The Impact of Code Review Coverage and Code Review Participation on Software Quality
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

MAGIC Summoning: Towards Automatic Suggesting and Testing of Gestures with Low Probability of False Positives During Use
JournalofMachineLearningResearch14(2013)209-242 Submitted 10/11; Revised 6/12; Published 1/13 MAGIC Summoning: Towards Automatic Suggesting and Testing of Gestures With Low Probability of False Positives During Use Daniel Kyu Hwa Kohlsdorf [email protected] Thad E. Starner [email protected] GVU & School of Interactive Computing Georgia Institute of Technology Atlanta, GA 30332 Editors: Isabelle Guyon and Vassilis Athitsos Abstract Gestures for interfaces should be short, pleasing, intuitive, and easily recognized by a computer. However, it is a challenge for interface designers to create gestures easily distinguishable from users’ normal movements. Our tool MAGIC Summoning addresses this problem. Given a specific platform and task, we gather a large database of unlabeled sensor data captured in the environments in which the system will be used (an “Everyday Gesture Library” or EGL). The EGL is quantized and indexed via multi-dimensional Symbolic Aggregate approXimation (SAX) to enable quick searching. MAGIC exploits the SAX representation of the EGL to suggest gestures with a low likelihood of false triggering. Suggested gestures are ordered according to brevity and simplicity, freeing the interface designer to focus on the user experience. Once a gesture is selected, MAGIC can output synthetic examples of the gesture to train a chosen classifier (for example, with a hidden Markov model). If the interface designer suggests his own gesture and provides several examples, MAGIC estimates how accurately that gesture can be recognized and estimates its false positive rate by comparing it against the natural movements in the EGL. We demonstrate MAGIC’s effectiveness in gesture selection and helpfulness in creating accurate gesture recognizers. -

Parasoft Dottest REDUCE the RISK of .NET DEVELOPMENT
Parasoft dotTEST REDUCE THE RISK OF .NET DEVELOPMENT TRY IT https://software.parasoft.com/dottest Complement your existing Visual Studio tools with deep static INCREASE analysis and advanced PROGRAMMING EFFICIENCY: coverage. An automated, non-invasive solution that the related code, and distributed to his or her scans the application codebase to iden- IDE with direct links to the problematic code • Identify runtime bugs without tify issues before they become produc- and a description of how to fix it. executing your software tion problems, Parasoft dotTEST inte- grates into the Parasoft portfolio, helping When you send the results of dotTEST’s stat- • Automate unit and component you achieve compliance in safety-critical ic analysis, coverage, and test traceability testing for instant verification and industries. into Parasoft’s reporting and analytics plat- regression testing form (DTP), they integrate with results from Parasoft dotTEST automates a broad Parasoft Jtest and Parasoft C/C++test, allow- • Automate code analysis for range of software quality practices, in- ing you to test your entire codebase and mit- compliance cluding static code analysis, unit testing, igate risks. code review, and coverage analysis, en- abling organizations to reduce risks and boost efficiency. Tests can be run directly from Visual Stu- dio or as part of an automated process. To promote rapid remediation, each problem detected is prioritized based on configur- able severity assignments, automatical- ly assigned to the developer who wrote It snaps right into Visual Studio as though it were part of the product and it greatly reduces errors by enforcing all your favorite rules. We have stuck to the MS Guidelines and we had to do almost no work at all to have dotTEST automate our code analysis and generate the grunt work part of the unit tests so that we could focus our attention on real test-driven development. -

Amigaos 3.2 FAQ 47.1 (09.04.2021) English
$VER: AmigaOS 3.2 FAQ 47.1 (09.04.2021) English Please note: This file contains a list of frequently asked questions along with answers, sorted by topics. Before trying to contact support, please read through this FAQ to determine whether or not it answers your question(s). Whilst this FAQ is focused on AmigaOS 3.2, it contains information regarding previous AmigaOS versions. Index of topics covered in this FAQ: 1. Installation 1.1 * What are the minimum hardware requirements for AmigaOS 3.2? 1.2 * Why won't AmigaOS 3.2 boot with 512 KB of RAM? 1.3 * Ok, I get it; 512 KB is not enough anymore, but can I get my way with less than 2 MB of RAM? 1.4 * How can I verify whether I correctly installed AmigaOS 3.2? 1.5 * Do you have any tips that can help me with 3.2 using my current hardware and software combination? 1.6 * The Help subsystem fails, it seems it is not available anymore. What happened? 1.7 * What are GlowIcons? Should I choose to install them? 1.8 * How can I verify the integrity of my AmigaOS 3.2 CD-ROM? 1.9 * My Greek/Russian/Polish/Turkish fonts are not being properly displayed. How can I fix this? 1.10 * When I boot from my AmigaOS 3.2 CD-ROM, I am being welcomed to the "AmigaOS Preinstallation Environment". What does this mean? 1.11 * What is the optimal ADF images/floppy disk ordering for a full AmigaOS 3.2 installation? 1.12 * LoadModule fails for some unknown reason when trying to update my ROM modules. -
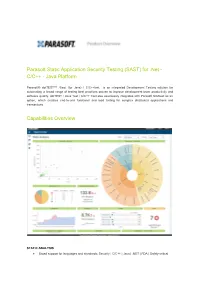
Parasoft Static Application Security Testing (SAST) for .Net - C/C++ - Java Platform
Parasoft Static Application Security Testing (SAST) for .Net - C/C++ - Java Platform Parasoft® dotTEST™ /Jtest (for Java) / C/C++test is an integrated Development Testing solution for automating a broad range of testing best practices proven to improve development team productivity and software quality. dotTEST / Java Test / C/C++ Test also seamlessly integrates with Parasoft SOAtest as an option, which enables end-to-end functional and load testing for complex distributed applications and transactions. Capabilities Overview STATIC ANALYSIS ● Broad support for languages and standards: Security | C/C++ | Java | .NET | FDA | Safety-critical ● Static analysis tool industry leader since 1994 ● Simple out-of-the-box integration into your SDLC ● Prevent and expose defects via multiple analysis techniques ● Find and fix issues rapidly, with minimal disruption ● Integrated with Parasoft's suite of development testing capabilities, including unit testing, code coverage analysis, and code review CODE COVERAGE ANALYSIS ● Track coverage during unit test execution and the data merge with coverage captured during functional and manual testing in Parasoft Development Testing Platform to measure true test coverage. ● Integrate with coverage data with static analysis violations, unit testing results, and other testing practices in Parasoft Development Testing Platform for a complete view of the risk associated with your application ● Achieve test traceability to understand the impact of change, focus testing activities based on risk, and meet compliance -

The'as Code'activities: Development Anti-Patterns for Infrastructure As Code
Empirical Software Engineering manuscript No. (will be inserted by the editor) The `as Code' Activities: Development Anti-patterns for Infrastructure as Code Akond Rahman · Effat Farhana · Laurie Williams Pre-print accepted at the Empirical Software Engineering Journal Abstract Context: The `as code' suffix in infrastructure as code (IaC) refers to applying software engineering activities, such as version control, to main- tain IaC scripts. Without the application of these activities, defects that can have serious consequences may be introduced in IaC scripts. A systematic investigation of the development anti-patterns for IaC scripts can guide prac- titioners in identifying activities to avoid defects in IaC scripts. Development anti-patterns are recurring development activities that relate with defective IaC scripts. Goal: The goal of this paper is to help practitioners improve the quality of infrastructure as code (IaC) scripts by identifying development ac- tivities that relate with defective IaC scripts. Methodology: We identify devel- opment anti-patterns by adopting a mixed-methods approach, where we apply quantitative analysis with 2,138 open source IaC scripts and conduct a sur- vey with 51 practitioners. Findings: We observe five development activities to be related with defective IaC scripts from our quantitative analysis. We iden- tify five development anti-patterns namely, `boss is not around', `many cooks spoil', `minors are spoiler', `silos', and `unfocused contribution'. Conclusion: Our identified development anti-patterns suggest -

Devnet Module 3
Module 3: Software Development and Design DEVASCv1 1 Module Objectives . Module Title: Software Development and Design . Module Objective: Use software development and design best practices. It will comprise of the following sections: Topic Title Topic Objective 3.1 Software Development Compare software development methodologies. 3.2 Software Design Patterns Describe the benefits of various software design patterns. 3.3 Version Control Systems Implement software version control using GIT. 3.4 Coding Basics Explain coding best practices. 3.5 Code Review and Testing Use Python Unit Test to evaluate code. 3.6 Understanding Data Formats Use Python to parse different messaging and data formats. DEVASCv1 2 3.1 Software Development DEVASCv1 3 Introduction . The software development process is also known as the software development life cycle (SDLC). SDLC is more than just coding and also includes gathering requirements, creating a proof of concept, testing, and fixing bugs. DEVASCv1 4 Software Development Life Cycle (SDLC) . SDLC is the process of developing software, starting from an idea and ending with delivery. This process consists of six phases. Each phase takes input from the results of the previous phase. SDLC is the process of developing software, starting from an idea and ending with delivery. This process consists of six phases. Each phase takes input from the results of the previous phase. Although the waterfall methods is still widely used today, it's gradually being superseded by more adaptive, flexible methods that produce better software, faster, with less pain. These methods are collectively known as “Agile development.” DEVASCv1 5 Requirements and Analysis Phase . The requirements and analysis phase involves the product owner and qualified team members exploring the stakeholders' current situation, needs and constraints, present infrastructure, and so on, and determining the problem to be solved by the software. -

Metrics for Gerrit Code Reviews
SPLST'15 Metrics for Gerrit code reviews Samuel Lehtonen and Timo Poranen University of Tampere, School of Information Sciences, Tampere, Finland [email protected],[email protected] Abstract. Code reviews are a widely accepted best practice in mod- ern software development. To enable easier and more agile code reviews, tools like Gerrit have been developed. Gerrit provides a framework for conducting reviews online, with no need for meetings or mailing lists. However, even with the help of tools like Gerrit, following and monitoring the review process becomes increasingly hard, when tens or even hun- dreds of code changes are uploaded daily. To make monitoring the review process easier, we propose a set of metrics to be used with Gerrit code review. The focus is on providing an insight to velocity and quality of code reviews, by measuring different review activities based on data, au- tomatically extracted from Gerrit. When automated, the measurements enable easy monitoring of code reviews, which help in establishing new best practices and improved review process. Keywords: Code quality; Code reviews; Gerrit; Metrics; 1 Introduction Code reviews are a widely used quality assurance practice in software engineer- ing, where developers read and assess each other's code before it is integrated into the codebase or deployed into production. Main motivations for reviews are to detect software defects and to improve code quality while sharing knowledge among developers. Reviews were originally introduced by Fagan [4] already in 1970's. The original, formal type of code inspections are still used in many com- panies, but has been often replaced with more modern types of reviews, where the review is not tied to place or time. -

Whodo: Automating Reviewer Suggestions at Scale
1 WhoDo: Automating reviewer suggestions at scale 59 2 60 3 61 4 Sumit Asthana B.Ashok Chetan Bansal 62 5 Microsoft Research India Microsoft Research India Microsoft Research India 63 6 [email protected] [email protected] [email protected] 64 7 65 8 Ranjita Bhagwan Christian Bird Rahul Kumar 66 9 Microsoft Research India Microsoft Research Redmond Microsoft Research India 67 10 [email protected] [email protected] [email protected] 68 11 69 12 Chandra Maddila Sonu Mehta 70 13 Microsoft Research India Microsoft Research India 71 14 [email protected] [email protected] 72 15 73 16 ABSTRACT ACM Reference Format: 74 17 Today’s software development is distributed and involves contin- Sumit Asthana, B.Ashok, Chetan Bansal, Ranjita Bhagwan, Christian Bird, 75 18 uous changes for new features and yet, their development cycle Rahul Kumar, Chandra Maddila, and Sonu Mehta. 2019. WhoDo: Automat- 76 ing reviewer suggestions at scale. In Proceedings of The 27th ACM Joint 19 has to be fast and agile. An important component of enabling this 77 20 European Software Engineering Conference and Symposium on the Founda- 78 agility is selecting the right reviewers for every code-change - the tions of Software Engineering (ESEC/FSE 2019). ACM, New York, NY, USA, 21 79 smallest unit of the development cycle. Modern tool-based code 9 pages. https://doi.org/10.1145/nnnnnnn.nnnnnnn 22 review is proven to be an effective way to achieve appropriate code 80 23 review of software changes. However, the selection of reviewers 81 24 in these code review systems is at best manual. -

Best Practices for the Use of Static Code Analysis Within a Real-World Secure Development Lifecycle
An NCC Group Publication Best Practices for the use of Static Code Analysis within a Real-World Secure Development Lifecycle Prepared by: Jeremy Boone © Copyright 2015 NCC Group Contents 1 Executive Summary ....................................................................................................................................... 3 2 Purpose and Motivation ................................................................................................................................. 3 3 Why SAST Often Fails ................................................................................................................................... 4 4 Methodology .................................................................................................................................................. 4 5 Integration with the Secure Development Lifecycle....................................................................................... 5 5.1 Training ................................................................................................................................................. 6 5.2 Requirements ....................................................................................................................................... 6 5.3 Design ................................................................................................................................................... 7 5.4 Implementation .................................................................................................................................... -

Understanding and Mitigating the Security Risks of Apple Zeroconf
2016 IEEE Symposium on Security and Privacy Staying Secure and Unprepared: Understanding and Mitigating the Security Risks of Apple ZeroConf Xiaolong Bai*,1, Luyi Xing*,2, Nan Zhang2, XiaoFeng Wang2, Xiaojing Liao3, Tongxin Li4, Shi-Min Hu1 1TNList, Tsinghua University, Beijing, 2Indiana University Bloomington, 3Georgia Institute of Technology, 4Peking University [email protected], {luyixing, nz3, xw7}@indiana.edu, [email protected], [email protected], [email protected] Abstract—With the popularity of today’s usability-oriented tend to build their systems in a “plug-and-play” fashion, designs, dubbed Zero Configuration or ZeroConf, unclear are using techniques dubbed zero-configuration (ZeroConf ). For the security implications of these automatic service discovery, example, the AirDrop service on iPhone, once activated, “plug-and-play” techniques. In this paper, we report the first systematic study on this issue, focusing on the security features automatically detects another Apple device nearby running of the systems related to Apple, the major proponent of the service to transfer documents. Such ZeroConf services ZeroConf techniques. Our research brings to light a disturb- are characterized by automatic IP selection, host name ing lack of security consideration in these systems’ designs: resolving and target service discovery. Prominent examples major ZeroConf frameworks on the Apple platforms, includ- include Apple’s Bonjour [3], and the Link-Local Multicast ing the Core Bluetooth Framework, Multipeer Connectivity and -

Software Reviews
Software Reviews Software Engineering II WS 2020/21 Enterprise Platform and Integration Concepts Image by Chris Isherwood from flickr: https://www.flickr.com/photos/isherwoodchris/6807654905/ (CC BY-SA 2.0) Review Meetings a software product is [examined by] project personnel, “ managers, users, customers, user representatives, or other interested parties for comment or approval —IEEE1028 ” Principles ■ Generate comments on software ■ Several sets of eyes check ■ Emphasis on people over tools Code Reviews — Software Engineering II 2 Software Reviews Motivation ■ Improve code ■ Discuss alternative solutions ■ Transfer knowledge ■ Find defects Code Reviews — Software Engineering II Image by Glen Lipka: http://commadot.com/wtf-per-minute/ 3 Involved Roles Manager ■ Assessment is an important task for manager ■ Possible lack of deep technical understanding ■ Assessment of product vs. assessment of person ■ Outsider in review process ■ Support with resources (time, staff, rooms, …) Developer ■ Should not justify but only explain their results ■ No boss should take part at review Code Reviews — Software Engineering II 4 Review Team Team lead ■ Responsible for quality of review & moderation ■ Technical, personal and administrative competence Reviewer ■ Study the material before first meeting ■ Don’t try to achieve personal targets! ■ Give positive and negative comments on review artifacts Recorder ■ Any reviewer, can rotate even in review meeting ■ Protocol as basis for final review document Code Reviews — Software Engineering II 5 Tasks of -
Cooper ( Interaction Design
Cooper ( Interaction Design Inspiration The Myth of Metaphor Cooper books by Alan Cooper, Chairman & Founder Articles June 1995 Newsletter Originally Published in Visual Basic Programmer's Journal Concept projects Book reviews Software designers often speak of "finding the right metaphor" upon which to base their interface design. They imagine that rendering their user interface in images of familiar objects from the real world will provide a pipeline to automatic learning by their users. So they render their user interface as an office filled with desks, file cabinets, telephones and address books, or as a pad of paper or a street of buildings in the hope of creating a program with breakthrough ease-of- learning. And if you search for that magic metaphor, you will be in august company. Some of the best and brightest designers in the interface world put metaphor selection as one of their first and most important tasks. But by searching for that magic metaphor you will be making one of the biggest mistakes in user interface design. Searching for that guiding metaphor is like searching for the correct steam engine to power your airplane, or searching for a good dinosaur on which to ride to work. I think basing a user interface design on a metaphor is not only unhelpful but can often be quite harmful. The idea that good user interface design is based on metaphors is one of the most insidious of the many myths that permeate the software community. Metaphors offer a tiny boost in learnability to first time users at http://www.cooper.com/articles/art_myth_of_metaphor.htm (1 of 8) [1/16/2002 2:21:34 PM] Cooper ( Interaction Design tremendous cost.