An Optimization-Based Approach to Social Network Group Decision Making with an Application to Earthquake Shelter-Site Selection
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lessons Learnt from Analysing the Causes of Casualties in the Sichuan
https://doi.org/10.5194/nhess-2020-64 Preprint. Discussion started: 19 March 2020 c Author(s) 2020. CC BY 4.0 License. Lessons learnt from analysing the causes of casualties in the Sichuan Changning Ms 6.0 earthquake Wei Wang1,2, Hong Chen1, Xiaolin Jiang3, Lisiwen Ma1, Minhao Qu4 1Institute of Crustal Dynamics, China Earthquake Administration, Beijing 100085, China 5 2Institute of Engineering Mechanics, China Earthquake Administration, Harbin 150080, China 3Sichuan Earthquake Administration, Chengdu 610041, China 4National Earthquake Response Support Service, Beijing 100049, China Correspondence to: Hong Chen ([email protected]) Abstract. This paper summarizes the Ms 6.0 earthquake disaster that occurred in Changning, Sichuan Province, China, on 17 10 June 2019. Additionally, a description of the disaster emergency response is provided. As determined by on-site investigation and analysis, the direct causes of earthquake casualties are summarized. Among them, 66% of the casualties can be attributed to substandard seismic protection, 25% to improper earthquake risk avoidance, 6% to earthquake-induced geological disasters, and 3% to pre-existing diseases exacerbated by the earthquake. Responding to the causes of these four casualty types, we summarize 4 lessons, which are to build in accordance with seismic protection requirements; strengthen publicity and 15 education awareness of earthquake emergency evacuation and training for the population; investigate and evaluate potential geological disaster sources in the stricken area, along with conducting prevention and control; establish cooperation with health organizations, focusing on people who are older or have serious illnesses and conducting earthquake evacuation training and psychological counselling. 1 Disaster characteristics and disaster situation 20 An Ms 6.0 (Mw 5.8) earthquake struck Changning County, Yibin City, Sichuan Province, China, at 22:55:43 on 17 June 2019 (14:55:43 UTC on 17 June 2019). -

The Spatial and Temporal Distribution Characteristics of Rainstorm Disaster in Sichuan Province Over the Past Decade
Journal of Geoscience and Environment Protection, 2017, 5, 1-9 http://www.scirp.org/journal/gep ISSN Online: 2327-4344 ISSN Print: 2327-4336 The Spatial and Temporal Distribution Characteristics of Rainstorm Disaster in Sichuan Province over the Past Decade Jie Gao1,2, Jianhua Pan1, Mingtian Wang1, Shanyun Guo1 1Sichuan Provincial Meteorological Observatory, Chengdu, China 2Heavy Rain and Drought-Flood Disasters in Plateau and Basin Key Laboratory of Sichuan Province, Chengdu, China How to cite this paper: Gao, J., Pan, J.H., Abstract Wang, M.T. and Guo, S.Y. (2017) The Spatial and Temporal Distribution Charac- The spatial and temporal distribution characteristics of rainstorm disaster in teristics of Rainstorm Disaster in Sichuan Sichuan Province were investigated by statistical analysis method based on Province over the Past Decade. Journal of 2002-2015 rainstorm disaster data of Sichuan Province. As shown by the re- Geoscience and Environment Protection, 5, 1-9. sults, the rainstorm disaster in Sichuan Province was distributed mainly in https://doi.org/10.4236/gep.2017.58001 four regions including Liangshan Prefecture and Sichuan Basin during 2002-2015, and the rainstorm disaster distribution had a good corresponding Received: March 29, 2017 Accepted: July 16, 2017 relationship with the rainstorm center regions; in terms of annual variation Published: July 19, 2017 trend, the variation of rainstorm disaster frequency showed a significant qua- si-2-3-year oscillation period; in terms of monthly distribution, June, July and Copyright © 2017 by authors and August saw the heaviest rainstorms; the high death toll from rainstorms was Scientific Research Publishing Inc. This work is licensed under the Creative attributed to not only routine rainfall, occurrence time and terrain feature, but Commons Attribution International also the populace’s awareness of disaster prevention and the disaster preven- License (CC BY 4.0). -
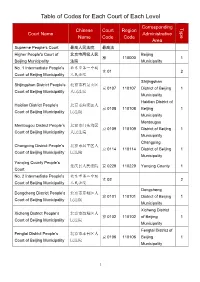
Table of Codes for Each Court of Each Level
Table of Codes for Each Court of Each Level Corresponding Type Chinese Court Region Court Name Administrative Name Code Code Area Supreme People’s Court 最高人民法院 最高法 Higher People's Court of 北京市高级人民 Beijing 京 110000 1 Beijing Municipality 法院 Municipality No. 1 Intermediate People's 北京市第一中级 京 01 2 Court of Beijing Municipality 人民法院 Shijingshan Shijingshan District People’s 北京市石景山区 京 0107 110107 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Haidian District of Haidian District People’s 北京市海淀区人 京 0108 110108 Beijing 1 Court of Beijing Municipality 民法院 Municipality Mentougou Mentougou District People’s 北京市门头沟区 京 0109 110109 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Changping Changping District People’s 北京市昌平区人 京 0114 110114 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Yanqing County People’s 延庆县人民法院 京 0229 110229 Yanqing County 1 Court No. 2 Intermediate People's 北京市第二中级 京 02 2 Court of Beijing Municipality 人民法院 Dongcheng Dongcheng District People’s 北京市东城区人 京 0101 110101 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Xicheng District Xicheng District People’s 北京市西城区人 京 0102 110102 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Fengtai District of Fengtai District People’s 北京市丰台区人 京 0106 110106 Beijing 1 Court of Beijing Municipality 民法院 Municipality 1 Fangshan District Fangshan District People’s 北京市房山区人 京 0111 110111 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Daxing District of Daxing District People’s 北京市大兴区人 京 0115 -
![Downloaded from Global Change Research Data Publisher & Repository [62]](https://docslib.b-cdn.net/cover/8722/downloaded-from-global-change-research-data-publisher-repository-62-2648722.webp)
Downloaded from Global Change Research Data Publisher & Repository [62]
Sustainability 2015, 7, 13469-13499; doi:10.3390/su71013469 OPEN ACCESS sustainability ISSN 2071-1050 www.mdpi.com/journal/sustainability Article Multi-Scale Measurement of Regional Inequality in Mainland China during 2005–2010 Using DMSP/OLS Night Light Imagery and Population Density Grid Data Huimin Xu 1,*, Hutao Yang 1, Xi Li 2,3,4,*, Huiran Jin 4 and Deren Li 2,3 1 School of Economics, Zhongnan University of Economics and Law, Wuhan 430073, China; E-Mail: [email protected] 2 State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing, Wuhan University, Wuhan 430079, China; E-Mail: [email protected] 3 Collaborative Innovation Centre of Geospatial Technology, Wuhan 430079, China 4 Department of Geographical Sciences, University of Maryland, College Park, 20742 MD, USA; E-Mails: [email protected] * Authors to whom correspondence should be addressed; E-Mails: [email protected] (H.X.); [email protected] (X.L.) or [email protected] (X.L.); Tel.: +86-27-8838-6464 (H.X.); +86-27-6877-8989 (X.L.); Fax: +86-27-8838-6239 (H.X.), +86-27-6877-8989 (X.L.) Academic Editor: Eric Vaz Received: 1 August 2015 / Accepted: 22 September 2015 / Published: 30 September 2015 Abstract: This study used the Night Light Development Index (NLDI) to measure the regional inequality of public services in Mainland China at multiple scales. The NLDI was extracted based on a Gini Coefficient approach to measure the spatial differences of population distribution and night light distribution. Population data were derived from the dataset of China’s population density grid, and night light data were acquired from satellite imagery. -

四川能投發展股份有限公司 Sichuan Energy Investment Development Co., Ltd
Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited take no responsibility for the contents of this announcement, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this announcement. 四川能投發展股份有限公司 Sichuan Energy Investment Development Co., Ltd.* (a joint stock company incorporated in the People’s Republic of China with limited liability) (Stock code: 01713) RESIGNATION AND PROPOSED APPOINTMENT OF A NON-EXECUTIVE DIRECTOR AND RESIGNATION AND PROPOSED APPOINTMENT OF A SUPERVISOR The Board announces that with effect from the approval of the Shareholders at the AGM of the proposed appointment of the new non-executive Director, Mr. Wang Chengke will resign as a non-executive Director and the Board proposed to appoint Mr. Xu Zhenhua as a non-executive Director, subject to the approval by the Shareholders at the AGM. The Board announces that with effect from the approval of the Shareholders at the AGM of the proposed appointment of the new Supervisor, Mr. Ouyang Yu will resign as a Supervisor and the Supervisor Committee proposed to appoint Mr. Xie Jun as a Supervisor, subject to the approval by the Shareholders at the AGM. Resignation of a Non-executive Director and Proposed Appointment of a Non-executive Director The board (the “Board”) of directors (the “Director(s)”) of Sichuan Energy Investment Development Co., Ltd.* (the “Company”) hereby announces that Mr. Wang Chengke (“Mr. Wang”) has tendered his resignation as a non-executive Director due to work adjustment. -

World Bank Document
E1245 v 3 Public Disclosure Authorized World Bank Financed Yibin Environmental Improvement Project In Yibin City, Sichuan Province Public Disclosure Authorized Environmental Impact Assessment Public Disclosure Authorized Chengdu Hydropower Investigation Design & Research Institute of Public Disclosure Authorized China Hydropower Engineering Consultant Group Corporation October, 2005 1 Preface The Environmental Improvement Project in Yibin City, Sichuan Province is also called Binjiang ring road project for short. It consists of road project, bridge and culvert project, protective project, landscape project and drainage project. The proposed road project is an import part of the urban road network planned by the municipal government, and involves two parts, namely Line A and Line B. Line A is laid along the left banks of the Min River and the Yangtze River, extending from east to west. It starts from the Min River North Bridge and ends at Tianyuan Co., Ltd., with a total length of 6688.51 meters. Line B starts from the Cultural Square of Nan’an and ends at the No. 4 Water Plant, following Nan’an (south bank) of the Jinsha River, with a total length of 3521.21 meters. The main functions of the project are transportation and relaxation. The total investment is RMB 574.06 million, of which USD 28.5 million is financed by the World Bank. According to the urban master plan of Yibin, the city will be composed of multi-districts with diverse function and characteristics. The proposed road of Line A is the only way connecting Jiucheng, Jiuzhou with Baisha. The proposed road of Line B connects West district of Nan’an, East district of Nan’an, Zhaozhou and Tianbai, which are important districts of the city. -

Dec 13, 2018 Prospectus
IMPORTANT If you are in any doubt about any of the contents of this prospectus, you should obtain independent professional advice. 四川能投發展股份有限公司 Sichuan Energy Investment Development Co., Ltd.* (a joint stock company incorporated in the People’s Republic of China with limited liability) GLOBAL OFFERING Number of Offer Shares under : 268,800,000 H Shares (subject to the the Global Offering Over-allotment Option) Number of Hong Kong Offer Shares : 26,880,000 H Shares (subject to adjustment) Number of International Offer Shares : 241,920,000 H Shares (subject to adjustment and the Over-allotment Option) Maximum Offer Price : HK$2.34 per H Share, plus brokerage of 1.0%, SFC transaction levy of 0.0027% and a Stock Exchange trading fee of 0.005% (payable in full on application in Hong Kong dollars and subject to refund) Nominal value : RMB1.00 per H Share Stock code : 1713 Sole Sponsor and Sole Global Coordinator Joint Bookrunners and Joint Lead Managers Hong Kong Exchanges and Clearing Limited, The Stock Exchange of Hong Kong Limited and Hong Kong Securities Clearing Company Limited take no responsibility for the contents of this prospectus, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this prospectus. A copy of this prospectus, having attached thereto the documents specified in the paragraph headed “Documents Delivered to the Registrar of Companies and Available for Inspection” in Appendix VII to this prospectus, has been registered by the Registrar of Companies in Hong Kong as required by Section 342C of the Companies (Winding Up and Miscellaneous Provisions) Ordinance, Chapter 32 of the Laws of Hong Kong. -

Multiscale Spatio-Temporal Dynamics of Economic
sustainability Article Multiscale Spatio-Temporal Dynamics of Economic Development in an Interprovincial Boundary Region: Junction Area of Tibetan Plateau, Hengduan Mountain, Yungui Plateau and Sichuan Basin, Southwestern China Case Jifei Zhang 1,2 and Wei Deng 1,* 1 Institute of Mountain Hazards and Environment, Chinese Academy of Sciences, Chengdu 610041, China; [email protected] 2 The International Centre for Integrated Mountain Development, Kathmandu 44700, Nepal * Correspondence: [email protected]; Tel./Fax: +86-028-8535-3897 Academic Editors: Giuseppe Ioppolo and Marc A. Rosen Received: 8 December 2015; Accepted: 25 February 2016; Published: 29 February 2016 Abstract: An interprovincial boundary region is a new subject of economic disparity study in China. This study explored the multi-scale spatio-temporal dynamics of economic development from 1995 to 2010 in the interprovincial boundary region of Sichuan-Yunnan-Guizhou, a mountain area and also the junction area of Tibetan Plateau, Hengduan Mountain, Yungui Plateau and Sichuan Basin in southwestern China. A quantitative study on county GDP per capita for different scales of administrative regions was conducted using the Theil index, Markov chains, a geographic information system and exploratory spatial data analysis. Results indicated that the economic disparity was closely related with geographical unit scale in the study area: the smaller the unit, the bigger the disparity, and the regional inequality gradually weakened over time. Moreover, significant positive spatial autocorrelation and clustering of economic development were also found. The spatial pattern of economic development presented approximate circle structure with two cores in the southwest and northeast. The Panxi region in the southwest core and a part of Hilly Sichuan Basin in the northeast core were considered to be hot spots of economic development. -

Financing Strategy of the Urban Wastewater Sector in Selected Municipalities of the Sichuan Province in China
FINANCING STRATEGY OF THE URBAN WASTEWATER SECTOR IN SELECTED MUNICIPALITIES OF THE SICHUAN PROVINCE IN CHINA OECD 2004 ORGANISATION FOR ECONOMIC CO-OPERATION AND DEVELOPMENT Pursuant to Article 1 of the Convention signed in Paris on 14th December 1960, and which came into force on 30th September 1961, the Organisation for Economic Co-operation and Development (OECD) shall promote policies designed: − to achieve the highest sustainable economic growth and employment and a rising standard of living in Member countries, while maintaining financial stability, and thus to contribute to the development of the world economy; − to contribute to sound economic expansion in member as well as non-member countries in the process of economic development; and − to contribute to the expansion of world trade on a multilateral, non-discriminatory basis in accordance with international obligations. The original Member countries of the OECD are Austria, Belgium, Canada, Denmark, France, Germany, Greece, Iceland, Ireland, Italy, Luxembourg, the Netherlands, Norway, Portugal, Spain, Sweden, Switzerland, Turkey, the United Kingdom and the United States. The following countries became Members subsequently through accession at the dates indicated hereafter: Japan (28th April 1964), Finland (28th January 1969), Australia (7th June 1971), New Zealand (29th May 1973), Mexico (18th May 1994), the Czech Republic (21st December 1995), Hungary (7th May 1996), Poland (22nd November 1996), Korea (12th December 1996), and the Slovak Republic (14th December 2000). The Commission of the European Communities takes part in the work of the OECD (Article 13 of the OECD Convention). © OECD 2004 Permission to reproduce a portion of this work for non-commercial purposes or classroom use should be obtained through the Centre français d'exploitation du droit de copie (CFC), 20, rue des Grands-Augustins, 75006 Paris, France, Tel. -

The Spatial Pattern and Influencing Factors of Rural Tourism in Chengdu-Chongqing Urban Agglomeration Hong HUI , Wei-Yi HE *
2020 2nd International Conference on Arts, Humanity and Economics, Management (AHEM 2020) ISBN: 978-1-60595-685-5 The Spatial Pattern and Influencing Factors of Rural Tourism in Chengdu-Chongqing Urban Agglomeration Hong HUI1,a, Wei-yi HE2,b,* and Ren-jun ZHANG3,c 1,2,3Tourism Management, Chongqing University of Technology, Chongqing, China [email protected], [email protected],[email protected] *Corresponding author Keywords: Chengdu-Chongqing urban agglomeration, Rural tourism, Spatial pattern, Geographic detector, Influencing factors. Abstract. As the fourth national-level urban agglomeration, the Chengdu-Chongqing urban agglomeration has good conditions for the development of tourism industry. It is of great significance to improve the development level of rural tourism in Chengdu-Chongqing region by understanding its spatial pattern and driving factors of rural tourism. This study analyzes the spatial pattern of rural tourism in the Chengdu-Chongqing urban agglomeration and explores its influencing factors by using the geographic detector model. It found that: (1) The spatial distribution of rural tourism in the Chengdu-Chongqing urban agglomeration presents the characteristics of agglomeration of "two big and three small"; (2) The structural ranking of urban agglomeration is the core factor affecting the spatial pattern of rural tourism; (3) Agricultural development level, economic development level, and tourism development level also have important influence on rural tourism; (4) The influence of resource endowments and natural conditions on it is not obvious. Therefore, the development of rural tourism in the Chengdu-Chongqing urban agglomeration should not be limited to the countryside and the resources itself, but should improve the level of urban development, the quality of agriculture and tourism development from the overall perspective of the urban agglomeration. -

Apr 23, 2021 Annual Report 2020
四川能投發展股份有限公司 Sichuan Energy Investment Development Co., Ltd. (A joint stock company incorporated in the People’s Republic of China with limited liability) Stock Code: 1713 2020 Annual Report CONTENTS DEFINITIONS 2 CHAIRMAN’S STATEMENT 4 COMPANY PROFILE 5 FINANCIAL HIGHLIGHTS 7 MANAGEMENT DISCUSSION AND ANALYSIS 8 REPORT OF THE BOARD OF DIRECTORS 20 REPORT OF THE SUPERVISORY COMMITTEE 40 CORPORATE GOVERNANCE REPORT 42 DIRECTORS, SUPERVISORS AND SENIOR MANAGEMENT 53 INDEPENDENT AUDITOR’S REPORT 60 CONSOLIDATED STATEMENT OF PROFIT OR LOSS 66 CONSOLIDATED STATEMENT OF PROFIT OR LOSS AND OTHER 67 COMPREHENSIVE INCOME CONSOLIDATED STATEMENT OF FINANCIAL POSITION 68 CONSOLIDATED STATEMENT OF CHANGES IN EQUITY 70 CONSOLIDATED STATEMENT OF CASH FLOWS 71 NOTES TO THE FINANCIAL STATEMENTS 72 Sichuan Energy Investment Development Co., Ltd. 1 ANNUAL REPORT 2020 DEFINITIONS In this annual report, the following expressions shall have the following meanings unless the context requires otherwise. “Annual General Meeting” or “AGM” the annual general meeting to be convened by the Company on 18 June 2021 “Articles of Association” or “Articles” the articles of association of the Company adopted by the written resolution of the Shareholders on 16 May 2017 and as amended, supplemented and otherwise modified from time to time “associate(s)” has the meaning ascribed thereto under the Listing Rules “Board” or “Board of Directors” the board of directors of the Company “China” or “PRC” the People’s Republic of China, excluding, for the purpose of this annual report, -

A12 List of China's City Gas Franchising Zones
附录 A12: 中国城市管道燃气特许经营区收录名单 Appendix A03: List of China's City Gas Franchising Zones • 1 Appendix A12: List of China's City Gas Franchising Zones 附录 A12:中国城市管道燃气特许经营区收录名单 No. of Projects / 项目数:3,404 Statistics Update Date / 统计截止时间:2017.9 Source / 来源:http://www.chinagasmap.com Natural gas project investment in China was relatively simple and easy just 10 CNG)、控股投资者(上级管理机构)和一线运营单位的当前主官经理、公司企业 years ago because of the brand new downstream market. It differs a lot since 所有制类型和联系方式。 then: LNG plants enjoyed seller market before, while a LNG plant investor today will find himself soon fighting with over 300 LNG plants for buyers; West East 这套名录的作用 Gas Pipeline 1 enjoyed virgin markets alongside its paving route in 2002, while today's Xin-Zhe-Yue Pipeline Network investor has to plan its route within territory 1. 在基础数据收集验证层面为您的专业信息团队节省 2,500 小时之工作量; of a couple of competing pipelines; In the past, city gas investors could choose to 2. 使城市燃气项目投资者了解当前特许区域最新分布、其他燃气公司的控股势力范 sign golden areas with best sales potential and easy access to PNG supply, while 围;结合中国 LNG 项目名录和中国 CNG 项目名录时,投资者更易于选择新项 today's investors have to turn their sights to areas where sales potential is limited 目区域或谋划收购对象; ...Obviously, today's investors have to consider more to ensure right decision 3. 使 LNG 和 LNG 生产商掌握采购商的最新布局,提前为充分市场竞争做准备; making in a much complicated gas market. China Natural Gas Map's associated 4. 便于 L/CNG 加气站投资者了解市场进入壁垒,并在此基础上谨慎规划选址; project directories provide readers a fundamental analysis tool to make their 5. 结合中国天然气管道名录时,长输管线项目的投资者可根据竞争性供气管道当前 decisions. With a completed idea about venders, buyers and competitive projects, 格局和下游用户的分布,对管道路线和分输口建立初步规划框架。 analyst would be able to shape a better market model when planning a new investment or marketing program.