Comparing Broadband ISP Performance Using Big Data from M-Lab
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
State of Mobile Networks: Australia (November 2018)
State of Mobile Networks: Australia (November 2018) Australia's level of 4G access and its mobile broadband speeds continue to climb steadily upwards. In our fourth examination of the country's mobile market, we found a new leader in both our 4G speed and availability metrics. Analyzing more than 425 million measurements, OpenSignal parsed the 3G and 4G metrics of Australia's three biggest operators Optus, Telstra and Vodafone. Report Facts 425,811,023 31,735 Jul 1 - Sep Australia Measurements Test Devices 28, 2018 Report Sample Period Location Highlights Telstra swings into the lead in our download Optus's 4G availability tops 90% speed metrics Optus's 4G availability score increased by 2 percentage points in the A sizable bump in Telstra's 4G download speed results propelled last six months, which allowed it to reach two milestones. It became the the operator to the top of our 4G download speed and overall first Australian operator in our measurements to pass the 90% threshold download speed rankings. Telstra also became the first in LTE availability, and it pulled ahead of Vodafone to become the sole Australian operator to cross the 40 Mbps barrier in our 4G winner of our 4G availability award. download analysis. Vodafone wins our 4G latency award, but Telstra maintains its commanding lead in 4G Optus is hot on its heels upload Vodafone maintained its impressive 4G latency score at 30 While the 4G download speed race is close among the three operators milliseconds for the second report in row, holding onto its award in Australia, there's not much of a contest in 4G upload speed. -

Separation of Telstra: Economic Considerations, International Experience
WIK-Consult Report Study for the Competitive Carriers‟ Coalition Separation of Telstra: Economic considerations, international experience Authors: J. Scott Marcus Dr. Christian Wernick Kenneth R. Carter WIK-Consult GmbH Rhöndorfer Str. 68 53604 Bad Honnef Germany Bad Honnef, 2 June 2009 Functional Separation of Telstra I Contents 1 Introduction 1 2 Economic and policy background on various forms of separation 4 3 Case studies on different separation regimes 8 3.1 The Establishment of Openreach in the UK 8 3.2 Functional separation in the context of the European Framework for Electronic Communication 12 3.3 Experiences in the U.S. 15 3.3.1 The Computer Inquiries 15 3.3.2 Separate affiliate requirements under Section 272 17 3.3.3 Cellular separation 18 3.3.4 Observations 20 4 Concentration and cross-ownership in the Australian marketplace 21 4.1 Characteristics of the Australian telecommunications market 22 4.2 Cross-ownership of fixed, mobile, and cable television networks 27 4.3 The dominant position of Telstra on the Australian market 28 5 An assessment of Australian market and regulatory characteristics based on Three Criteria Test 32 5.1 High barriers to entry 33 5.2 Likely persistence of those barriers 35 5.3 Inability of other procompetitive instruments to address the likely harm 38 5.4 Conclusion 38 6 The way forward 39 6.1 Regulation or separation? 40 6.2 Structural separation, or functional separation? 42 6.3 What kind of functional separation? 44 6.3.1 Overview of the functional separation 44 6.3.2 What services and assets should be assigned to the separated entity? 47 6.3.3 How should the separation be implemented? 49 Bibliography 52 II Functional Separation of Telstra Recommendations Recommendation 1. -

Telstra Corporation Limited (‘Telstra’) Welcomes the Opportunity to Make a Submission to the USPTO on Prior User Rights
Introduction Telstra Corporation Limited (‘Telstra’) welcomes the opportunity to make a submission to the USPTO on prior user rights. As Australia’s leading telecommunications and information services company, Telstra provides customers with a truly integrated experience across fixed line, mobiles, broadband, information, transaction, search and pay TV. Telstra BigPond is Australia’s leading Internet Service Provider offering retail internet access nationally, along with a range of online and mobile content and value added services One of our major strengths in providing integrated telecommunications services is our vast geographical coverage through both our fixed and mobile network infrastructure. This network and systems infrastructure underpins the carriage and termination of the majority of Australia's domestic and international voice and data telephony traffic. Telstra has an extensive intellectual property portfolio, including trade mark and patent rights in Australian and overseas. Telstra is also a licensor and a licensee of intellectual property, including a licensee of online and digital content. The prior user exemptions to infringement under Australian and other countries’ (such as Japanese, EU and Canadian) law are important mechanisms that allow companies or individuals to continue activities legitimately undertaken prior to the grant of a third party patent. It’s Telstra’s submission that harmonisation of US laws to recognise and adopt similar prior user provisions would be welcomed to similarly provide certainty for commercial practices and investment. Our response below focuses on those aspects of the study into prior user rights that are of particular interest or concern to Telstra. 1a. Please share your experiences relating to the use of prior user rights in foreign jurisdictions including, but not limited to, members of the European Union and Japan, Canada, and Australia. -

Getting to Know Your Telstra Pre-Paid 3G Wi-Fi Let’S Get This Show on the Road
GETTING TO KNOW YOUR TELSTRA PRE-PAID 3G WI-FI LET’S GET THIS SHOW ON THE ROAD You must be excited about your brand new Telstra Pre-Paid 3G Wi-Fi. This guide will help you get connected as quickly and as easily as possible. It’ll guide you through installation and run through all the handy extra features that are included. If all goes to plan you’ll be up and running in no time, so you can get connected while you’re on the move. 2 WHAT’S INSIDE 03 Safety first 06 Let’s get started 13 Getting connected 25 Wi-Fi home page 20 Extra features 22 Problem solving 25 Extra bits you should know 2 SAFETY FIRST Please read all the safety notices before using this device. This device is designed to be used at least 20cm from your body. Do not use the device near fuel or chemicals or in any prescribed area such as service stations, refineries, hospitals and aircraft. Obey all warning signs where posted. RADIO FREQUENCY SAFETY INFORMATION The device has an internal antenna. For optimum performance with minimum power consumption do not shield the device or cover with any object. Covering the antenna affects signal quality, may cause the router to operate at a higher power level than needed, and may shorten battery life. RADIO FREQUENCY ENERGY Your wireless device is a low-power radio transmitter and receiver. When switched on it intermittently transmits radio frequency (RF) energy (radio waves). The transmit power level is optimised for best performance and automatically 3 4 reduces when there is good quality reception. -
The State of 5G Trials
The State of Trials Courtesy of 5G Data Speeds Shows the highest claimed data speeds reached during 5G trials, where disclosed 36 Gb/s Etisalat 35.46 Gb/s Ooredoo 35 Gb/s M1 35 Gb/s StarHub 35 Gb/s Optus 20 Gb/s Telstra 20 Gb/s Vodafone UK 15 Gb/s Telia 14 Gb/s AT&T 12 Gb/s T-Mobile USA 11.29 Gb/s NTT DoCoMo 10 Gb/s Vodafone Turkey 10 Gb/s Verizon 10 Gb/s Orange France 9 Gb/s US Cellular 7 Gb/s SK Telecom 5.7 Gb/s SmartTone 5 Gb/s Vodafone Australia 4.5 Gb/s Sonera 4 Gb/s Sprint 2.3 Gb/s Korea Telecom 2.2 Gb/s C Spire 5G Trial Spectrum Shows the spectrum used by operators during 5G trials, where disclosed Telstra Optus NTTDoCoMo AT&T AT&T AT&T AT&T Verizon Vodafone Korea Vodafone Bell Vodafone StarHub UK Telecom Turkey Canada Turkey Sonera China SmarTone C Spire Verizon Mobile M1 Vodafone Sprint Korea Australia Telecom Optus Telia NTT DoCoMo Sprint Turkcell SK Telecom US Cellular T-Mobile USA Verizon US Cellular Verizon SUB 3 3.5 4.5 SUB 6 15 28 39 64 70 70-80 71-76 73 81-86 60-90 GHTZ Operator 5G Trials Shows the current state of 5G progress attained by operators Announced 5G trials Lab testing 5G Field testing 5G Operators that have announced timings of Operators that have announced Operators that have announced that they trials or publicly disclosed MoUs for trials that they have lab tested 5G have conducted 5G testing in the field Equipment Providers in 5G Trials Shows which equipment providers are involved in 5G trials with operators MTS T-Mobile USA SK Telekom Verizon Batelco Turkcell AT&T Bell Canada Sonera SmarTone Vodafone Orange BT Taiwan Germany Telia Mobile Telstra C Spire Vodafone US Cellular Vodafone Turkey M1 Australia MTS Ooredoo M1 NTT Docomo Optus Orange China StarHub Mobile Korea Telecom 5G trials with all five equipment providers Telefonica Deutsche Telekom Etisalat Telus Vodafone UK Viavi (NASDAQ: VIAV) is a global provider of network test, monitoring and assurance solutions to communications service providers, enterprises and their ecosystems. -

LTE-M & NB-Iot Measurements in Australia
Audit Report. LTE-M & NB-IoT measurements in Australia umlaut report umlaut report Foreword umlaut has tested the quality of the Mobile Networks in the Australian The company is headquartered in market and took a detailed look into Aachen, Germany and is a world the LTE-M & NB-IoT scanner mea- leader in mobile network testing and surements of the operators offering benchmarking. these services. 2 3 umlaut report umlaut report Report facts Testing Area 48,000 km States measured driven km Australian Capital Territory Victoria Northern Territory W43 2019 Western Australia to W48 2019 South Australia Data collection Queensland time period Tasmania The map shows the total driving area for Australia. The routes were independently selected by umlaut. 4 5 umlaut report umlaut report Overall coverage comparison per region NB-IoT and LTE-M technologies overall NB-IoT coverage comparison LTE-M coverage comparison coverage comparison per region per region per region Telstra Vodafone Telstra Vodafone Telstra Vodafone 100 100 100 The observation period was between CW43 2019 and CW48 2019. Telstra shows a higher NB-IoT coverage than Vodafone in [%] [%] [%] all eight Australian regions. Telstra is the only operator to deploy LTE-M technology in Australia showing high signal network coverage country wide. 0 0 0 South South South Overall Overall Overall Victoria Victoria Victoria Western Western Western Territory Territory Territory Australia Australia Australia Australia Australia Australia Northern Northern Northern Tasmania Tasmania Tasmania New South New South New South Queensland Queensland Queensland Wales & ACT Wales & ACT Wales & ACT 6 7 umlaut report umlaut report Signal coverage level and quality comparison per region (total) Telstra shows higher average values for NB-IoT signal Telstra shows an average of -10,4 dB for NB-IoT signal Telstra shows an average of -15,5 dB for LTE-M signal net- network coverage (NRSRP) than Vodafone in 6 out of 8 network quality (NRSRQ) and is slightly worse (~1dB) than work quality (RSRQ) in all Australian regions. -

Exesim Ultra 3G Mobile Voice Plan (4G17-ULTRA)
CRITICAL INFORMATION SUMMARY ExeSim Ultra 3G Mobile Voice Plan (4G17-ULTRA) This summary gives you the important information you need to know about your Exetel mobile Voice plan. It covers things like the length of your contract, billing, what’s covered and what’s not. Information About The Service This plan offers a $79.99 3G mobile voice service on a month to The monthly allowances are not interchangeable and unused value month term which includes one included value allowance and two from one allowance cannot be transferred to another or into the unlimited allowances: current of following month if unused. 1. UNLIMITED National talk to Landlines and Mobiles Subject to the Exetel Mobile Acceptable use Policy and the Exetel Terms and Conditions go to: 2. UNLIMITED National SMS and MMS http://www.exetel.com.au/terms 3. 90GB of 3G National Data* Information about pricing Recurring charges are payable monthly in advance. The allowances expire at the end of each month. The included National Data Minimum monthly cost allowance includes all usage for both uploads and downloads. This is a stand-alone service and is not bundled with any other product. $79.99 is the minimum financial commitment for this offer. If your * Prorata allowance applies in the first month. usage exceeds the included National 3G Data Allowance, additional usage charges will apply. BYO device The most common charges used to calculate your usage A compatible mobile (with the Optus 3G Network) device is (allowance and any excess) are as follows; required to gain access to the service, and is required to be operated inside the coverage area. -

Optus Internet Everyday
Critical information summary This summary does not reflect any special discounts, bonus data or promotions which may apply from time to time. Optus Internet Everyday Plan ID: 35287684 Information about the Service Description of the Service This plan is for a stand-alone Fixed Broadband service that is supplied using the Optus nbn™ network. The Optus Internet Everyday plan also has the option of bundling a Fixed Telephone service. See “Optional Phone Plans” (page 3) section for more information. Plan Minimum monthly charge $79/mth Minimum term Month-to-month Monthly data allowance Unlimited Start-up fee $0 However, fees may apply for a first time nbn connection to dwellings in new developments, for additional lines or for non-standard installations Modem charges $252 Optus will cover the cost of the modem if you remain connected for 36 months (i.e. $7/mth over 36 months) Cancellation fee There is no cancellation fee for this plan. If applicable, you’ll need to pay out any remaining device payments in full (any credits or discounts will be forfeited), plus, all charges incurred up to the end of the billing cycle in which your service is cancelled (unless otherwise specified) Minimum total cost $331 (includes $252 modem cost and one month of plan fee) (when you pay by direct debit) Service and plan availability Device Payment Plans Optus Broadband services are not available in all areas or to You can buy an eligible device (such as a Booster) on a Device all premises. The broadband service offered will be determined Payment Plan (DPP) and pay for it over a selected term by by what is available at your location. -
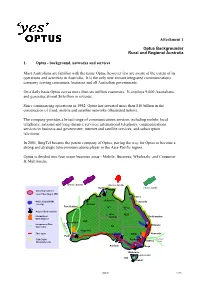
1. Optus - Background, Networks and Services
Attachment 1 Optus Backgrounder Rural and Regional Australia 1. Optus - background, networks and services Most Australians are familiar with the name Optus, however few are aware of the extent of its operations and activities in Australia. It is the only new entrant integrated communications company serving consumers, business and all Australian governments. On a daily basis Optus serves more than six million customers. It employs 9,000 Australians, and generates almost $6 billion in revenue. Since commencing operations in 1992, Optus has invested more than $10 billion in the construction of fixed, mobile and satellite networks (illustrated below). The company provides a broad range of communications services including mobile; local telephony; national and long distance services; international telephony; communications services to business and government; internet and satellite services; and subscription television. In 2001, SingTel became the parent company of Optus, paving the way for Optus to become a strong and strategic telecommunications player in the Asia-Pacific region. Optus is divided into four major business areas - Mobile; Business; Wholesale; and Consumer & Multimedia. B-Series Satellite A-Series Satellite Darwin C-Series Satellite Switching Systems/ Local Fibre Ring in CBD Cairns Mobile Digital(GSM) Katherine Townsville coverage Broome Port Hedland NT Mt Isa National Earth Stations Alice QLD International Springs Rockhampton Earth Station s WA S Geraldton International Fibre e M Brisbane e SA Optic Cable W e 3 Kalgoorlie Fibre Optic Port Augusta NSW Newcastle Perth SDH Digital Canberra Southern Sydney Microwave Link Cross VIC Adelaide Bega Melbourne Launceston TAS Hobart Optus 1 of 5 The company’s Mobile business unit has captured around one-third of the total Australian GSM mobile market and leads the market in mobile data take up. -

Optus Recognises That Such an Approach, Whilst It Has Strong Policy Merit, Might Be Challenging Politically
Public Version | Page 1 Executive Summary 3 Developments in the sector have removed the need for a USO 5 Historical rationale of the USO 5 Current USO is a failed policy 7 There is no need for a USO 8 No justification for multiple sets of infrastructure to deliver USO 13 Retail competition over competitive infrastructure ensures supply 13 Current USO imposes high and untested costs 16 Extent of the current USO 16 Costs of the current USO 18 The USO distorts competition 22 Impact of USO on competitors 23 USO tax diverts competitive rural investment 25 Interaction with other government policies 25 Alternate USO policy options 27 A reformed USO should leverage off the NBN infrastructure 28 Promoting retail competition for provision of services 29 Keeping Telstra’s USO contractual position whole 31 Appendix A. Historic rationale of the USO 32 Appendix B. Issues Paper Questions 39 Public Version | Page 2 1.1 The Universal Service Obligation (USO) remains rooted in principles more applicable to the analogue era of telecommunications. It is predominantly focused on the delivery of fixed voice handsets and voice calls over fixed line copper connections. The widespread deployment and use of mobile, data and broadband services now render it increasingly inappropriate. 1.2 Three decades after the genesis of the USO the industry is vastly different from that which existed in the late 1980s: (a) Whilst Telstra retains a dominant position in the market, especially in regional Australia, competitive forces and regulation ensure that customers have access to genuine choice in a way that was not possible in the 1980s. -

Roaming Rates.Xlsx
ROAMING RATES IN LSL Main TAP Back Country Organisation Code Local Call Home SMS GPRS Price/min Price/min Originated Price/MB Albania ALBEM Eagle Mobile Sh.a. 4.77 27.66 2.28 11.91 Angola AGOUT Unitel 6.22 41.46 2.76 17.97 Anguilla AIACW Cable & Wireless, Anguilla 22.11 36.62 4.15 12.74 Antigua and Barbuda ATGCW Cable & Wireless, Antigua 22.11 36.62 4.15 12.74 Argentina ARGTM Telefonica M�viles Argentina S.A. 8.29 38.69 4.15 13.87 Armenia ARM05 K Telecom CJSC 4.35 26.12 3.45 9.76 Australia AUSTA Telstra 8.93 45.27 5.10 32.64 Bahrain BHRBT Bahrain Telecommunications Co. 11.42 46.28 5.80 18.80 Bahrain BHRST VIVA Bahrain 11.75 49.58 6.61 22.56 Barbados BRBCW Cable & Wireless (Barbados) Limited 22.11 36.62 4.15 12.74 Belgium BELKO KPN GROUP BELGIUM NV/SA 9.77 47.91 2.38 19.23 Belgium BELMO Mobistar S.A. 17.25 46.83 4.12 33.36 Belgium BELTB Belgacom SA/NV 14.37 54.61 4.12 19.23 Bolivia BOLTE Telefonica Celular De Bolivia S.A 8.43 17.96 3.45 7.22 Botswana BWAGA Mascom Wireless 4.40 4.88 3.15 3.14 Botswana BWAVC Orange (Botswana) PTY Limited 3.93 6.29 3.15 13.50 Botswana BWABC beMOBILE BOTSWANA 5.33 14.95 3.81 21.19 Brazil BRACS TIM CELULAR SA (BRACS) 10.78 41.32 4.15 16.56 Brazil BRARN TIM CELULAR SA (BRARN) 10.78 41.32 4.15 16.56 Brazil BRASP TIM CELULAR SA (BRASP) 10.78 41.32 4.15 16.56 Brazil BRATC Vivo MG 9.81 39.11 3.59 16.98 Brazil BRAV1 VIVO (BRAV1) 9.81 39.11 3.59 16.98 Brazil BRAV2 VIVO (BRAV2) 9.81 39.11 3.59 16.98 Brazil BRAV3 VIVO (BRAV3) 9.81 39.11 3.59 16.98 British Virgin Isl VGBCW CABLE & WIRELESS (BVI) 22.11 36.62 4.15 12.74 Bulgaria BGR01 Mobiltel EAD 9.58 47.91 4.79 17.46 Burkina Faso BFATL Telecel Faso 5.84 13.99 2.91 n/a Cambodia KHMGM Camgsm Company Ltd. -

PRIMUS TELECOMMUNICATIONS GROUP, INCORPORATED (Exact Name of Registrant As Specified in Its Charter)
Table of Contents SECURITIES AND EXCHANGE COMMISSION WASHINGTON, D.C. 20549 FORM 10-K ☒ ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the fiscal year ended December 31, 2007 OR ☐ TRANSITION REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 Commission File No. 0-29092 PRIMUS TELECOMMUNICATIONS GROUP, INCORPORATED (Exact name of registrant as specified in its charter) Delaware 54-1708481 (State or other jurisdiction of (I.R.S. Employer incorporation or organization) Identification No.) 7901 Jones Branch Drive, Suite 900, McLean, VA 22102 (Address of principal executive offices) (Zip Code) (703) 902-2800 (Registrant’s telephone number, including area code) Securities registered pursuant to Section 12(b) of the Act: Title of each class Name of each exchange on which registered None N/A Securities registered pursuant to Section 12(g) of the Act: Common Stock, par value $.01 per share Indicate by check mark if the registrant is a well-known seasoned issuer, as defined in Rule 405 of the Securities Act. Yes ☐ No ☒ Indicate by check mark if the registrant is not required to file reports pursuant to Section 13 or Section 15(d) of the Act. Yes ☐ No ☒ Indicate by check mark whether the registrant (1) has filed all reports required to be filed by Section 13 or 15(d) of the Securities Exchange Act of 1934 during the preceding 12 months (or for such shorter period that the registrant was required to file such reports), and (2) has been subject to such filing requirements for the past 90 days.