Introducing PROC SIMSYSTEM for Systematic Nonnormal Simulation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
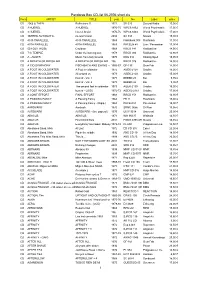
Pandoras Box CD-List 06-2006 Short
Pandoras Box CD-list 06-2006 short.xls Form ARTIST TITLE year No Label price CD 2066 & THEN Reflections !! 1971 SB 025 Second Battle 15,00 € CD 3 HUEREL 3 HUEREL 1970-75 WPC6 8462 World Psychedelic 17,00 € CD 3 HUEREL Huerel Arisivi 1970-75 WPC6 8463 World Psychedelic 17,00 € CD 3SPEED AUTOMATIC no man's land 2004 SA 333 Nasoni 15,00 € CD 49 th PARALLELL 49 th PARALLELL 1969 Flashback 008 Flashback 11,90 € CD 49TH PARALLEL 49TH PARALLEL 1969 PACELN 48 Lion / Pacemaker 17,90 € CD 50 FOOT HOSE Cauldron 1968 RRCD 141 Radioactive 14,90 € CD 7 th TEMPLE Under the burning sun 1978 RRCD 084 Radioactive 14,90 € CD A - AUSTR Music from holy Ground 1970 KSG 014 Kissing Spell 19,95 € CD A BREATH OF FRESH AIR A BREATH OF FRESH AIR 196 RRCD 076 Radioactive 14,90 € CD A CID SYMPHONY FISCHBACH AND EWING - (21966CD) -67 GF-135 Gear Fab 14,90 € CD A FOOT IN COLDWATER A Foot in coldwater 1972 AGEK-2158 Unidisc 15,00 € CD A FOOT IN COLDWATER All around us 1973 AGEK-2160 Unidisc 15,00 € CD A FOOT IN COLDWATER best of - Vol. 1 1973 BEBBD 25 Bei 9,95 € CD A FOOT IN COLDWATER best of - Vol. 2 1973 BEBBD 26 Bei 9,95 € CD A FOOT IN COLDWATER The second foot in coldwater 1973 AGEK-2159 Unidisc 15,00 € CD A FOOT IN COLDWATER best of - (2CD) 1972-73 AGEK2-2161 Unidisc 17,90 € CD A JOINT EFFORT FINAL EFFORT 1968 RRCD 153 Radioactive 14,90 € CD A PASSING FANCY A Passing Fancy 1968 FB 11 Flashback 15,00 € CD A PASSING FANCY A Passing Fancy - (Digip.) 1968 PACE-034 Pacemaker 15,90 € CD AARDVARK Aardvark 1970 SRMC 0056 Si-Wan 19,95 € CD AARDVARK AARDVARK - (lim. -

Leonard Bernstein
chamber music with a modernist edge. His Piano Sonata (1938) reflected his Leonard Bernstein ties to Copland, with links also to the music of Hindemith and Stravinsky, and his Sonata for Clarinet and Piano (1942) was similarly grounded in a neoclassical aesthetic. The composer Paul Bowles praised the clarinet sonata as having a "tender, sharp, singing quality," as being "alive, tough, integrated." It was a prescient assessment, which ultimately applied to Bernstein’s music in all genres. Bernstein’s professional breakthrough came with exceptional force and visibility, establishing him as a stunning new talent. In 1943, at age twenty-five, he made his debut with the New York Philharmonic, replacing Bruno Walter at the last minute and inspiring a front-page story in the New York Times. In rapid succession, Bernstein Leonard Bernstein photo © Susech Batah, Berlin (DG) produced a major series of compositions, some drawing on his own Jewish heritage, as in his Symphony No. 1, "Jeremiah," which had its first Leonard Bernstein—celebrated as one of the most influential musicians of the performance with the composer conducting the Pittsburgh Symphony in 20th century—ushered in an era of major cultural and technological transition. January 1944. "Lamentation," its final movement, features a mezzo-soprano He led the way in advocating an open attitude about what constituted "good" delivering Hebrew texts from the Book of Lamentations. In April of that year, music, actively bridging the gap between classical music, Broadway musicals, Bernstein’s Fancy Free was unveiled by Ballet Theatre, with choreography by jazz, and rock, and he seized new media for its potential to reach diverse the young Jerome Robbins. -

The Routledge Companion to Actor-Network Theory
The Routledge Companion to Actor-Network Theory This companion explores ANT as an intellectual practice, tracking its movements and engagements with a wide range of other academic and activist projects. Showcasing the work of a diverse set of ‘second generation’ ANT scholars from around the world, it highlights the exciting depth and breadth of contemporary ANT and its future possibilities. The companion has 38 chapters, each answering a key question about ANT and its capacities. Early chapters explore ANT as an intellectual practice and highlight ANT’s dialogues with other fields and key theorists. Others open critical, provocative discussions of its limitations. Later sections explore how ANT has been developed in a range of so cial scientific fields and how it has been used to explore a wide range of scales and sites. Chapters in the final section discuss ANT’s involvement in ‘real world’ endeavours such as disability and environmental activism, and even running a Chilean hospital. Each chapter contains an overview of relevant work and introduces original examples and ideas from the authors’ recent research. The chapters orient readers in rich, complex fields and can be read in any order or combination. Throughout the volume, authors mobilise ANT to explore and account for a range of exciting case studies: from wheelchair activism to parliamentary decision-making; from racial profiling to energy consumption monitoring; from queer sex to Korean cities. A comprehensive introduction by the editors explores the significance of ANT more broadly and provides an overview of the volume. The Routledge Companion to Actor-Network Theory will be an inspiring and lively companion to aca- demics and advanced undergraduates and postgraduates from across many disciplines across the social sciences, including Sociology, Geography, Politics and Urban Studies, Environmental Studies and STS, and anyone wishing to engage with ANT, to understand what it has already been used to do and to imagine what it might do in the future. -

The Alignment of Screens
The Alignment of Screens Felipe Raglianti , B.A.; M.A. Submitted for the degree of Doctor of Philosophy (PhD) Department of Sociology, Lancaster University, 2016 Declaration I declare that this thesis is my own work and that it has not been submitted in any form for the award of a higher degree elsewhere. Felipe Raglianti, June 2016 1 Abstract This thesis makes a distinction between screen and surface. It proposes that an inquiry into screens includes, but is not limited to, the study of surfaces. Screens and screening practices are about doing both divisions and vision. The habit of reducing screens to the display neglects their capacity to emplace separations (think of folding screens). In this thesis an investigation of screens becomes a matter of asking how surfaces and the gaps in between them articulate alignments of people and things with displays that, in practice, always leave something out of sight. Rather than losing touch with screens by reducing them to surfaces, in other words, I am interested in alternative screen configurations. For this task I sketch an approach that touches on screens through the figures of lines, surfaces, textures, folds, knots and cuts. Lines help me to make the case for thinking about screens as alignments. I then ask what kinds of observers emerge from reducing screens to single or digital surfaces. I trace that concern with Google Glass, a pair of “smartglasses” with a transparent display. To distinguish between screen and surface I suggest, through a study of biodetection and assistance dogs, how to qualify or texture screens within webs of relations. -

Cangoma Calling Spirits and Rhythms of Freedom in Brazilian Jongo Slavery Songs
Cangoma Calling Spirits and Rhythms of Freedom in Brazilian Jongo Slavery Songs Cangoma Calling Spirits and Rhythms of Freedom in Brazilian Jongo Slavery Songs Edited by Pedro Meira Monteiro Michael Stone luso-asio-afro-brazilian studies & theory 3 Editor Victor K. Mendes, University of Massachusetts Dartmouth Associate Editor Gina M. Reis, University of Massachusetts Dartmouth Editorial Board Hans Ulrich Gumbrecht, Stanford University Anna M. Klobucka, University of Massachusetts Dartmouth Pedro Meira Monteiro, Princeton University João Cezar de Castro Rocha, Universidade do Estado do Rio de Janeiro Phillip Rothwell, Rutgers University, New Brunswick Miguel Tamen, Universidade de Lisboa Claire Williams, University of Oxford Cover Design Inês Sena, Lisbon © 2013 The Authors We are thankful to the Centro de Pesquisa em História Social da Cultura (Cecult) and the Arquivo Edgar Leuenroth (AEL) at Unicamp for permission to reproduce the images in this book including the cover image. Library of Congress Cataloging-in-Publication Data Cangoma calling : spirits and rhythms of freedom in Brazilian jongo slavery songs / edited by Pedro Meira Monteiro ; Michael Stone. pages ; cm. -- (Luso-Asio-Afro-Brazilian studies & theory ; 3) Includes bibliographical references and index. ISBN 978-0-9814580-2-1 (alk. paper) 1. Jongos (Music)--History and criticism. 2. Blacks--Brazil--Music--History and criticism. 3. Music--Social aspects--Brazil. I. Monteiro, Pedro Meira. II. Stone, Michael. ML3575.B7C25 2013 781.62’96981--dc23 2012012085 Table of Contents Preface: A (Knotted) Stitch in Time, Weaving Connections Between Collections 7 Gage Averill Introduction: Jongos, the Creativity of the Enslaved and Beyond 11 Pedro Meira Monteiro and Michael Stone A Marvelous Journey 19 Stanley Stein Vassouras and the Sounds of Captivity in Southeast Brazil 25 Silvia Hunold Lara Memory Hanging by a Wire: Stanley J. -

Comhaltas Ceoltóirí Éireann (The Irish Musicians' Association) and the Politics of Musical Community in Irish Traditional Music
City University of New York (CUNY) CUNY Academic Works All Dissertations, Theses, and Capstone Projects Dissertations, Theses, and Capstone Projects 2-2015 Comhaltas Ceoltóirí Éireann (The Irish Musicians' Association) and the Politics of Musical Community in Irish Traditional Music Lauren Weintraub Stoebel Graduate Center, City University of New York How does access to this work benefit ou?y Let us know! More information about this work at: https://academicworks.cuny.edu/gc_etds/627 Discover additional works at: https://academicworks.cuny.edu This work is made publicly available by the City University of New York (CUNY). Contact: [email protected] COMHALTAS CEOLTÓIRÍ ÉIREANN (THE IRISH MUSICIANS’ ASSOCIATION) AND THE POLITICS OF MUSICAL COMMUNITY IN IRISH TRADITIONAL MUSIC By LAUREN WEINTRAUB STOEBEL A dissertation submitted to the Graduate Faculty in Music in partial fulfillment of the requirements for the degree of Doctor of Philosophy, The City University of New York 2015 ii © 2015 LAUREN WEINTRAUB STOEBEL All Rights Reserved iii This manuscript has been read and accepted for the Graduate Faculty in Music in satisfaction of the dissertation requirement for the degree of Doctor of Philosophy. Peter Manuel______________________________ ________________ _________________________________________ Date Chair of Examining Committee Norman Carey_____________________________ ________________ _________________________________________ Date Executive Officer Jane Sugarman___________________________________________ Stephen Blum_____________________________________________ Sean Williams____________________________________________ Supervisory Committee THE CITY UNIVERSITY OF NEW YORK iv Abstract COMHALTAS CEOLTÓIRÍ ÉIREANN (THE IRISH MUSICIANS’ ASSOCIATION) AND THE POLITICS OF MUSICAL COMMUNITY IN IRISH TRADITIONAL MUSIC By LAUREN WEINTRAUB STOEBEL Advisor: Jane Sugarman This dissertation examines Comhaltas Ceoltóirí Éireann (The Irish Musicians’ Association) and its role in the politics of Irish traditional music communities. -

EURASIA MAILORDER Prog List 2021/8/2 Updated How to Order
EURASIA MAILORDER Prog List 2021/9/1 updated How to Order 0.720 ALEACION [SAME] (MEX / PRIVATE / 86 / WI) EX/EX USD 61 / EURO52 14 BIS [A IDADE DA LUZ] (BRA / EMI / 82 / WI) EX/EX USD 34 / EURO29 14 BIS [ALEM PARAISO] (BRA / EMI / 82 / WI) EX/EX USD 34 / EURO29 14 BIS [ESPELHO DAS AGUAS] (BRA / EMI / 81 / WI) EX/EX USD 34 / EURO29 14 BIS [II] (BRA / EMI / 80 / WI) EX/EX USD 34 / EURO29 14 BIS [SAME] (BRA / EMI / 79 / ) EX/EX USD 34 / EURO29 14 BIS [SETE] (BRA / EMI / 82 / WI) EX/EX USD 34 / EURO29 1979 IL CONCERTO [V.A.] (ITA / CRAMPS / 79 / 2LP/FOC) EX/EX USD 34 / EURO29 220 VOLT [MIND OVER MUSCLE] (HOL / CBS / 85 / WI) EX/EX USD 25 / EURO21 5 U U'S [SAME] (US / PRIVATE / 86 / WI/WB) M-/EX USD 34 / EURO29 A BARCA DO SOL [PIRATA] (BRA / PRIVATE / 79 / ) EX/EX USD 90 / EURO76 A BARCA DO SOL [SAME] (BRA / CONTINENTAL / 74 / ) EX/EX USD 151 / EURO127 A BOLHA [E PROIBIDO FUMAR] (BRA / POLYDOR / 77 / FOC) EX-/VG+ USD 70 / EURO59 A BOLHA [UM PASSO A FRENTE] (BRA / CONTINENTAL / 73 / FOC) EX/EX USD 288 / EURO242 A THINKING PLAGUE [SAME] (US / ENDEMIC MUSIC / 84 / WI) EX+/EX- USD 79 / EURO67 A. ASPELUND / L.MUGARULA [KARIBU] (FIN / DELTA / 76 / WI) M-/M- USD 34 / EURO29 ABACUS [EVERYTHING YOU NEED] (GER / GREEN TREE RECORDS / 12 / RE) M/M USD 16 / EURO14 ABACUS [SAME] (GER / POLYDOR / 71 / ) EX+/EX- USD 169 / EURO142 ABISSI INFINITI [TUNNEL] (ITA / KNIGHTS / 81 / FOC) EX+/EX USD 225 / EURO189 ABISSI INFINITI [TUNNEL] (ITA / KNIGHTS / 81 / FOC) EX+/EX USD 198 / EURO167 ABUS DANGEREUX [LE QUATRIEME MOUVEMENT] (FRA / AJ RECORD / 80 / ) EX/EX USD -

Internationalising Higher Education Curricula in Italy
EMI Beyond and This collection presents the state of the art on English-me- dium instruction (EMI) / Integrating content and language (ICL) in Italian higher education, drawing attention to dif- EMI and Beyond: ferent critical aspects of the teaching/learning experience and highlighting the perspectives of various educational Internationalising Higher stakeholders regarding the effectiveness of tertiary study in a foreign language. The chapters draw on a range of methodologies, from multimodal participant observation, to Education Curricula action research, to video-stimulated recall (VSR), to ques- tionnaires and interviews, in examining language policies and practices across various educational settings. Overall, Mastellotto, Zanin (eds.) in Italy the volume suggests that internationalisation succeeds best when the form of lessons (language) and the con- Lynn Mastellotto, Renata Zanin (eds.) tent of lessons (disciplinary concepts) are constructively aligned in curriculum planning and delivery. This integra- tion process requires the strategic support of educators to guarantee the quality of learning in multilingual education. 26,00 Euro www.unibz.it/universitypress EMI and Beyond: Internationalising Higher Education Curricula in Italy Lynn Mastellotto, Renata Zanin (eds.) peer reviewed Bozen-Bolzano University Press, 2021 Free University of Bozen-Bolzano www.unibz.it/universitypress Cover design / layout: DOC.bz / bu,press Printing: dipdruck ISBN 978-88-6046-181-0 E-ISBN 978-88-6046-182-7 This work–excluding the cover and the quotations–is -

2011-Commencement-Program.Pdf
SUNDAY, THE FIFTEENTH OF MAY, Two THOUSAND AND ELEVEN TEN O'CLOCK IN THE MORNING - WALLACE WADE STADIUM DUKE UNIVERSITY COMMENCEMENT 2 0 I I ONE HUNDRED FIFTY-NINTH COMMENCEMENT Notes on Academic Dress Academic dress had its origin in the Middle Ages. When the European universities were taking form in the thirteenth and fourteenth centuries, scholars were also clerics, and they adopted Mace and Chain of Office robes similar to those of their monastic orders. Caps were a necessity in drafty buildings, and Again at commencement, ceremonial use is copes or capes with hoods attached were made of two important insignia given to Duke needed for warmth. As the control of universities University In memory of Benjamin N. Duke. gradually passed from the church, academic Both the mace and chain of office are the gifts costume began to take on brighter hues and to of anonymous donors and of the Mary Duke employ varied patterns in cut and color of gown Biddle Foundation. They were des1gned and and type of headdress. executed by Professor Kurt J. Matzdorf of New The use of academic costume in the United Paltz, New York, and were dedicated and first States has been continuous since Colonial times, used at the inaugural ceremonies of President but a dear protocol did not emerge until an Sanford in 1970. intercollegiate commission in 1893 recommended The Mace, the symbol of authority of the a uniform code. In this country, the design of a University, is made of sterling silver throughout. gown varies with the degree held. The bachelor's lt is thirty-seven inches long and weighs about gown is relatively simple with long pointed Significance of Colors eight pounds. -
Simulation and Modeling Techniques for Signal Integrity and Electromagnetic Interference on High Frequency Electronic Systems
Simulation and Modeling Techniques for Signal Integrity and Electromagnetic Interference on High Frequency Electronic Systems. by Luca Daniel Laurea (University of Padua, Italy) 1996 A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Engineering - Electrical Engineering and Computer Sciences in the GRADUATE DIVISION of the UNIVERSITY of CALIFORNIA at BERKELEY Committee in charge: Professor Alberto L Sangiovanni-Vincentelli, Chair Professor Jacob K White Professor Robert K Brayton Professor Ole H Hald Spring 2003 2 The dissertation of Luca Daniel is approved: Chair Date Date Date Date University of California at Berkeley Spring 2003 4 Simulation and Modeling Techniques for Signal Integrity and Electromagnetic Interference on High Frequency Electronic Systems. Copyright 2003 by Luca Daniel 6 1 Abstract Simulation and Modeling Techniques for Signal Integrity and Electromagnetic Interference on High Frequency Electronic Systems. by Luca Daniel Doctor of Philosophy in Engineering - Electrical Engineering and Computer Sciences University of California at Berkeley Professor Alberto L Sangiovanni-Vincentelli, Chair Many future electronic systems will consist of several significantly heterogeneous modules such as Opto- Electronic and analog RF links, mixed-signal analog to digital converters (ADC), digital signal processors (DSP), Central Processor Units (CPU), Memory modules, Microfabricated Electro-Mechanical (MEM) res- onators, sensors and actuators with power electronics converters. When assembling such an heterogeneous set of modules on a single package (Systems on Package: SoP) or integrated circuit substrate (Systems on Chip: SoC), compatibility issues are soon to arise from many possible point of views. In this thesis, we will address the physical electromagnetic point of view. -

Dissertation Addresses One of the Most Popular Management Control Practices Adopted Worldwide Over the Last Three Decades: the Practice of Risk Management
A Service of Leibniz-Informationszentrum econstor Wirtschaft Leibniz Information Centre Make Your Publications Visible. zbw for Economics Neerup Themsen, Tim Doctoral Thesis Risk Management in Large Danish Public Capital Investment Programmes PhD Series, No. 41.2014 Provided in Cooperation with: Copenhagen Business School (CBS) Suggested Citation: Neerup Themsen, Tim (2014) : Risk Management in Large Danish Public Capital Investment Programmes, PhD Series, No. 41.2014, ISBN 9788793155831, Copenhagen Business School (CBS), Frederiksberg, http://hdl.handle.net/10398/9053 This Version is available at: http://hdl.handle.net/10419/208917 Standard-Nutzungsbedingungen: Terms of use: Die Dokumente auf EconStor dürfen zu eigenen wissenschaftlichen Documents in EconStor may be saved and copied for your Zwecken und zum Privatgebrauch gespeichert und kopiert werden. personal and scholarly purposes. Sie dürfen die Dokumente nicht für öffentliche oder kommerzielle You are not to copy documents for public or commercial Zwecke vervielfältigen, öffentlich ausstellen, öffentlich zugänglich purposes, to exhibit the documents publicly, to make them machen, vertreiben oder anderweitig nutzen. publicly available on the internet, or to distribute or otherwise use the documents in public. Sofern die Verfasser die Dokumente unter Open-Content-Lizenzen (insbesondere CC-Lizenzen) zur Verfügung gestellt haben sollten, If the documents have been made available under an Open gelten abweichend von diesen Nutzungsbedingungen die in der dort Content Licence (especially -

China Today a Festival of Chinese Composition 当代中国 一场中国作曲创作的盛典 the Juilliard School Presents
Focus! Festival China Today A Festival of Chinese Composition 当代中国 一场中国作曲创作的盛典 The Juilliard School presents The 34th annual Focus! festival Focus! 2018 China Today: A Festival of Chinese Composition Joel Sachs, Director TABLE OF CONTENTS 1 Introduction to Focus! 2018 5 Program I Friday, January 19, 7:30pm 12 Program II Monday, January 22, 7:30pm 19 Program III Tuesday, January 23 Preconcert Forum, 6:30pm; Concert, 7:30pm 26 Program IV Wednesday, January 24, 7:30pm 33 Program V Thursday, January 25, 7:30pm 39 Program VI Friday, January 26, 7:30pm 48 Focus! Staff This performance is supported in part by the Muriel Gluck Production Fund. Please make certain that all electronic devices are turned off during the performance. The taking of photographs and the use of recording equipment are not permitted in this auditorium. Introduction to Focus! 2018 By Joel Sachs Almost a year ago, Juilliard president Joseph W. Polisi and I convened to consider the theme of the coming Focus! festival, a concept we jointly created in his first semester as president in 1984. This time, however, contemplating his final festival as Juilliard’s president, Dr. Polisi had a specific request—a focus on China, linked to the milestone project with which his tenure is culminating: the establishment of Juilliard’s campus in Tianjin. While China had been in my mind as a Focus! topic for years it always got pushed aside, largely by the thought of what would be involved in trying to survey the composers of such a huge, diverse, and culturally rich nation.