Lemedisco: a Computational Method for Large-Scale
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2011 Annual Report of the Georgia Research Alliance Not Every Day Brings a Major Win, but in 2011, Many Did
2011 AnnuAl report of the GeorGiA reseArch AlliAnce not every day brings a major win, but in 2011, many did. An advance in science, a venture investment, the growth of a company – these kinds of developments, all connected in some way to the catalytic efforts of the Georgia research Alliance, signaled that Georgia’s technology-rich economy is alive and growing. And that’s good news. In GRA, Georgia has a game Beginning in July, GRA partnered These and other 2011 events Competition among states for plan for building the science- with the Georgia Department and activities represent a economic development and job and technology-driven of Economic Development to foundation for future creation is as intense as ever. economy of tomorrow. And determine how the state’s seven advances, investments and Every advantage matters. GRA in 2011, that game plan was Centers of Innovation, which economic growth. As such, bolsters Georgia’s competitive strengthened when newly help grow strategic industries, they are a reminder that it advantage by expanding elected Governor Nathan Deal can maximize their potential. pays to make every day count. university R&D capacity and moved to align more closely And the Georgia Cancer adding the fuel needed to several of Georgia’s greatest Coalition, the state’s signature launch new enterprises. assets for creating, expanding initiative for cancer research and attracting companies and care, was moved under the that foster high-wage jobs. GRA umbrella. the events of 2011 | JAnuArY – feBruArY Jan 1 Expert in autism named GRA Eminent Scholar Jan 11 Collaboration aims to develop new treatment for ovarian cancer Georgia Tech researchers have Meg Buscema proposed a filtration system that could potentially remove Billy Howard Jan 4 free-floating cancer cells that cause secondary tumors. -

For Ligand- Binding Site Prediction and Functional Annotation
A threading-based method (FINDSITE) for ligand- binding site prediction and functional annotation Michal Brylinski and Jeffrey Skolnick* Center for the Study of Systems Biology, School of Biology, Georgia Institute of Technology, 250 14th Street NW, Atlanta, GA 30318 Edited by Harold A. Scheraga, Cornell University, Ithaca, NY, and approved November 19, 2007 (received for review August 15, 2007) The detection of ligand-binding sites is often the starting point for Connolly surface (21) and then reranks the identified pockets by protein function identification and drug discovery. Because of the degree of conservation of identified surface residues. inaccuracies in predicted protein structures, extant binding pocket- A systematic analysis of known protein structures grouped detection methods are limited to experimentally solved structures. according to SCOP (22) reveals a general tendency of certain Here, FINDSITE, a method for ligand-binding site prediction and protein folds to bind substrates at a similar location, suggesting functional annotation based on binding-site similarity across that analogous or very distantly homologous proteins can have groups of weakly homologous template structures identified from common binding sites (11). If so, it should be possible to develop threading, is described. For crystal structures, considering a cutoff an approach for ligand-binding site identification that is less distance of4Åasthehitcriterion, the success rate is 70.9% for sensitive than pocket-detection methods to distortions in the identifying -

Daisuke Kihara, Ph.D. Professor of Biological Sciences and Computer Science Purdue University
Updated on June 21, 2020 Daisuke Kihara, Ph.D. Professor of Biological Sciences and Computer Science Purdue University Contact Information Purdue University Department of Biological Sciences and Computer Science West Lafayette, IN, 47907 Office: Hockmyer 229 Tel: (765) 496-2284 E-mail: [email protected] https://www.bio.purdue.edu/People/faculty_dm/directory.php?refID=166 https://www.cs.purdue.edu/people/faculty/dkihara/ http://kiharalab.org (Lab) Education 1999 Ph.D. (Science) in Bioinformatics Kyoto University, Faculty of Science, Japan, Advisor: Minoru Kanehisa 1996 M.S. in Bioinformatics Kyoto University, Faculty of Science, Japan 1994 B.S. in Interdisciplinary Science The University of Tokyo, College of Arts and Sciences, Japan Positions held 2019.3-present Full member, Purdue University Center for Cancer Research 2014.8-present Full Professor 2018.3-present Adjunct Professor, University of Cincinnati, Department of Pediatrics 2015.1-2015.8 Visiting Scientist, Eli Lilly, Indianapolis 2009.8-2014.8 Associate professor 2003.8-2009.8 tenure-track Assistant professor Purdue University, West Lafayette, Indiana Department of Biological Sciences/Computer Sciences (joint appointment) 2002.9-2003.7 Senior Postdoctoral Research Associate Advisor: Jeffrey Skolnick Buffalo Center of Excellence in Bioinformatics, Buffalo, NY, USA 1999-2002.9 Postdoctoral Research Associate Advisor: Jeffrey Skolnick Donald Danforth Plant Science Center, St. Louis, MO, USA 1998-1999 Research Assistant Advisor: Minoru Kanehisa Bioinformatics Center, Institute for -

Jacquelyn S. Fetrow
Jacquelyn S. Fetrow President and Professor of Chemistry Albright College Curriculum Vitae Office of the President Work Email: [email protected] Library and Administration Building Office Phone: 610-921-7600 N. 13th and Bern Streets, P.O. Box 15234 Reading, PA 19612 Education Ph.D. Biological Chemistry, December, 1986 B.S. Biochemistry, May, 1982 Department of Biological Chemistry Albright College, Reading, PA The Pennsylvania State University College of Medicine, Hershey, PA Graduated summa cum laude Loops: A Novel Class of Protein Secondary Structure Thesis Advisor: George D. Rose Professional Experience Albright College, Reading PA President and Professor of Chemistry June 2017-present University of Richmond, Richmond, VA Provost and Vice President of Academic Affairs July 2014-December 2016 Professor of Chemistry July 2014-May 2017 Responsibilities as Provost: Chief academic administrator for all academic matters for the University of Richmond, a university with five schools (Arts and Sciences, Business, Law, Leadership, and Professional and Continuing Studies), ~400 faculty and ~3300 full-time undergraduate and graduate students; manage the ~$91.8M annual operating budget of the Academic Affairs Division, as well as endowment and gift accounts; oversee Richmond’s Bonner Center of Civic Engagement (engage.richmond.edu), Center for International Education (international.richmond.edu), Registrar (registrar.richmond.edu), Office of Institutional Effectiveness (ifx.richmond.edu), as well as other programs and staff; partner with VP -

Tertiary Structure Predictions on a Comprehensive Benchmark of Medium to Large Size Proteins
Biophysical Journal Volume 87 October 2004 2647–2655 2647 Tertiary Structure Predictions on a Comprehensive Benchmark of Medium to Large Size Proteins Yang Zhang and Jeffrey Skolnick Center of Excellence in Bioinformatics, University at Buffalo, Buffalo, New York 14203 ABSTRACT We evaluate tertiary structure predictions on medium to large size proteins by TASSER, a new algorithm that assembles protein structures through rearranging the rigid fragments from threading templates guided by a reduced Ca and side-chain based potential consistent with threading based tertiary restraints. Predictions were generated for 745 proteins 201– 300 residues in length that cover the Protein Data Bank (PDB) at the level of 35% sequence identity. With homologous proteins excluded, in 365 cases, the templates identified by our threading program, PROSPECTOR_3, have a root-mean-square deviation (RMSD) to native , 6.5 A˚ , with .70% alignment coverage. After TASSER assembly, in 408 cases the best of the top five full-length models has a RMSD , 6.5 A˚ . Among the 745 targets are 18 membrane proteins, with one-third having a predicted RMSD , 5.5 A˚ . For all representative proteins less than or equal to 300 residues that have corresponding multiple NMR structures in the Protein Data Bank, 20% of the models generated by TASSER are closer to the NMR structure centroid than the farthest individual NMR model. These results suggest that reasonable structure predictions for nonhomologous large size proteins can be automatically generated on a proteomic scale, and the application of this approach to structural as well as functional genomics represent promising applications of TASSER. INTRODUCTION The protein structure prediction problem, that is, deducing a RMSD , 7A˚ in the top five models (Simons et al., 2001). -

Jacquelyn S. Fetrow Executive Resume Office of the President Work Email: [email protected] Library and Administration Building Office Phone: 610-921-7600 N
Jacquelyn S. Fetrow Executive Resume Office of the President Work Email: [email protected] Library and Administration Building Office Phone: 610-921-7600 N. 13th and Bern Streets, P.O. Box 15234 Reading, PA 19612 Current Position: President and Professor of Chemistry June 2017-present Education Ph.D. Biological Chemistry, Penn State, December, 1986 B.S. Biochemistry, Albright College, May, 1982 Professional Experience University of Richmond, Richmond, VA Provost and Vice President for Academic Affairs July 2014-Dec 2016 Professor of Chemistry July 2014-May 2017 Wake Forest University, Winston-Salem, NC Dean, Wake Forest College January 2009-June 2014 Reynolds Professor of Computational Biophysics August 2003-June 2014 Concurrent appointments: Affiliated Faculty, Wake Forest School of Medicine Cancer Center. Department of Biochemistry, Program in Molecular Medicine, Program in Molecular Genetics and Genomics, School of Biomedical Engineering and Science (SBES, joint program between Virginia Tech and Wake Forest) Director, Graduate Track in Structural and Computational Biophysics 2005-2008 GeneFormatics, Inc., San Diego, CA Co-founder, Chief Scientific Officer and Director May 1999-January, 2003 The Scripps Research Institute, La Jolla, CA Associate Professor, Department of Molecular Biology April 1998-May 1999 Visiting Scientist, Department of Molecular Biology (laboratory of Jeffrey Skolnick) January-December 1997 The University at Albany, SUNY, Albany, NY Associate Professor (with tenure), Department of Biological Sciences September 1995-April 1998 Assistant Professor, Department of Biological Sciences January 1990-August 1995 Concurrent/joint appointments: Department of Chemistry, Department of Biomedical Sciences, School of Public Health, Department of Biomedical Science, School of Public Health Postdoctoral Fellowships The Whitehead Institute for Biomedical Research, MIT, Cambridge, MA (Advisor: Peter S. -
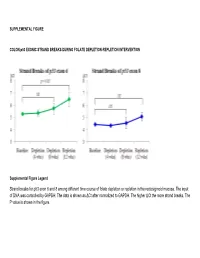
Strand Breaks for P53 Exon 6 and 8 Among Different Time Course of Folate Depletion Or Repletion in the Rectosigmoid Mucosa
SUPPLEMENTAL FIGURE COLON p53 EXONIC STRAND BREAKS DURING FOLATE DEPLETION-REPLETION INTERVENTION Supplemental Figure Legend Strand breaks for p53 exon 6 and 8 among different time course of folate depletion or repletion in the rectosigmoid mucosa. The input of DNA was controlled by GAPDH. The data is shown as ΔCt after normalized to GAPDH. The higher ΔCt the more strand breaks. The P value is shown in the figure. SUPPLEMENT S1 Genes that were significantly UPREGULATED after folate intervention (by unadjusted paired t-test), list is sorted by P value Gene Symbol Nucleotide P VALUE Description OLFM4 NM_006418 0.0000 Homo sapiens differentially expressed in hematopoietic lineages (GW112) mRNA. FMR1NB NM_152578 0.0000 Homo sapiens hypothetical protein FLJ25736 (FLJ25736) mRNA. IFI6 NM_002038 0.0001 Homo sapiens interferon alpha-inducible protein (clone IFI-6-16) (G1P3) transcript variant 1 mRNA. Homo sapiens UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase 15 GALNTL5 NM_145292 0.0001 (GALNT15) mRNA. STIM2 NM_020860 0.0001 Homo sapiens stromal interaction molecule 2 (STIM2) mRNA. ZNF645 NM_152577 0.0002 Homo sapiens hypothetical protein FLJ25735 (FLJ25735) mRNA. ATP12A NM_001676 0.0002 Homo sapiens ATPase H+/K+ transporting nongastric alpha polypeptide (ATP12A) mRNA. U1SNRNPBP NM_007020 0.0003 Homo sapiens U1-snRNP binding protein homolog (U1SNRNPBP) transcript variant 1 mRNA. RNF125 NM_017831 0.0004 Homo sapiens ring finger protein 125 (RNF125) mRNA. FMNL1 NM_005892 0.0004 Homo sapiens formin-like (FMNL) mRNA. ISG15 NM_005101 0.0005 Homo sapiens interferon alpha-inducible protein (clone IFI-15K) (G1P2) mRNA. SLC6A14 NM_007231 0.0005 Homo sapiens solute carrier family 6 (neurotransmitter transporter) member 14 (SLC6A14) mRNA. -

Sean Raspet – Molecules
1. Commercial name: Fructaplex© IUPAC Name: 2-(3,3-dimethylcyclohexyl)-2,5,5-trimethyl-1,3-dioxane SMILES: CC1(C)CCCC(C1)C2(C)OCC(C)(C)CO2 Molecular weight: 240.39 g/mol Volume (cubic Angstroems): 258.88 Atoms number (non-hydrogen): 17 miLogP: 4.43 Structure: Biological Properties: Predicted Druglikenessi: GPCR ligand -0.23 Ion channel modulator -0.03 Kinase inhibitor -0.6 Nuclear receptor ligand 0.15 Protease inhibitor -0.28 Enzyme inhibitor 0.15 Commercial name: Fructaplex© IUPAC Name: 2-(3,3-dimethylcyclohexyl)-2,5,5-trimethyl-1,3-dioxane SMILES: CC1(C)CCCC(C1)C2(C)OCC(C)(C)CO2 Predicted Olfactory Receptor Activityii: OR2L13 83.715% OR1G1 82.761% OR10J5 80.569% OR2W1 78.180% OR7A2 77.696% 2. Commercial name: Sylvoxime© IUPAC Name: N-[4-(1-ethoxyethenyl)-3,3,5,5tetramethylcyclohexylidene]hydroxylamine SMILES: CCOC(=C)C1C(C)(C)CC(CC1(C)C)=NO Molecular weight: 239.36 Volume (cubic Angstroems): 252.83 Atoms number (non-hydrogen): 17 miLogP: 4.33 Structure: Biological Properties: Predicted Druglikeness: GPCR ligand -0.6 Ion channel modulator -0.41 Kinase inhibitor -0.93 Nuclear receptor ligand -0.17 Protease inhibitor -0.39 Enzyme inhibitor 0.01 Commercial name: Sylvoxime© IUPAC Name: N-[4-(1-ethoxyethenyl)-3,3,5,5tetramethylcyclohexylidene]hydroxylamine SMILES: CCOC(=C)C1C(C)(C)CC(CC1(C)C)=NO Predicted Olfactory Receptor Activity: OR52D1 71.900% OR1G1 70.394% 0R52I2 70.392% OR52I1 70.390% OR2Y1 70.378% 3. Commercial name: Hyperflor© IUPAC Name: 2-benzyl-1,3-dioxan-5-one SMILES: O=C1COC(CC2=CC=CC=C2)OC1 Molecular weight: 192.21 g/mol Volume -

Emidio Capriotti Phd CURRICULUM VITÆ
Emidio Capriotti PhD CURRICULUM VITÆ Name: Emidio Capriotti Nationality: Italian Date of birth: February, 1973 Place of birth: Roma, Italy Languages: Italian, English, Spanish Positions Oct 2019 Associate Professor: Department of Pharmacy and Biotechnology (FaBiT). University of Bologna, Bologna, Italy 2016-2019 Senior Assistant Professor (RTD type B): Department of Pharmacy and Biotechnology (FaBiT) and Department of Biological, Geological, and Environmental Sciences (BiGeA). University of Bologna, Bologna, Italy. 2015-2016 Junior Group Leader: Institute of Mathematical Modeling of Biological Systems, University of Düsseldorf, Düsseldorf, Germany 2012-2015 Assistant Professor: Division of Informatics, Department of Pathology, University of Alabama at Birmingham (UAB), Birmingham (AL), USA. 2011-2012 Marie-Curie IOF: Contracted Researcher at the Department of Mathematics and Computer Science, University of Balearic Islands (UIB), Palma de Mallorca, Spain. 2009-2011 Marie-Curie IOF: Postdoctoral Researcher at the Helix Group, Department of Bioengineering, Stanford University, Stanford (CA), USA. 2006-2009 Postdoctoral Researcher in the Structural Genomics Group at Department of Bioinformatics and Genetics, Prince Felipe Research Center (CIPF) Valencia, Spain. 2004-2006 Contract researcher at Department of Biology, University of Bologna, Bologna, Italy. 2001-2003 Ph.D student in Physical Sciences at University of Bologna, Bologna, Italy. Education Sep 2004 Master in Bioinformatics (first level) University of Bologna, Bologna (Italy). Jun 2004 Ph.D. in Physical Sciences University of Bologna, Bologna (Italy). Jul 1999 Laurea (B.S.) Degree in Physical Sciences, score 106/110 University of Bologna, Bologna (Italy). Visiting Jun 2012 – Jul 2012 Prof. Frederic Rousseau and Prof. Joost Schymkowitz, VIB Switch Laboratory, KU Leuven, Leuven (Belgium) May 2009 Prof. -

Clinical, Molecular, and Immune Analysis of Dabrafenib-Trametinib
Supplementary Online Content Chen G, McQuade JL, Panka DJ, et al. Clinical, molecular and immune analysis of dabrafenib-trametinib combination treatment for metastatic melanoma that progressed during BRAF inhibitor monotherapy: a phase 2 clinical trial. JAMA Oncology. Published online April 28, 2016. doi:10.1001/jamaoncol.2016.0509. eMethods. eReferences. eTable 1. Clinical efficacy eTable 2. Adverse events eTable 3. Correlation of baseline patient characteristics with treatment outcomes eTable 4. Patient responses and baseline IHC results eFigure 1. Kaplan-Meier analysis of overall survival eFigure 2. Correlation between IHC and RNAseq results eFigure 3. pPRAS40 expression and PFS eFigure 4. Baseline and treatment-induced changes in immune infiltrates eFigure 5. PD-L1 expression eTable 5. Nonsynonymous mutations detected by WES in baseline tumors This supplementary material has been provided by the authors to give readers additional information about their work. © 2016 American Medical Association. All rights reserved. Downloaded From: https://jamanetwork.com/ on 09/30/2021 eMethods Whole exome sequencing Whole exome capture libraries for both tumor and normal samples were constructed using 100ng genomic DNA input and following the protocol as described by Fisher et al.,3 with the following adapter modification: Illumina paired end adapters were replaced with palindromic forked adapters with unique 8 base index sequences embedded within the adapter. In-solution hybrid selection was performed using the Illumina Rapid Capture Exome enrichment kit with 38Mb target territory (29Mb baited). The targeted region includes 98.3% of the intervals in the Refseq exome database. Dual-indexed libraries were pooled into groups of up to 96 samples prior to hybridization. -
![A Glance Into the Evolution of Template-Free Protein Structure Prediction Methodologies Arxiv:2002.06616V2 [Q-Bio.QM] 24 Apr 2](https://docslib.b-cdn.net/cover/3618/a-glance-into-the-evolution-of-template-free-protein-structure-prediction-methodologies-arxiv-2002-06616v2-q-bio-qm-24-apr-2-2853618.webp)
A Glance Into the Evolution of Template-Free Protein Structure Prediction Methodologies Arxiv:2002.06616V2 [Q-Bio.QM] 24 Apr 2
A glance into the evolution of template-free protein structure prediction methodologies Surbhi Dhingra1, Ramanathan Sowdhamini2, Frédéric Cadet3,4,5, and Bernard Offmann∗1 1Université de Nantes, CNRS, UFIP, UMR6286, F-44000 Nantes, France 2Computational Approaches to Protein Science (CAPS), National Centre for Biological Sciences (NCBS), Tata Institute for Fundamental Research (TIFR), Bangalore 560-065, India 3University of Paris, BIGR—Biologie Intégrée du Globule Rouge, Inserm, UMR_S1134, Paris F-75015, France 4Laboratory of Excellence GR-Ex, Boulevard du Montparnasse, Paris F-75015, France 5DSIMB, UMR_S1134, BIGR, Inserm, Faculty of Sciences and Technology, University of La Reunion, Saint-Denis F-97715, France Abstract Prediction of protein structures using computational approaches has been explored for over two decades, paving a way for more focused research and development of algorithms in com- parative modelling, ab intio modelling and structure refinement protocols. A tremendous suc- cess has been witnessed in template-based modelling protocols, whereas strategies that involve template-free modelling still lag behind, specifically for larger proteins (> 150 a.a.). Various improvements have been observed in ab initio protein structure prediction methodologies over- time, with recent ones attributed to the usage of deep learning approaches to construct protein backbone structure from its amino acid sequence. This review highlights the major strategies undertaken for template-free modelling of protein structures while discussing few tools devel- arXiv:2002.06616v2 [q-bio.QM] 24 Apr 2020 oped under each strategy. It will also briefly comment on the progress observed in the field of ab initio modelling of proteins over the course of time as seen through the evolution of CASP platform. -

American Society for Biochemistry and Molecular Biology
Vol. 12 No. 9 October 2013 American Society for Biochemistry and Molecular Biology contents OCTOBER 2013 On the cover: ASBMB Today senior news science writer Rajendrani Mukhopadhyay writes about 2 President’s Message what we know about the Listing unsolved problems origins of proteins. 12 MANY THANKS TO TIMOTHY COLLIER AND RON 4 BOSE AT THE WASHINGTON UNIVERSITY SCHOOL News from the Hill OF MEDICINE IN ST. LOUIS FOR THE COVER IMAGE. An open letter to our readers who have something to say Have you taken the challenge? but need a place (and maybe even permission) to say it 5 Member Update 6 Retrospective Dear Reader, Tony Pawson (1952 – 2013) This is your magazine. Seriously, it is. You support it when you renew your ASBMB dues, share its contents with 8 Tabor award winners F. Peter Guengerich of Vanderbilt University, your friends and colleagues, crack it open on the train and even when you use it as a coaster for your coffee mug. 9 NIH Update It’s yours. an associate editor for the Journal of Biological Chemistry, writes about how features working on the family farm made him a Over the past two years, we’ve worked hard to get more of *you* in these pages. We’ve asked for your science- disciplined scientist. 10 inspired poems (thanks for humoring me), your unique perspectives (keep ’em coming) and, most recently, your 12 ‘Close to a miracle’ inspiring stories of failure and triumph (the “Derailed but Undeterred” series). Your contributions have trans- Researchers are debating the origins of proteins formed this magazine into one with greater depth, unique storytelling and diversity of ideas.