Aberystwyth University a Note on the Ogham Inscription from Buckquoy
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Early Medieval Dykes (400 to 850 Ad)
EARLY MEDIEVAL DYKES (400 TO 850 AD) A thesis submitted to the University of Manchester for the degree of Doctor of Philosophy in the Faculty of Humanities 2015 Erik Grigg School of Arts, Languages and Cultures Contents Table of figures ................................................................................................ 3 Abstract ........................................................................................................... 6 Declaration ...................................................................................................... 7 Acknowledgments ........................................................................................... 9 1 INTRODUCTION AND METHODOLOGY ................................................. 10 1.1 The history of dyke studies ................................................................. 13 1.2 The methodology used to analyse dykes ............................................ 26 2 THE CHARACTERISTICS OF THE DYKES ............................................. 36 2.1 Identification and classification ........................................................... 37 2.2 Tables ................................................................................................. 39 2.3 Probable early-medieval dykes ........................................................... 42 2.4 Possible early-medieval dykes ........................................................... 48 2.5 Probable rebuilt prehistoric or Roman dykes ...................................... 51 2.6 Probable reused prehistoric -

Historical Background of the Contact Between Celtic Languages and English
Historical background of the contact between Celtic languages and English Dominković, Mario Master's thesis / Diplomski rad 2016 Degree Grantor / Ustanova koja je dodijelila akademski / stručni stupanj: Josip Juraj Strossmayer University of Osijek, Faculty of Humanities and Social Sciences / Sveučilište Josipa Jurja Strossmayera u Osijeku, Filozofski fakultet Permanent link / Trajna poveznica: https://urn.nsk.hr/urn:nbn:hr:142:149845 Rights / Prava: In copyright Download date / Datum preuzimanja: 2021-09-27 Repository / Repozitorij: FFOS-repository - Repository of the Faculty of Humanities and Social Sciences Osijek Sveučilište J. J. Strossmayera u Osijeku Filozofski fakultet Osijek Diplomski studij engleskog jezika i književnosti – nastavnički smjer i mađarskog jezika i književnosti – nastavnički smjer Mario Dominković Povijesna pozadina kontakta između keltskih jezika i engleskog Diplomski rad Mentor: izv. prof. dr. sc. Tanja Gradečak – Erdeljić Osijek, 2016. Sveučilište J. J. Strossmayera u Osijeku Filozofski fakultet Odsjek za engleski jezik i književnost Diplomski studij engleskog jezika i književnosti – nastavnički smjer i mađarskog jezika i književnosti – nastavnički smjer Mario Dominković Povijesna pozadina kontakta između keltskih jezika i engleskog Diplomski rad Znanstveno područje: humanističke znanosti Znanstveno polje: filologija Znanstvena grana: anglistika Mentor: izv. prof. dr. sc. Tanja Gradečak – Erdeljić Osijek, 2016. J.J. Strossmayer University in Osijek Faculty of Humanities and Social Sciences Teaching English as -

The Irish Language in Education in Northern Ireland 2Nd Edition
Irish The Irish language in education in Northern Ireland 2nd edition This document was published by Mercator-Education with financial support from the Fryske Akademy and the European Commission (DG XXII: Education, Training and Youth) ISSN: 1570-1239 © Mercator-Education, 2004 The contents of this publication may be reproduced in print, except for commercial purposes, provided that the extract is proceeded by a complete reference to Mercator- Education: European network for regional or minority languages and education. Mercator-Education P.O. Box 54 8900 AB Ljouwert/Leeuwarden The Netherlands tel. +31- 58-2131414 fax: + 31 - 58-2131409 e-mail: [email protected] website://www.mercator-education.org This regional dossier was originally compiled by Aodán Mac Póilin from Ultach Trust/Iontaobhas Ultach and Mercator Education in 1997. It has been updated by Róise Ní Bhaoill from Ultach Trust/Iontaobhas Ultach in 2004. Very helpful comments have been supplied by Dr. Lelia Murtagh, Department of Psycholinguistics, Institúid Teangeolaíochta Éireann (ITE), Dublin. Unless stated otherwise the data reflect the situation in 2003. Acknowledgment: Mo bhuíochas do mo chomhghleacaithe in Iontaobhas ULTACH, do Liz Curtis, agus do Sheán Ó Coinn, Comhairle na Gaelscolaíochta as a dtacaíocht agus a gcuidiú agus mé i mbun na hoibre seo, agus don Roinn Oideachas agus an Roinn Fostaíochta agus Foghlama as an eolas a cuireadh ar fáil. Tsjerk Bottema has been responsible for the publication of the Mercator regional dossiers series from January 2004 onwards. Contents Foreword ..................................................1 1. Introduction .........................................2 2. Pre-school education .................................13 3. Primary education ...................................16 4. Secondary education .................................19 5. Further education ...................................22 6. -

Corpas Na Gaeilge (1882-1926): Integrating Historical and Modern
Corpas na Gaeilge (1882-1926): Integrating Historical and Modern Irish Texts Elaine Uí Dhonnchadha3, Kevin Scannell7, Ruairí Ó hUiginn2, Eilís Ní Mhearraí1, Máire Nic Mhaoláin1, Brian Ó Raghallaigh4, Gregory Toner5, Séamus Mac Mathúna6, Déirdre D’Auria1, Eithne Ní Ghallchobhair1, Niall O’Leary1 1Royal Irish Academy, Dublin, Ireland 2National University of Ireland Maynooth, Ireland 3Trinity College Dublin, Ireland 4Dublin City University, Ireland 5Queens University Belfast, Northern Ireland 6University of Ulster, Northern Ireland 7Saint Louis University, Missouri, USA E-mail: [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected]; [email protected], [email protected] Abstract This paper describes the processing of a corpus of seven million words of Irish texts from the period 1882-1926. The texts which have been captured by typing or optical character recognition are processed for the purpose of lexicography. Firstly, all historical and dialectal word forms are annotated with their modern standard equivalents using software developed for this purpose. Then, using the modern standard annotations, the texts are processed using an existing finite-state morphological analyser and part-of-speech tagger. This method enables us to retain the original historical text, and at the same time have full corpus-searching capabilities using modern lemmas and inflected forms (one can also use the historical forms). It also makes use of existing NLP tools for modern Irish, and enables integration of historical and modern Irish corpora. Keywords: historical corpus, normalisation, standardisation, natural language processing, Irish, Gaeilge 1. -

The Cornish Language in Education in the UK
The Cornish language in education in the UK European Research Centre on Multilingualism and Language Learning hosted by CORNISH The Cornish language in education in the UK | 2nd Edition | c/o Fryske Akademy Doelestrjitte 8 P.O. Box 54 NL-8900 AB Ljouwert/Leeuwarden The Netherlands T 0031 (0) 58 - 234 3027 W www.mercator-research.eu E [email protected] | Regional dossiers series | tca r cum n n i- ual e : Available in this series: This document was published by the Mercator European Research Centre on Multilingualism Albanian; the Albanian language in education in Italy Aragonese; the Aragonese language in education in Spain and Language Learning with financial support from the Fryske Akademy and the Province Asturian; the Asturian language in education in Spain (2nd ed.) of Fryslân. Basque; the Basque language in education in France (2nd ed.) Basque; the Basque language in education in Spain (2nd ed.) Breton; the Breton language in education in France (2nd ed.) Catalan; the Catalan language in education in France Catalan; the Catalan language in education in Spain (2nd ed.) © Mercator European Research Centre on Multilingualism Cornish; the Cornish language in education in the UK (2nd ed.) and Language Learning, 2019 Corsican; the Corsican language in education in France (2nd ed.) Croatian; the Croatian language in education in Austria Danish; The Danish language in education in Germany ISSN: 1570 – 1239 Frisian; the Frisian language in education in the Netherlands (4th ed.) 2nd edition Friulian; the Friulian language in education in Italy Gàidhlig; The Gaelic Language in Education in Scotland (2nd ed.) Galician; the Galician language in education in Spain (2nd ed.) The contents of this dossier may be reproduced in print, except for commercial purposes, German; the German language in education in Alsace, France (2nd ed.) provided that the extract is proceeded by a complete reference to the Mercator European German; the German language in education in Belgium Research Centre on Multilingualism and Language Learning. -

Preservation of Original Orthography in the Construction of an Old Irish Corpus
Preservation of Original Orthography in the Construction of an Old Irish Corpus. Adrian Doyle, John P. McCrae, Clodagh Downey National University of Ireland Galway [email protected], [email protected], [email protected] Abstract Irish was one of the earliest vernacular European languages to have been written using the Latin alphabet. Furthermore, there exists a relatively large corpus of Irish language text dating to this Old Irish period (c. 700 – c 950). Beginning around the turn of the twentieth century, a large amount of study into Old Irish revealed a highly standardised language with a rich morphology, and often creative orthography. While Modern Irish enjoys recognition from the Irish state as the first official language, and from the EU as a full official and working language, Old Irish is almost incomprehensible to most modern speakers, and remains extremely under-resourced. This paper will examine considerations which must be given to aspects of orthography and palaeography before the text of a historical manuscript can be represented in digital format. Based on these considerations the argument will be presented that digitising the text of the Würzburg glosses as it appears in Thesaurus Palaeohibernicus will enable the use of computational analysis to aid in current areas of linguistic research by preserving original orthographical information. The process of compiling the digital corpus, including considerations given to preservation of orthographic information during this process, will then be detailed. Keywords: manuscripts, palaeography, orthography, digitisation, optical character recognition, Python, Unicode, morphology, Old Irish, historical languages glosses]” (2006, p.10). Before any text can be deemed 1. -

Symbols of Power in Ireland and Scotland, 8Th-10Th Century Dr
Symbols of power in Ireland and Scotland, 8th-10th century Dr. Katherine Forsyth (Department of Celtic, University of Glasgow, Scotland) Prof. Stephen T. Driscoll (Department of Archaeology, University of Glasgow, Scotland) d Territorio, Sociedad y Poder, Anejo Nº 2, 2009 [pp. 31-66] TSP Anexto 4.indb 31 15/11/09 17:22:04 Resumen: Este artículo investiga algunos de los símbolos utilizaron las cruces de piedra en su inserción espacial como del poder utilizados por las autoridades reales en Escocia signos de poder. La segunda parte del trabajo analiza más e Irlanda a lo largo de los siglos viii al x. La primera parte ampliamente los aspectos visibles del poder y la naturaleza del trabajo se centra en las cruces de piedra, tanto las cruces de las sedes reales en Escocia e Irlanda. Los ejemplos exentas (las high crosses) del mundo gaélico de Irlanda estudiados son la sede de la alta realeza irlandesa en Tara y y la Escocia occidental, como las lastras rectangulares la residencia regia gaélica de Dunnadd en Argyll. El trabajo con cruz de la tierra de los pictos. El monasterio de concluye volviendo al punto de partida con el examen del Clonmacnoise ofrece un ejemplo muy bien documentado centro regio picto de Forteviot. de patronazgo regio, al contrario que el ejemplo escocés de Portmahomack, carente de base documental histórica, Palabras clave: pictos, gaélicos, escultura, Clonmacnoise, pero en ambos casos es posible examinar cómo los reyes Portmahomack, Tara, Dunnadd, Forteviot. Abstract: This paper explores some of the symbols of power landscape context as an expression of power. -
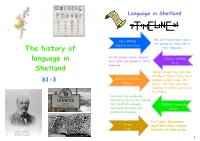
The History of Language in Shetland
Language in Shetland We don’t know much about Pre-300AD the people of Shetland or Before the Picts The history of their language. Pictish people carve symbols 300AD-800AD language in into stone and speak a ‘Celtic’ Picts language. Shetland Vikings occupy the isles and introduce ‘Norn’. They carve S1-3 800AD-1500AD symbols called ‘runes’ into Vikings stone. The Picts and their language are then wiped out by Vikings. Scotland rule gradually influences life on the islands. The Scottish language 1500AD onwards eventually becomes the Scots prominent language. The dialect Shetlanders Today speak with today contains Us! Scottish and Norn words. 2 THE PICTS Ogham alphabet Some carvings are part of an The Picts spoke a Celtic The Picts lived in mainland alphabet called ‘ogham’. Ogham language, originating from Scotland from around the 6th represents the spoken language of Ireland. Picts may have to the 9th Century, possibly the Picts, by using a ‘stem’ with travelled from Ireland, earlier. Indications of a shorter lines across it or on either Scotland or further afield burial at Sumburgh suggest side of it. to settle on Shetland. that Picts had probably settled in Shetland by There are seven ogham ogham.celt.dias.ie 300AD. inscriptions from Shetland Picts in Shetland spoke one of (including St Ninian’s Isle, The side, number and angle of the the ‘strands’ of the Celtic Cunningsburgh and Bressay) short lines to the stem indicates the language. Picts also carved symbols onto and one from a peat bog in intended sound. Lunnasting. stone. These symbols have been found throughout These symbol stones may Scotland—common symbols have been grave markers, or This inscribed sandstone was dug they may have indicated up from the area of the ancient must have been understood by gathering points. -

Maccoinnich, A. (2008) Where and How Was Gaelic Written in Late Medieval and Early Modern Scotland? Orthographic Practices and Cultural Identities
MacCoinnich, A. (2008) Where and how was Gaelic written in late medieval and early modern Scotland? Orthographic practices and cultural identities. Scottish Gaelic Studies, XXIV . pp. 309-356. ISSN 0080-8024 http://eprints.gla.ac.uk/4940/ Deposited on: 13 February 2009 Enlighten – Research publications by members of the University of Glasgow http://eprints.gla.ac.uk WHERE AND HOW WAS GAELIC WRITTEN IN LATE MEDIEVAL AND EARLY MODERN SCOTLAND? ORTHOGRAPHIC PRACTICES AND CULTURAL IDENTITIES This article owes its origins less to the paper by Kathleen Hughes (1980) suggested by this title, than to the interpretation put forward by Professor Derick Thomson (1968: 68; 1994: 100) that the Scots- based orthography used by the scribe of the Book of the Dean of Lismore (c.1514–42) to write his Gaelic was anomalous or an aberration − a view challenged by Professor Donald Meek in his articles ‘Gàidhlig is Gaylick anns na Meadhon Aoisean’ and ‘The Scoto-Gaelic scribes of late medieval Perth-shire’ (Meek 1989a; 1989b). The orthography and script used in the Book of the Dean has been described as ‘Middle Scots’ and ‘secretary’ hand, in sharp contrast to traditional Classical Gaelic spelling and corra-litir (Meek 1989b: 390). Scholarly debate surrounding the nature and extent of traditional Gaelic scribal activity and literacy in Scotland in the late medieval and early modern period (roughly 1400–1700) has flourished in the interim. It is hoped that this article will provide further impetus to the discussion of the nature of the literacy and literary culture of Gaelic Scots by drawing on the work of these scholars, adding to the debate concerning the nature, extent and status of the literacy and literary activity of Gaelic Scots in Scotland during the period c.1400–1700, by considering the patterns of where people were writing Gaelic in Scotland, with an eye to the usage of Scots orthography to write such Gaelic. -

The Iconography of the Papil Stone: Sculptural and Literary Comparisons with a Pictish Motif*
Proc Soc Antiq Scot 141 (2011), 159–205 THE ICONOGRAPHY OF THE PAPIL STONE | 159 The iconography of the Papil Stone: sculptural and literary comparisons with a Pictish motif* Kelly A Kilpatrick† ABSTRACT The axe-carrying bird-men and the remaining iconography of the cross-slab from Papil, West Burra, Shetland, are described and analysed. Special emphasis is placed on examining the Papil bird- men first with Irish and Pictish examples of the Temptation of St Antony and second with detailed descriptions of weapon-carrying bird-men and axe-carrying human figures in Pictish sculpture, concluding that the Papil bird-men belong with the latter. This motif is compared with descriptions of battlefield demons in early Irish literature, namely, Morrígan, Bodb and Macha. The Papil cross- slab is suggested to date to the early 9th century, based on technique and comparative iconographic evidence, and is thus contemporary with related Pictish examples. This motif is shown to represent a common ideal of mythological war-like creatures in Pictish tradition, paralleled by written descriptions of Irish battlefield demons, thus suggesting shared perceptions of similar mythological figures in the Insular world. A further connection between Ireland, Irish ecclesiastical foundations in the Hebrides, Shetland and southern Pictland is also discussed. INTRODUCTION Pictish monumental art. In many instances this has conditioned the suggested interpretations The cross-slab known as the Papil Stone of the monument’s iconography. In previous (illus 1 & 2) was discovered in 1887 by studies, various icons from this cross-slab Gilbert Goudie (1881) in the churchyard of have been compared individually with similar St Laurence’s Church, Papil, West Burra, examples in Britain and Ireland, especially Shetland (NGR HU 3698 3141). -

Ancient Greek Tragedy and Irish Epic in Modern Irish
MEMORABLE BARBARITIES AND NATIONAL MYTHS: ANCIENT GREEK TRAGEDY AND IRISH EPIC IN MODERN IRISH THEATRE A Dissertation Submitted to the Graduate School of the University of Notre Dame in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy by Katherine Anne Hennessey, B.A., M.A. ____________________________ Dr. Susan Cannon Harris, Director Graduate Program in English Notre Dame, Indiana March 2008 MEMORABLE BARBARITIES AND NATIONAL MYTHS: ANCIENT GREEK TRAGEDY AND IRISH EPIC IN MODERN IRISH THEATRE Abstract by Katherine Anne Hennessey Over the course of the 20th century, Irish playwrights penned scores of adaptations of Greek tragedy and Irish epic, and this theatrical phenomenon continues to flourish in the 21st century. My dissertation examines the performance history of such adaptations at Dublin’s two flagship theatres: the Abbey, founded in 1904 by W.B. Yeats and Lady Gregory, and the Gate, established in 1928 by Micheál Mac Liammóir and Hilton Edwards. I argue that the potent rivalry between these two theatres is most acutely manifest in their production of these plays, and that in fact these adaptations of ancient literature constitute a “disputed territory” upon which each theatre stakes a claim of artistic and aesthetic preeminence. Partially because of its long-standing claim to the title of Ireland’s “National Theatre,” the Abbey has been the subject of the preponderance of scholarly criticism about the history of Irish theatre, while the Gate has received comparatively scarce academic attention. I contend, however, that the history of the Abbey--and of modern Irish theatre as a whole--cannot be properly understood except in relation to the strikingly different aesthetics practiced at the Gate. -

Language, Politics and Identity in Ireland: a Historical Overview
This is a repository copy of Language, Politics and Identity in Ireland: a Historical Overview. White Rose Research Online URL for this paper: http://eprints.whiterose.ac.uk/98924/ Version: Accepted Version Book Section: Crowley, AE (2016) Language, Politics and Identity in Ireland: a Historical Overview. In: Hickey, R, (ed.) Sociolinguistics in Ireland. Palgrave Macmillan , London , pp. 198-217. ISBN 978-1-137-45347-1 Reuse Items deposited in White Rose Research Online are protected by copyright, with all rights reserved unless indicated otherwise. They may be downloaded and/or printed for private study, or other acts as permitted by national copyright laws. The publisher or other rights holders may allow further reproduction and re-use of the full text version. This is indicated by the licence information on the White Rose Research Online record for the item. Takedown If you consider content in White Rose Research Online to be in breach of UK law, please notify us by emailing [email protected] including the URL of the record and the reason for the withdrawal request. [email protected] https://eprints.whiterose.ac.uk/ Language, politics and identity in Ireland: a historical overview. Tony Crowley 1. Introduction. The Belfast Agreement (1998) brought about new constitutional arrangements between the Republic of Ireland and the United Kingdom, and a new structure of governance within Northern Ireland. Designed, amongst other aims, to end the war in Northern Ireland that had lasted almost thirty years, the agreement was arguably the most important political development within Ireland since the declaration of the Irish Republic in 1948.