Size Oblivious Programming with Infinimem
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Oracle Database User's Guide for Fujitsu Siemens BS2000/OSD
Oracle® Database User's Guide 10g Release 2 (10.2) for Fujitsu Siemens BS2000/OSD E10320-01 August 2007 Oracle Database User's Guide, 10g Release 2 (10.2) for Fujitsu Siemens BS2000/OSD E10320-01 Copyright © 2007, Oracle. All rights reserved. Primary Author: Brintha Bennet Contributing Author: Janelle Simmons The Programs (which include both the software and documentation) contain proprietary information; they are provided under a license agreement containing restrictions on use and disclosure and are also protected by copyright, patent, and other intellectual and industrial property laws. Reverse engineering, disassembly, or decompilation of the Programs, except to the extent required to obtain interoperability with other independently created software or as specified by law, is prohibited. The information contained in this document is subject to change without notice. If you find any problems in the documentation, please report them to us in writing. This document is not warranted to be error-free. Except as may be expressly permitted in your license agreement for these Programs, no part of these Programs may be reproduced or transmitted in any form or by any means, electronic or mechanical, for any purpose. If the Programs are delivered to the United States Government or anyone licensing or using the Programs on behalf of the United States Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the Programs, including documentation and technical data, shall be subject to the licensing restrictions set forth in the applicable Oracle license agreement, and, to the extent applicable, the additional rights set forth in FAR 52.227-19, Commercial Computer Software--Restricted Rights (June 1987). -
BS2000/OSD-BC ≥ V4.0, OSD-SVP V4.0 and OSD/XC V1.0 with SPOOL ≥ V4.4A – Openft for BS2000 As of V7.0 Und Openft-AC for BS2000 As of V7.0
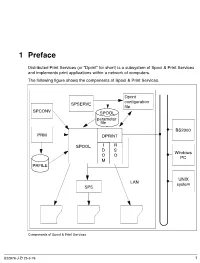
1Preface Distributed Print Services (or “Dprint” for short) is a subsystem of Spool & Print Services and implements print applications within a network of computers. The following figure shows the components of Spool & Print Services. Dprint configuration SPSERVE file SPCONV SPOOL parameter file BS2000 PRM DPRINT SPOOL I R D S Windows O O PC M PRFILE UNIX LAN system SPS Components of Spool & Print Services U22878-J-Z125-6-76 1 Brief product description Preface 1.1 Brief product description Distributed Print Services (known as “Dprint” for short) implements print applications in a network consisting of computers which use the BS20000/OSD, UNIX and Windows operating systems. Dprint utilizes TCP/IP, ISO or NEA (TRANSDATA) transport protocols. Dprint requires SPOOL as its execution unit and expands the print capabilities of SPOOL in respect of host-wide and network-wide utilization of the local BS2000 high-performance printers. Dprint supports network-wide access to BS2000 printers, printers attached to UNIX systems and Windows printers, i.e. interoperability between BS2000, Xprint and Wprint is possible. This means that data from a Windows PC can be output to a BS2000 printer. It is also possible to output data from BS2000 on a printer which is connected to a Windows PC. This then runs via a UNIX system. Dprint is designed as a client/server model and comprises the following components: – DPRINTCL (client component: print job generation) – DPRINTSV (server component: print job management) – DPRINTCM (implements management services, file transfer, communication, etc.) These components are installed as independent subsystems. DPRINTCL and DPRINTCM are combined to form the selectable unit DPRINT-CL, and DPRINTSV is supplied as the selectable unit DPRINT-SV. -

NUMA-Aware Thread Migration for High Performance NVMM File Systems
NUMA-Aware Thread Migration for High Performance NVMM File Systems Ying Wang, Dejun Jiang and Jin Xiong SKL Computer Architecture, ICT, CAS; University of Chinese Academy of Sciences fwangying01, jiangdejun, [email protected] Abstract—Emerging Non-Volatile Main Memories (NVMMs) out considering the NVMM usage on NUMA nodes. Besides, provide persistent storage and can be directly attached to the application threads accessing file system rely on the default memory bus, which allows building file systems on non-volatile operating system thread scheduler, which migrates thread only main memory (NVMM file systems). Since file systems are built on memory, NUMA architecture has a large impact on their considering CPU utilization. These bring remote memory performance due to the presence of remote memory access and access and resource contentions to application threads when imbalanced resource usage. Existing works migrate thread and reading and writing files, and thus reduce the performance thread data on DRAM to solve these problems. Unlike DRAM, of NVMM file systems. We observe that when performing NVMM introduces extra latency and lifetime limitations. This file reads/writes from 4 KB to 256 KB on a NVMM file results in expensive data migration for NVMM file systems on NUMA architecture. In this paper, we argue that NUMA- system (NOVA [47] on NVMM), the average latency of aware thread migration without migrating data is desirable accessing remote node increases by 65.5 % compared to for NVMM file systems. We propose NThread, a NUMA-aware accessing local node. The average bandwidth is reduced by thread migration module for NVMM file system. -
Openscad User Manual (PDF)
OpenSCAD User Manual Contents 1 Introduction 1.1 Additional Resources 1.2 History 2 The OpenSCAD User Manual 3 The OpenSCAD Language Reference 4 Work in progress 5 Contents 6 Chapter 1 -- First Steps 6.1 Compiling and rendering our first model 6.2 See also 6.3 See also 6.3.1 There is no semicolon following the translate command 6.3.2 See Also 6.3.3 See Also 6.4 CGAL surfaces 6.5 CGAL grid only 6.6 The OpenCSG view 6.7 The Thrown Together View 6.8 See also 6.9 References 7 Chapter 2 -- The OpenSCAD User Interface 7.1 User Interface 7.1.1 Viewing area 7.1.2 Console window 7.1.3 Text editor 7.2 Interactive modification of the numerical value 7.3 View navigation 7.4 View setup 7.4.1 Render modes 7.4.1.1 OpenCSG (F9) 7.4.1.1.1 Implementation Details 7.4.1.2 CGAL (Surfaces and Grid, F10 and F11) 7.4.1.2.1 Implementation Details 7.4.2 View options 7.4.2.1 Show Edges (Ctrl+1) 7.4.2.2 Show Axes (Ctrl+2) 7.4.2.3 Show Crosshairs (Ctrl+3) 7.4.3 Animation 7.4.4 View alignment 7.5 Dodecahedron 7.6 Icosahedron 7.7 Half-pyramid 7.8 Bounding Box 7.9 Linear Extrude extended use examples 7.9.1 Linear Extrude with Scale as an interpolated function 7.9.2 Linear Extrude with Twist as an interpolated function 7.9.3 Linear Extrude with Twist and Scale as interpolated functions 7.10 Rocket 7.11 Horns 7.12 Strandbeest 7.13 Previous 7.14 Next 7.14.1 Command line usage 7.14.2 Export options 7.14.2.1 Camera and image output 7.14.3 Constants 7.14.4 Command to build required files 7.14.5 Processing all .scad files in a folder 7.14.6 Makefile example 7.14.6.1 Automatic -

Conservation Cores: Reducing the Energy of Mature Computations
Conservation Cores: Reducing the Energy of Mature Computations Ganesh Venkatesh Jack Sampson Nathan Goulding Saturnino Garcia Vladyslav Bryksin Jose Lugo-Martinez Steven Swanson Michael Bedford Taylor Department of Computer Science & Engineering University of California, San Diego fgvenkatesh,jsampson,ngouldin,sat,vbryksin,jlugomar,swanson,[email protected] Abstract power. Consequently, the rate at which we can switch transistors Growing transistor counts, limited power budgets, and the break- is far outpacing our ability to dissipate the heat created by those down of voltage scaling are currently conspiring to create a utiliza- transistors. tion wall that limits the fraction of a chip that can run at full speed The result is a technology-imposed utilization wall that limits at one time. In this regime, specialized, energy-efficient processors the fraction of the chip we can use at full speed at one time. Our experiments with a 45 nm TSMC process show that we can can increase parallelism by reducing the per-computation power re- 2 quirements and allowing more computations to execute under the switch less than 7% of a 300mm die at full frequency within an same power budget. To pursue this goal, this paper introduces con- 80W power budget. ITRS roadmap projections and CMOS scaling servation cores. Conservation cores, or c-cores, are specialized pro- theory suggests that this percentage will decrease to less than 3.5% cessors that focus on reducing energy and energy-delay instead of in 32 nm, and will continue to decrease by almost half with each increasing performance. This focus on energy makes c-cores an ex- process generation—and even further with 3-D integration. -

Geometry & Computation for Interactive Simulation
Geometry & Computation for Interactive Simulation Jorg Peters (CISE University of Florida, USA), Dinesh Pai (University of British Columbia), Ulrich Reif (Technische Universitaet Darmstadt) Sep 24 – Sep 29, 2017 1 Overview The workshop advanced the state of the art in geometry and computation for interactive simulation by in- troducing to each other researchers from different branches of academia, research labs and industry. These researchers share the common goal of improving the interface between geometry and computation for physi- cal simulation – but approach it with differing emphasis, techniques and toolkits. A key issue for all partici- pants is to shorten process times and to improve the outcomes of the design-analysis cycle. That is, to more quickly optimize shape, structure and properties to achieve one or multiple design goals. Correspondingly, the challenges laid out covered a wide spectrum from hierarchical design and prediction of novel 3D printed materials, to multi-objective optimization minimizing fuel consumption of commercial airplanes, to creating training scenarios for minimally invasive surgery, to multi-point interactive force feedback for virtually plac- ing an engine into a restricted cavity. These challenges map to challenges in the underlying areas of geometry processing, computational geometry, geometric design, formulation of simulation models, isogeometric and higher-order isoparametric design with splines and meshingless approaches, to real-time computation for interactive surgical force-feedback simulation. The workshop was highly succesful in presenting and con- trasting this rich set of techniques. And it generated recommendations for educating future generation of researchers in geometry and computation for interactive simulation (see outcomes). The lower than usual number of participants (due to a second series of earth quakes just before the meeting) allowed for increased length of individual presentations, so as to discuss topics and ideas at length, and to address basics theory. -

Přehled Serverových Řešení Fujitsu
Fujitsu – nejen DC HW ORTEX - WS 25.10.2018 [email protected] 0 © 2018 FUJITSU Fujitsu DC portfolio ETERNUS storage PRIMERGY servery včetně SW partnerů ETERNUS CS Data Protection Appliances ETERNUS CS200c Octo PQ Quad BS2000 Software TX & RX Služby Dual Scale Up/SMP Computing Up/SMP Scale ETERNUS CD ETERNUS DX/AF 10000 JX40/JX60 Disk Storage Hyper-scale LT JBOD system Mono Storage Tape Storage Kooperace s partnery CX Scale Out/Distributed Computing 1 © 2018 FUJITSU Portfolio serverů Fujitsu Fujitsu jako jediná firma na světě s kompletní nabídkou serverů. PRIMERGY PRIMEQUEST SPARC BS2000 Zkušenosti s vývojem a x86 servery pro provoz UNIX servery s jasnou Mainframe výrobou x86 serverů již od Mission-critical aplikací. roadmapou roku 1994 2 © 2018 FUJITSU Více než 20 let zkušeností Servery inspirované požadavky zákazníků First First x86 Converged Infrastructure First massive scale-out Cool-safe® ATD PRIMERGY First blade server Platform (PRIMERGY computing platform for web New levels of In- with support for server (PRIMERGY BX300) BladeFrame) hosters and telcos Memory computing up to 45°C 1994/95 2002 2005 2009 2014 2016 1998/99 2004 2008 2012 2015 First scale-up 8- Best-in-class cooling Virtual I/O First vendor offering a Cool-Central Liquid way x86 server concept (Cool-safe® management ‘Cluster-in-a-box’ solution Cooling Technology technology) … vývoj se zaměřením na jednoduchou obsluhu a nízké TCO Management Highest Highest-levels across the Usability & Versatile efficiency of reliability lifecycle Serviceability performance 3 © 2018 FUJITSU Doživotní záruka www.zatorucim.cz 4 © 2018 FUJITSU FUJITSU Server PRIMERGY Tower systems Robust and cost-efficient tower servers which are performance oriented, affordable and expandable. -

Nvidia® Gelato™ 1.0 Hardware
NVIDIA GELATO PRODUCT OVERVIEW APRIL04v01 NVIDIA® GELATO™ 1.0 HARDWARE- Key to this doctrine of no compromises is Gelato’s new shading language incorporates a ACCELERATED FINAL-FRAME RENDERER Gelato’s use of NVIDIA graphics hardware. simple and streamlined syntax based on C, Gelato is breakthrough, rendering software Gelato uses the NVIDIA Quadro FX as a second making it familiar and easy for most from NVIDIA, designed with a new architecture floating-point processor, taking advantage of programmers to learn and allowing for state- that leverages advances in mainstream graphics the 3D engine in ways far beyond gameplay. of-the-art shader-specific types and hardware to accelerate film-quality rendering. Gelato is one of the first in a wave of software functions. Gelato ships with an extensive This software renderer takes advantage of the applications that use the graphics hardware as set of shader libraries and examples. programmability, precision, performance, and an off-line processor, a “floating-point Gelato is available with a world-class quality of NVIDIA Quadro® FX professional supercomputer on a chip,” and not simply to support package, backed by NVIDIA, graphics solutions to render imagery of manage the display. the global leader in 3D graphics. uncompromising quality at unheard-of speeds. FAST AND GETTING FASTER The annual support package includes Gelato offers all the features film and television all product updates and upgrades. customers demand today and is flexible and Gelato unleashes the processing power of the extensible enough to satisfy their future graphics hardware that currently sits idle on LOOKING TO THE FUTURE requirements. -

Datasheet Search Site |
Datasheet Fujitsu SPARC Enterprise M8000 server Datasheet Fujitsu SPARC Enterprise M8000 server Provides the enterprise start point for large database. ERP and OLTP applications plus total stability, flexibility and asset protection. Only the best with Fujitsu SPARC Enterprise A SPARC of steel Based on robust SPARC architecture and As you would expect in a server aimed at your running the leading Oracle Solaris 11, Fujitsu most important tasks, Fujitsu SPARC Enterprise SPARC Enterprise servers are ideal for M8000 has all the qualities of a mainframe. customers needing highly scalable, reliable Absolutely rock solid, dependable and servers that increase their system utilization sophisticated, it has the total Solaris binary and performance through virtualization. compatibility necessary to both protect your investments and enhance your business. The combined leverage of Fujitsu’s expertise in mission-critical computing technologies and Its rich virtualization eco-system of extended high-performance processor design, with partitioning and Solaris Containers coupled Oracle’s expertise in open, scalable, with dynamic reconfiguration, means partition-based network computing, provides non-stop operation and total resource the overall flexibility to meet any task. utilization at no extra cost. Benchmark leading performance with the world’s best applications and outstanding processor scalability just add to the capabilities of this attractive open system platform. Page 1 of 8 www.fujitsu.com/sparcenterprise Datasheet Fujitsu SPARC Enterprise M8000 server Features and benefits Main features Benefits Flexible investment protection All SPARC64 VI dual-core processor and SPARC64 VII/VII+ quad-core Investment protection for years to come, less risk and lower cost of processor can be mixed and matched in the servers and even ownership. -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

An Adaptable and Extensible Geometry Kernel
An Adaptable and Extensible Geometry Kernel ¾ ¿ Susan Hert ½ , Michael Hoffmann , Lutz Kettner , ½ Sylvain Pion , and Michael Seel ½ Max-Planck-Institut fur ¨ Informatik, Stuhlsatzenhausweg 85 66123 Saarbrucken, ¨ Germany. Email: [hert|seel]@mpi-sb.mpg.de. ¾ Institute for Theoretical Computer Science, ETH Zurich, CH-8092 Zurich, Switzerland. Email: [email protected]. ¿ University of North Carolina at Chapel Hill, USA. Email: [email protected]. INRIA, Sophia Antipolis - France. Email: [email protected]. Abstract. Geometric algorithms are based on geometric objects such as points, lines and circles. The term kernel refers to a collection of representations for constant- size geometric objects and operations on these representations. This paper describes how such a geometry kernel can be designed and implemented in C++, having spe- cial emphasis on adaptability, extensibility and efficiency. We achieve these goals fol- lowing the generic programming paradigm and using templates as our tools. These ideas are realized and tested in CGAL [10], the Computational Geometry Algorithms Library. Keywords: Computational geometry, library design, generic programming. 1 Introduction Geometric algorithms that manipulate constant-size objects such as circles, lines, and points are usually described independent of any particular representation of the ob- jects. It is assumed that these objects have certain operations defined on them and that simple predicates exist that can be used, for example, to compare two objects or to determine their relative position. Algorithms are described in this way because all representations are equally valid as far as the correctness of an algorithm is concerned. Also, algorithms can be more concisely described and are more easily seen as being applicable in many settings when they are described in this more generic way. -

FCM 61 Italiano
Full Circle LA RIVISTA INDIPENDENTE PER LA COMUNITÀ LINUX UBUNTU Numero #61 - Maggio 2012 AUDIO FLUX NUOVA SEZIONE MUSICA GRATIS IN CC foto: downhilldom1984 (Flickr.com) CCOOPPIIAA EE CCOODDIIFFIICCAA DDII DDVVDD QQUUAATTTTRROO SSIISSTTEEMMII CCRROONNOOMMEETTRRAATTII EE PPRROOVVAATTII full circle magazine n.61 1 Full Circle magazine non è affiliata né sostenuta da Canonical Ltd. indice ^ HowTo Full Circle Opinioni LA RIVISTA INDIPENDENTE PER LA COMUNITÀ LINUX UBUNTU Python-Parte33 p.07 Rubriche LaMiaStoria p.38 UsareilcomandoTOP p.10 NotizieLinux p.04 AudioFlux p.52 LaMiaOpinione p.42 VirtualBoxNetworking p.15 Comanda&Conquista p.05 GiochiUbuntu p.53 IoPensoChe... p.43 GIMP-BeanstalkParte 2 p.21 LinuxLabs p.29 D&R p.50 RecensioneLibro p.45 Torna Prossimo Mese Inkscape-Parte1 p.24 DonneUbuntu p.XX Chiuderele«Finestre» p.32 Lettere p.46 Grafica Gli articoli contenuti in questa rivista sono stati rilasciati sotto la licenza Creative Commons Attribuzione - Non commerciale - Condividi allo stesso modo 3.0. Ciò significa che potete adattare, copiare, distribuire e inviare gli articoli ma solo sotto le seguenti condizioni: dovete attribuire il lavoro all'autore originale in una qualche forma (almeno un nome, un'email o un indirizzo Internet) e a questa rivista col suo nome ("Full Circle Magazine") e con il suo indirizzo Internet www.fullcirclemagazine.org (ma non attribuire il/gli articolo/i in alcun modo che lasci intendere che gli autori e la rivista abbiano esplicitamente autorizzato voi o l'uso che fate dell'opera). Se alterate, trasformate o create un'opera su questo lavoro dovete distribuire il lavoro risultante con la stessa licenza o una simile o compatibile.