The Need to Measure Variance in Experiential Learning and a New Statistic to Do So
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ocr IB 1967 '70
ocr IB 1967 '70 OAK RIDGE NATIONAL LABORATORY operated by UNION CARBIDE CORPORATION NUCLEAR DIVISION for the • U.S. ATOMIC ENERGY COMMISSION ORNL - TM- 1919 INDICES OF QUALITATIVE VARIATION Allen R. Wilcox NOTICE This document contains information of a preliminary natur<> and was prepared primarily far internal use at the Oak Ridge National Laboratory. It is subject to revision or correction and therefore doe> not represent o finol report. DISCLAIMER This report was prepared as an account of work sponsored by an agency of the United States Government. Neither the United States Government nor any agency Thereof, nor any of their employees, makes any warranty, express or implied, or assumes any legal liability or responsibility for the accuracy, completeness, or usefulness of any information, apparatus, product, or process disclosed, or represents that its use would not infringe privately owned rights. Reference herein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise does not necessarily constitute or imply its endorsement, recommendation, or favoring by the United States Government or any agency thereof. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States Government or any agency thereof. DISCLAIMER Portions of this document may be illegible in electronic image products. Images are produced from the best available original document. .-------------------LEGAL NOTICE--------------~ This report was prepared as on account of Government sponsored work. Neither the United States, nor the Commission, nor any person acting on behalf of the Commission: A. Makes any warranty or representation, expressed or implied, with respect to the accuracy, compl""t"'n~<~~:oo;, nr ulltf!fulnes!l: of the information conto1ned in this report, or that the use of any information, apparatus, method, or process disc lased in this report may not infringe privately ownsd rights; or B. -

A Two Parameter Discrete Lindley Distribution
Revista Colombiana de Estadística January 2016, Volume 39, Issue 1, pp. 45 to 61 DOI: http://dx.doi.org/10.15446/rce.v39n1.55138 A Two Parameter Discrete Lindley Distribution Distribución Lindley de dos parámetros Tassaddaq Hussain1;a, Muhammad Aslam2;b, Munir Ahmad3;c 1Department of Statistics, Government Postgraduate College, Rawalakot, Pakistan 2Department of Statistics, Faculty of Sciences, King Abdulaziz University, Jeddah, Saudi Arabia 3National College of Business Administration and Economics, Lahore, Pakistan Abstract In this article we have proposed and discussed a two parameter discrete Lindley distribution. The derivation of this new model is based on a two step methodology i.e. mixing then discretizing, and can be viewed as a new generalization of geometric distribution. The proposed model has proved itself as the least loss of information model when applied to a number of data sets (in an over and under dispersed structure). The competing mod- els such as Poisson, Negative binomial, Generalized Poisson and discrete gamma distributions are the well known standard discrete distributions. Its Lifetime classification, kurtosis, skewness, ascending and descending factorial moments as well as its recurrence relations, negative moments, parameters estimation via maximum likelihood method, characterization and discretized bi-variate case are presented. Key words: Characterization, Discretized version, Estimation, Geometric distribution, Mean residual life, Mixture, Negative moments. Resumen En este artículo propusimos y discutimos la distribución Lindley de dos parámetros. La obtención de este Nuevo modelo está basada en una metodo- logía en dos etapas: mezclar y luego discretizar, y puede ser vista como una generalización de una distribución geométrica. El modelo propuesto de- mostró tener la menor pérdida de información al ser aplicado a un cierto número de bases de datos (con estructuras de supra y sobredispersión). -

Current Practices in Quantitative Literacy © 2006 by the Mathematical Association of America (Incorporated)
Current Practices in Quantitative Literacy © 2006 by The Mathematical Association of America (Incorporated) Library of Congress Catalog Card Number 2005937262 Print edition ISBN: 978-0-88385-180-7 Electronic edition ISBN: 978-0-88385-978-0 Printed in the United States of America Current Printing (last digit): 10 9 8 7 6 5 4 3 2 1 Current Practices in Quantitative Literacy edited by Rick Gillman Valparaiso University Published and Distributed by The Mathematical Association of America The MAA Notes Series, started in 1982, addresses a broad range of topics and themes of interest to all who are in- volved with undergraduate mathematics. The volumes in this series are readable, informative, and useful, and help the mathematical community keep up with developments of importance to mathematics. Council on Publications Roger Nelsen, Chair Notes Editorial Board Sr. Barbara E. Reynolds, Editor Stephen B Maurer, Editor-Elect Paul E. Fishback, Associate Editor Jack Bookman Annalisa Crannell Rosalie Dance William E. Fenton Michael K. May Mark Parker Susan F. Pustejovsky Sharon C. Ross David J. Sprows Andrius Tamulis MAA Notes 14. Mathematical Writing, by Donald E. Knuth, Tracy Larrabee, and Paul M. Roberts. 16. Using Writing to Teach Mathematics, Andrew Sterrett, Editor. 17. Priming the Calculus Pump: Innovations and Resources, Committee on Calculus Reform and the First Two Years, a subcomit- tee of the Committee on the Undergraduate Program in Mathematics, Thomas W. Tucker, Editor. 18. Models for Undergraduate Research in Mathematics, Lester Senechal, Editor. 19. Visualization in Teaching and Learning Mathematics, Committee on Computers in Mathematics Education, Steve Cunningham and Walter S. -

Measuring Variation for Nominal Data
Bulletin ofthe Psychonomic Society 1988. 26 (5), 433-436 Measuring variation for nominal data TARALD O. KVALSETH University of Minnesota , Minneapolis, Minnesota This paper is concerned with the measurement of variation or dispersion for nominal categori cal data. A new measure of such variation is proposed. It is defined as the complement of the standard deviation of the individual category frequencies from the modal frequency. Large-sample distribution methods are developed for constructing confidence intervals and testing hypotheses for the equivalent population measure of variation. Numerical sample data are used to exem plify the statistical inference methods. For measuring the variation or dispersion in a set of measures, the IQV in Equation 2 appears to be the most nominal data, a number ofalternative measures have been widely accepted, especially in the social sciences (e.g., defined in the literature. Such measures are generally Ott, Mendenhall, & Larson, 1978, pp. 110-113). The functions ofthe absolute frequencies or counts nh n2, . .. , measure in Equation 3, which is based on Shannon's n, for a set of I categories that are exhaustive and mutu (1948) entropy in information theory, has been used quite ally exclusive. Thus, among the total number ofn = Elnl extensively in the biological sciences (Pielou, 1977). observations (individuals or items), n, observations be The measure MOM in Equation 1 suffers from one seri long to category i, with each observation belonging to one ous limitation: its value is determined exclusively by the and only one category. Among the best known variation relative modal frequency nm/n and I (the number of measures for the n, (i = 1, 2, . -

KOF Working Papers, No
A Service of Leibniz-Informationszentrum econstor Wirtschaft Leibniz Information Centre Make Your Publications Visible. zbw for Economics Maag, Thomas Working Paper On the accuracy of the probability method for quantifying beliefs about inflation KOF Working Papers, No. 230 Provided in Cooperation with: KOF Swiss Economic Institute, ETH Zurich Suggested Citation: Maag, Thomas (2009) : On the accuracy of the probability method for quantifying beliefs about inflation, KOF Working Papers, No. 230, ETH Zurich, KOF Swiss Economic Institute, Zurich, http://dx.doi.org/10.3929/ethz-a-005859391 This Version is available at: http://hdl.handle.net/10419/50407 Standard-Nutzungsbedingungen: Terms of use: Die Dokumente auf EconStor dürfen zu eigenen wissenschaftlichen Documents in EconStor may be saved and copied for your Zwecken und zum Privatgebrauch gespeichert und kopiert werden. personal and scholarly purposes. Sie dürfen die Dokumente nicht für öffentliche oder kommerzielle You are not to copy documents for public or commercial Zwecke vervielfältigen, öffentlich ausstellen, öffentlich zugänglich purposes, to exhibit the documents publicly, to make them machen, vertreiben oder anderweitig nutzen. publicly available on the internet, or to distribute or otherwise use the documents in public. Sofern die Verfasser die Dokumente unter Open-Content-Lizenzen (insbesondere CC-Lizenzen) zur Verfügung gestellt haben sollten, If the documents have been made available under an Open gelten abweichend von diesen Nutzungsbedingungen die in der dort Content Licence (especially Creative Commons Licences), you genannten Lizenz gewährten Nutzungsrechte. may exercise further usage rights as specified in the indicated licence. www.econstor.eu KOF Working Papers On the Accuracy of the Probability Method for Quantifying Beliefs about Inflation Thomas Maag No. -

Media Diversity and the Analysis of Qualitative Variation
Media diversity and the analysis of qualitative variation David Deacon & James Stanyer CENTRE FOR RESEARCH IN COMMUNICATION AND CULTURE, LOUGHBOROUGH UNIVERSITY January 2019 1 Abstract Diversity is recognised as a significant criterion for appraising the democratic performance of media systems. This article begins by considering key conceptual debates that help differentiate types and levels of diversity. It then addresses one of the core methodological challenges in measuring diversity: how do we model statistical variation and difference when many measures of source and content diversity only attain the nominal level of measurement? We identify a range of obscure statistical indices developed in other fields that measure the strength of ‘qualitative variation’. Using original data, we compare the performance of five diversity indices and, on this basis, propose the creation of a more effective diversity average measure (DIVa). The article concludes by outlining innovative strategies for drawing statistical inferences from these measures, using bootstrapping and permutation testing resampling. All statistical procedures are supported by a unique online resource developed with this article. Key word: Media diversity, diversity indices, qualitative variation, categorical data Acknowledgements We wish to thank Orange Gao and Peter Dean of Business Intelligence and Strategy Ltd and Dr Adrian Leguina, School of Social Sciences, Loughborough University for their assistance in developing the conceptual and technical aspects of this paper. 2 Introduction Concerns about diversity are at the heart of discussions about the democratic performance of all media platforms (e.g. Entman, 1989: 64, 95; Habermas, 2006: 412, 416; Sunstein, 2018:85). With mainstream media, such debates are fundamentally about plurality, namely, the extent to which these powerful opinion leading organisations are able and/or inclined to engage with and represent the disparate communities, issues and interests that sculpt modern societies. -

Descriptive Statistics
IMGD 2905 Descriptive Statistics Chapter 3 Summarizing Data Q: how to summarize numbers? • With lots of playtesting, there is a lot of data (good!) • But raw data is often just a pile of numbers • Rarely of interest, or even sensible Summarizing Data Measures of central tendency Groupwork 4 3 7 8 3 4 22 3 5 3 2 3 • Indicate central tendency with one number? • What are pros and cons of each? Measure of Central Tendency: Mean • Aka: “arithmetic mean” or “average” =AVERAGE(range) =AVERAGEIF() – averages if numbers meet certain condition Measure of Central Tendency: Median • Sort values low to high and take middle value =MEDIAN(range) Measure of Central Tendency: Mode • Number which occurs most frequently • Not too useful in many cases Best use for categorical data • e.g., most popular Hero group in http://pad3.whstatic.com/images/thumb/c/cd/Find-the-Mode-of-a-Set-of-Numbers- Heroes of theStep-7.jpg/aid130521-v4-728px-Find-the-Mode-of-a-Set-of-Numbers-Step-7.jpg Storm =MODE() Mean, Median, Mode? frequency Mean, Median, Mode? frequency Mean, Median, Mode? frequency Mean, Median, Mode? frequency Mean, Median, Mode? frequency Mean, Median, Mode? mean median modes mode mean median frequency no mode mean (a) median (b) frequency mode mode median median (c) mean mean frequency frequency frequency (d) (e) Which to Use: Mean, Median, Mode? Which to Use: Mean, Median, Mode? • Mean many statistical tests that use sample ‒ Estimator of population mean ‒ Uses all data Which to Use: Mean, Median, Mode? • Median is useful for skewed data ‒ e.g., income data (US Census) or housing prices (Zillo) ‒ e.g., Overwatch team (6 players): 5 people level 5, 1 person level 275 ₊ Mean is 50 - not so useful since no one at this level ₊ Median is 5 – perhaps more representative ‒ Does not use all data. -
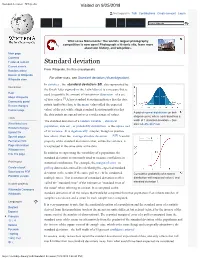
Standard Deviation - Wikipedia Visited on 9/25/2018
Standard deviation - Wikipedia Visited on 9/25/2018 Not logged in Talk Contributions Create account Log in Article Talk Read Edit View history Wiki Loves Monuments: The world's largest photography competition is now open! Photograph a historic site, learn more about our history, and win prizes. Main page Contents Featured content Standard deviation Current events Random article From Wikipedia, the free encyclopedia Donate to Wikipedia For other uses, see Standard deviation (disambiguation). Wikipedia store In statistics , the standard deviation (SD, also represented by Interaction the Greek letter sigma σ or the Latin letter s) is a measure that is Help used to quantify the amount of variation or dispersion of a set About Wikipedia of data values.[1] A low standard deviation indicates that the data Community portal Recent changes points tend to be close to the mean (also called the expected Contact page value) of the set, while a high standard deviation indicates that A plot of normal distribution (or bell- the data points are spread out over a wider range of values. shaped curve) where each band has a Tools The standard deviation of a random variable , statistical width of 1 standard deviation – See What links here also: 68–95–99.7 rule population, data set , or probability distribution is the square root Related changes Upload file of its variance . It is algebraically simpler, though in practice [2][3] Special pages less robust , than the average absolute deviation . A useful Permanent link property of the standard deviation is that, unlike the variance, it Page information is expressed in the same units as the data. -

TRACE: Tennessee Research and Creative Exchange
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Doctoral Dissertations Graduate School 12-2016 On the quantification of complexity and diversity from phenotypes to ecosystems Zachary Harrison Marion University of Tennessee, Knoxville, [email protected] Follow this and additional works at: https://trace.tennessee.edu/utk_graddiss Part of the Biostatistics Commons, and the Other Ecology and Evolutionary Biology Commons Recommended Citation Marion, Zachary Harrison, "On the quantification of complexity and diversity from phenotypes to ecosystems. " PhD diss., University of Tennessee, 2016. https://trace.tennessee.edu/utk_graddiss/4104 This Dissertation is brought to you for free and open access by the Graduate School at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Doctoral Dissertations by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. To the Graduate Council: I am submitting herewith a dissertation written by Zachary Harrison Marion entitled "On the quantification of complexity and diversity from phenotypes to ecosystems." I have examined the final electronic copy of this dissertation for form and content and recommend that it be accepted in partial fulfillment of the equirr ements for the degree of Doctor of Philosophy, with a major in Ecology and Evolutionary Biology. Benjamin M. Fitzpatrick, Major Professor We have read this dissertation and recommend its acceptance: James A. Fordyce, Nathan J. Sanders, Shawn R. Campagna Accepted for the Council: Carolyn R. Hodges Vice Provost and Dean of the Graduate School (Original signatures are on file with official studentecor r ds.) On the quantification of complexity and diversity from phenotypes to ecosystems A Dissertation Presented for the Doctor of Philosophy Degree The University of Tennessee, Knoxville Zachary Harrison Marion December 2016 c by Zachary Harrison Marion, 2016 All Rights Reserved. -

Population Dispersion
AccessScience from McGraw-Hill Education Page 1 of 7 www.accessscience.com Population dispersion Contributed by: Francis C. Evans Publication year: 2014 The spatial distribution at any particular moment of the individuals of a species of plant or animal. Under natural conditions organisms are distributed either by active movements, or migrations, or by passive transport by wind, water, or other organisms. The act or process of dissemination is usually termed dispersal, while the resulting pattern of distribution is best referred to as dispersion. Dispersion is a basic characteristic of populations, controlling various features of their structure and organization. It determines population density, that is, the number of individuals per unit of area, or volume, and its reciprocal relationship, mean area, or the average area per individual. It also determines the frequency, or chance of encountering one or more individuals of the population in a particular sample unit of area, or volume. The ecologist therefore studies not only the fluctuations in numbers of individuals in a population but also the changes in their distribution in space. See also: POPULATION DISPERSAL. Principal types of dispersion The dispersion pattern of individuals in a population may conform to any one of several broad types, such as random, uniform, or contagious (clumped). Any pattern is relative to the space being examined; a population may appear clumped when a large area is considered, but may prove to be distributed at random with respect to a much smaller area. Random or haphazard. This implies that the individuals have been distributed by chance. In such a distribution, the probability of finding an individual at any point in the area is the same for all points (Fig. -

Summarizing Measured Data
SummarizingSummarizing MeasuredMeasured DataData Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 [email protected] These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/ Washington University in St. Louis CSE567M ©2008 Raj Jain 12-1 OverviewOverview ! Basic Probability and Statistics Concepts: CDF, PDF, PMF, Mean, Variance, CoV, Normal Distribution ! Summarizing Data by a Single Number: Mean, Median, and Mode, Arithmetic, Geometric, Harmonic Means ! Mean of A Ratio ! Summarizing Variability: Range, Variance, percentiles, Quartiles ! Determining Distribution of Data: Quantile-Quantile plots Washington University in St. Louis CSE567M ©2008 Raj Jain 12-2 PartPart III:III: ProbabilityProbability TheoryTheory andand StatisticsStatistics 1. How to report the performance as a single number? Is specifying the mean the correct way? 2. How to report the variability of measured quantities? What are the alternatives to variance and when are they appropriate? 3. How to interpret the variability? How much confidence can you put on data with a large variability? 4. How many measurements are required to get a desired level of statistical confidence? 5. How to summarize the results of several different workloads on a single computer system? 6. How to compare two or more computer systems using several different workloads? Is comparing the mean sufficient? 7. What model best describes the relationship between two variables? Also, how good is the model? Washington University in St. Louis CSE567M ©2008 Raj Jain 12-3 BasicBasic ProbabilityProbability andand StatisticsStatistics ConceptsConcepts ! Independent Events: Two events are called independent if the occurrence of one event does not in any way affect the probability of the other event. -

Measures of Dispersion and Serial Dependence in Categorical Time Series
econometrics Article Measures of Dispersion and Serial Dependence in Categorical Time Series Christian H. Weiß Department of Mathematics and Statistics, Helmut Schmidt University, 22043 Hamburg, Germany; [email protected] Received: 21 December 2018; Accepted: 17 April 2019; Published: 22 April 2019 Abstract: The analysis and modeling of categorical time series requires quantifying the extent of dispersion and serial dependence. The dispersion of categorical data is commonly measured by Gini index or entropy, but also the recently proposed extropy measure can be used for this purpose. Regarding signed serial dependence in categorical time series, we consider three types of k-measures. By analyzing bias properties, it is shown that always one of the k-measures is related to one of the above-mentioned dispersion measures. For doing statistical inference based on the sample versions of these dispersion and dependence measures, knowledge on their distribution is required. Therefore, we study the asymptotic distributions and bias corrections of the considered dispersion and dependence measures, and we investigate the finite-sample performance of the resulting asymptotic approximations with simulations. The application of the measures is illustrated with real-data examples from politics, economics and biology. Keywords: Cohen’s k; extropy; nominal variation; signed serial dependence; asymptotic distribution 1. Introduction In many applications, the available data are not of quantitative nature (e.g., real numbers or counts) but consist of observations from a given finite set of categories. In the present article, we are concerned with data about political goals in Germany, fear states in the stock market, and phrases in a bird’s song.