100127983 uncharacterized LOC100127983 93.1 229584_at LRRK2 leucine-rich repeat kinase 2 HOXD cluster antisense RNA 1 (non- 88.6 242042_s_at D HOXD-AS1 protein coding) 86.0 205569_at LAMP3 lysosomal-associated membrane protein 3 85.4 232698_at BPIFB2 BPI fold containing family B, member 2 84.4 205979_at SCGB2A1 secretoglobin, family 2A, member 1 84.3 230469_at RTKN2 rhotekin 2 82.2 204130_at HSD11B2 hydroxysteroid (11-beta) dehydrogenase 2 81.9 222242_s_at KLK5 kallikrein-related peptidase 5 77.0 237281_at AKAP14 A kinase (PRKA) anchor protein 14 76.7 1553602_at MUCL1 mucin-like 1 76.3 216359_at D MUC7 mucin 7, -

SOX2 and SOX12 Are Predictive of Prognosis in Patients with Clear Cell Renal Cell Carcinoma
4564 ONCOLOGY LETTERS 15: 4564-4570, 2018 SOX2 and SOX12 are predictive of prognosis in patients with clear cell renal cell carcinoma WEIJIE GU1,2*, BEIHE WANG1,2*, FANGNING WAN1,2*, JUNLONG WU1,2, XIAOLIN LU1,2, HONGKAI WANG1,2, YAO ZHU1,2, HAILIANG ZHANG1,2, GUOHAI SHI1,2, BO DAI1,2 and DINGWEI YE1,2 1Department of Urology, Fudan University Shanghai Cancer Center; 2Department of Oncology, Shanghai Medical College, Fudan University, Shanghai 200032, P.R. China Received October 21, 2016; Accepted September 28, 2017 DOI: 10.3892/ol.2018.7828 Abstract. Sex-determining region Y-box protein (SOX) genes were associated with poor prognosis for OS (log-rank test, all serve an important role in cancer growth and metastasis. P<0.05). SOX2 and SOX12 were identified as independent The present study aimed to determine the predictive ability prognostic factors of OS in clear cell RCC. of SOX and associated genes identified through molecular network in clear cell renal cell carcinoma (RCC). A total of Introduction 505 patients with clear cell RCC from The Cancer Genome Atlas (TCGA) cohorts were collected in this study. The Renal cell carcinoma (RCC) accounts for ~2-3% of all malig- expression profile of SOX and associated genes were obtained nancies worldwide (1). Despite an increasing proportion of from the TCGA RNAseq database. Clinicopathological patients with early stage tumors at diagnosis and the develop- characteristics, including age, gender, tumor grade, stage, ment of novel treatment strategies, a quarter still present with laterality disease-free-survival and overall survival (OS) were locally advanced or metastatic disease, and eventually, one collected. -

Supplementary Table 2
Supplementary Table 2. Differentially Expressed Genes following Sham treatment relative to Untreated Controls Fold Change Accession Name Symbol 3 h 12 h NM_013121 CD28 antigen Cd28 12.82 BG665360 FMS-like tyrosine kinase 1 Flt1 9.63 NM_012701 Adrenergic receptor, beta 1 Adrb1 8.24 0.46 U20796 Nuclear receptor subfamily 1, group D, member 2 Nr1d2 7.22 NM_017116 Calpain 2 Capn2 6.41 BE097282 Guanine nucleotide binding protein, alpha 12 Gna12 6.21 NM_053328 Basic helix-loop-helix domain containing, class B2 Bhlhb2 5.79 NM_053831 Guanylate cyclase 2f Gucy2f 5.71 AW251703 Tumor necrosis factor receptor superfamily, member 12a Tnfrsf12a 5.57 NM_021691 Twist homolog 2 (Drosophila) Twist2 5.42 NM_133550 Fc receptor, IgE, low affinity II, alpha polypeptide Fcer2a 4.93 NM_031120 Signal sequence receptor, gamma Ssr3 4.84 NM_053544 Secreted frizzled-related protein 4 Sfrp4 4.73 NM_053910 Pleckstrin homology, Sec7 and coiled/coil domains 1 Pscd1 4.69 BE113233 Suppressor of cytokine signaling 2 Socs2 4.68 NM_053949 Potassium voltage-gated channel, subfamily H (eag- Kcnh2 4.60 related), member 2 NM_017305 Glutamate cysteine ligase, modifier subunit Gclm 4.59 NM_017309 Protein phospatase 3, regulatory subunit B, alpha Ppp3r1 4.54 isoform,type 1 NM_012765 5-hydroxytryptamine (serotonin) receptor 2C Htr2c 4.46 NM_017218 V-erb-b2 erythroblastic leukemia viral oncogene homolog Erbb3 4.42 3 (avian) AW918369 Zinc finger protein 191 Zfp191 4.38 NM_031034 Guanine nucleotide binding protein, alpha 12 Gna12 4.38 NM_017020 Interleukin 6 receptor Il6r 4.37 AJ002942