Conservation Cores: Reducing the Energy of Mature Computations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nvidia® Gelato™ 1.0 Hardware
NVIDIA GELATO PRODUCT OVERVIEW APRIL04v01 NVIDIA® GELATO™ 1.0 HARDWARE- Key to this doctrine of no compromises is Gelato’s new shading language incorporates a ACCELERATED FINAL-FRAME RENDERER Gelato’s use of NVIDIA graphics hardware. simple and streamlined syntax based on C, Gelato is breakthrough, rendering software Gelato uses the NVIDIA Quadro FX as a second making it familiar and easy for most from NVIDIA, designed with a new architecture floating-point processor, taking advantage of programmers to learn and allowing for state- that leverages advances in mainstream graphics the 3D engine in ways far beyond gameplay. of-the-art shader-specific types and hardware to accelerate film-quality rendering. Gelato is one of the first in a wave of software functions. Gelato ships with an extensive This software renderer takes advantage of the applications that use the graphics hardware as set of shader libraries and examples. programmability, precision, performance, and an off-line processor, a “floating-point Gelato is available with a world-class quality of NVIDIA Quadro® FX professional supercomputer on a chip,” and not simply to support package, backed by NVIDIA, graphics solutions to render imagery of manage the display. the global leader in 3D graphics. uncompromising quality at unheard-of speeds. FAST AND GETTING FASTER The annual support package includes Gelato offers all the features film and television all product updates and upgrades. customers demand today and is flexible and Gelato unleashes the processing power of the extensible enough to satisfy their future graphics hardware that currently sits idle on LOOKING TO THE FUTURE requirements. -

FCM 61 Italiano
Full Circle LA RIVISTA INDIPENDENTE PER LA COMUNITÀ LINUX UBUNTU Numero #61 - Maggio 2012 AUDIO FLUX NUOVA SEZIONE MUSICA GRATIS IN CC foto: downhilldom1984 (Flickr.com) CCOOPPIIAA EE CCOODDIIFFIICCAA DDII DDVVDD QQUUAATTTTRROO SSIISSTTEEMMII CCRROONNOOMMEETTRRAATTII EE PPRROOVVAATTII full circle magazine n.61 1 Full Circle magazine non è affiliata né sostenuta da Canonical Ltd. indice ^ HowTo Full Circle Opinioni LA RIVISTA INDIPENDENTE PER LA COMUNITÀ LINUX UBUNTU Python-Parte33 p.07 Rubriche LaMiaStoria p.38 UsareilcomandoTOP p.10 NotizieLinux p.04 AudioFlux p.52 LaMiaOpinione p.42 VirtualBoxNetworking p.15 Comanda&Conquista p.05 GiochiUbuntu p.53 IoPensoChe... p.43 GIMP-BeanstalkParte 2 p.21 LinuxLabs p.29 D&R p.50 RecensioneLibro p.45 Torna Prossimo Mese Inkscape-Parte1 p.24 DonneUbuntu p.XX Chiuderele«Finestre» p.32 Lettere p.46 Grafica Gli articoli contenuti in questa rivista sono stati rilasciati sotto la licenza Creative Commons Attribuzione - Non commerciale - Condividi allo stesso modo 3.0. Ciò significa che potete adattare, copiare, distribuire e inviare gli articoli ma solo sotto le seguenti condizioni: dovete attribuire il lavoro all'autore originale in una qualche forma (almeno un nome, un'email o un indirizzo Internet) e a questa rivista col suo nome ("Full Circle Magazine") e con il suo indirizzo Internet www.fullcirclemagazine.org (ma non attribuire il/gli articolo/i in alcun modo che lasci intendere che gli autori e la rivista abbiano esplicitamente autorizzato voi o l'uso che fate dell'opera). Se alterate, trasformate o create un'opera su questo lavoro dovete distribuire il lavoro risultante con la stessa licenza o una simile o compatibile. -

The Utilization Wall
UC San Diego UC San Diego Electronic Theses and Dissertations Title Configurable energy-efficient co-processors to scale the utilization wall Permalink https://escholarship.org/uc/item/3g99v4qd Author Venkatesh, Ganesh Publication Date 2011 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA, SAN DIEGO Configurable Energy-efficient Co-processors to Scale the Utilization Wall A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Computer Science by Ganesh Venkatesh Committee in charge: Professor Steven Swanson, Co-Chair Professor Michael Taylor, Co-Chair Professor Pamela Cosman Professor Rajesh Gupta Professor Dean Tullsen 2011 Copyright Ganesh Venkatesh, 2011 All rights reserved. The dissertation of Ganesh Venkatesh is approved, and it is acceptable in quality and form for publication on microfilm and electronically: Co-Chair Co-Chair University of California, San Diego 2011 iii DEDICATION To my dear parents and my loving wife. iv EPIGRAPH The lurking suspicion that something could be simplified is the world's richest source of rewarding challenges. |Edsger Dijkstra v TABLE OF CONTENTS Signature Page.................................. iii Dedication..................................... iv Epigraph.....................................v Table of Contents................................. vi List of Figures.................................. ix List of Tables................................... xi Acknowledgements............................... -

3D Computer Graphics Compiled By: H
animation Charge-coupled device Charts on SO(3) chemistry chirality chromatic aberration chrominance Cinema 4D cinematography CinePaint Circle circumference ClanLib Class of the Titans clean room design Clifford algebra Clip Mapping Clipping (computer graphics) Clipping_(computer_graphics) Cocoa (API) CODE V collinear collision detection color color buffer comic book Comm. ACM Command & Conquer: Tiberian series Commutative operation Compact disc Comparison of Direct3D and OpenGL compiler Compiz complement (set theory) complex analysis complex number complex polygon Component Object Model composite pattern compositing Compression artifacts computationReverse computational Catmull-Clark fluid dynamics computational geometry subdivision Computational_geometry computed surface axial tomography Cel-shaded Computed tomography computer animation Computer Aided Design computerCg andprogramming video games Computer animation computer cluster computer display computer file computer game computer games computer generated image computer graphics Computer hardware Computer History Museum Computer keyboard Computer mouse computer program Computer programming computer science computer software computer storage Computer-aided design Computer-aided design#Capabilities computer-aided manufacturing computer-generated imagery concave cone (solid)language Cone tracing Conjugacy_class#Conjugacy_as_group_action Clipmap COLLADA consortium constraints Comparison Constructive solid geometry of continuous Direct3D function contrast ratioand conversion OpenGL between -

VMD User's Guide
VMD User’s Guide Version 1.9.4a48 October 13, 2020 NIH Biomedical Research Center for Macromolecular Modeling and Bioinformatics Theoretical and Computational Biophysics Group1 Beckman Institute for Advanced Science and Technology University of Illinois at Urbana-Champaign 405 N. Mathews Urbana, IL 61801 http://www.ks.uiuc.edu/Research/vmd/ Description The VMD User’s Guide describes how to run and use the molecular visualization and analysis program VMD. This guide documents the user interfaces displaying and grapically manipulating molecules, and describes how to use the scripting interfaces for analysis and to customize the behavior of VMD. VMD development is supported by the National Institutes of Health grant numbers NIH P41- GM104601. 1http://www.ks.uiuc.edu/ Contents 1 Introduction 11 1.1 Contactingtheauthors. ....... 12 1.2 RegisteringVMD.................................. 12 1.3 CitationReference ............................... ...... 12 1.4 Acknowledgments................................. ..... 13 1.5 Copyright and Disclaimer Notices . .......... 13 1.6 For information on our other software . .......... 15 2 Hardware and Software Requirements 17 2.1 Basic Hardware and Software Requirements . ........... 17 2.2 Multi-core CPUs and GPU Acceleration . ......... 17 2.3 Parallel Computing on Clusters and Supercomputers . .............. 18 3 Tutorials 19 3.1 RapidIntroductiontoVMD. ...... 19 3.2 Viewing a molecule: Myoglobin . ........ 19 3.3 RenderinganImage ................................ 21 3.4 AQuickAnimation................................. 21 3.5 An Introduction to Atom Selection . ......... 22 3.6 ComparingTwoStructures . ...... 22 3.7 SomeNiceRepresenations . ....... 23 3.8 Savingyourwork.................................. 24 3.9 Tracking Script Command Versions of the GUI Actions . ............ 24 4 Loading A Molecule 26 4.1 Notes on common molecular file formats . ......... 26 4.2 Whathappenswhenafileisloaded? . ....... 27 4.3 Babelinterface ................................. -

C 2009 Aqeel A. Mahesri TRADEOFFS in DESIGNING MASSIVELY PARALLEL ACCELERATOR ARCHITECTURES
c 2009 Aqeel A. Mahesri TRADEOFFS IN DESIGNING MASSIVELY PARALLEL ACCELERATOR ARCHITECTURES BY AQEEL A. MAHESRI B.S., University of California at Berkeley, 2002 M.S., University of Illinois at Urbana-Champaign, 2004 DISSERTATION Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Science in the Graduate College of the University of Illinois at Urbana-Champaign, 2009 Urbana, Illinois Doctoral Committee: Associate Professor Sanjay J. Patel, Chair Professor Josep Torrellas Professor Wen-Mei Hwu Assistant Professor Craig Zilles ABSTRACT There is a large, emerging, and commercially relevant class of applications which stands to be enabled by a significant increase in parallel computing throughput. Moreover, continued scaling of semiconductor technology allows us the creation of architectures with tremendous throughput on a single chip. In this thesis, we examine the confluence of these emerging single-chip accelerators and the appli- cations they enable. We examine the tradeoffs associated with accelerator archi- tectures, working our way down the abstraction hierarchy of computing starting at the application level and concluding with the physical design of the circuits. Research into accelerator architectures is hampered by the lack of standard- ized, readily available benchmarks. Among these applications is what we refer to as visualization, interaction, and simulation (VIS). These applications are ide- ally suited for accelerators because of their parallelizability and demand for high throughput. We present VISBench, a benchmark suite to serve as an experimen- tal proxy for for VIS applications. VISBench contains a sampling of applications and application kernels from traditional visual computing areas such as graphics rendering and video encoding. -

Enabling Compute-Communication Overlap in Distributed Deep
Enabling Compute-Communication Overlap in Distributed Deep Learning Training Platforms Saeed Rashidi∗, Matthew Denton∗, Srinivas Sridharan†, Sudarshan Srinivasan‡, Amoghavarsha Suresh§, Jade Nie†, and Tushar Krishna∗ ∗Georgia Institute of Technology, Atlanta, USA †Facebook, Menlo Park, USA ‡Intel, Bangalore, India §Stony Brook University, Stony Brook, USA [email protected], [email protected], [email protected], [email protected] Abstract—Deep Learning (DL) training platforms are built From other server nodes by interconnecting multiple DL accelerators (e.g., GPU/TPU) Datacenter Network 1) Mellanox 2) Barefoot via fast, customized interconnects with 100s of gigabytes (GBs) 3) Inception of bandwidth. However, as we identify in this work, driving CPU CPU 4) sPIN this bandwidth is quite challenging. This is because there is a 5) Triggered- pernicious balance between using the accelerator’s compute and Based memory for both DL computations and communication. PCIe PCIe PCIe PCIe This work makes two key contributions. First, via real system Switch Switch Switch Switch measurements and detailed modeling, we provide an under- A 7) ACE A A standing of compute and memory bandwidth demands for DL NPU 0 F NPU 1 AFI F NPU 4 F NPU 5 I I I compute and comms. Second, we propose a novel DL collective ACE Accelerator communication accelerator called Accelerator Collectives Engine Fabric (AF) (ACE) that sits alongside the compute and networking engines at A A A A NPU 2 F NPU 3 F F NPU 6 F NPU 7 the accelerator endpoint. ACE frees up the endpoint’s compute I I 6) NVIDIA I I Switch-Based and memory resources for DL compute, which in turn reduces Datacenter AFI network PCIe link NIC the required memory BW by 3.5× on average to drive the same network link link network BW compared to state-of-the-art baselines. -
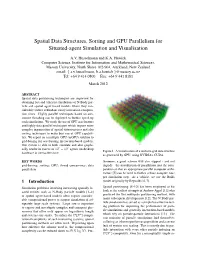
Spatial Data Structures, Sorting and GPU Parallelism for Situated-Agent Simulation and Visualisation
Spatial Data Structures, Sorting and GPU Parallelism for Situated-agent Simulation and Visualisation A.V. Husselmann and K.A. Hawick Computer Science, Institute for Information and Mathematical Sciences, Massey University, North Shore 102-904, Auckland, New Zealand email: f a.v.husselmann, k.a.hawick [email protected] Tel: +64 9 414 0800 Fax: +64 9 441 8181 March 2012 ABSTRACT Spatial data partitioning techniques are important for obtaining fast and efficient simulations of N-Body par- ticle and spatial agent based models where they con- siderably reduce redundant entity interaction computa- tion times. Highly parallel techniques based on con- current threading can be deployed to further speed up such simulations. We study the use of GPU accelerators and highly data parallel techniques which require more complex organisation of spatial datastructures and also sorting techniques to make best use of GPU capabili- ties. We report on a multiple-GPU (mGPU) solution to grid-boxing for accelerating interaction-based models. Our system is able to both simulate and also graphi- cally render in excess of 105 − 106 agents on desktop Figure 1: A visualisation of a uniform grid datastructure hardware in interactive-time. as generated by GPU, using NVIDIA’s CUDA. KEY WORDS thermore, a good scheme will also support - and not grid-boxing; sorting; GPU; thread concurrency; data impede - the introduction of parallelism into the com- parallelism putation so that an appropriate parallel computer archi- tecture [5] can be used to further reduce compute time per simulation step. As a vehicle, we use the Boids 1 Introduction model originally by Reynolds [6, 7]. -

July/August 2021
July/August 2021 A Straight Path to the FreeBSD Desktop Human Interface Device (HID) Support in FreeBSD 13 The Panfrost Driver Updating FreeBSD from Git ® J O U R N A L LETTER E d i t o r i a l B o a r d from the Foundation John Baldwin FreeBSD Developer and Chair of ne of the myths surrounding FreeBSD is that it • FreeBSD Journal Editorial Board. is only useful in server environments or as the Justin Gibbs Founder of the FreeBSD Foundation, • President of the FreeBSD Foundation, foundation for appliances. The truth is FreeBSD and a Software Engineer at Facebook. O is also a desktop operating system. FreeBSD’s base sys- Daichi Goto Director at BSD Consulting Inc. tem and packages include device drivers for modern • (Tokyo). graphics adapters and input devices. Consistent with Tom Jones FreeBSD Developer, Internet Engineer FreeBSD’s role as a toolkit, FreeBSD supports a variety • and Researcher at the University of Aberdeen. of graphical interfaces ranging from minimalist window managers to full-featured desktop environments. The Dru Lavigne Author of BSD Hacks and • The Best of FreeBSD Basics. first article in this issue walks through several of these Michael W Lucas Author of more than 40 books including options explaining how users can tailor their desktop • Absolute FreeBSD, the FreeBSD to their needs. It also provides pointers to downstream Mastery series, and git commit murder. projects which build an integrated desktop system on Ed Maste Senior Director of Technology, top of FreeBSD. The next two articles dig into the details • FreeBSD Foundation and Member of the FreeBSD Core Team. -

Graphics Hardware
Department of Computer Engineering Graphics Hardware Ulf Assarsson Graphics hardware – why? l About 100x faster! l Another reason: about 100x faster! l Simple to pipeline and parallelize l Current hardware based on triangle rasterization with programmable shading (e.g., OpenGL acceleration) l Ray tracing: there are research architetures, and few commercial products – Renderdrive, RPU, (Gelato), NVIDIA OptiX – Or write your own GPU ray-tracer 2 3 Perspective-correct texturing l How is texture coordinates interpolated over a triangle? l Linearly? Linear interpolation Perspective-correct interpolation l Perspective-correct interpolation gives foreshortening effect! l Hardware does this for you, but you need to understand this anyway! 4 5 Recall the following l Before projection, v, and after p (p=Mv) l After projection pw is not 1! l Homogenization: (px /pw , py /pw , pz /pw , 1) l Gives (px´, py ´ , pz´ , 1) " v % " v % " 1 0 0 0 % x x $ '$ ' $ ' 0 1 0 0 $ vy ' $ vy ' p = Mv = $ ' = $ ' $ '$ ' 0 0 1 0 v $ vz ' $ '$ z ' # 0 0 −1/ d 0 &$ ' $ ' # 1 & −vz / d 6 # & Texture coordinate interpolation l Linear interpolation does not work l Rational linear interpolation does: – u(x)=(ax+b) / (cx+d) (along a scanline where y=constant) – a,b,c,d are computed from triangle’s vertices (x,y,z,w,u,v) l Not really efficient to compute a,b,c,d per scan line l Smarter: – Compute (u/w,v/w,1/w) per vertex – These quantities can be linearly interpolated! – Then at each pixel, compute 1/(1/w)=w – And obtain: (w*u/w,w*v/w)=(u,v) – The (u,v) are perspectively-correct interpolated l Need to interpolate shading this way too – Though, not as annoying as textures l Since linear interpolation now is OK, compute, e.g., Δ(u/w)/ Δx, and use this to update u/w when stepping in the x- direction (similarly for other parameters) 7 Put differently: l Linear interpolation in screen space does not work for u,v l Solution: – We have applied a non-linear transform to each vertex (x/w, y/w, z/w). -

Gelato Pro 2.0 and Gelato 2.0 Gpu-Accelerated Final-Frame Renderer
GELATO PRO 2.0 AND GELATO 2.0 GPU-ACCELERATED FINAL-FRAME RENDERER NVIDIA Sorbetto™ is a feature set Speed Without Gelato / Gelato Pro Sacrificing Quality that allows you to change any lighting parameter you wish and re-render the Selected Feature Comparison NVIDIA® Gelato® is built on the principle frame in record time. Best of all, Sorbetto Gelato of never compromising on the quality of performs this relighting on the final pixels. Features Gelato Pro the rendered image. Gelato uses NVIDIA The image you work with in Sorbetto is GPU acceleration graphics processing units (GPUs) as always identical to the final rendered image a general purpose GPU and not just and you do not need to alter or specially Highest quality images as a way to fill pixels on the display. It prepare your scene to use Sorbetto. renders images quickly and is robust Raytracing, incl. global Sorbetto uses the same geometry, and powerful enough to render the most illumination and ambient shaders, procedurals, and hardware complex scenes while avoiding the quality occlusion as a regular Gelato render. Sorbetto limitations of hardware-generated images. functionality is exposed in the Maya plug- High-order geometry support Gelato seamlessly leverages the advances in (and soon in the 3ds Max plug-in) and found in the latest GPU hardware while in the C++ API, so it can be used with any Fully programmable shading protecting your investment in production existing lighting tool in your pipeline. Sorbetto interactive tools and digital assets by insulating them Best of all, Gelato Pro is backed by the relighting from hardware changes. -

Size Oblivious Programming with Infinimem
Size Oblivious Programming with InfiniMem ? Sai Charan Koduru, Rajiv Gupta, Iulian Neamtiu Department of Computer Science and Engineering University of California, Riverside {scharan,gupta,neamtiu}@cs.ucr.edu Abstract. Many recently proposed BigData processing frameworks make programming easier, but typically expect the datasets to fit in the mem- ory of either a single multicore machine or a cluster of multicore ma- chines. When this assumption does not hold, these frameworks fail. We introduce the InfiniMem framework that enables size oblivious processing of large collections of objects that do not fit in memory by making them disk-resident. InfiniMem is easy to program with: the user just indicates the large collections of objects that are to be made disk-resident, while InfiniMem transparently handles their I/O management. The InfiniMem library can manage a very large number of objects in a uniform manner, even though the objects have different characteristics and relationships which, when processed, give rise to a wide range of access patterns re- quiring different organizations of data on the disk. We demonstrate the ease of programming and versatility of InfiniMem with 3 different prob- abilistic analytics algorithms, 3 different graph processing size oblivious frameworks; they require minimal effort, 6{9 additional lines of code. We show that InfiniMem can successfully generate a mesh with 7.5 mil- lion nodes and 300 million edges (4.5 GB on disk) in 40 minutes and it performs the PageRank computation on a 14GB graph with 134 million vertices and 805 million edges at 14 minutes per iteration on an 8-core machine with 8 GB RAM.