The Funcsearch Search Engine
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Disability Classification System
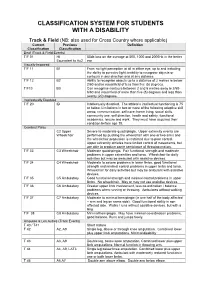
CLASSIFICATION SYSTEM FOR STUDENTS WITH A DISABILITY Track & Field (NB: also used for Cross Country where applicable) Current Previous Definition Classification Classification Deaf (Track & Field Events) T/F 01 HI 55db loss on the average at 500, 1000 and 2000Hz in the better Equivalent to Au2 ear Visually Impaired T/F 11 B1 From no light perception at all in either eye, up to and including the ability to perceive light; inability to recognise objects or contours in any direction and at any distance. T/F 12 B2 Ability to recognise objects up to a distance of 2 metres ie below 2/60 and/or visual field of less than five (5) degrees. T/F13 B3 Can recognise contours between 2 and 6 metres away ie 2/60- 6/60 and visual field of more than five (5) degrees and less than twenty (20) degrees. Intellectually Disabled T/F 20 ID Intellectually disabled. The athlete’s intellectual functioning is 75 or below. Limitations in two or more of the following adaptive skill areas; communication, self-care; home living, social skills, community use, self direction, health and safety, functional academics, leisure and work. They must have acquired their condition before age 18. Cerebral Palsy C2 Upper Severe to moderate quadriplegia. Upper extremity events are Wheelchair performed by pushing the wheelchair with one or two arms and the wheelchair propulsion is restricted due to poor control. Upper extremity athletes have limited control of movements, but are able to produce some semblance of throwing motion. T/F 33 C3 Wheelchair Moderate quadriplegia. Fair functional strength and moderate problems in upper extremities and torso. -

Structure of the Full Kinetoplastids Mitoribosome and Insight on Its Large Subunit Maturation
bioRxiv preprint doi: https://doi.org/10.1101/2020.05.02.073890; this version posted June 30, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Structure of the full kinetoplastids mitoribosome and insight on its large subunit maturation Heddy Soufari1* & Florent Waltz1*, Camila Parrot1+, Stéphanie Durrieu1+, Anthony Bochler1, Lauriane Kuhn2, Marie Sissler1, Yaser Hashem1‡ 1 Institut Européen de Chimie et Biologie, U1212 Inserm, UMR5320 CNRS, Université de Bordeaux, 2 rue R. Escarpit, F-33600 Pessac, France 2 Plateforme protéomique Strasbourg Esplanade FRC1589 du CNRS, Université de Strasbourg, Strasbourg, France *contributed equally, co-first authors +contributed equally, co-second authors ‡corresponding author Abstract: Kinetoplastids are unicellular eukaryotic parasites responsible for human pathologies such as Chagas disease, sleeping sickness or Leishmaniasis1. They possess a single large mitochondrion, essential for the parasite survival2. In kinetoplastids mitochondrion, most of the molecular machineries and gene expression processes have significantly diverged and specialized, with an extreme example being their mitochondrial ribosomes3. These large complexes are in charge of translating the few essential mRNAs encoded by mitochondrial genomes4,5. Structural studies performed in Trypanosoma brucei already highlighted the numerous peculiarities of these mitoribosomes and the maturation of their small subunit3,6. However, several important aspects mainly related to the large subunit remain elusive, such as the structure and maturation of its ribosomal RNA3. Here, we present a cryo-electron microscopy study of the protozoans Leishmania tarentolae and Trypanosoma cruzi mitoribosomes. -

RULES 2004 Final Amended
INTERNATIONAL PARALYMPIC COMMITTEE ATHLETICS SECTION COMBINED RULES 2004 PREAMBLE For competition at Paralympics and I.P.C. World Championships, this book shall be used, along with the current I.A.A.F. Handbook. It contains all the rules, which govern an I.P.C. Athletics competition, written in a way, which is compatible with the rules of the governing body for athletics, the International Association of Athletics Federations (I.A.A.F.). In this way, officials, coaches and athletes may find rules to cover any event in a single document, rather than having to refer to separate books for each group. The rules must be read in conjunction with the I.A.A.F. rules, contained in the Handbook of that Association. For the period including the 2004 Athens Paralympics, the version of the I.A.A.F. Handbook to which this book refers is the 2004-2005 edition. The rules concerned are the Technical Rules of Competition as described herein, and additional rules as shown. The reference to the I.A.A.F. Handbook does not confer any responsibility onto the I.A.A.F. for the I.P.C. Rules. Each of the I.O.S.D.’s has its own cycle of rule changes, and this volume does not intend to change any rules so decided. It is quite simply a means of simplifying the task of reading the rules for those concerned. NOTES This Rule Book will remain in force until the publication of the next I.A.A.F. Handbook, at which time a new edition will be published to take account of any new I.A.A.F. -

Structure of the Full Kinetoplastids Mitoribosome and Insight on Its Large Subunit Maturation
bioRxiv preprint doi: https://doi.org/10.1101/2020.05.02.073890; this version posted June 30, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Structure of the full kinetoplastids mitoribosome and insight on its large subunit maturation Heddy Soufari1* & Florent Waltz1*, Camila Parrot1+, Stéphanie Durrieu1+, Anthony Bochler1, Lauriane Kuhn2, Marie Sissler1, Yaser Hashem1‡ 1 Institut Européen de Chimie et Biologie, U1212 Inserm, UMR5320 CNRS, Université de Bordeaux, 2 rue R. Escarpit, F-33600 Pessac, France 2 Plateforme protéomique Strasbourg Esplanade FRC1589 du CNRS, Université de Strasbourg, Strasbourg, France *contributed equally, co-first authors +contributed equally, co-second authors ‡corresponding author Abstract: Kinetoplastids are unicellular eukaryotic parasites responsible for human pathologies such as Chagas disease, sleeping sickness or Leishmaniasis1. They possess a single large mitochondrion, essential for the parasite survival2. In kinetoplastids mitochondrion, most of the molecular machineries and gene expression processes have significantly diverged and specialized, with an extreme example being their mitochondrial ribosomes3. These large complexes are in charge of translating the few essential mRNAs encoded by mitochondrial genomes4,5. Structural studies performed in Trypanosoma brucei already highlighted the numerous peculiarities of these mitoribosomes and the maturation of their small subunit3,6. However, several important aspects mainly related to the large subunit remain elusive, such as the structure and maturation of its ribosomal RNA3. Here, we present a cryo-electron microscopy study of the protozoans Leishmania tarentolae and Trypanosoma cruzi mitoribosomes. -

Deportistas Sin Adjetivos
Part 1-0 AUTORES-INDICE-INTRO:Part 1-0 AUTORES-INDICE-INTRO.qxd 12/12/2011 22:30 Página 5 Part 1-0 AUTORES-INDICE-INTRO:Part 1-0 AUTORES-INDICE-INTRO.qxd 12/12/2011 19:59 Página 6 Edita Consejo Superior de Deportes, Real Patronato sobre Discapacidad. Ministerio de Sanidad, Política Social e Igualdad Comité Paralímpico Español Consejo de Redacción Joan Palau Francàs. Presidente de la FEDDF Josep Oriol Martínez i Ferrer. Adjunto al Presidente de la FEDDF Miguel Ángel García Alfaro. Gerente y Director Técnico de la FEDDF Merche Ríos Hernández. Profesora de la Universitat de Barcelona Dirección editorial Javier Fernández Diseño y maquetación Ana F. Pérez Producción G·2 · [email protected] Impresión Croma graf Press c. o. NIPO (CSD): 008-11-021-13 NIPO (RPD): 864-11-015-6 Depósito Legal: M-46953 -2011 Todos los derechos reservados, no pudiéndose utilizar mecánica ni electrónicamente parte o la totalidad de la obra sin permiso de sus autores o del editor. Será requerido quien infrinja las normas legales establecidas. Impreso en España · Printed in Spain Part 1-0 AUTORES-INDICE-INTRO:Part 1-0 AUTORES-INDICE-INTRO.qxd 02/12/2011 19:39 Página 7 Esta Obra, que ha tenido un largo periodo de confección, ha sido posible gracias al aporte e impulso de una figura seguramente irrepetible en el mundo del deporte español, que por desgracia nos dejó el 26 de abril de 2011, Joan Palau, a quien todos los que hemos colaborado en la misma queremos brindar su puesta de largo. Esto es por y para ti. -

Uk Athletics Rules for Competition
UKA RULES FOR COMPETITION Effective from 1st April 2014 UK Athletics Athletics House Alexander Stadium Walsall Road Perry Barr Birmingham B42 2BE Lynn Davies, C.B.E. - President Edmond Warner O.B.E. - Chair Niels de Vos - Chief Executive Tel 0121 713 8400 Fax 0121 713 8452 W: www.britishathletics.org.uk E: [email protected] UK Athletics Ltd. ISBN: 978-0-9547401-3-9 Typeset by Data Standards Ltd., Frome Printed and bound by Polestar Wheatons Ltd., Exeter OFFICERS OF UKA GROUPS OFFICIALS GROUP Coordinator: Andrew Clatworthy, 26 Columba Drive, Leighton Buzzard, Beds. LU7 3YN. Tel/Fax: 01525 371186; E: [email protected] NATIONAL ASSOCIATIONS ENGLAND ATHLETICS Office: Alexander Stadium, Walsall Road, Perry Barr, Birmingham. B42 2BE.Tel: 0121 347 6543. Fax: 0121 347 6544. www.englandathletics.org Tri-Regional Officials’ Secretaries: South: Mrs Wendy Haxell, 5 Nursery Gardens, Horndean, Waterlooville. PO8 9LE. Tel: 02392 613717. E: [email protected]. Midlands & South West: Barry Parker, 26 Field Drive, Alvaston, Derby. DE24 0HF. Tel: 01332 753933; E: [email protected]. North: Paul Yates, 29 Chadwick Road, Eccles, Lancashire. M30 0WU. Tel: 07905 340077. E; [email protected]. ATHLETICS NORTHERN IRELAND Office: Athletics House, Old Coach Road, Belfast. BT79 5PR. Tel: 028 9060 2707; Fax: 028 9030 9939. www.niathletics.org. Officials’ Secretary: Bob Brodie, 3 Millar’s Ford, Lisburn, Northern Ireland. BT28 1JY. Tel: 028 9267 0311; Mob: 07939 670371; E: [email protected]. SCOTTISH ATHLETICS LTD Office: Caledonia House, South Gyle, Edinburgh. EH12 9DQ. Tel: 0131 539 7320. www.scottishathletics.org.uk Officials’ Convenor: Vic Hockley, 41 Murieston Park, Murieston South, Livingston, West Lothian. -

Identification of S-Phase DNA Damage-Response Targets in Fission Yeast Reveals Conservation of Damage-Response Networks
Identification of S-phase DNA damage-response targets in fission yeast reveals conservation of damage-response networks Nicholas A. Willisa,1,2, Chunshui Zhoub,c,2, Andrew E. H. Eliab,d, Johanne M. Murraye, Antony M. Carre, Stephen J. Elledgeb,f,3, and Nicholas Rhinda,3 aDepartment of Biochemistry and Molecular Pharmacology, University of Massachusetts Medical School, Worcester, MA 01605; bDepartment of Genetics, Division of Genetics, Brigham and Women’s Hospital, Harvard Medical School, Boston, MA 02115; cThe Laboratory of Medical Genetics, Harbin Medical University, Harbin, China, 150081; dDepartment of Radiation Oncology, Massachusetts General Hospital, Boston, MA 02114; eGenome Damage and Stability Centre, School of Life Sciences, University of Sussex, Falmer, BN1 9RQ, United Kingdom; and fHoward Hughes Medical Institute, Harvard Medical School, Boston, MA 02115 Contributed by Stephen J. Elledge, February 16, 2016 (sent for review December 28, 2015; reviewed by Mingxia Huang and Lee Zou) The cellular response to DNA damage during S-phase regulates a Cds1 in fission yeast (11–13). Despite this plasticity in check- complicated network of processes, including cell-cycle progression, point-kinase wiring, the biological processes regulated by the gene expression, DNA replication kinetics, and DNA repair. In fission S-phase DDR are conserved. yeast, this S-phase DNA damage response (DDR) is coordinated by The S-phase DDR regulates a wide range of cellular functions, two protein kinases: Rad3, the ortholog of mammalian ATR, and including cell-cycle progression, transcription of S-phase genes, Cds1, the ortholog of mammalian Chk2. Although several critical DNA-replication kinetics, and DNA repair (14, 15). However, the downstream targets of Rad3 and Cds1 have been identified, most specific targets phosphorylated to regulate these functions have of their presumed targets are unknown, including the targets re- been identified in only a limited number of cases. -

BUILDINGS and THEIR APPLICATIONS in GEOMETRY and TOPOLOGY to the Memory of Professor S.S. Chern Contents 1 Introduction and Hist
ASIAN J. MATH. c 2006 International Press Vol. 10, No. 1, pp. 011–080, March 2006 002 BUILDINGS AND THEIR APPLICATIONS IN GEOMETRY AND TOPOLOGY∗ LIZHEN JI† To the memory of Professor S.S. Chern Abstract. Buildings were first introduced by J. Tits in 1950s to give systematic geometric inter- pretations of exceptional Lie groups and have been generalized in various ways: Euclidean buildings (Bruhat-Tits buildings), topological buildings, R-buildings, in particular R-trees. They are useful for many different applications in various subjects: algebraic groups, finite groups, finite geometry, representation theory over local fields, algebraic geometry, Arakelov intersection for arithmetic va- rieties, algebraic K-theories, combinatorial group theory, global geometry and algebraic topology, in particular cohomology groups, of arithmetic groups and S-arithmetic groups, rigidity of cofinite subgroups of semisimple Lie groups and nonpositively curved manifolds, classification of isoparamet- ric submanifolds in Rn of high codimension, existence of hyperbolic structures on three dimensional manifolds in Thurston’s geometrization program. In this paper, we survey several applications of buildings in differential geometry and geometric topology. There are four underlying themes in these applications: 1. Buildings often describe the geometry at infinity of symmetric spaces and locally symmetric spaces and also appear as limiting objects under degeneration or scaling of metrics. 2. Euclidean buildings are analogues of symmetric spaces for semisimple groups defined over local fields and their discrete subgroups. 3. Buildings of higher rank are rigid and hence objects which contain or induce higher rank buildings tend to be rigid. 4. Additional structures on buildings, for example, topological buildings, are important in applications for infinite groups. -

Rules for Competition
RULES FOR COMPETITION Effective from 1st April 2006 UK Athletics Athletics House Central Boulevard Blythe Valley Park Solihull B90 8AJ Tel: 0870 998 6800 Fax: 0870 998 6752 W: www.ukathletics.net E: [email protected] UK Athletics Ltd ISBN 0-9547401-1-4 Typeset by Polestar Applied Solutions Ltd., Milton Keynes Printed and bound by Polestar Wheatons Ltd., Exeter OFFICERS OF UKA GROUPS OFFICIALS GROUP Coordinator: A. J. CLATWORTHY, 26 Columba Drive, Leighton Buzzard, Beds. LU7 3YN Tel/Fax: 01525 371186 RULES AND RECORDS GROUP Chairman: J. W. McINNES, 20 Larchfield, Colquhoun Street, Helensburgh. G84 9JG Tel/Fax: 01436 674233 Hon. Secretary: D. R. LITTLEWOOD, 26 Newborough Green, New Malden, Surrey. KT3 5HS. Tel: 020 8949 1506; Fax: 020 8942 0943 NATIONAL/TERRITORIAL ASSOCIATIONS ENGLAND ATHLETICS ENGLAND To be confirmed MIDLAND COUNTIES ATHLETIC ASSOCIATION Office: Edgbaston House, 3Duchess Place, Hagley Road, Birmingham. B16 8NM Tel: 0121 456 1896 www.midlandathletics.org.uk Officials’ Secretary: Mrs. M. BULLEN, 56 Kittoe Road, Sutton Coldfield, West Midlands. B74 4SA. Tel: 0121 308 2257 NORTH OF ENGLAND ATHLETIC ASSOCIATION Office: 7Wellington Road East, Dewsbury, West Yorkshire. WF13 1HF Tel: 0870 991 4545; Fax: 0870 991 4546. www.noeaa-athletics.org.uk Officials’ Secretary: R. BROWN, 107 Tedder Road, Acomb, York. YO24 3JE Tel: 01904 792646 SOUTH OF ENGLAND ATHLETIC ASSOCIATION Marathon House, 115 Southwark Street, London. SE1 0JF Tel: 020 7021 0988; Fax: 020 7620 0012. www.seaa.org.uk Officials’ Secretary: J. NEALE, 29 Preston Parade, Seasalter, Whitstable. Kent. CT5 4ADTel/Fax: 01227 276558 ii NORTHERN IRELAND NORTHERN IRELAND AMATEUR ATHLETIC FEDERATION Office: Athletics House, Old Coach Road, Belfast. -

Faculty and Student Perceptions of Reading and Language Arts Preparation and Preparedness for the State Subject Area Test Ingrid Ahrens Massey Walden University
Walden University ScholarWorks Walden Dissertations and Doctoral Studies Walden Dissertations and Doctoral Studies Collection 2016 Faculty and Student Perceptions of Reading and Language Arts Preparation and Preparedness for the State Subject Area Test Ingrid Ahrens Massey Walden University Follow this and additional works at: https://scholarworks.waldenu.edu/dissertations Part of the Higher Education Administration Commons, Higher Education and Teaching Commons, Other Education Commons, and the Reading and Language Commons This Dissertation is brought to you for free and open access by the Walden Dissertations and Doctoral Studies Collection at ScholarWorks. It has been accepted for inclusion in Walden Dissertations and Doctoral Studies by an authorized administrator of ScholarWorks. For more information, please contact [email protected]. Walden University COLLEGE OF EDUCATION This is to certify that the doctoral study by Ingrid Ahrens Massey has been found to be complete and satisfactory in all respects, and that any and all revisions required by the review committee have been made. Review Committee Dr. Sydney Parent, Committee Chairperson, Education Faculty Dr. Mario Castro, Committee Member, Education Faculty Dr. Rollen Fowler, University Reviewer, Education Faculty Chief Academic Officer Eric Riedel, Ph.D. Walden University 2016 Abstract Faculty and Student Perceptions of Reading and Language Arts Preparation and Preparedness for the State Subject Area Test by Ingrid Ahrens Massey MEd, Oklahoma State University, 2003 BS, Northeastern State University, 1996 Project Study Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Education Walden University December 2016 Abstract Since changes to the reading/language arts State Subject Area Test (SSAT) in late 2010, elementary education teacher candidates at a teacher training college in the Southern United States have experienced declining scores resulting in test failure and delaying student teaching and graduation. -

Infk Atior N Eas Ses T IIIR :Ol8 ^63 I-Mo >Nth Low I Cle. I S. Jans
v - v | Q n r ■ ; ry y k ^ IIT iTTS^63 77th y ear, J* Twin Falls, Ida , N o. 57 laho FridIday, Februaty 26■6,1982 J25^ Infkatiorn easses t:ol8i-mo>nthlow ] recession could pork, popoultry, seafood, fnill, sugar, ^■ByNew York Dally News * -consider it (obe aI tettemporary reaction to the rc<recession." Popkin wametned thal only a prolonged n gar, cereal and baked said economist Joelocl Popkin, form er assistantIt commls- produce this result.rcj goods. BlBul beef and eggs were lower.cr. : .•WASHlNGTOTT^nnalllatisiranhcTSCTiibook levelle' sloner of the Bureatreau o( Labor Statistics. HeIe said the "Kwehavetlethe mid-year recovery the‘ adadministralion is McdlciIcal care continued io bc Ihe(h< most Inflationary ry In (he Index, rising 0.8 o( i ensed Jn January, the goveru'ernmentrtpwW rrHawtey.f.i f • underiying Innatlon>n r;rate was still 9 percent, predicting, thebe Inflation rate will s^tle aroiiround 9 perccnl.” category o( a perccnt tor a 12.1 - Post-Christpias clothinglg «sales and lower gasoline prk)rices The 0.3 of a percentrent January hike In the consurlumer price hesaid. percentiit Increase over the year. iTtafnment prices cllmbcd O.'i held the consum er price indiIndex to an advance of only 0.3 of Index. foUowing increicreases of 0.4 of a percent In D<December, Aside fromn clothing,( which fell 0.1 o( ia pcrcent. and. Enlert I 0.7 of a pcrcenl^and ss were up 0,6 of a perccnt. Th( a perccnt. thcsm ^est incrccrease In 18 months, 0.5 of a p ercent In1 November,No 0.4 percenc in Ocl)ctober and transportation,on, o(( 0.2 o( a p e r c ^ t, (hele JJanuary report sewlces The Increases lo bealtb Itertalnment were higher thai . -

Ipc Athletics Classification Handbook
IPC ATHLETICS CLASSIFICATION HANDBOOK INTRODUCTION This first edition of a combined IPC Athletics Classification Rule Book contains four chapters which cover the areas needed to understand the classification of athletes in Athletics. It is a developing document, and this first edition will remain in use for 2006, and may be amended from time to time. It will be further amended to ensure full compliance with the IPC Classification Code. INDEX Chapter 1 The Classification System Page 1 Chapter 2 The Classification Process Page 20 Chapter 3 General Guidelines Page 23 Chapter 4 Codes of Conduct Page 26 CHAPTER 1: THE CLASSIFICATION SYSTEM 1. INTRODUCTION The IPC Athletics Classification System offers track and field events for ambulant and wheelchair athletes. 1.1. The wheelchair athlete group consists of two subgroups. 1.1.1. Athletes with • spinal cord injuries or spinal cord conditions, • athletes with amputations, • athletes with other musculoskeletal impairments, congenital anomalies and nerve lesions who meet the sport specific minimum impairment levels. 1.1.2. Athletes with cerebral palsy, traumatic brain injury or stroke. 1.2. The ambulant athlete group consists of four subgroups. 1.2.1. Athletes with • amputations, • athletes with spinal cord injuries or spinal cord conditions. • athletes with other musculoskeletal impairments, congenital anomalies and nerve lesions who meet the sport specific minimum impairment levels. 1.2.2. Athletes with cerebral palsy, traumatic brain injury or stroke. 1.2.3. Athletes who are visually impaired 1.2.4. Athletes who are intellectually disabled. 1 IPC Athletics Classification Rules 2006 2. MINIMAL IMPAIRMENT The minimal impairment varies from sub-group to sub-group e.g.