Pweb Peer-To-Peer Web Hosting Communication System and Dynamic Web Hosting
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Attachment A
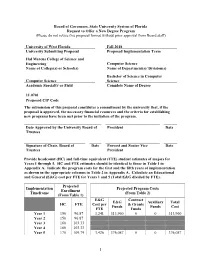
Board of Governors, State University System of Florida Request to Offer a New Degree Program (Please do not revise this proposal format without prior approval from Board staff) University of West Florida Fall 2018 University Submitting Proposal Proposed Implementation Term Hal Marcus College of Science and Engineering Computer Science Name of College(s) or School(s) Name of Department(s)/ Division(s) Bachelor of Science in Computer Computer Science Science Academic Specialty or Field Complete Name of Degree 11.0701 Proposed CIP Code The submission of this proposal constitutes a commitment by the university that, if the proposal is approved, the necessary financial resources and the criteria for establishing new programs have been met prior to the initiation of the program. Date Approved by the University Board of President Date Trustees Signature of Chair, Board of Date Provost and Senior Vice Date Trustees President Provide headcount (HC) and full-time equivalent (FTE) student estimates of majors for Years 1 through 5. HC and FTE estimates should be identical to those in Table 1 in Appendix A. Indicate the program costs for the first and the fifth years of implementation as shown in the appropriate columns in Table 2 in Appendix A. Calculate an Educational and General (E&G) cost per FTE for Years 1 and 5 (Total E&G divided by FTE). Projected Implementation Projected Program Costs Enrollment Timeframe (From Table 2) (From Table 1) E&G Contract E&G Auxiliary Total HC FTE Cost per & Grants Funds Funds Cost FTE Funds Year 1 150 96.87 3,241 313,960 0 0 313,960 Year 2 150 96.87 Year 3 160 103.33 Year 4 160 103.33 Year 5 170 109.79 3,426 376,087 0 0 376,087 1 Note: This outline and the questions pertaining to each section must be reproduced within the body of the proposal to ensure that all sections have been satisfactorily addressed. -

공개sw 솔루션 목록(2015.12.30)
OS/DBMS/WEB/WAS 공개SW 솔루션 목록(2015.12.30) 순번 분류 솔루션명 라이선스 기술지원 홈페이지 제품개요 1 DBMS C-JDBC LGPL community http://c-jdbc.ow2.org/ 데이터베이스 클러스터 2 DBMS DB4 오브젝트(db4o) GPL & dOCL prof/community http://www.db4o.com 객체지향 메모리 데이터베이스 엔진 GPL v2, GPL v3, 3 DBMS Drizzle community http://www.drizzle.org/ MySQL 6.0에서 파생된 RDBMS BSD 4 DBMS H2 EPL, MPL community http://www.h2database.com/ 자바기반 RDBMS HSQLDB 5 DBMS (Hyper Structured Query BSD community http://www.hsqldb.org 경량의 Java 기반 관계형 데이터베이스 Language Database) 데이터 웨어하우스, OLAP서버, BI 시스템 운용을 목적으 6 DBMS LucidDB GPL v2, LGPL v2 community http://luciddb.sourceforge.net 로 개발된 오픈소스 DBMS GPL v3, AGPL v3, 7 DBMS Neo4j community http://www.neo4j.org 그래프 데이터베이스 commercial AGPL v3, 8 DBMS VoltDB Proprietary prof/community http://voltdb.com/ 인메모리기반 RDBMS License 오픈소스 관계형 데이터베이스 관리 시스템. 9 DBMS 마리아DB(MariaDB) GPLv2, LGPL prof/community https://mariadb.org/ MySQL과 동일한 소스 코드를 기반 세계에서 가장 널리 사용되고 있는 대표적인 10 DBMS 마이에스큐엘(MySQL) GPL v2 prof/community http://www.mysql.com 관계형 데이터베이스 ※ prof : Professional Support(전문업체 기술지원) ※ community : Community Support(커뮤니티 기술지원) OS/DBMS/WEB/WAS 공개SW 솔루션 목록(2015.12.30) 순번 분류 솔루션명 라이선스 기술지원 홈페이지 제품개요 IBM에서 기증한 cloudscape 소스 기반으로 11 DBMS 아파치 더비(Apache Derby) Apache v2 community http://db.apache.org/derby/ 개발된 Java 기반의 관계형 데이터베이스 Berkeley 오라클 버클리 DB Database License http://www.oracle.com/kr/products/database/ 슬리피캣을 인수한 오라클에서 제공하는 12 DBMS prof/community (Oracle Berkeley DB) or berkeley-db/index.html 고성능 임베디드 데이터베이스 Sleepycat License GPL or Postgresql 데이터베이스의 기반으로 상용화된 13 DBMS 잉그레스(Ingres) prof/community -

Deviceside Software Update Strategies for Automotive Grade Linux
Deviceside Software Update Strategies for Automotive Grade Linux Konsulko Group, sponsored by ATS Advanced Telematic Systems GmbH Overview This whitepaper explores the area of software update strategies for devices running Automotive Grade Linux. The starting point is understanding several key use cases for updating software in an AGL1 system. Several open source deviceside software update mechanisms are compared with a focus on their ability to meet the stated use cases. Finally, recommendations are made for an approach that can be implemented for inclusion in AGL. Use Cases and Requirements The topic of software update on any computing device is very broad and can only be examined properly by narrowing the scope of the system, operating conditions, and the policies established for executing a software update. The following sections describe the use cases considered when evaluating the various mechanisms that could be employed in an AGL software update strategy. System Description AGL systems include both IVI2 and ADAS3 devices that run Linux on at least one processor in the system. The complete IVI or ADAS system is not necessarily limited to a single processing node, but is normally part of a larger network that includes a number of ECU4 nodes throughout the automobile. Due to this distributed architecture it is often necessary to update software on 1 Automotive Grade Linux (https://www.automotivelinux.org/aglspecification) 2 InVehicle Infotainment 3 Advanced Driver Assistance System 4 Electronic Control Unit Copyright 2016 Konsulko Group and ATS Advanced Telematic Systems GmbH CC BYSA 3.0 US (https://creativecommons.org/licenses/bysa/3.0/us/) the ECUs as well as the node running AGL. -

Python Language
Python Language #python Table of Contents About 1 Chapter 1: Getting started with Python Language 2 Remarks 2 Versions 3 Python 3.x 3 Python 2.x 3 Examples 4 Getting Started 4 Verify if Python is installed 4 Hello, World in Python using IDLE 5 Hello World Python file 5 Launch an interactive Python shell 6 Other Online Shells 7 Run commands as a string 7 Shells and Beyond 8 Creating variables and assigning values 8 User Input 12 IDLE - Python GUI 13 Troubleshooting 14 Datatypes 15 Built-in Types 15 Booleans 15 Numbers 15 Strings 16 Sequences and collections 16 Built-in constants 17 Testing the type of variables 18 Converting between datatypes 18 Explicit string type at definition of literals 19 Mutable and Immutable Data Types 19 Built in Modules and Functions 20 Block Indentation 24 Spaces vs. Tabs 25 Collection Types 25 Help Utility 30 Creating a module 31 String function - str() and repr() 32 repr() 33 str() 33 Installing external modules using pip 34 Finding / installing a package 34 Upgrading installed packages 34 Upgrading pip 35 Installation of Python 2.7.x and 3.x 35 Chapter 2: *args and **kwargs 38 Remarks 38 h11 38 h12 38 h13 38 Examples 39 Using *args when writing functions 39 Using **kwargs when writing functions 39 Using *args when calling functions 40 Using **kwargs when calling functions 41 Using *args when calling functions 41 Keyword-only and Keyword-required arguments 42 Populating kwarg values with a dictionary 42 **kwargs and default values 42 Chapter 3: 2to3 tool 43 Syntax 43 Parameters 43 Remarks 44 Examples 44 Basic -

An Analysis of Python's Topics, Trends, and Technologies Through Mining Stack Overflow Discussions
1 An Analysis of Python’s Topics, Trends, and Technologies Through Mining Stack Overflow Discussions Hamed Tahmooresi, Abbas Heydarnoori, and Alireza Aghamohammadi F Abstract—Python is a popular, widely used, and general-purpose pro- (LDA) [3] to categorize discussions in specific areas such gramming language. In spite of its ever-growing community, researchers as web programming [4], mobile application development [5], have not performed much analysis on Python’s topics, trends, and tech- security [6], and blockchain [7]. However, none of them has nologies which provides insights for developers about Python commu- focused on Python. In this study, we shed light on the nity trends and main issues. In this article, we examine the main topics Python’s main areas of discussion through mining 2 461 876 related to this language being discussed by developers on one of the most popular Q&A websites, Stack Overflow, as well as temporal trends posts, from August 2008 to January 2019, using LDA based through mining 2 461 876 posts. To be more useful for the software topic modeling . We also analyze the temporal trends of engineers, we study what Python provides as the alternative to popular the extracted topics to find out how the developers’ interest technologies offered by common programming languages like Java. is changing over the time. After explaining the topics and Our results indicate that discussions about Python standard features, trends of Python, we investigate the technologies offered web programming, and scientific programming 1 are the most popular by Python, which are not properly revealed by the topic areas in the Python community. -
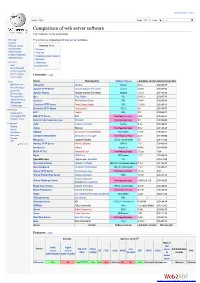
Comparison of Web Server Software from Wikipedia, the Free Encyclopedia
Create account Log in Article Talk Read Edit ViewM ohrisetory Search Comparison of web server software From Wikipedia, the free encyclopedia Main page This article is a comparison of web server software. Contents Featured content Contents [hide] Current events 1 Overview Random article 2 Features Donate to Wikipedia 3 Operating system support Wikimedia Shop 4 See also Interaction 5 References Help 6 External links About Wikipedia Community portal Recent changes Overview [edit] Contact page Tools Server Developed by Software license Last stable version Latest release date What links here AOLserver NaviSoft Mozilla 4.5.2 2012-09-19 Related changes Apache HTTP Server Apache Software Foundation Apache 2.4.10 2014-07-21 Upload file Special pages Apache Tomcat Apache Software Foundation Apache 7.0.53 2014-03-30 Permanent link Boa Paul Phillips GPL 0.94.13 2002-07-30 Page information Caudium The Caudium Group GPL 1.4.18 2012-02-24 Wikidata item Cite this page Cherokee HTTP Server Álvaro López Ortega GPL 1.2.103 2013-04-21 Hiawatha HTTP Server Hugo Leisink GPLv2 9.6 2014-06-01 Print/export Create a book HFS Rejetto GPL 2.2f 2009-02-17 Download as PDF IBM HTTP Server IBM Non-free proprietary 8.5.5 2013-06-14 Printable version Internet Information Services Microsoft Non-free proprietary 8.5 2013-09-09 Languages Jetty Eclipse Foundation Apache 9.1.4 2014-04-01 Čeština Jexus Bing Liu Non-free proprietary 5.5.2 2014-04-27 Galego Nederlands lighttpd Jan Kneschke (Incremental) BSD variant 1.4.35 2014-03-12 Português LiteSpeed Web Server LiteSpeed Technologies Non-free proprietary 4.2.3 2013-05-22 Русский Mongoose Cesanta Software GPLv2 / commercial 5.5 2014-10-28 中文 Edit links Monkey HTTP Server Monkey Software LGPLv2 1.5.1 2014-06-10 NaviServer Various Mozilla 1.1 4.99.6 2014-06-29 NCSA HTTPd Robert McCool Non-free proprietary 1.5.2a 1996 Nginx NGINX, Inc. -

Problems and Alternative Approaches Expanding the Scope of Software
Expanding the Scope of Software Product Families: Problems and Alternative Approaches Jan Bosch VP, Head of Software and Application Technologies Laboratory Nokia Research Center Helsinki, Finland [email protected] © 2006 Nokia QoSA/CBSE 2006/ June 2006 Some background • Nokia Research Center since fall 2004 • Professor and Head of Software Engineering group at University of Groningen, The Netherlands - earlier head of RISE research group @ Blekinge Institute of Technology, Sweden. • Collaboration through research and consulting with, among others, Philips, Bosch, Thales, Baan, Avaya, Ericsson, etc. • Working IEEE/IFIP Conference on Software Architecture series, programme chair (2002), general chair (2004), steering committee member • Software Product Line Conference series • EU and ITEA projects, e.g. SeCSE (Service Centric Software Engineering) © 2006 Nokia QoSA/CBSE 2006/ June 2006 Overview • Introduction • Nokia and Nokia Research Center • Trends in Software • Platforms for Nokia Mobile Devices • Problems and Challenges • Alternative approaches • Conclusions © 2006 Nokia QoSA/CBSE 2006/ June 2006 R&D in Nokia • Global network with R&D centers in 11 countries • Over 20,882 people in R&D at the end of 2005 • R&D personnel represents 36% of Nokia’s total workforce • Nokia’s R&D expenditure totaled EUR 3,825 million in 2005 (11.2% of net sales) All figures are from Dec, 2005 © 2006 Nokia QoSA/CBSE 2006/ June 2006 Nokia Research Center – world-class expertise • Founded in 1986 • 1,097 employees at the end of 2005, or 5% of Nokia’s R&D -

Final Report
Team 4 - Rescue Drone Final Report Members Alexandra Borgesen [email protected] Peter Burchell [email protected] Cody Campbell [email protected] Shawn Cho [email protected] Sarah Hood [email protected] Halil Yonter [email protected] Sponsor Mr. David F. Merrick Faculty Advisor Dr. Rodney Roberts Instructor Dr. Jerris Hooker Reviewers Dr. Bruce Harvey Dr. Simon Foo 04/21/2017 Team 4 Final Report Rescue Drone Executive Summary UAVs used by Florida State University’s Emergency Management and Homeland Security Program can autonomously scan an area, but will provide no feedback regarding image contents, nor do they have a user-friendly interface for interprocess communication. The multidisciplinary ECE Senior Design Team #4 was tasked with creating a new, unique UAV capable of scanning disaster zones and identifying unique objects of interest. Careful research and planning has led to an innovative flight control architecture. The final product features a powerful onboard computer capable of live image processing for object detection, with distinct algorithms for color filtering and pedestrian tracking. A conversion algorithm was also implemented for converting the UAV’s latitude and longitude data, which is read from the flight control hardware, into USNG format. An IP network governs all communication between the ground station and the UAV. In the pursuit of increasing autonomy and implementing computer vision, a reliable and consistent object detection remains integral to accomplishing this task. By analyzing an image in search of HSV values that satisfy a predetermined range of color, any region of pixels that comply with the given range is highlighted using the color filtering algorithm. -

STONE FAB CATALOG 2020-V1 Your Stone, Tile and Concrete Tool Supply Experts Since 1971
STONE FAB CATALOG 2020-V1 Your stone, tile and concrete tool supply experts since 1971 C • Less risk of damaging tools • Increase tools life • Quicker set up • Better accuracy • Increase productivity • Increase parameters • Overall better quality © Grabo Nemo Portable Aardwolf Thin Material ® Electric Vacuum Cup Diarex VB Core Drills Slab Gripper Alpha AIR-830/850 see page 166 see page 78 & 81 see page 156 see page 231 STONE FAB CATALOG, 2020-V1 WWW.GRANQUARTZ.CA Dear valued customers, It’s just now been a year since we’ve implemented our new Enterprise Resource Planning (ERP) System. Despite the amount of preparation involved in this transition, it was a rough period to adapt to our new system and still offer the same level of service. Even after the change of system, we faced many unpredictable issues necessitating quick and efficient decisions altering the processes that were previously agreed on. Throughout all these challenges, our team worked together to ensure that we continued to offer the best possible service to you. We thank you for your patience and understanding as we sorted out those issues. Now that we have a solid foundation, we plan to work on numerous other projects that will connect with our ERP database to offer better and quicker solutions to you. During the previous year we have begun offering what we call the “Zoller service” for calibrating CNC tools so that you can save hours when you set up new tools or redressed tools on your CNC machine. If you haven’t heard of this service please ask your local sales and service representative or our customer service agents for more information. -

SOPHOS IPS Signature Update Release Notes
SOPHOS IPS Signature Update Release Notes Version : 9.16.41 Release Date : 31st October 2019 IPS Signature Update Release Information Upgrade Applicable on IPS Signature Release Version 9.16.40 CR250i, CR300i, CR500i-4P, CR500i-6P, CR500i-8P, CR500ia, CR500ia-RP, CR500ia1F, CR500ia10F, CR750ia, CR750ia1F, CR750ia10F, CR1000i-11P, CR1000i-12P, CR1000ia, CR1000ia10F, CR1500i-11P, CR1500i-12P, CR1500ia, CR1500ia10F Sophos Appliance Models CR25iNG, CR25iNG-6P, CR35iNG, CR50iNG, CR100iNG, CR200iNG/XP, CR300iNG/XP, CR500iNG- XP, CR750iNG-XP, CR2500iNG, CR25wiNG, CR25wiNG-6P, CR35wiNG, CRiV1C, CRiV2C, CRiV4C, CRiV8C, CRiV12C, XG85 to XG450, SG105 to SG650 Upgrade Information Upgrade type: Automatic Compatibility Annotations: None Introduction The Release Note document for IPS Signature Database Version 9.16.41 includes support for the new signatures. The following sections describe the release in detail. New IPS Signatures The Sophos Intrusion Prevention System shields the network from known attacks by matching the network traffic against the signatures in the IPS Signature Database. These signatures are developed to significantly increase detection performance and reduce the false alarms. Report false positives at [email protected], along with the application details. October 2019 Page 2 of 27 IPS Signature Update This IPS Release includes Two Hundred and Fifteen(215) signatures to address One Hundred and Eighty One(181) vulnerabilities. New signatures are added for the following vulnerabilities: Name CVE–ID Category Severity BROWSER-IE Microsoft -

Mobile Open Source Economic Analysis
Mobile Open Source Economic Analysis LiMo Foundation White Paper August 2009 ™ ™ White Paper 1 Executive Summary It is possible to use quantitative techniques to examine a number of the proposed economic benefits of open source software. The claimed benefits are a reduction in cost of acquisition, access to innovation and cost of ownership of software technology. The quantitative techniques we use to conduct our analysis are based on measuring source lines of code (SLOC) applied to publicly accessible open source project repositories. To aid our analysis, we have developed a command line tool to mine information on open source projects using the ohloh1 web service. Based on this analysis, Based on this analysis, there is a strong case for constructive engagement with there is a strong case for open source communities where the corresponding open source software constructive engagement components are used within a collaboratively developed, open mobile software with open source platform such as the LiMo Platform™. communities... There is additionally a case for mobile software platform providers to consider using certain strategic open source projects as the basis for development of new functionality on their roadmap. There is no proven case within this analysis for converting existing proprietary items already within a mobile software platform to open source. To conduct a cost-benefit analysis of that scenario would require examination of more factors than SLOC alone. 1http://www.ohloh.net ™ White Paper 1 1. Introduction The subject of open source is increasingly important in relation to mobile device platforms and in view of this, it is vital to understand the underlying economic factors driving the use of open source software in a mobile context. -

Code of Federal Regulations GPO Access
6±11±97 Wednesday Vol. 62 No. 112 June 11, 1997 Pages 31701±32020 Briefings on how to use the Federal Register For information on a briefing in Washington, DC, see the announcement on the inside cover of this issue. Now Available Online Code of Federal Regulations via GPO Access (Selected Volumes) Free, easy, online access to selected Code of Federal Regulations (CFR) volumes is now available via GPO Access, a service of the United States Government Printing Office (GPO). CFR titles will be added to GPO Access incrementally throughout calendar years 1996 and 1997 until a complete set is available. GPO is taking steps so that the online and printed versions of the CFR will be released concurrently. The CFR and Federal Register on GPO Access, are the official online editions authorized by the Administrative Committee of the Federal Register. New titles and/or volumes will be added to this online service as they become available. http://www.access.gpo.gov/nara/cfr For additional information on GPO Access products, services and access methods, see page II or contact the GPO Access User Support Team via: ★ Phone: toll-free: 1-888-293-6498 ★ Email: [email protected] federal register 1 II Federal Register / Vol. 62, No. 112 / Wednesday, June 11, 1997 SUBSCRIPTIONS AND COPIES PUBLIC Subscriptions: Paper or fiche 202±512±1800 Assistance with public subscriptions 512±1806 General online information 202±512±1530; 1±888±293±6498 FEDERAL REGISTER Published daily, Monday through Friday, (not published on Saturdays, Sundays, or on official holidays), Single copies/back copies: by the Office of the Federal Register, National Archives and Paper or fiche 512±1800 Records Administration, Washington, DC 20408, under the Federal Assistance with public single copies 512±1803 Register Act (49 Stat.