Metrics for Gerrit Code Reviews
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Open Source Used in Influx1.8 Influx 1.9
Open Source Used In Influx1.8 Influx 1.9 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-1178791953 Open Source Used In Influx1.8 Influx 1.9 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-1178791953 Contents 1.1 golang-protobuf-extensions v1.0.1 1.1.1 Available under license 1.2 prometheus-client v0.2.0 1.2.1 Available under license 1.3 gopkg.in-asn1-ber v1.0.0-20170511165959-379148ca0225 1.3.1 Available under license 1.4 influxdata-raft-boltdb v0.0.0-20210323121340-465fcd3eb4d8 1.4.1 Available under license 1.5 fwd v1.1.1 1.5.1 Available under license 1.6 jaeger-client-go v2.23.0+incompatible 1.6.1 Available under license 1.7 golang-genproto v0.0.0-20210122163508-8081c04a3579 1.7.1 Available under license 1.8 influxdata-roaring v0.4.13-0.20180809181101-fc520f41fab6 1.8.1 Available under license 1.9 influxdata-flux v0.113.0 1.9.1 Available under license 1.10 apache-arrow-go-arrow v0.0.0-20200923215132-ac86123a3f01 1.10.1 Available under -

Buildbot Documentation Release 1.6.0
Buildbot Documentation Release 1.6.0 Brian Warner Nov 17, 2018 Contents 1 Buildbot Tutorial 3 1.1 First Run.................................................3 1.2 First Buildbot run with Docker......................................6 1.3 A Quick Tour...............................................9 1.4 Further Reading............................................. 17 2 Buildbot Manual 23 2.1 Introduction............................................... 23 2.2 Installation................................................ 29 2.3 Concepts................................................. 41 2.4 Secret Management........................................... 50 2.5 Configuration............................................... 53 2.6 Customization.............................................. 251 2.7 Command-line Tool........................................... 278 2.8 Resources................................................. 289 2.9 Optimization............................................... 289 2.10 Plugin Infrastructure in Buildbot..................................... 289 2.11 Deployment............................................... 290 2.12 Upgrading................................................ 292 3 Buildbot Development 305 3.1 Development Quick-start......................................... 305 3.2 General Documents........................................... 307 3.3 APIs................................................... 391 3.4 Python3 compatibility.......................................... 484 3.5 Classes................................................. -

Gerrit J.J. Van Den Burg, Phd London, UK | Email: [email protected] | Web: Gertjanvandenburg.Com
Gerrit J.J. van den Burg, PhD London, UK | Email: [email protected] | Web: gertjanvandenburg.com Summary I am a research scientist with a PhD in machine learning and 8+ years of experience in academic research. I am currently looking to transition to industry to work on complex, large-scale problems that can have a positive real-world impact. I have extensive experience with machine learning modeling, algorithm design, and software engineering in Python, C, and R. My goal is to use my expertise and technical skills to address ongoing research challenges in machine learning and AI. Research Experience Postdoctoral Researcher — The Alan Turing Institute, UK 2018–2021 • Introduced a memorization score for probabilistic deep generative models and showed that neural networks can remember part of their input data, which has important implications for data privacy • Created a method for structure detection in textual data files that improved on the Python builtin method by 21%. Developed this into a Python package that has received over 600,000 downloads • Developed a robust Bayesian matrix factorization algorithm for time series modeling and forecasting that improved imputation error up to 60% while maintaining competitive runtime • Established the first benchmark dataset for change point detection on general real-world time series and determined the best performing methods, with consequences for research and practice • Collaborated with other researchers to design a unified interface for AI-powered data cleaning tools Doctoral Researcher -

Parasoft Dottest REDUCE the RISK of .NET DEVELOPMENT
Parasoft dotTEST REDUCE THE RISK OF .NET DEVELOPMENT TRY IT https://software.parasoft.com/dottest Complement your existing Visual Studio tools with deep static INCREASE analysis and advanced PROGRAMMING EFFICIENCY: coverage. An automated, non-invasive solution that the related code, and distributed to his or her scans the application codebase to iden- IDE with direct links to the problematic code • Identify runtime bugs without tify issues before they become produc- and a description of how to fix it. executing your software tion problems, Parasoft dotTEST inte- grates into the Parasoft portfolio, helping When you send the results of dotTEST’s stat- • Automate unit and component you achieve compliance in safety-critical ic analysis, coverage, and test traceability testing for instant verification and industries. into Parasoft’s reporting and analytics plat- regression testing form (DTP), they integrate with results from Parasoft dotTEST automates a broad Parasoft Jtest and Parasoft C/C++test, allow- • Automate code analysis for range of software quality practices, in- ing you to test your entire codebase and mit- compliance cluding static code analysis, unit testing, igate risks. code review, and coverage analysis, en- abling organizations to reduce risks and boost efficiency. Tests can be run directly from Visual Stu- dio or as part of an automated process. To promote rapid remediation, each problem detected is prioritized based on configur- able severity assignments, automatical- ly assigned to the developer who wrote It snaps right into Visual Studio as though it were part of the product and it greatly reduces errors by enforcing all your favorite rules. We have stuck to the MS Guidelines and we had to do almost no work at all to have dotTEST automate our code analysis and generate the grunt work part of the unit tests so that we could focus our attention on real test-driven development. -
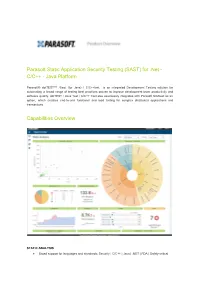
Parasoft Static Application Security Testing (SAST) for .Net - C/C++ - Java Platform
Parasoft Static Application Security Testing (SAST) for .Net - C/C++ - Java Platform Parasoft® dotTEST™ /Jtest (for Java) / C/C++test is an integrated Development Testing solution for automating a broad range of testing best practices proven to improve development team productivity and software quality. dotTEST / Java Test / C/C++ Test also seamlessly integrates with Parasoft SOAtest as an option, which enables end-to-end functional and load testing for complex distributed applications and transactions. Capabilities Overview STATIC ANALYSIS ● Broad support for languages and standards: Security | C/C++ | Java | .NET | FDA | Safety-critical ● Static analysis tool industry leader since 1994 ● Simple out-of-the-box integration into your SDLC ● Prevent and expose defects via multiple analysis techniques ● Find and fix issues rapidly, with minimal disruption ● Integrated with Parasoft's suite of development testing capabilities, including unit testing, code coverage analysis, and code review CODE COVERAGE ANALYSIS ● Track coverage during unit test execution and the data merge with coverage captured during functional and manual testing in Parasoft Development Testing Platform to measure true test coverage. ● Integrate with coverage data with static analysis violations, unit testing results, and other testing practices in Parasoft Development Testing Platform for a complete view of the risk associated with your application ● Achieve test traceability to understand the impact of change, focus testing activities based on risk, and meet compliance -

QUARTERLY CHECK-IN Technology (Services) TECH GOAL QUADRANT
QUARTERLY CHECK-IN Technology (Services) TECH GOAL QUADRANT C Features that we build to improve our technology A Foundation level goals offering B Features we build for others D Modernization, renewal and tech debt goals The goals in each team pack are annotated using this scheme illustrate the broad trends in our priorities Agenda ● CTO Team ● Research and Data ● Design Research ● Performance ● Release Engineering ● Security ● Technical Operations Photos (left to right) Technology (Services) CTO July 2017 quarterly check-in All content is © Wikimedia Foundation & available under CC BY-SA 4.0, unless noted otherwise. CTO Team ● Victoria Coleman - Chief Technology Officer ● Joel Aufrecht - Program Manager (Technology) ● Lani Goto - Project Assistant ● Megan Neisler - Senior Project Coordinator ● Sarah Rodlund - Senior Project Coordinator ● Kevin Smith - Program Manager (Engineering) Photos (left to right) CHECK IN TEAM/DEPT PROGRAM WIKIMEDIA FOUNDATION July 2017 CTO 4.5 [LINK] ANNUAL PLAN GOAL: expand and strengthen our technical communities What is your objective / Who are you working with? What impact / deliverables are you expecting? workflow? Program 4: Technical LAST QUARTER community building (none) Outcome 5: Organize Wikimedia Developer Summit NEXT QUARTER Objective 1: Developer Technical Collaboration Decide on event location, dates, theme, deadlines, etc. Summit web page and publicize the information published four months before the event (B) STATUS: OBJECTIVE IN PROGRESS Technology (Services) Research and Data July, 2017 quarterly -

Devnet Module 3
Module 3: Software Development and Design DEVASCv1 1 Module Objectives . Module Title: Software Development and Design . Module Objective: Use software development and design best practices. It will comprise of the following sections: Topic Title Topic Objective 3.1 Software Development Compare software development methodologies. 3.2 Software Design Patterns Describe the benefits of various software design patterns. 3.3 Version Control Systems Implement software version control using GIT. 3.4 Coding Basics Explain coding best practices. 3.5 Code Review and Testing Use Python Unit Test to evaluate code. 3.6 Understanding Data Formats Use Python to parse different messaging and data formats. DEVASCv1 2 3.1 Software Development DEVASCv1 3 Introduction . The software development process is also known as the software development life cycle (SDLC). SDLC is more than just coding and also includes gathering requirements, creating a proof of concept, testing, and fixing bugs. DEVASCv1 4 Software Development Life Cycle (SDLC) . SDLC is the process of developing software, starting from an idea and ending with delivery. This process consists of six phases. Each phase takes input from the results of the previous phase. SDLC is the process of developing software, starting from an idea and ending with delivery. This process consists of six phases. Each phase takes input from the results of the previous phase. Although the waterfall methods is still widely used today, it's gradually being superseded by more adaptive, flexible methods that produce better software, faster, with less pain. These methods are collectively known as “Agile development.” DEVASCv1 5 Requirements and Analysis Phase . The requirements and analysis phase involves the product owner and qualified team members exploring the stakeholders' current situation, needs and constraints, present infrastructure, and so on, and determining the problem to be solved by the software. -

VES Home Welcome to the VNF Event Stream (VES) Project Home
VES Home Welcome to the VNF Event Stream (VES) Project Home This project was approved May 31, 2016 based upon the VNF Event Stream project proposal. In the meantime the project evolved and VES is not only used by VNF but also by PNF (physical network functions). However, the term "VES" is established and will be kept. Next to OPNFV and ONAP also O-RAN, O-RAN-SC and 3GPP are using VES. The term "xNF" refers to the combination of virtual network functions and physical network functions. Project description: Objective: This project will develop OPNFV platform support for VNF and PNF event streams, in a common model and format intended for use by Service Providers (SPs), e.g. in managing xNF health and lifecycle. The project’s goal is to enable a significant reduction in the effort to develop and integrate xNF telemetry-related data into automated xNF management systems, by promoting convergence toward a common event stream format and collection system. The VES doc source, code, and tests are available at: OPNFV github (generally updated with 30 minutes of merged commits) OPNFV gitweb To clone from the OPNFV repo, see the instructions at the Gerrit project page Powerpoint intro to the project: OPNVF VES.pptx. A demo of the project (vHello_VES Demo) was first presented at OpenStack Barcelona (2016), and updated for the OPNFV Summit 2017 (VES ONAP demo - see below for more info). The following diagram illustrates the concept and scope for the VES project, which includes: From ONAP a Common Event Data Model for the “VNF Event Stream”, with report "domains" covering e.g. -

Best Practices for the Use of Static Code Analysis Within a Real-World Secure Development Lifecycle
An NCC Group Publication Best Practices for the use of Static Code Analysis within a Real-World Secure Development Lifecycle Prepared by: Jeremy Boone © Copyright 2015 NCC Group Contents 1 Executive Summary ....................................................................................................................................... 3 2 Purpose and Motivation ................................................................................................................................. 3 3 Why SAST Often Fails ................................................................................................................................... 4 4 Methodology .................................................................................................................................................. 4 5 Integration with the Secure Development Lifecycle....................................................................................... 5 5.1 Training ................................................................................................................................................. 6 5.2 Requirements ....................................................................................................................................... 6 5.3 Design ................................................................................................................................................... 7 5.4 Implementation .................................................................................................................................... -

Fashion Terminology Today Describe Your Heritage Collections with an Eye on the Future
Fashion Terminology Today Describe your heritage collections with an eye on the future Ykje Wildenborg MoMu – Fashion Museum of the Province of Antwerp, Belgium Europeana Fashion, Modemuze Abstract: This article was written for ‘non-techy people’, or people with a basic knowledge of information technology, interested in preparing their fashion heritage metadata for publication online. Publishing fashion heritage on the web brings about the undisputed need for a shared vocabulary, especially when merged. This is not only a question of multilingualism. Between collections and even within collections different words have been used to describe, for example, the same types of objects, materials or techniques. In professional language: the data often is “unclean”. Linked Data is the name of a development in information technology that could prove useful for fashion collecting institutions. It means that the descriptions of collections, in a computer readable format, have a structure that is extremely easy for the device to read. As alien as it may sound, Linked Data practices are already used by the data departments of larger museums, companies and governmental institutions around the world. It eliminates the need for translation or actual changing of the content of databases. It only concerns ‘labeling’ of terms in databases with an identifier. With this in mind, MoMu, the fashion museum of Antwerp, Belgium, is carrying out a termi- nology project in Flanders and the Netherlands, in order to motivate institutions to accomplish the task of labeling their terms. This article concludes with some of the experiences of this adventure, but firstly elucidates the context of the situation. -

Code Review Guide
CODE REVIEW GUIDE 2.0 RELEASE Project leaders: Larry Conklin and Gary Robinson Creative Commons (CC) Attribution Free Version at: https://www.owasp.org 1 F I 1 Forward - Eoin Keary Introduction How to use the Code Review Guide 7 8 10 2 Secure Code Review 11 Framework Specific Configuration: Jetty 16 2.1 Why does code have vulnerabilities? 12 Framework Specific Configuration: JBoss AS 17 2.2 What is secure code review? 13 Framework Specific Configuration: Oracle WebLogic 18 2.3 What is the difference between code review and secure code review? 13 Programmatic Configuration: JEE 18 2.4 Determining the scale of a secure source code review? 14 Microsoft IIS 20 2.5 We can’t hack ourselves secure 15 Framework Specific Configuration: Microsoft IIS 40 2.6 Coupling source code review and penetration testing 19 Programmatic Configuration: Microsoft IIS 43 2.7 Implicit advantages of code review to development practices 20 2.8 Technical aspects of secure code review 21 2.9 Code reviews and regulatory compliance 22 5 A1 3 Injection 51 Injection 52 Blind SQL Injection 53 Methodology 25 Parameterized SQL Queries 53 3.1 Factors to Consider when Developing a Code Review Process 25 Safe String Concatenation? 53 3.2 Integrating Code Reviews in the S-SDLC 26 Using Flexible Parameterized Statements 54 3.3 When to Code Review 27 PHP SQL Injection 55 3.4 Security Code Review for Agile and Waterfall Development 28 JAVA SQL Injection 56 3.5 A Risk Based Approach to Code Review 29 .NET Sql Injection 56 3.6 Code Review Preparation 31 Parameter collections 57 3.7 Code Review Discovery and Gathering the Information 32 3.8 Static Code Analysis 35 3.9 Application Threat Modeling 39 4.3.2. -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version}