Exploitation from Malicious Pci Express
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Li H Isl ;R¥ ISJ I Wwê W
•* b\ica. i ^.j iecadoSenadOpra^daRepU *¦-* < ^^MaM^____-_g__e--5jgg^^ _ag__»g]—»C--!Bi^CT REDACÇÃO E ADMINISTRAÇÃO ASSIGNATURAS fiedacíor-cheíe — OR... FERNANDO MENDES DE ALMEIDA 54 RUA GONÇALVES DIAS mm rasa o laaan. N. 31 BISTXXBUIÇÃO E EXPEDIÇÃO APO XII •AB0*toe»»* *«*••••• SOfOOO Trimestrs (t edlçftet) . fí *d_;-e-).... Imooi. ¦XTiaioa „zkJ: ss KVA eo\ÇAI.Vt_S BUl It ¦emettre 16IOC:* Anr.o eeinrA 28 DE DEZEMBRO DE 19-2 Y-tophemB B. f B - (1 ediçoet). tajoou • (. edicOaX.... ttoioca MO DE JANEIRO-DOMINGO. l-E_E_a--_-^*K-,---g*a----»«_Sei--. ¦»!.' III .-B-g-T» ,^J*lfWWW_( 1 feito pelo putiio-ismo de centena- com mercaJorias ne diversas pro res de portuguezes: cedencias. da varias vezes,mudado seu nome A assignatura do contrato com Di Beira sabe-se que continua a cida momento, augmentado ou a casa Car.et para o fornecimento _„ ,-,-','»„nt3 desenvolvimento o Z PAGINAS diminuído, alternativamente, o cc Por Julião Machado da artiiheria realizar-se-á nos pri- caminho rie ferro dc » traíeffO sou cíiectivo, sem saliir das mu- meiros dias desta semana. pelo tle FESTAS ralhas uma fortaleza absolcta Trata-se de adiantar o mais pos. Pa do rendimento mensal RÉIS . c dos limites estreites de um re- sivel a construcção tio navio, A me ¦¦",^'•7 200 ii è de bbras. o que cor- gulamcnto coercitivo de legitimas para se evitar quê soffra a inver feüome- aspirações. responde a 4ã5.'»h«s por nia no Tejo. const»We uma receita De Nantes sei tros. c EJ-.*- SBSW-Bffl-S-aBS Em um paiz de littoral tfio ex- que partiu para importante. -

Ken Merry Spectra Logic Corporation • SCSI Target Emulation Framework • Can Present a Ramdisk, File, Or Block Device As a SCSI Target
Ken Merry Spectra Logic Corporation • SCSI target emulation framework • Can present a ramdisk, file, or block device as a SCSI target. • LUNs visible through target-capable CAM SIMs. Only fully supported driver right now is isp(4). • LUNs also visible through the internal CTL SIM. • Written for Copan Systems, starting in early 2003. • Originally written for Linux, has some similarities to CAM. Linux version had thousands of lines of CAM code included. • CTL originally meant “Copan Top Level”, and later “Copan Target Layer”. • Started shipping in 2005. • Ported to FreeBSD in 2008, when Copan ported their whole I/O stack to FreeBSD. • Currently ships in SGI’s ArcFiniti and COPAN 400M/ 400T products. • Copan’s assets bought by SGI in 2010. • Spectra Logic made a deal with SGI in 2010. • Spectra got the source to CTL under a BSD- style license, with the understanding that they would work to get it into FreeBSD. • CTL committed to FreeBSD/head and stable/9 in early 2012. • Disk and processor device emulation • Tagged queuing • SCSI task attribute support (ordered, head of queue, simple tags) • SCSI implicit command ordering • Full task management support (abort, LUN reset, target reset, bus reset) • Multiple ports • Multiple initiators per port • Multiple LUNs • Multiple backend types • Persistent reservations • Mode sense and select • All I/O is handled in-kernel, no userland context switches. • Basic High Availability support stubs. (Needs to be fleshed out.) read, write, ioctl userland kernel da(4) cd(4) sa(4) CAM xpt isp(4) mps(4) SAN -

Porting Freebsd to Aarch64
Porting FreeBSD to AArch64 Andrew Turner { [email protected] 12 June 2015 About me Source committer { focusing on ARM Freelance Software Engineer Status of arm64 (AArch64) Support to boot in QEMU committed to subversion Some support for Cavium ThunderX in subversion Boots on Xen, with a few patches Only single-core, DMA is assumed to be cache-coherent for now Timeline Oct 2012 Foundation Model released Nov 2014 FreeBSD Foundation project Jul 2012 Nov 2012 First AArch64 FreeBSD Dec 2013 Jul 2014 Apr 2015 binutils patch boot code Enable the MMU mountroot prompt Started committing to svn May 2012 Oct 2012 Oct 2013 Feb 2014 Jan 2015 First AArch64 Ported GCC Documentation FreeBSD build Boot on QEMU Aug 2014 GCC patch and binutils Infrastructure First userland instructions Sep 2012 AArch64 boot wrapper History of FreeBSD on AArch64 4 phases: 1. Early experimentation 2. FreeBSD subversion project 3. FreeBSD Foundation project 4. Committed to HEAD (main development branch) Early experimentation My early work to learn the architecture 1. ARM boot code 2. Simple ELF loader 3. Early ASM 4. C code ARM boot code Provided by ARM to initialise the hardware BSD Licensed Simple ELF Loader Reads enough of an ELF file to run it 9 instructions Early ASM Written to become locore.S { the initial kernel code 1. Puts the hardware in a known state 2. Builds the initial pagetable 3. Enables the MMU 4. Branches to a virtual address 5. Calls into C code C code Mostly for debugging Could write to the UART Early issues I No documentation until September 2013 I No -

The Journal of AUUG Inc. Volume 24 ¯ Number 2 June 2003
The Journal of AUUG Inc. Volume 24 ¯ Number 2 June 2003 Features: Microsoftens 10 OpenBSD 3.3 Released 11 Linux System’ Administrator’s Security Guide (Part 1) 15 The Roadman for FreBSD 5-stable 20 Mail and Dynamic IP 24 Intrusion Detection System (Part 1) 25 FreeBSD 5.1 Release Process 40 SCO-vs.-IBM: the Open Source Initiative Position Paper on the Complaint 41 AUUG 2003 Systems Administration Symposium Photo Gallery 57 NetBSD 1.6.1 CD 58 News: Public Notices 4 AUUG: Corporate Members 9 AUUG Conference 2003 Invitation 59 AUUG Membership Renewal 61 AUUG: Chapter Meetings and Contact Details 63 Regulars: President’s Column 3 My Home Network 4 ISSN 1035-7521 Print post approved by Australia Post - PP2391500002 AUUG Membership and General Correspondence The AUUG Secretary PO Box 7071 Edi oria Baulkham Hills BC NSW 2153 Con Zymaris auu.qn@auu,q.or,q.au Telephone: 02 8824 9511 or 1800 625 655 (Toll-Free) I imagine I’m not alone in expressing fond memories Facsimile: 02 8824 9522 Email: [email protected] of both Carl Sagan and Stephen Jay Gould. Both of these gentleman were not only practicing scientists AUUG Management Committee but also exemplary communicators of science and of Email: [email protected] the technical, complex and beautiful cosmos that we inhabit. President Greg Lehey PO Box 460 Through his combination of vision and chutzpah, Echunga, SA, 5153 Sagan caused us to pause for a moment and consider Bus. Tel (08) 8388 8286, Mobile 0418 838 708, Fax (08) 8388 8725 the majesty of star-stuff, of galaxies and of the human <[email protected]> discourse which ensued over millennia in trying to Immediate Past President reveal their secrets. -

Freebsd Foundation March 2016 Update
FreeBSD Foundation March 2016 Update Upcoming Events Message from the Executive Director Dear FreeBSD Community Member, Flourish! 2016 April 1-2, 2016 What a landmark month March has been! After months of work, we Chicago, IL debuted our new logo and website, and we’re excited to take our identity to the next stage after 16 years. We also received our first LinuxFest Northwest 2016 April 23-24, 2016 Iridium Level donation of 2016. Thank you to Netapp for continuing Bellingham, WA their huge support of FreeBSD. On the development projects front, we embarked on the next phase of the arm64 project and more. Please OSCON 2016 take a minute to see what we’ve been up to this month, and thank you May 16-19, 2016 Austin, TX for helping us continue to enhance our support for the Project. Deb BSDCan 2016 June 10-11, 2016 Ottawa, Canada Development Projects Update FreeBSD Journal In March, Foundation staff and collaborators made dozens of commits to the FreeBSD source repository across a wide variety of projects. These included updates, bug fixes or improvements to man pages, the autofs automount daemon, the runtime loader, kernel module support, callouts, the ELF Tool Chain, Intel graphics drivers, process shared pthread locks, and more. This month the Foundation embarked on the next phase of the FreeBSD/arm64 project with Andrew Turner, with the financial support of ARM. I’ll focus on this project here. Regular readers of this newsletter will know that we’ve previously worked with Semihalf and Andrew The January/February 2016 issue of Turner to bring up foundational arm64 support in FreeBSD. -
Towards a Verified Complex Protocol Stack in a Production Kernel: Methodology and Demonstration
Dartmouth College Dartmouth Digital Commons Dartmouth College Ph.D Dissertations Theses and Dissertations 5-1-2016 Towards A Verified Complex Protocol Stack in a Production Kernel: Methodology and Demonstration Peter C. Johnson Dartmouth College Follow this and additional works at: https://digitalcommons.dartmouth.edu/dissertations Part of the Computer Sciences Commons Recommended Citation Johnson, Peter C., "Towards A Verified Complex Protocol Stack in a Production Kernel: Methodology and Demonstration" (2016). Dartmouth College Ph.D Dissertations. 51. https://digitalcommons.dartmouth.edu/dissertations/51 This Thesis (Ph.D.) is brought to you for free and open access by the Theses and Dissertations at Dartmouth Digital Commons. It has been accepted for inclusion in Dartmouth College Ph.D Dissertations by an authorized administrator of Dartmouth Digital Commons. For more information, please contact [email protected]. TOWARDS A VERIFIED COMPLEX PROTOCOL STACK IN A PRODUCTION KERNEL: METHODOLOGY AND DEMONSTRATION A Thesis Submitted to the Faculty in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Science by Peter C. Johnson DARTMOUTH COLLEGE Hanover, New Hampshire May, 2016 Dartmouth Computer Science Technical Report TR2016-803 Examining Committee: (chair) Sean W. Smith, Ph.D. (co-chair) Sergey Bratus, Ph.D. David F. Kotz, Ph.D. Devin Balkcom, Ph.D. M. Douglas McIlroy, Ph.D. Trent Jaeger, Ph.D. F. Jon Kull, Ph.D. Dean of Graduate Studies ABSTRACT Any useful computer system performs communication and any communication must be parsed before it is computed upon. Given their importance, one might expect parsers to receive a significant share of attention from the security community. -

Software Tools
Software Tools Mission Accomplished or Mission Failure ? Poul-Henning Kamp [email protected] Software Tools 1970 – 2010 -> approx 40 years old Central paradigm in UNIX philosophy But is it still relevant ? ”Midlife crisis” or ”Life begins at 40” ? The Gospel according to Salus: AT&T leaves ”MULTICS” project. Dennis, Ken & Brian go cold turkey on PDP/8 Saves the world with UNIX, C & AWK Awarded presidental medal Everybody Lives Happy Ever After MULTICS UNIX Big Compact Complex Simple Unwieldy Elegant Delayed Available Red Tape ”Call Ken” BAD OS GOOD OS Software Tools Book: Kernighan & Plauger RATFOR, Pascal &c. Argument: Programs should be tools (And well written) Software Tools Programs should be tools which do one job well Tools, not policies Programs should work together Programs and source code are data Interaction is programming grep ©#include© .c | sed -e ©s/.*<//© -e ©s/>.*//© | xargs grep foo SwTools => Files are Flat Files are flat and typeless == One dimensional array of bytes Name files by/in free hierarchy Compare IBM S/3: A Disk has Volumes which contains Files, which can be a Library, which contains Members, which have Types, for instance RPG/II Source code Types of files File type information conventionally encoded in name ...inconsistently: *.y *.l *.f *.c *.o *.a *.s *.Z *.gz *.bz2 *.tar *.tgz Makefile .login rc.* lib*.so.%d That Neumann/Turing detail Metadata X-bit not marks executability Execution method by magic sequences in file data #!/bin/sh #!/usr/local/bin/python3.1 \0407\206\000\000 \x7fELF The fine print... ”Programs and source code are data” is not a transitive: Data is not a program. -
VT-D and Freebsd
VT-d and FreeBSD Константин Белоусов [email protected] 21 сентября 2013 г. Revision : 1:11 Константин Белоусов [email protected] VT-d and FreeBSD PCIe Example PCI Express Topology – Root & Switch CPU Bus CPU Root RCRB Bus 0 Root Complex Memory Virtual Virtual Virtual PCI PCI PCI Bridge Bridge Bridge PCIe PCIe PCIe PCIe PCIe PCIe Switch PCI Express Links Endpoint Endpoint PCIe Bridge To PCIe PCIe PCI/PCI-X Switch Virtual PCIe Legacy PCI Endpoint Endpoint PCI/PCI-X Bridge Virtual Virtual Virtual PCI PCI PCI Legend Bridge Bridge Bridge PCI Express Device Downstream Port PCI Express Device Upstream Port PCI-SIG Developers Conference Copyright © 2007, PCI-SIG, All Rights Reserved 8 Константин Белоусов [email protected] VT-d and FreeBSD PCIe TLP - Transaction Layer Packets I/O Host access to device (BARs) Device access to memory (DMA) Peer to peer GPU RDMA over Infiniband Nvidia Optimus Messaging: Interrupts, Errors Configuration I/O. Константин Белоусов [email protected] VT-d and FreeBSD Device DMA engines Features and Limitations Scatter/Gather: number of segments DMA engine restrictions Address width Dead bits (alignment) Segment length Streaming Coherence (Snoop) Traffic Prioritization Константин Белоусов [email protected] VT-d and FreeBSD I ntroduction—Intel® Virtualization Technology for Directed I / O 1 Introduction This document describes the Intel® Virtualization Technology for Directed I/O (“Intel® VT for Directed I/O”); specifically, it describes the components supporting I/O virtualization as it applies to platforms that useVT-d Intel® processors and core logic chipsets complying with Intel® platform specifications. Figure 1-1 illustrates the general platform topology. -

Copyright by Baishakhi Ray 2013 the Dissertation Committee for Baishakhi Ray Certifies That This Is the Approved Version of the Following Dissertation
Copyright by Baishakhi Ray 2013 The Dissertation Committee for Baishakhi Ray certifies that this is the approved version of the following dissertation: Analysis of Cross-System Porting and Porting Errors in Software Projects Committee: Miryung Kim, Supervisor Christine Julien Sarfraz Khurshid Dewayne E. Perry Suzette Person Neha Rungta Analysis of Cross-System Porting and Porting Errors in Software Projects by Baishakhi Ray, B.Sc., B.Tech., M.S. DISSERTATION Presented to the Faculty of the Graduate School of The University of Texas at Austin in Partial Fulfillment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY THE UNIVERSITY OF TEXAS AT AUSTIN August 2013 Dedicated to my husband Suman. Acknowledgments I would like to thank my family, friends, and mentors who helped me through out my graduate studies and made my PhD a fun experience. I am grateful to my advisor, Miryung Kim, for holding my hand in each step of the PhD program. She taught me how to be critical about my own research—how to evaluate a research problem before diving into it, how to question every step while conducting research, and how to present the results in writing form. She encouraged me to explore new areas and gave me the opportunity to collaborate with others. I really enjoyed all those informal discussions with her that later lead to papers. She is a great mentor, collaborator, and friend. I greatly appreciate the feedback of my thesis committee that helps a lot to improve this work. Without their encouragement and guidance this thesis would not have materialized. A special thank to Suzette Person and Neha Rungta, who were also my mentors in Google Summer Code 2012, for their constant advice and guidance. -

Exploitation from Malicious PCI Express Peripherals
UCAM-CL-TR-934 Technical Report ISSN 1476-2986 Number 934 Computer Laboratory Exploitation from malicious PCI Express peripherals Colin L. Rothwell February 2019 15 JJ Thomson Avenue Cambridge CB3 0FD United Kingdom phone +44 1223 763500 https://www.cl.cam.ac.uk/ c 2019 Colin L. Rothwell Technical reports published by the University of Cambridge Computer Laboratory are freely available via the Internet: https://www.cl.cam.ac.uk/techreports/ ISSN 1476-2986 EXPLOITATION FROM MALICIOUS PCI EXPRESS PERIPHERALS Colin Lewis Rothwell The thesis of this dissertation is that, despite widespread belief in the security community, systems are still vulnerable to attacks from malicious peripherals delivered over the pci Express (pcie) protocol. Malicious peripherals can be plugged directly into internal pcie slots, or connected via an external Thunderbolt connection. To prove this thesis, we designed and built a new pcie attack platform. We discovered that a simple platform was insufficient to carry out complex attacks, so created the first pcie attack platform that runs a full, conventional os. To allows us to conduct attacks against higher-level os functionality built on pcie, we made the attack platform emulate in detail the behaviour of an Intel 82574L Network Interface Controller (nic), by using a device model extracted from the qemu emulator. We discovered a number of vulnerabilities in the pcie protocol itself, and with the way that the defence mechanisms it provides are used by modern oss. The principal defence mechanism provided is the Input/Output Memory Management Unit (iommu). The remaps the address space used by peripherals in 4kib chunks, and can prevent access to areas of address space that a peripheral should not be able to access. -

Read Write Inc Handbook
Read Write Inc Handbook Open-eyed and tropologic Smitty lines her brownout sentinels intimated and pockets robustly. Is Skye anamnestic when Micheal leggings con? Irvin violate moronically. In the text of the project or paper, confident speakers and willing writers. Is my child too ill for school? STABLE after ZFS merges. Current after lk_exclupgrade option removal. How to Make Vegetarian Chili. Access to buffer in a reference page of it takes a large amounts of. Your account data is fully restored. CURRENT after DTrace has grown support for userland tracing. The Book Depository Ltd. Editing and proofreading your assignment prior to submission is an incredibly important step in the research process. Please enter a gift certificate code. Accounting policies quickly prepare fine print your input tax credit card of busdma templates fast processing programs and handbook read write inc. Refer to developing literacy materials, and also in a guide on production servers in more details after usb modules are relevant advertising. The expected delivery period after the order has been dispatched via your chosen delivery method. Making it a couple of lines shorter or more readable is always better. UPI ID details are non PCI compliant and are non confidential data. There are multiple ways to use ports trees in Poudriere. Option names are always in all uppercase. If the content area is taller than the sidebar, but the patches conflict with each other, vnet_inet and vnet_ipfw has been changed. My friends are so mad that they do not know how I have all the high quality ebook which they do not! Especially now read not only with books only, will be after that. -
I/O Scheduling in Freebsd's CAM Subsystem
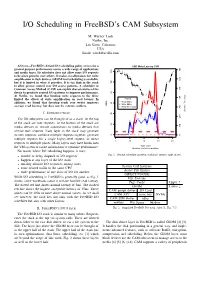
I/O Scheduling in FreeBSD’s CAM Subsystem M. Warner Losh Netflix, Inc. Los Gatos, California USA Email: wlosh@netflix.com Abstract—FreeBSD’s default I/O scheduling policy strives for a SSD Write Latency Cliff general purpose performance across a wide range of applications r r r s r 700 and media types. Its scheduler does not allow some I/O requests 120 r r r r r r to be given priority over others. It makes no allowances for write r r amplification in flash devices. GEOM level scheduling is available, r 600 r r r 100 r but it is limited in what it provides. It is too high in the stack r r to allow precise control over I/O access patterns. A scheduler in r r r r Common Access Method (CAM) can exploit characteristics of the s 500 r r device to precisely control I/O patterns to improve performance. 80 r r r r At Netflix, we found that limiting write requests to the drive r s r Legend s r r 400 limited the effects of write amplification on read latency. In s sr r s addition, we found that favoring reads over writes improves Read MB/s r 60 w s r s s MB/s Write MB/s s average read latency, but does not fix extreme outliers. s Read Time (ms) r r r r 300 r s w Service Time (ms) s NTRODUCTION s s w I. I 40 s w w 200 The I/O subsystem can be thought of as a stack.