A Novel Tool for Detection of Tissue and Cell Specific Marker Genes From
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

S41467-020-18249-3.Pdf
ARTICLE https://doi.org/10.1038/s41467-020-18249-3 OPEN Pharmacologically reversible zonation-dependent endothelial cell transcriptomic changes with neurodegenerative disease associations in the aged brain Lei Zhao1,2,17, Zhongqi Li 1,2,17, Joaquim S. L. Vong2,3,17, Xinyi Chen1,2, Hei-Ming Lai1,2,4,5,6, Leo Y. C. Yan1,2, Junzhe Huang1,2, Samuel K. H. Sy1,2,7, Xiaoyu Tian 8, Yu Huang 8, Ho Yin Edwin Chan5,9, Hon-Cheong So6,8, ✉ ✉ Wai-Lung Ng 10, Yamei Tang11, Wei-Jye Lin12,13, Vincent C. T. Mok1,5,6,14,15 &HoKo 1,2,4,5,6,8,14,16 1234567890():,; The molecular signatures of cells in the brain have been revealed in unprecedented detail, yet the ageing-associated genome-wide expression changes that may contribute to neurovas- cular dysfunction in neurodegenerative diseases remain elusive. Here, we report zonation- dependent transcriptomic changes in aged mouse brain endothelial cells (ECs), which pro- minently implicate altered immune/cytokine signaling in ECs of all vascular segments, and functional changes impacting the blood–brain barrier (BBB) and glucose/energy metabolism especially in capillary ECs (capECs). An overrepresentation of Alzheimer disease (AD) GWAS genes is evident among the human orthologs of the differentially expressed genes of aged capECs, while comparative analysis revealed a subset of concordantly downregulated, functionally important genes in human AD brains. Treatment with exenatide, a glucagon-like peptide-1 receptor agonist, strongly reverses aged mouse brain EC transcriptomic changes and BBB leakage, with associated attenuation of microglial priming. We thus revealed tran- scriptomic alterations underlying brain EC ageing that are complex yet pharmacologically reversible. -

Downloaded from the Ensembl Database) Using the BWA MEM Algorithm (Version
bioRxiv preprint doi: https://doi.org/10.1101/2020.02.17.953281; this version posted March 18, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 Identification of characteristic genomic markers in human hepatoma Huh7 and Huh7.5.1-8 2 cell lines 3 Masaki Kawamoto1, Toshiyuki Yamaji2, Kyoko Saito2, Kazuhiro Satomura3, Toshinori Endo3, 4 Masayoshi Fukasawa2, Kentaro Hanada2,*, and Naoki Osada3,4,* 5 1. Graduate School of Information Science and Technology, Hokkaido University, Sapporo 6 060-0814, Japan 7 2. Department of Biochemistry & Cell Biology, National Institute of Infectious Diseases, 8 Tokyo 162-8640, Japan 9 3. Faculty of Information Science and Technology, Hokkaido University, Sapporo 060-0814, 10 Japan 11 4. Global Station for Big Data and Cybersecurity, GI-CoRE, Hokkaido University, Sapporo 12 060-0814, Japan 13 14 *Correspondence 15 Kentaro Hanada 16 Email: [email protected] 17 Naoki Osada 18 Email: [email protected] 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.02.17.953281; this version posted March 18, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 19 Abstract 20 The human hepatoma-derived Huh7 cell line and its derivatives (Huh7.5 and Huh7.5.1) have been 21 widely used as a convenient experimental substitute for primary hepatocytes. -

Macropinocytosis Requires Gal-3 in a Subset of Patient-Derived Glioblastoma Stem Cells
ARTICLE https://doi.org/10.1038/s42003-021-02258-z OPEN Macropinocytosis requires Gal-3 in a subset of patient-derived glioblastoma stem cells Laetitia Seguin1,8, Soline Odouard2,8, Francesca Corlazzoli 2,8, Sarah Al Haddad2, Laurine Moindrot2, Marta Calvo Tardón3, Mayra Yebra4, Alexey Koval5, Eliana Marinari2, Viviane Bes3, Alexandre Guérin 6, Mathilde Allard2, Sten Ilmjärv6, Vladimir L. Katanaev 5, Paul R. Walker3, Karl-Heinz Krause6, Valérie Dutoit2, ✉ Jann N. Sarkaria 7, Pierre-Yves Dietrich2 & Érika Cosset 2 Recently, we involved the carbohydrate-binding protein Galectin-3 (Gal-3) as a druggable target for KRAS-mutant-addicted lung and pancreatic cancers. Here, using glioblastoma patient-derived stem cells (GSCs), we identify and characterize a subset of Gal-3high glio- 1234567890():,; blastoma (GBM) tumors mainly within the mesenchymal subtype that are addicted to Gal-3- mediated macropinocytosis. Using both genetic and pharmacologic inhibition of Gal-3, we showed a significant decrease of GSC macropinocytosis activity, cell survival and invasion, in vitro and in vivo. Mechanistically, we demonstrate that Gal-3 binds to RAB10, a member of the RAS superfamily of small GTPases, and β1 integrin, which are both required for macro- pinocytosis activity and cell survival. Finally, by defining a Gal-3/macropinocytosis molecular signature, we could predict sensitivity to this dependency pathway and provide proof-of- principle for innovative therapeutic strategies to exploit this Achilles’ heel for a significant and unique subset of GBM patients. 1 University Côte d’Azur, CNRS UMR7284, INSERM U1081, Institute for Research on Cancer and Aging (IRCAN), Nice, France. 2 Laboratory of Tumor Immunology, Department of Oncology, Center for Translational Research in Onco-Hematology, Swiss Cancer Center Léman (SCCL), Geneva University Hospitals, University of Geneva, Geneva, Switzerland. -

Actin Nucleator Spire 1 Is a Regulator of Ectoplasmic Specialization in the Testis Qing Wen1,Nanli1,Xiangxiao 1,2,Wing-Yeelui3, Darren S
Wen et al. Cell Death and Disease (2018) 9:208 DOI 10.1038/s41419-017-0201-6 Cell Death & Disease ARTICLE Open Access Actin nucleator Spire 1 is a regulator of ectoplasmic specialization in the testis Qing Wen1,NanLi1,XiangXiao 1,2,Wing-yeeLui3, Darren S. Chu1, Chris K. C. Wong4, Qingquan Lian5,RenshanGe5, Will M. Lee3, Bruno Silvestrini6 and C. Yan Cheng 1 Abstract Germ cell differentiation during the epithelial cycle of spermatogenesis is accompanied by extensive remodeling at the Sertoli cell–cell and Sertoli cell–spermatid interface to accommodate the transport of preleptotene spermatocytes and developing spermatids across the blood–testis barrier (BTB) and the adluminal compartment of the seminiferous epithelium, respectively. The unique cell junction in the testis is the actin-rich ectoplasmic specialization (ES) designated basal ES at the Sertoli cell–cell interface, and the apical ES at the Sertoli–spermatid interface. Since ES dynamics (i.e., disassembly, reassembly and stabilization) are supported by actin microfilaments, which rapidly converts between their bundled and unbundled/branched configuration to confer plasticity to the ES, it is logical to speculate that actin nucleation proteins play a crucial role to ES dynamics. Herein, we reported findings that Spire 1, an actin nucleator known to polymerize actins into long stretches of linear microfilaments in cells, is an important regulator of ES dynamics. Its knockdown by RNAi in Sertoli cells cultured in vitro was found to impede the Sertoli cell tight junction (TJ)-permeability barrier through changes in the organization of F-actin across Sertoli cell cytosol. Unexpectedly, Spire 1 knockdown also perturbed microtubule (MT) organization in Sertoli cells cultured in vitro. -

Applying Expression Profile Similarity for Discovery of Patient-Specific
bioRxiv preprint doi: https://doi.org/10.1101/172015; this version posted September 17, 2017. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Applying expression profile similarity for discovery of patient-specific functional mutations Guofeng Meng Partner Institute of Computational Biology, Yueyang 333, Shanghai, China email: [email protected] Abstract The progress of cancer genome sequencing projects yields unprecedented information of mutations for numerous patients. However, the complexity of mutation profiles of patients hinders the further understanding of mechanisms of oncogenesis. One basic question is how to uncover mutations with functional impacts. In this work, we introduce a computational method to predict functional somatic mutations for each of patient by integrating mutation recurrence with similarity of expression profiles of patients. With this method, the functional mutations are determined by checking the mutation enrichment among a group of patients with similar expression profiles. We applied this method to three cancer types and identified the functional mutations. Comparison of the predictions for three cancer types suggested that most of the functional mutations were cancer-type-specific with one exception to p53. By checking prediction results, we found that our method effectively filtered non-functional mutations resulting from large protein sizes. In addition, this methods can also perform functional annotation to each patient to describe their association with signalling pathways or biological processes. In breast cancer, we predicted "cell adhesion" and other mutated gene associated terms to be significantly enriched among patients. -
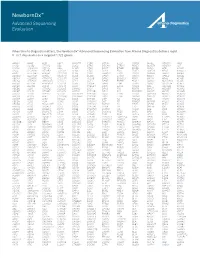
Cldn19 Clic2 Clmp Cln3
NewbornDx™ Advanced Sequencing Evaluation When time to diagnosis matters, the NewbornDx™ Advanced Sequencing Evaluation from Athena Diagnostics delivers rapid, 5- to 7-day results on a targeted 1,722-genes. A2ML1 ALAD ATM CAV1 CLDN19 CTNS DOCK7 ETFB FOXC2 GLUL HOXC13 JAK3 AAAS ALAS2 ATP1A2 CBL CLIC2 CTRC DOCK8 ETFDH FOXE1 GLYCTK HOXD13 JUP AARS2 ALDH18A1 ATP1A3 CBS CLMP CTSA DOK7 ETHE1 FOXE3 GM2A HPD KANK1 AASS ALDH1A2 ATP2B3 CC2D2A CLN3 CTSD DOLK EVC FOXF1 GMPPA HPGD K ANSL1 ABAT ALDH3A2 ATP5A1 CCDC103 CLN5 CTSK DPAGT1 EVC2 FOXG1 GMPPB HPRT1 KAT6B ABCA12 ALDH4A1 ATP5E CCDC114 CLN6 CUBN DPM1 EXOC4 FOXH1 GNA11 HPSE2 KCNA2 ABCA3 ALDH5A1 ATP6AP2 CCDC151 CLN8 CUL4B DPM2 EXOSC3 FOXI1 GNAI3 HRAS KCNB1 ABCA4 ALDH7A1 ATP6V0A2 CCDC22 CLP1 CUL7 DPM3 EXPH5 FOXL2 GNAO1 HSD17B10 KCND2 ABCB11 ALDOA ATP6V1B1 CCDC39 CLPB CXCR4 DPP6 EYA1 FOXP1 GNAS HSD17B4 KCNE1 ABCB4 ALDOB ATP7A CCDC40 CLPP CYB5R3 DPYD EZH2 FOXP2 GNE HSD3B2 KCNE2 ABCB6 ALG1 ATP8A2 CCDC65 CNNM2 CYC1 DPYS F10 FOXP3 GNMT HSD3B7 KCNH2 ABCB7 ALG11 ATP8B1 CCDC78 CNTN1 CYP11B1 DRC1 F11 FOXRED1 GNPAT HSPD1 KCNH5 ABCC2 ALG12 ATPAF2 CCDC8 CNTNAP1 CYP11B2 DSC2 F13A1 FRAS1 GNPTAB HSPG2 KCNJ10 ABCC8 ALG13 ATR CCDC88C CNTNAP2 CYP17A1 DSG1 F13B FREM1 GNPTG HUWE1 KCNJ11 ABCC9 ALG14 ATRX CCND2 COA5 CYP1B1 DSP F2 FREM2 GNS HYDIN KCNJ13 ABCD3 ALG2 AUH CCNO COG1 CYP24A1 DST F5 FRMD7 GORAB HYLS1 KCNJ2 ABCD4 ALG3 B3GALNT2 CCS COG4 CYP26C1 DSTYK F7 FTCD GP1BA IBA57 KCNJ5 ABHD5 ALG6 B3GAT3 CCT5 COG5 CYP27A1 DTNA F8 FTO GP1BB ICK KCNJ8 ACAD8 ALG8 B3GLCT CD151 COG6 CYP27B1 DUOX2 F9 FUCA1 GP6 ICOS KCNK3 ACAD9 ALG9 -

Involvement of the Kinesin Family Members KIF4A and KIF5C In
Downloaded from http://jmg.bmj.com/ on March 10, 2015 - Published by group.bmj.com Cognitive and behavioural genetics ORIGINAL ARTICLE Involvement of the kinesin family members KIF4A and KIF5C in intellectual disability and synaptic Editor’s choice Scan to access more free content function Marjolein H Willemsen,1,2 Wei Ba,1,3,4 Willemijn M Wissink-Lindhout,1 Arjan P M de Brouwer,1,2 Stefan A Haas,5 Melanie Bienek,6 Hao Hu,6 Lisenka E L M Vissers,1,2 Hans van Bokhoven,1,2,3,4 Vera Kalscheuer,6 Nael Nadif Kasri,1,2,3,4 Tjitske Kleefstra1,2 For numbered affiliations see ABSTRACT genes in the development and functioning of the end of article. Introduction Kinesin superfamily (KIF) genes encode nervous system. Mice with homozygous knockout Kif1a 1b 2a 3a 3b 4a 5a 5b Correspondence to motor proteins that have fundamental roles in brain mutations in , , , , , , and Dr Nael Nadif Kasri, functioning, development, survival and plasticity by show various neurological phenotypes including Department of Cognitive regulating the transport of cargo along microtubules structural brain anomalies, decreased brain size, Neuroscience, Radboud within axons, dendrites and synapses. Mouse knockout loss of neurons, reduced rate of neuronal apoptosis university medical center, studies support these important functions in the nervous and perinatal lethality due to neurological pro- Nijmegen, The Netherlands; 4–12 Nael.NadifKasri@radboudumc. system. The role of KIF genes in intellectual disability (ID) blems. The embryonic lethality of knockout nl; has so far received limited attention, although previous mice for Kif2a, Kif3a and 3b, and Kif5b suggest Dr Tjitske Kleefstra, studies have suggested that many ID genes impinge on that these Kif genes have an important function in Department of Human synaptic function. -

Single-Cell RNA-Seq Analysis of the Brainstem of Mutant SOD1 Mice Reveals Perturbed Cell Types and Pathways of Amyotrophic Lateral Sclerosis
HHS Public Access Author manuscript Author ManuscriptAuthor Manuscript Author Neurobiol Manuscript Author Dis. Author manuscript; Manuscript Author available in PMC 2020 September 26. Published in final edited form as: Neurobiol Dis. 2020 July ; 141: 104877. doi:10.1016/j.nbd.2020.104877. Single-cell RNA-seq analysis of the brainstem of mutant SOD1 mice reveals perturbed cell types and pathways of amyotrophic lateral sclerosis Wenting Liua, Sharmila Venugopala, Sana Majida, In Sook Ahna, Graciel Diamantea, Jason Honga, Xia Yanga,b,c,*, Scott H. Chandlera,b,* aDepartment of Integrative Biology & Physiology, University of California, 2024 Terasaki Bld, 610 Charles E. Young Dr. East, Los Angeles, USA bBrain Research Institute, University of California, Los Angeles, USA cInstitute for Quantitative and Computational Biosciences, University of California, Los Angeles, USA Abstract Amyotrophic lateral sclerosis (ALS) is a neurodegenerative disease in which motor neurons throughout the brain and spinal cord progressively degenerate resulting in muscle atrophy, paralysis and death. Recent studies using animal models of ALS implicate multiple cell-types (e.g., astrocytes and microglia) in ALS pathogenesis in the spinal motor systems. To ascertain cellular vulnerability and cell-type specific mechanisms of ALS in the brainstem that orchestrates oral-motor functions, we conducted parallel single cell RNA sequencing (scRNA-seq) analysis using the high-throughput Drop-seq method. We isolated 1894 and 3199 cells from the brainstem of wildtype and mutant SOD1 symptomatic mice respectively, at postnatal day 100. We recovered major known cell types and neuronal subpopulations, such as interneurons and motor neurons, and trigeminal ganglion (TG) peripheral sensory neurons, as well as, previously uncharacterized interneuron subtypes. -

Comparative Transcriptome Profiling of the Human and Mouse Dorsal Root Ganglia: an RNA-Seq-Based Resource for Pain and Sensory Neuroscience Research
bioRxiv preprint doi: https://doi.org/10.1101/165431; this version posted October 13, 2017. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Title: Comparative transcriptome profiling of the human and mouse dorsal root ganglia: An RNA-seq-based resource for pain and sensory neuroscience research Short Title: Human and mouse DRG comparative transcriptomics Pradipta Ray 1, 2 #, Andrew Torck 1 , Lilyana Quigley 1, Andi Wangzhou 1, Matthew Neiman 1, Chandranshu Rao 1, Tiffany Lam 1, Ji-Young Kim 1, Tae Hoon Kim 2, Michael Q. Zhang 2, Gregory Dussor 1 and Theodore J. Price 1, # 1 The University of Texas at Dallas, School of Behavioral and Brain Sciences 2 The University of Texas at Dallas, Department of Biological Sciences # Corresponding authors Theodore J Price Pradipta Ray School of Behavioral and Brain Sciences School of Behavioral and Brain Sciences The University of Texas at Dallas The University of Texas at Dallas BSB 14.102G BSB 10.608 800 W Campbell Rd 800 W Campbell Rd Richardson TX 75080 Richardson TX 75080 972-883-4311 972-883-7262 [email protected] [email protected] Number of pages: 27 Number of figures: 9 Number of tables: 8 Supplementary Figures: 4 Supplementary Files: 6 Word count: Abstract = 219; Introduction = 457; Discussion = 1094 Conflict of interest: The authors declare no conflicts of interest Patient anonymity and informed consent: Informed consent for human tissue sources were obtained by Anabios, Inc. (San Diego, CA). Human studies: This work was approved by The University of Texas at Dallas Institutional Review Board (MR 15-237). -

Site-Specific and Common Prostate Cancer Metastasis Genes
life Article Site-Specific and Common Prostate Cancer Metastasis Genes as Suggested by Meta-Analysis of Gene Expression Data Ivana Samaržija 1,2 1 Laboratory for Epigenomics, Division of Molecular Medicine, Ruder¯ Boškovi´cInstitute, Bijeniˇcka54, 10000 Zagreb, Croatia; [email protected] 2 Laboratory for Cell Biology and Signalling, Division of Molecular Biology, Ruder¯ Boškovi´cInstitute, Bijeniˇcka54, 10000 Zagreb, Croatia Abstract: Anticancer therapies mainly target primary tumor growth and little attention is given to the events driving metastasis formation. Metastatic prostate cancer, in comparison to localized disease, has a much worse prognosis. In the work presented here, groups of genes that are common to prostate cancer metastatic cells from bones, lymph nodes, and liver and those that are site-specific were delineated. The purpose of the study was to dissect potential markers and targets of anticancer therapies considering the common characteristics and differences in transcriptional programs of metastatic cells from different secondary sites. To that end, a meta-analysis of gene expression data of prostate cancer datasets from the GEO database was conducted. Genes with differential expression in all metastatic sites analyzed belong to the class of filaments, focal adhesion, and androgen receptor signaling. Bone metastases undergo the largest transcriptional changes that are highly enriched for the term of the chemokine signaling pathway, while lymph node metastasis show perturbation in signaling cascades. Liver metastases change the expression of genes in a way that is reminiscent of processes that take place in the target organ. Survival analysis for the common hub genes revealed Citation: Samaržija, I. Site-Specific involvements in prostate cancer prognosis and suggested potential biomarkers. -

Sperm Differentiation
International Journal of Molecular Sciences Review Sperm Differentiation: The Role of Trafficking of Proteins Maria E. Teves 1,* , Eduardo R. S. Roldan 2,*, Diego Krapf 3 , Jerome F. Strauss III 1 , Virali Bhagat 4 and Paulene Sapao 5 1 Department of Obstetrics and Gynecology, Virginia Commonwealth University, Richmond, VA 23298, USA; [email protected] 2 Department of Biodiversity and Evolutionary Biology, Museo Nacional de Ciencias Naturales (CSIC), 28006 Madrid, Spain 3 Department of Electrical and Computer Engineering, Colorado State University, Fort Collins, CO 80523, USA; [email protected] 4 Department of Physiology and Biophysics, Virginia Commonwealth University, Richmond, VA 23298, USA; [email protected] 5 Department of Chemistry, Virginia Commonwealth University, Richmond, VA 23298, USA; [email protected] * Correspondence: [email protected] (M.E.T.); [email protected] (E.R.S.R.) Received: 4 March 2020; Accepted: 20 May 2020; Published: 24 May 2020 Abstract: Sperm differentiation encompasses a complex sequence of morphological changes that takes place in the seminiferous epithelium. In this process, haploid round spermatids undergo substantial structural and functional alterations, resulting in highly polarized sperm. Hallmark changes during the differentiation process include the formation of new organelles, chromatin condensation and nuclear shaping, elimination of residual cytoplasm, and assembly of the sperm flagella. To achieve these transformations, spermatids have unique mechanisms for protein trafficking that operate in a coordinated fashion. Microtubules and filaments of actin are the main tracks used to facilitate the transport mechanisms, assisted by motor and non-motor proteins, for delivery of vesicular and non-vesicular cargos to specific sites.