Introduction to Audio Signal Processing Human-Computer Interaction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

And Passive Speakers?
To be active or not to be active – that is the question... To be active or not to be active – that is the question... 1. Active, passive – the situation 2. Active and passive loudspeaker – the basic difference 3. Passive loudspeaker 4. Active loudspeaker 5. The ADAM loudspeaker: passive option, active optimum 1. Active versus Passive – the Situation In any hifi-system, the loudspeakers are the pivotal component concerning sound quality. That is not to say that the other components do not matter. Nevertheless, it is indisputable that the loudspeaker is decisive for the sound of a hifi-system. It is – besides the acoustical properties of the listening room and the recording itself – the core of any music reproduction. The history of loudspeaker development has produced a great variety of very different systems and designs. The circuit technology of the frequency-separating filter that separates the audio signal into different frequency ranges is determining the design of a loudspeaker. In this respect we distinguish between active and passive systems. Usually, this is a topic that is often underestimated in its importance for sound quality. Active-passive is much more than just a technical negligibility: In fact, the impact of the dividing network on the overall sound of a loudspeaker is substantial. Active or passive – which system is preferable? Considering the aspects mentioned before, it may become a little more comprehensive why the very question comes up over and over again in the hifi-world. For decades it has been spooking as a debate on principles in the journals and magazines and for some time, now, in the web forums. -

Real-Time Programming and Processing of Music Signals Arshia Cont
Real-time Programming and Processing of Music Signals Arshia Cont To cite this version: Arshia Cont. Real-time Programming and Processing of Music Signals. Sound [cs.SD]. Université Pierre et Marie Curie - Paris VI, 2013. tel-00829771 HAL Id: tel-00829771 https://tel.archives-ouvertes.fr/tel-00829771 Submitted on 3 Jun 2013 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Realtime Programming & Processing of Music Signals by ARSHIA CONT Ircam-CNRS-UPMC Mixed Research Unit MuTant Team-Project (INRIA) Musical Representations Team, Ircam-Centre Pompidou 1 Place Igor Stravinsky, 75004 Paris, France. Habilitation à diriger la recherche Defended on May 30th in front of the jury composed of: Gérard Berry Collège de France Professor Roger Dannanberg Carnegie Mellon University Professor Carlos Agon UPMC - Ircam Professor François Pachet Sony CSL Senior Researcher Miller Puckette UCSD Professor Marco Stroppa Composer ii à Marie le sel de ma vie iv CONTENTS 1. Introduction1 1.1. Synthetic Summary .................. 1 1.2. Publication List 2007-2012 ................ 3 1.3. Research Advising Summary ............... 5 2. Realtime Machine Listening7 2.1. Automatic Transcription................. 7 2.2. Automatic Alignment .................. 10 2.2.1. -

Introduction to the Digital Snake
TABLE OF CONTENTS What’s an Audio Snake ........................................4 The Benefits of the Digital Snake .........................5 Digital Snake Components ..................................6 Improved Intelligibility ...........................................8 Immunity from Hums & Buzzes .............................9 Lightweight & Portable .......................................10 Low Installation Cost ...........................................11 Additional Benefits ..............................................12 Digital Snake Comparison Chart .......................14 Conclusion ...........................................................15 All rights reserved. No part of this publication may be reproduced in any form without the written permission of Roland System Solutions. All trade- marks are the property of their respective owners. Roland System Solutions © 2005 Introduction Digital is the technology of our world today. It’s all around us in the form of CDs, DVDs, MP3 players, digital cameras, and computers. Digital offers great benefits to all of us, and makes our lives easier and better. Such benefits would have been impossible using analog technology. Who would go back to the world of cassette tapes, for example, after experiencing the ease of access and clean sound quality of a CD? Until recently, analog sound systems have been the standard for sound reinforcement and PA applications. However, recent technological advances have brought the benefits of digital audio to the live sound arena. Digital audio is superior -

Audio Interface User's Manual
Audio Interface User’s Manual Eurorack Synthesizer Modules 14 HP TABLE OF CONTENTS 1.INTRODUCTION 2.WARRANTY 3.INSTALLATION 4.FUNCTION OF PANEL COMPONENTS 5.SIGNALFLOW & ROUTING 6.SPECIFICATIONS 2 1. INTRODUCTION Audiophile Circuits League. -The main purpose of the ACL Audio Interface module is to interface modular synthesizer systems with professional audio recording and stage equipment. The combination of studio quality signal path, �lexible routing possibilities and a headphoneheadphones ampli�ier, with low capabledistortion, of drivingmakes theboth connection high and low between impedance these different environments effortless and sonically transparent. The ACL Audio Interface offers balanced to unbalanced and unbalanced to balanced stereo lines with level controls. The stereo signal from the auxiliary input,either alsowith with balanced level tocontrol, unbalanced, can be oroptionally unbalanced routed to balanced to and mixed line signals,together or can be muted. The headphone ampli�ier can also get its signal from one or the other line after the level control and mixing stage, or can be muted. Since the ampli�ier is AC coupled only at the input, but not at the output, there is an on-board DC protection circuit included. In case the headphone ampli�ier is driven into clipping, the protection can also be tripped. The module has a soft start function* and one overload indicator for every line. *With the soft start function, the interface switch is turned on after a while after turning on the Eurorack main unit. This function can prevent output of unexpecteddamage to the sound speaker. that another module will emit at startup, which will cause 3 2. -

21065L Audio Tutorial
a Using The Low-Cost, High Performance ADSP-21065L Digital Signal Processor For Digital Audio Applications Revision 1.0 - 12/4/98 dB +12 0 -12 Left Right Left EQ Right EQ Pan L R L R L R L R L R L R L R L R 1 2 3 4 5 6 7 8 Mic High Line L R Mid Play Back Bass CNTR 0 0 3 4 Input Gain P F R Master Vol. 1 2 3 4 5 6 7 8 Authors: John Tomarakos Dan Ledger Analog Devices DSP Applications 1 Using The Low Cost, High Performance ADSP-21065L Digital Signal Processor For Digital Audio Applications Dan Ledger and John Tomarakos DSP Applications Group, Analog Devices, Norwood, MA 02062, USA This document examines desirable DSP features to consider for implementation of real time audio applications, and also offers programming techniques to create DSP algorithms found in today's professional and consumer audio equipment. Part One will begin with a discussion of important audio processor-specific characteristics such as speed, cost, data word length, floating-point vs. fixed-point arithmetic, double-precision vs. single-precision data, I/O capabilities, and dynamic range/SNR capabilities. Comparisions between DSP's and audio decoders that are targeted for consumer/professional audio applications will be shown. Part Two will cover example algorithmic building blocks that can be used to implement many DSP audio algorithms using the ADSP-21065L including: Basic audio signal manipulation, filtering/digital parametric equalization, digital audio effects and sound synthesis techniques. TABLE OF CONTENTS 0. INTRODUCTION ................................................................................................................................................................4 1. -

MINIDISC MANUAL V3.0E Table of Contents
MINIDISC MANUAL V3.0E Table of Contents Introduction . 1 1. The MiniDisc System 1.1. The Features . 2 1.2. What it is and How it Works . 3 1.3. Serial Copy Management System . 8 1.4. Additional Features of the Premastered MD . 8 2. The production process of the premastered MD 2.1. MD Production . 9 2.2. MD Components . 10 3. Input components specification 3.1. Sound Carrier Specifications . 12 3.2. Additional TOC Data / Character Information . 17 3.3. Label-, Artwork- and Print Films . 19 3.4. MiniDisc Logo . 23 4. Sony DADC Austria AG 4.1. The Company . 25 5. Appendix Form Sheets Introduction T he quick random access of Compact Disc players has become a necessity for music lovers. The high quality of digital sound is now the norm. The future of personal audio must meet the above criteria and more. That’s why Sony has created the MiniDisc, a revolutionary evolution in the field of digital audio based on an advanced miniature optical disc. The MD offers consumers the quick random access, durability and high sound quality of optical media, as well as superb compactness, shock- resistant portability and recordability. In short, the MD format has been created to meet the needs of personal music entertainment in the future. Based on a dazzling array of new technologies, the MiniDisc offers a new lifestyle in personal audio enjoyment. The Features 1. The MiniDisc System 1.1. The Features With the MiniDisc, Sony has created a revolutionary optical disc. It offers all the features that music fans have been waiting for. -

Class D Audio Amplifier Basics
Application Note AN-1071 Class D Audio Amplifier Basics By Jun Honda & Jonathan Adams Table of Contents Page What is a Class D Audio Amplifier? – Theory of Operation..................2 Topology Comparison – Linear vs. Class D .........................................4 Analogy to a Synchronous Buck Converter..........................................5 Power Losses in the MOSFETs ...........................................................6 Half Bridge vs. Full Bridge....................................................................7 Major Cause of Imperfection ................................................................8 THD and Dead Time ............................................................................9 Audio Performance Measurement........................................................10 Shoot Through and Dead Time ............................................................11 Power Supply Pumping........................................................................12 EMI Consideration: Qrr in Body Diode .................................................13 Conclusion ...........................................................................................14 A Class D audio amplifier is basically a switching amplifier or PWM amplifier. There are a number of different classes of amplifiers. This application note takes a look at the definitions for the main classifications. www.irf.com AN-1071 1 AN-1071 What is a Class D Audio Amplifier - non-linearity of Class B designs is overcome, Theory of Operation without the inefficiencies -

Audio Signals Amplitude and Loudness Sound
Intro to Audio Signals Amplitude and Loudness Sound I Sound: vibration transmitted through a medium (gas, liquid, Audio DSP solid and plasma) composed of frequencies capable of being detected by ears. I Note: sound cannot travel through a vacuum. Dr. Deepa Kundur I Human detectable sound is often characterized by air pressure University of Toronto variations detected by the human ear. I The amplitude, frequency and relative phase of the air pressure signal components determine (in part) the way the sound is perceived. Dr. Deepa Kundur (University of Toronto) Audio DSP 1 / 56 Dr. Deepa Kundur (University of Toronto) Audio DSP 2 / 56 Intro to Audio Signals Amplitude and Loudness Intro to Audio Signals Amplitude and Loudness Sinusoids and Sound: Amplitude Sound Volume I Volume = Amplitude of sound waves/audio signals I A fundamental unit of sound is the sinusoidal signal. 2 I quoted in dB, which is a logarithmic measure; 10 log(A ) I no sound/null is −∞ dB xa(t) = A cos(2πF0t + θ); t 2 R I Loudness is a subjective measure of sound psychologically correlating to the strength of the sound signal. I A ≡ volume I the volume is an objective measure and does not have a I F0 ≡ pitch (more on this . ) one-to-one correspondence with loudness I θ ≡ phase (more on this . ) I perceived loudness varies from person-to-person and depends on frequency and duration of the sound Dr. Deepa Kundur (University of Toronto) Audio DSP 3 / 56 Dr. Deepa Kundur (University of Toronto) Audio DSP 4 / 56 Intro to Audio Signals Amplitude and Loudness Intro to Audio Signals Frequency and Pitch Music Volume Dynamic Range Sinusoids and Sound: Frequency Tests conducted for the musical note: C6 (F0 = 1046:502 Hz). -
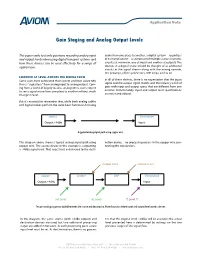
Gain Staging and Analog Output Levels
Application Note Gain Staging and Analog Output Levels This paper seeks to clarify questions regarding analog input audio from one place to another, a digital system—regardless and output levels when using digital transport systems and of its manufacturer—is comprised of multiple active electronic how these devices can be used effectively for a range of circuits (at minimum, one at input and another at output). The applications. devices in a digital snake should be thought of as additional circuits in the signal chain—along with the mixing console, mic preamps, effects processors, DSP, amps, and so on. Looking At LeVeL ACroSS the SignAL FLoW Some users have connected their system and then asked why In all of these devices, there is no expectation that the input there’s “signal loss” from analog input to analog output. Com- signal and the output signal match, and the industry is full of ing from a world of largely lossless analog wires, users expect gear with input and output specs that are different from one to see a signal move from one place to another without much another. Unfortunately, input and output level specifications change in level. are not standardized. But it’s essential to remember that, while both analog cables and digital snakes perform the same basic function of moving Source Destination Output +4dBu Input Source A typical analog signal path using copper wire Destination Output +4dBu Input This diagram above shows a typical analog signal path using nation device—no processing occurs in the copper wire con- copper wire. The source device in this example is outputting necting the two devices. -

Analog Signal Processing Christophe Caloz, Fellow, IEEE, Shulabh Gupta, Member, IEEE, Qingfeng Zhang, Member, IEEE, and Babak Nikfal, Student Member, IEEE
1 Analog Signal Processing Christophe Caloz, Fellow, IEEE, Shulabh Gupta, Member, IEEE, Qingfeng Zhang, Member, IEEE, and Babak Nikfal, Student Member, IEEE Abstract—Analog signal processing (ASP) is presented as a discrimination effects, emphasizing the concept of group delay systematic approach to address future challenges in high speed engineering, and presenting the fundamental concept of real- and high frequency microwave applications. The general concept time Fourier transformation. Next, it addresses the topic of of ASP is explained with the help of examples emphasizing basic ASP effects, such as time spreading and compression, the “phaser”, which is the core of an ASP system; it reviews chirping and frequency discrimination. Phasers, which repre- phaser technologies, explains the characteristics of the most sent the core of ASP systems, are explained to be elements promising microwave phasers, and proposes corresponding exhibiting a frequency-dependent group delay response, and enhancement techniques for higher ASP performance. Based hence a nonlinear phase response versus frequency, and various on ASP requirements, found to be phaser resolution, absolute phaser technologies are discussed and compared. Real-time Fourier transformation (RTFT) is derived as one of the most bandwidth and magnitude balance, it then describes novel fundamental ASP operations. Upon this basis, the specifications synthesis techniques for the design of all-pass transmission of a phaser – resolution, absolute bandwidth and magnitude and reflection phasers -

A History of Audio Effects
applied sciences Review A History of Audio Effects Thomas Wilmering 1,∗ , David Moffat 2 , Alessia Milo 1 and Mark B. Sandler 1 1 Centre for Digital Music, Queen Mary University of London, London E1 4NS, UK; [email protected] (A.M.); [email protected] (M.B.S.) 2 Interdisciplinary Centre for Computer Music Research, University of Plymouth, Plymouth PL4 8AA, UK; [email protected] * Correspondence: [email protected] Received: 16 December 2019; Accepted: 13 January 2020; Published: 22 January 2020 Abstract: Audio effects are an essential tool that the field of music production relies upon. The ability to intentionally manipulate and modify a piece of sound has opened up considerable opportunities for music making. The evolution of technology has often driven new audio tools and effects, from early architectural acoustics through electromechanical and electronic devices to the digitisation of music production studios. Throughout time, music has constantly borrowed ideas and technological advancements from all other fields and contributed back to the innovative technology. This is defined as transsectorial innovation and fundamentally underpins the technological developments of audio effects. The development and evolution of audio effect technology is discussed, highlighting major technical breakthroughs and the impact of available audio effects. Keywords: audio effects; history; transsectorial innovation; technology; audio processing; music production 1. Introduction In this article, we describe the history of audio effects with regards to musical composition (music performance and production). We define audio effects as the controlled transformation of a sound typically based on some control parameters. As such, the term sound transformation can be considered synonymous with audio effect. -

Telesounds Quickstart Guide
Telesounds Quickstart Guide English ( 2 – 7 ) Guía de inicio rápido Español ( 8 – 13 ) Appendix English ( 14 – 15 ) Quickstart Guide (English) Introduction Thank you for purchasing the Telesounds. At ION, your entertainment is as important to us as it is to you. That’s why we design our products with one thing in mind—to make your life more fun and more convenient. Important Safety Notices Warning: Prolonged exposure to excessive sound pressure (high volumes) from headphones can cause permanent hearing loss. Warning: Do not expose batteries to excessive heat such as sunlight, fire, or the like. Box Contents Telesounds Headphones 1/4”-to-1/8” (6.35 mm to 3.5 mm) Adapter Transmitter Power Adapter Cables (1 of each): (2) Rechargeable AAA Batteries 1/8”-to-1/8” (3.5 mm) Quickstart Guide RCA-to-RCA Safety & Warranty Manual 1/8”-to-RCA (3.5 mm) Optical Coaxial Support For the latest information about this product (documentation, technical specifications, system requirements, compatibility information, etc.) and product registration, visit ionaudio.com. For additional product support, visit ionaudio.com/support. 2 Features Transmitter 1 Front Panel 1. Charging Dock: Place the headband of the headphones on this dock (on top of the transmitter) to charge them. Make 2 sure that the transmitter is connected to a power outlet and that its Power switch is set to On. 3 2. Charge Light: This light is green when the headphones 4 (placed on the charging station) are charging. It will turn off when the headphones are fully charged. 3. Power Light: This light is blue when the transmitter is powered on.