Molecular Characterisation of Renal Cell Carcinoma and Related Disorders
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hyperactivated Wnt-Β-Catenin Signaling in the Absence of Sfrp1 and Sfrp5 Disrupts Trophoblast Differentiation Through Repressio
Bao et al. BMC Biology (2020) 18:151 https://doi.org/10.1186/s12915-020-00883-4 RESEARCH ARTICLE Open Access Hyperactivated Wnt-β-catenin signaling in the absence of sFRP1 and sFRP5 disrupts trophoblast differentiation through repression of Ascl2 Haili Bao1,2,3†, Dong Liu2†, Yingchun Xu2, Yang Sun2, Change Mu2, Yongqin Yu2, Chunping Wang2, Qian Han2, Sanmei Liu2, Han Cai1,2, Fan Liu2, Shuangbo Kong1,2, Wenbo Deng1,2, Bin Cao1,2, Haibin Wang1,2*, Qiang Wang3,4* and Jinhua Lu1,2* Abstract Background: Wnt signaling is a critical determinant for the maintenance and differentiation of stem/progenitor cells, including trophoblast stem cells during placental development. Hyperactivation of Wnt signaling has been shown to be associated with human trophoblast diseases. However, little is known about the impact and underlying mechanisms of excessive Wnt signaling during placental trophoblast development. Results: In the present work, we observed that two inhibitors of Wnt signaling, secreted frizzled-related proteins 1 and 5 (Sfrp1 and Sfrp5), are highly expressed in the extraembryonic trophoblast suggesting possible roles in early placental development. Sfrp1 and Sfrp5 double knockout mice exhibited disturbed trophoblast differentiation in the placental ectoplacental cone (EPC), which contains the precursors of trophoblast giant cells (TGCs) and spongiotrophoblast cells. In addition, we employed mouse models expressing a truncated β-catenin with exon 3 deletion globally and trophoblast-specifically, as well as trophoblast stem cell lines, and unraveled that hyperactivation of canonical Wnt pathway exhausted the trophoblast precursor cells in the EPC, resulting in the overabundance of giant cells at the expense of spongiotrophoblast cells. -

Supplementary Table 1: Adhesion Genes Data Set
Supplementary Table 1: Adhesion genes data set PROBE Entrez Gene ID Celera Gene ID Gene_Symbol Gene_Name 160832 1 hCG201364.3 A1BG alpha-1-B glycoprotein 223658 1 hCG201364.3 A1BG alpha-1-B glycoprotein 212988 102 hCG40040.3 ADAM10 ADAM metallopeptidase domain 10 133411 4185 hCG28232.2 ADAM11 ADAM metallopeptidase domain 11 110695 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 195222 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 165344 8751 hCG20021.3 ADAM15 ADAM metallopeptidase domain 15 (metargidin) 189065 6868 null ADAM17 ADAM metallopeptidase domain 17 (tumor necrosis factor, alpha, converting enzyme) 108119 8728 hCG15398.4 ADAM19 ADAM metallopeptidase domain 19 (meltrin beta) 117763 8748 hCG20675.3 ADAM20 ADAM metallopeptidase domain 20 126448 8747 hCG1785634.2 ADAM21 ADAM metallopeptidase domain 21 208981 8747 hCG1785634.2|hCG2042897 ADAM21 ADAM metallopeptidase domain 21 180903 53616 hCG17212.4 ADAM22 ADAM metallopeptidase domain 22 177272 8745 hCG1811623.1 ADAM23 ADAM metallopeptidase domain 23 102384 10863 hCG1818505.1 ADAM28 ADAM metallopeptidase domain 28 119968 11086 hCG1786734.2 ADAM29 ADAM metallopeptidase domain 29 205542 11085 hCG1997196.1 ADAM30 ADAM metallopeptidase domain 30 148417 80332 hCG39255.4 ADAM33 ADAM metallopeptidase domain 33 140492 8756 hCG1789002.2 ADAM7 ADAM metallopeptidase domain 7 122603 101 hCG1816947.1 ADAM8 ADAM metallopeptidase domain 8 183965 8754 hCG1996391 ADAM9 ADAM metallopeptidase domain 9 (meltrin gamma) 129974 27299 hCG15447.3 ADAMDEC1 ADAM-like, -

Variants of Innate CD8+ T Cells Are Associated with Grip2 and Klf15 Genes
Cellular & Molecular Immunology www.nature.com/cmi CORRESPONDENCE Variants of innate CD8+ T cells are associated with Grip2 and Klf15 genes Yuna Jo1, Lois Balmer 2,3, Byunghyuk Lee1, Ju A Shim1, Laraib Amir Ali1, Grant Morahan2 and Changwan Hong 1 Cellular & Molecular Immunology (2020) 17:1007–1009; https://doi.org/10.1038/s41423-019-0357-3 Lineage commitment of thymocytes can be distinguished and Next, the frequency of i8Ts was compared with the genotypes modulated by key factors of transcriptional networks, such as of each CC and founder strain. Mapping was performed using the antagonistic expression and function of Th-POK and a logistic regression model (LRM) fit over the reconstructed Runx3 in the CD4 and CD8 lineages1 and Foxp32 and PLZF3 in haplotype matrix.8 The resulting genome-wide distribution of –log CD4+ regulatory T (Treg) cells and natural killer T (NKT) cells, (P) values (ANOVA chi-squared) is shown in Fig. S2a, together with respectively. Little is known, however, about the transcriptional the FDR thresholds. The genome-wide scan for genetic loci regulation of the innate T cell lineage, especially innate CD8+ associated with changes in i8Ts revealed a major peak on T cells (i8Ts), which were initially defined in genetically chromosome 6, centered at 93.7 Mb (Fig. S2b). Within the LOD-2 manipulated mice4 and later in BALB/c mice5 and humans.6 region (89.4–95.6 Mb), Klf15 was the only gene that had a i8Ts are nonconventional αβT cells that exhibit features of nonsynonymous SNP in only the WSB and CAST strains, which memory phenotype and are dependent on IL-4 produced by had the highest i8T levels. -

Neurology Genetics
An Official Journal of the American Academy of Neurology Neurology.org/ng • Online ISSN: 2376-7839 Volume 3, Number 4, August 2017 Genetics Functionally pathogenic ExACtly zero or once: Clinical and experimental EARS2 variants in vitro A clinically helpful guide studies of a novel P525R may not manifest a to assessing genetic FUS mutation in amyotrophic phenotype in vivo variants in mild epilepsies lateral sclerosis Table of Contents Neurology.org/ng Online ISSN: 2376-7839 Volume 3, Number 4, August 2017 THE HELIX e171 Autopsy case of the C12orf65 mutation in a patient e175 What does phenotype have to do with it? with signs of mitochondrial dysfunction S.M. Pulst H. Nishihara, M. Omoto, M. Takao, Y. Higuchi, M. Koga, M. Kawai, H. Kawano, E. Ikeda, H. Takashima, and T. Kanda EDITORIAL e173 This variant alters protein function, but is it pathogenic? M. Pandolfo e174 Prevalence of spinocerebellar ataxia 36 in a US Companion article, e162 population J.M. Valera, T. Diaz, L.E. Petty, B. Quintáns, Z. Yáñez, ARTICLES E. Boerwinkle, D. Muzny, D. Akhmedov, R. Berdeaux, e162 Functionally pathogenic EARS2 variants in vitro may M.J. Sobrido, R. Gibbs, J.R. Lupski, D.H. Geschwind, not manifest a phenotype in vivo S. Perlman, J.E. Below, and B.L. Fogel N. McNeill, A. Nasca, A. Reyes, B. Lemoine, B. Cantarel, A. Vanderver, R. Schiffmann, and D. Ghezzi Editorial, e173 e170 Loss-of-function variants of SCN8A in intellectual disability without seizures e163 ExACtly zero or once: A clinically helpful guide to J.L. Wagnon, B.S. Barker, M. -

Potential Impact of Mir-137 and Its Targets in Schizophrenia
Georgia State University ScholarWorks @ Georgia State University Psychology Faculty Publications Department of Psychology 4-2013 Potential Impact of miR-137 and Its Targets in Schizophrenia Carrie Wright University of New Mexico, [email protected] Jessica Turner Georgia State University, [email protected] Vince D. Calhoun University of New Mexico, [email protected] Nora I. Perrone-Bizzozero University of New Mexico, [email protected] Follow this and additional works at: https://scholarworks.gsu.edu/psych_facpub Part of the Psychology Commons Recommended Citation Wright C, Turner JA, Calhoun VD and Perrone-Bizzozero N (2013) Potential impact of miR-137 and its tar- gets in schizophrenia. Front. Genet. 4:58. doi: http://dx.doi.org/10.3389/fgene.2013.00058 This Article is brought to you for free and open access by the Department of Psychology at ScholarWorks @ Georgia State University. It has been accepted for inclusion in Psychology Faculty Publications by an authorized administrator of ScholarWorks @ Georgia State University. For more information, please contact [email protected]. HYPOTHESIS AND THEORY ARTICLE published: 26 April 2013 doi: 10.3389/fgene.2013.00058 Potential impact of miR-137 and its targets in schizophrenia Carrie Wright 1, Jessica A.Turner 2,3*,Vince D. Calhoun2,3 and Nora Perrone-Bizzozero1* 1 Department of Neurosciences, Health Sciences Center, University of New Mexico, Albuquerque, NM, USA 2 The Mind Research Network, Albuquerque, NM, USA 3 Psychology Department, University of New Mexico, Albuquerque, NM, USA Edited by: The significant impact of microRNAs (miRNAs) on disease pathology is becoming increas- Francis J. McMahon, National ingly evident.These small non-coding RNAs have the ability to post-transcriptionally silence Institute of Mental Health, USA the expression of thousands of genes. -

UC San Diego Electronic Theses and Dissertations
UC San Diego UC San Diego Electronic Theses and Dissertations Title Cardiac Stretch-Induced Transcriptomic Changes are Axis-Dependent Permalink https://escholarship.org/uc/item/7m04f0b0 Author Buchholz, Kyle Stephen Publication Date 2016 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA, SAN DIEGO Cardiac Stretch-Induced Transcriptomic Changes are Axis-Dependent A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Bioengineering by Kyle Stephen Buchholz Committee in Charge: Professor Jeffrey Omens, Chair Professor Andrew McCulloch, Co-Chair Professor Ju Chen Professor Karen Christman Professor Robert Ross Professor Alexander Zambon 2016 Copyright Kyle Stephen Buchholz, 2016 All rights reserved Signature Page The Dissertation of Kyle Stephen Buchholz is approved and it is acceptable in quality and form for publication on microfilm and electronically: Co-Chair Chair University of California, San Diego 2016 iii Dedication To my beautiful wife, Rhia. iv Table of Contents Signature Page ................................................................................................................... iii Dedication .......................................................................................................................... iv Table of Contents ................................................................................................................ v List of Figures ................................................................................................................... -

Polymorphisms in Genes Involved in Neurodevelopment May Be Associated with Altered Brain Morphology in Schizophrenia: Preliminary Evidence
Psychiatry Research 165 (2009) 1–9 www.elsevier.com/locate/psychres Polymorphisms in genes involved in neurodevelopment may be associated with altered brain morphology in schizophrenia: Preliminary evidence Sheila P. Gregório a,b, Paulo C. Sallet a, Kim-Anh Do c, E. Lin c, ⁎ Wagner F. Gattaz a, Emmanuel Dias-Neto a, ,1 a Laboratório de Neurociências (LIM-27), Departmento e Instituto de Psiquiatria, Faculdade de Medicina, Universidade de São Paulo, São Paulo, Brazil b Departmento de Bioquímica, Inst. Química, Universidade de São Paulo, São Paulo, Brazil c Department of Biostatistics, the University of Texas, MD Anderson Cancer Center, 1515 Holcombe Blvd, 77030, Houston, TX, USA Received 24 June 2006; received in revised form 16 July 2007; accepted 18 August 2007 Abstract An abnormality in neurodevelopment is one of the most robust etiologic hypotheses in schizophrenia (SZ). There is also strong evidence that genetic factors may influence abnormal neurodevelopment in the disease. The present study evaluated in SZ patients, whose brain structural data had been obtained with magnetic resonance imaging (MRI), the possible association between structural brain measures, and 32 DNA polymorphisms, located in 30 genes related to neurogenesis and brain development. DNA was extracted from peripheral blood cells of 25 patients with schizophrenia, genotyping was performed using diverse procedures, and putative associations were evaluated by standard statistical methods (using the software Statistical Package for Social Sciences - SPSS) with a modified Bonferroni adjustment. For reelin (RELN), a protease that guides neurons in the developing brain and underlies neurotransmission and synaptic plasticity in adults, an association was found for a non-synonymous polymorphism (Val997Leu) with left and right ventricular enlargement. -

Mechanism-Driven Hypothesis Generation Support for a Predictive Adverse Effect in Colorectal Cancer Treatment
Aus dem Institut für Medizinische Informationsverarbeitung, Biometrie und Epidemiologie, Lehrstuhl Biometrie und Bioinformatik, Ludwig-Maximilians-Universität München Vorstand: Prof. Dr. Ulrich Mansmann Mechanism-driven Hypothesis Generation Support for a Predictive Adverse Effect in Colorectal Cancer Treatment Dissertation zur Erlangung des Doktorgrades der Naturwissenschaften an der Medizinischen Fakultät der Ludwig-Maximilians-Universität zu München vorgelegt von Sebastian Schaaf aus Bergisch Gladbach 2018 ______________________________________________________ Mit Genehmigung der Medizinischen Fakultät der Universität München Betreuer: Prof. Dr. Ulrich Mansmann Zweitgutachter: Prof. Dr. Volker Heun Dekan: Prof. Dr. med. dent. Reinhard Hickel Tag der mündlichen Prüfung: 15.02.2019 Eidesstattliche Versicherung Schaaf, Sebastian Name, Vorname Ich erkläre hiermit an Eides statt, dass ich die vorliegende Dissertation mit dem Thema „Mechanism-driven Hypothesis Generation Support for a Predictive Adverse Effect in Colorectal Cancer Treatment“ selbstständig verfasst, mich außer der angegebenen keiner weiteren Hilfsmittel bedient und alle Erkenntnisse, die aus dem Schrifttum ganz oder annähernd übernommen sind, als solche kenntlich gemacht und nach ihrer Herkunft unter Bezeichnung der Fundstelle einzeln nachgewiesen habe. Ich erkläre des Weiteren, dass die hier vorgelegte Dissertation nicht in gleicher oder in ähnlicher Form bei einer anderen Stelle zur Erlangung eines akademischen Grades eingereicht wurde. Kerpen, 15.01.2020___________ Sebastian_Schaaf_________________ -

The Role of Lamin Associated Domains in Global Chromatin Organization and Nuclear Architecture
THE ROLE OF LAMIN ASSOCIATED DOMAINS IN GLOBAL CHROMATIN ORGANIZATION AND NUCLEAR ARCHITECTURE By Teresa Romeo Luperchio A dissertation submitted to The Johns Hopkins University in conformity with the requirements for the degree of Doctor of Philosophy Baltimore, Maryland March 2016 © 2016 Teresa Romeo Luperchio All Rights Reserved ABSTRACT Nuclear structure and scaffolding have been implicated in expression and regulation of the genome (Elcock and Bridger 2010; Fedorova and Zink 2008; Ferrai et al. 2010; Li and Reinberg 2011; Austin and Bellini 2010). Discrete domains of chromatin exist within the nuclear volume, and are suggested to be organized by patterns of gene activity (Zhao, Bodnar, and Spector 2009). The nuclear periphery, which consists of the inner nuclear membrane and associated proteins, forms a sub- nuclear compartment that is mostly associated with transcriptionally repressed chromatin and low gene expression (Guelen et al. 2008). Previous studies from our lab and others have shown that repositioning genes to the nuclear periphery is sufficient to induce transcriptional repression (K L Reddy et al. 2008; Finlan et al. 2008). In addition, a number of studies have provided evidence that many tissue types, including muscle, brain and blood, use the nuclear periphery as a compartment during development to regulate expression of lineage specific genes (Meister et al. 2010; Szczerbal, Foster, and Bridger 2009; Yao et al. 2011; Kosak et al. 2002; Peric-Hupkes et al. 2010). These large regions of chromatin that come in molecular contact with the nuclear periphery are called Lamin Associated Domains (LADs). The studies described in this dissertation have furthered our understanding of maintenance and establishment of LADs as well as the relationship of LADs with the epigenome and other factors that influence three-dimensional chromatin structure. -
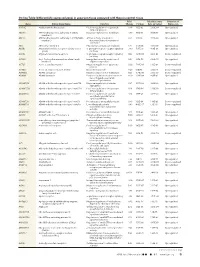
Differentially Expressed Genes in Aneurysm Tissue Compared With
On-line Table: Differentially expressed genes in aneurysm tissue compared with those in control tissue Fold False Discovery Direction of Gene Entrez Gene Name Function Change P Value Rate (q Value) Expression AADAC Arylacetamide deacetylase Positive regulation of triglyceride 4.46 1.33E-05 2.60E-04 Up-regulated catabolic process ABCA6 ATP-binding cassette, subfamily A (ABC1), Integral component of membrane 3.79 9.15E-14 8.88E-12 Up-regulated member 6 ABCC3 ATP-binding cassette, subfamily C (CFTR/MRP), ATPase activity, coupled to 6.63 1.21E-10 7.33E-09 Up-regulated member 3 transmembrane movement of substances ABI3 ABI family, member 3 Peptidyl-tyrosine phosphorylation 6.47 2.47E-05 4.56E-04 Up-regulated ACKR1 Atypical chemokine receptor 1 (Duffy blood G-protein–coupled receptor signaling 3.80 7.95E-10 4.18E-08 Up-regulated group) pathway ACKR2 Atypical chemokine receptor 2 G-protein–coupled receptor signaling 0.42 3.29E-04 4.41E-03 Down-regulated pathway ACSM1 Acyl-CoA synthetase medium-chain family Energy derivation by oxidation of 9.87 1.70E-08 6.52E-07 Up-regulated member 1 organic compounds ACTC1 Actin, ␣, cardiac muscle 1 Negative regulation of apoptotic 0.30 7.96E-06 1.65E-04 Down-regulated process ACTG2 Actin, ␥2, smooth muscle, enteric Blood microparticle 0.29 1.61E-16 2.36E-14 Down-regulated ADAM33 ADAM domain 33 Integral component of membrane 0.23 9.74E-09 3.95E-07 Down-regulated ADAM8 ADAM domain 8 Positive regulation of tumor necrosis 4.69 2.93E-04 4.01E-03 Up-regulated factor (ligand) superfamily member 11 production ADAMTS18 -

Polyclonal Antibody to Protocadherin-12 / PCDH12 (N-Term) - Purified
OriGene Technologies, Inc. OriGene Technologies GmbH 9620 Medical Center Drive, Ste 200 Schillerstr. 5 Rockville, MD 20850 32052 Herford UNITED STATES GERMANY Phone: +1-888-267-4436 Phone: +49-5221-34606-0 Fax: +1-301-340-8606 Fax: +49-5221-34606-11 [email protected] [email protected] AP23866PU-N Polyclonal Antibody to Protocadherin-12 / PCDH12 (N-term) - Purified Alternate names: VE-cad-2, VE-cadherin-2, Vascular cadherin-2, Vascular endothelial cadherin-2 Quantity: 50 µg Concentration: 1 mg/ml Background: PCDH12 / VE-Cadherin-2 belongs to the protocadherin gene family, a subfamily of the cadherin superfamily. The encoded protein consists of an extracellular domain containing 6 cadherin repeats, a transmembrane domain and a cytoplasmic tail that differs from those of the classical cadherins. The gene localizes to the region on chromosome 5 where the protocadherin gene clusters reside. Uniprot ID: Q9NPG4 NCBI: NP_057664 GeneID: 51294 Host: Rabbit Immunogen: 17 amino synthetic peptide near the amino terminus of Human PCDH12. Epitope: N-Terminus. Genename: PCDH12 Format: State: Liquid purfied Ig fraction Purification: Immunoaffinity Chromatography Buffer System: PBS containing 0.02% Sodium Azide Applications: ELISA. Immunohistochemistry on Paraffin Sections: 5 µg/ml. Western Blot: 1 - 2 µg/ml. Other applications not tested. Optimal dilutions are dependent on conditions and should be determined by the user. Specificity: This antibody reacts to the N-term of PCDH12. Species Reactivity: Tested: Human. Expected from sequence similarity: Mouse and Rat. Storage: Store undiluted at 2-8°C for one month or (in aliquots) at -20°C for longer. Avoid repeated freezing and thawing. -

Is Expressed in Endothelial, Trophoblast And
Protocadherin 12 (VE-cadherin 2) is expressed in endothelial, trophoblast and mesangial cells Christine Rampon1, Marie-Hélène Prandini1, Stéphanie Bouillot1, Hervé Pointu2, Emmanuelle Tillet1, Ronald Frank3, Muriel Vernet2 and Philippe Huber1. 1Laboratoire Développement et Vieillissement de l’Endothélium CEA-Inserm EMI-0219 and 2Atelier de Transgenèse, Département de Réponse et Dynamique Cellulaires, CEA-Grenoble, 17 rue des Martyrs 38054 Grenoble, France. 3Department of Chemical Biology, German Research Centre for Biotechnology, D-38124 Braunschweig, Germany. Author for correspondence: Philippe Huber, DRDC-DVE, 17 rue des Martyrs CEA-Grenoble 38 054 Grenoble. Tel: 33-438 78 41 18, Fax: 33-438 78 49 64, e-mail: [email protected]. Short title: Protocadherin 12 tissue expression ABSTRACT Protocadherin 12 protein (PCDH12, VE-cadherin 2) is a cell adhesion molecule which has been isolated from endothelial cells. Here, we have used Northern and Western blots, immunohistology and flow cytometry to examine the distribution of PCDH12 in mouse tissue. It is an N-glycosylated protein of 150 kDa mass. In the endothelium, PCDH12 immunoreactivity was variable and dependent upon the vascular bed. In both the embryo and embryonic stem cell differentiation system, signals were localized in vasculogenic rather than angiogenic endothelium. In addition, the protein was strongly expressed in a subset of invasive cells of the placenta, which were identified as glycogen-rich trophoblasts. In adult mice, strong PCDH12 signals were observed in mesangial cells of kidney glomeruli whereas expression was not detected in other types of perivascular cells. As opposed to most protocadherins, PCDH12 is not expressed in early embryonic (day 12.5) and adult brains.