A Generic Computer Platform for Efficient Iris Recognition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
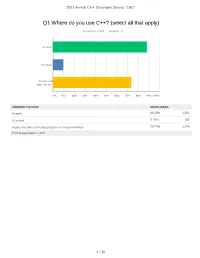
Q1 Where Do You Use C++? (Select All That Apply)
2021 Annual C++ Developer Survey "Lite" Q1 Where do you use C++? (select all that apply) Answered: 1,870 Skipped: 3 At work At school In personal time, for ho... 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES At work 88.29% 1,651 At school 9.79% 183 In personal time, for hobby projects or to try new things 73.74% 1,379 Total Respondents: 1,870 1 / 35 2021 Annual C++ Developer Survey "Lite" Q2 How many years of programming experience do you have in C++ specifically? Answered: 1,869 Skipped: 4 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 7.60% 142 3-5 years 20.60% 385 6-10 years 20.71% 387 10-20 years 30.02% 561 >20 years 21.08% 394 TOTAL 1,869 2 / 35 2021 Annual C++ Developer Survey "Lite" Q3 How many years of programming experience do you have overall (all languages)? Answered: 1,865 Skipped: 8 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 1.02% 19 3-5 years 12.17% 227 6-10 years 22.68% 423 10-20 years 29.71% 554 >20 years 34.42% 642 TOTAL 1,865 3 / 35 2021 Annual C++ Developer Survey "Lite" Q4 What types of projects do you work on? (select all that apply) Answered: 1,861 Skipped: 12 Gaming (e.g., console and.. -

Surveymonkey Analyze
C++ Developer Survey "Lite": 2018-08 -- C++ and Cloud Q1 This month we focus on how C++ is used, or could be better for use, in cloud-related applications and environments. In what (if any) kinds of cloud computing-related workloads do you use C++? (select all that apply) Answered: 198 Skipped: 5 1 / 20 C++ Developer Survey "Lite": 2018-08 -- C++ and Cloud None -- I don't use th... Communications (e.g.,... Machine learning, us... IoT / embedded (e.g., senso... Business (e.g., B2B,... Engineering (e.g.,... Developer tools (e.g.,... Artificial intelligence... Entertainment (e.g., sport... Financial (e.g., tradi... Consumer (e.g., retai... Gaming (e.g., cloud-based ... Automotive (e.g,... Frameworks (e.g., React... Productivity (e.g., note... Social and business... 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES None -- I don't use the cloud in any way in my C++ projects 35.86% 71 Communications (e.g., networking, email) 25.25% 50 Machine learning, using data to train software to learn patterns and make predictions (e.g., forecasting) 16.67% 33 IoT / embedded (e.g., sensors, embedded systems, home automation) 15.15% 30 Business (e.g., B2B, B2E) 12.63% 25 2 / 20 C++ Developer Survey "Lite": 2018-08 -- C++ and Cloud Engineering (e.g., avionics, power management) 12.63% 25 Developer tools (e.g., compilers, code editors) 9.60% 19 Artificial intelligence, software that works and reacts like humans (e.g., digital assistants) 9.09% 18 Entertainment (e.g., sports apps, video streaming) 9.09% 18 Financial (e.g., trading, mortgage, -

Using Qt Creator for Opencl - 05-25-2010 by Vincent - Streamcomputing
Using Qt Creator for OpenCL - 05-25-2010 by vincent - StreamComputing - http://streamcomputing.eu Using Qt Creator for OpenCL by vincent – Tuesday, May 25, 2010 http://streamcomputing.eu/blog/2010-05-25/using-qt-creator-for-opencl/ More and more ways are getting available to bring easy OpenCL to you. Most of the convenience libraries are wrappers for other languages, so it seems that C and C++ programmers have the hardest time. Since a while my favourite way to go is Qt: it is multi-platform, has a good IDE, is very extensive, has good multi-core and OpenGL-support and… has an extension for OpenCL: http://labs.trolltech.com/blogs/2010/04/07/using-opencl-with-qt http://blog.qt.digia.com/blog/2010/04/07/using-opencl-with-qt/ Other multi-platform choices are Anjuta, CodeLite, Netbeans and Eclipse. I will discuss them later, but wanted to give Qt an advantage because it also simplifies your OpenCL-development. While it is great for learning OpenCL-concepts, please know that the the commercial version of Qt Creator costs at least €2995,- a year. I must also warn the plugin is still in beta. StreamComputing.eu is not affiliated with Qt. Getting it all Qt Creator is available in most Linux-repositories: install packages ‘qtcreator’ and ‘qt4-qmake’. For Windows, MAC and the other Linux-distributions there are installers available: http://qt.nokia.com/downloads. People who are not familiar with Qt, really should take a look around on http://qt.nokia.com/. You can get the source for the plugin QtOpenCL, by using GIT: git clone http://git.gitorious.org/qt-labs/opencl.git QtOpenCL See http://qt.gitorious.org/qt-labs/opencl for more information about the status of the project. -

C++ Ide Download
C++ ide download click here to download An IDE for C/C++ developers with Mylyn integration. C/C++ Development Tools ; Eclipse Git Team Provider; Mylyn Task List; Remote Download Links. Download Dev-C++ for free. A free, portable, fast and simple C/C++ IDE. A new and improved fork of Bloodshed Dev-C++. NetBeans IDE - integrated tools for C and C++ developers. Docs & Support · Community · HOME · Download NetBeans NetBeans IDE includes project types for C and C++ and appropriate project templates. You can work with and create. Free Download Cevelop C++ IDE - Write and compile code by relying on this advanced Eclipse-based C++ IDE that packs a comprehensive. Code::Blocks is a free C, C++ and Fortran IDE built to meet the most demanding needs of its users. It is designed to be very extensible and fully configurable. In this article, we shall look at some of the best IDEs or code editors you can Download Your Free eBooks NOW - 10 Free Linux eBooks for. Download today. Full C and C++ IDE with Visual Studio Use MSBuild with the Microsoft Visual C++ compiler or a 3rd party toolset like. CodeLite is an open source, free, cross platform IDE specialized in C, C++, PHP and JavaScript (mainly for You can Download CodeLite for the following OSs. Download Turbo C++ for Windows 7, 8, and Windows 10 with full/window screen mode and many more extra feature. Installing a C++ IDE on Your Own PC. Steven J. Zeil Choose the appropriate binary for your PC operating system and download it. If you are. -

Towards Left Duff S Mdbg Holt Winters Gai Incl Tax Drupal Fapi Icici
jimportneoneo_clienterrorentitynotfoundrelatedtonoeneo_j_sdn neo_j_traversalcyperneo_jclientpy_neo_neo_jneo_jphpgraphesrelsjshelltraverserwritebatchtransactioneventhandlerbatchinsertereverymangraphenedbgraphdatabaseserviceneo_j_communityjconfigurationjserverstartnodenotintransactionexceptionrest_graphdbneographytransactionfailureexceptionrelationshipentityneo_j_ogmsdnwrappingneoserverbootstrappergraphrepositoryneo_j_graphdbnodeentityembeddedgraphdatabaseneo_jtemplate neo_j_spatialcypher_neo_jneo_j_cyphercypher_querynoe_jcypherneo_jrestclientpy_neoallshortestpathscypher_querieslinkuriousneoclipseexecutionresultbatch_importerwebadmingraphdatabasetimetreegraphawarerelatedtoviacypherqueryrecorelationshiptypespringrestgraphdatabaseflockdbneomodelneo_j_rbshortpathpersistable withindistancegraphdbneo_jneo_j_webadminmiddle_ground_betweenanormcypher materialised handaling hinted finds_nothingbulbsbulbflowrexprorexster cayleygremlintitandborient_dbaurelius tinkerpoptitan_cassandratitan_graph_dbtitan_graphorientdbtitan rexter enough_ram arangotinkerpop_gremlinpyorientlinkset arangodb_graphfoxxodocumentarangodborientjssails_orientdborientgraphexectedbaasbox spark_javarddrddsunpersist asigned aql fetchplanoriento bsonobjectpyspark_rddrddmatrixfactorizationmodelresultiterablemlibpushdownlineage transforamtionspark_rddpairrddreducebykeymappartitionstakeorderedrowmatrixpair_rddblockmanagerlinearregressionwithsgddstreamsencouter fieldtypes spark_dataframejavarddgroupbykeyorg_apache_spark_rddlabeledpointdatabricksaggregatebykeyjavasparkcontextsaveastextfilejavapairdstreamcombinebykeysparkcontext_textfilejavadstreammappartitionswithindexupdatestatebykeyreducebykeyandwindowrepartitioning -

Freeware-List.Pdf
FreeWare List A list free software from www.neowin.net a great forum with high amount of members! Full of information and questions posted are normally answered very quickly 3D Graphics: 3DVia http://www.3dvia.com...re/3dvia-shape/ Anim8or - http://www.anim8or.com/ Art Of Illusion - http://www.artofillusion.org/ Blender - http://www.blender3d.org/ CreaToon http://www.creatoon.com/index.php DAZ Studio - http://www.daz3d.com/program/studio/ Freestyle - http://freestyle.sourceforge.net/ Gelato - http://www.nvidia.co...ge/gz_home.html K-3D http://www.k-3d.org/wiki/Main_Page Kerkythea http://www.kerkythea...oomla/index.php Now3D - http://digilander.li...ng/homepage.htm OpenFX - http://www.openfx.org OpenStages http://www.openstages.co.uk/ Pointshop 3D - http://graphics.ethz...loadPS3D20.html POV-Ray - http://www.povray.org/ SketchUp - http://sketchup.google.com/ Sweet Home 3D http://sweethome3d.sourceforge.net/ Toxic - http://www.toxicengine.org/ Wings 3D - http://www.wings3d.com/ Anti-Virus: a-squared - http://www.emsisoft..../software/free/ Avast - http://www.avast.com...ast_4_home.html AVG - http://free.grisoft.com/ Avira AntiVir - http://www.free-av.com/ BitDefender - http://www.softpedia...e-Edition.shtml ClamWin - http://www.clamwin.com/ Microsoft Security Essentials http://www.microsoft...ity_essentials/ Anti-Spyware: Ad-aware SE Personal - http://www.lavasoft....se_personal.php GeSWall http://www.gentlesec...m/download.html Hijackthis - http://www.softpedia...ijackThis.shtml IObit Security 360 http://www.iobit.com/beta.html Malwarebytes' -

Sistem Operasi Teknik Dan Islami Stmik Sumedang (Sotiss)
SISTEM OPERASI TEKNIK DAN ISLAMI STMIK SUMEDANG (SOTISS) Esa Firmansyah Dosen Jurusan Teknik Informatika STMIK Sumedang Email : [email protected] ABSTRAK Perkembangan sistem operasi Linux berkembang pesat di dunia, termasuk di Indonesia. Berbagai lapisan masyarakat secara antusias mempelajari sistem operasi ini, bahkan terlibat langsung dalam pengembangannya. Begitu juga dengan mahasiswa STMIK Sumedang, namun ada kalanya mahasiswa merasa kesulitan karena aplikasi pada linux harus di update, terutama dengan aplikasi teknik. Penelitian ini bertujuan mengembangkan Linux Ubuntu menjadi Sistem Operasi Teknik dan Islami STMIK Sumedang (SOTISS). Adapun pengembangan system operasi tersebut menggunakan teknik Remastering. Hasil akhir dari penelitian ini berupa Sistem operasi open source yang dilengkapi dengan aplikasi- aplikasi teknik dan islami, sesuai dengan Visi dari STMIK Sumedang. Kata Kunci: Sistem Operasi, Open Source, Remastering, Aplikasi. PENDAHULUAN a. Latar Belakang Perkembangan sistem operasi Linux berkembang pesat di dunia, termasuk di Indonesia. Berbagai lapisan masyarakat secara antusias mempelajari sistem operasi ini, bahkan terlibat langsung dalam pengembangannya. Cara kerja dan penggunaan yang agak berbeda mungkin dirasakan oleh setiap pengguna Linux. Tidak sedikit masalah yang dihadapi, seperti instalasi software yang rumit, file multimedia tidak dapat diputar, serta sulitnya pemasangan perangkat baru seperti halnya modem. Namun hal tersebut tidak lagi menjadi masalah karena saat ini Linux telah memiliki package manager -

Introduzione Agli Ambienti Di Sviluppo MS Visual Studio 2005/2008/2010
Fondamenti di Informatica T-1 CdS Ingegneria Informatica Introduzione agli ambienti di sviluppo MS Visual Studio 2005/2008/2010 ... 2017 CodeLite 6.1.1 1 Outline • Solution/Workspace e Project • IDE e linguaggio C • Schermata principale • Aggiungere file a un progetto • Compilare ed eseguire un programma • Debug di un programma • Appendice A: “Che cosa fare se…” • Appendice B: “Creare un progetto per il C” • Appendice C: (VS2017 only) scanf deprecated...2 Solutions/Workspace e Projects • Nei moderni IDE ogni programma si sviluppa come un “progetto”… • Un progetto contiene tutte le informazioni utili/necessarie per realizzare il programma – Elenco dei file sorgenti che compongono quel programma – Opzioni particolari relative allo specifico progetto 3 Solutions/Workspace e Projects • A volte un programma “usa” funzionalità offerte da un altro programma • In tal caso, è utile avere due progetti separati (uno per ogni programma)… • … ma è utile anche raggruppare i programmi – secondo criteri di utilizzo (il programma A usa il programma B) – secondo criteri di affinità funzionali (i programmi A e B svolgono compiti molto simili) – secondo criteri di composizione (i programmi A e B condividono lo stesso componente) –… 4 Solutions/Workspace e Projects • Una Solution (termine Microsoft) o un Workspace (termine CodeLite ed Eclipse) è un insieme di progetti, raggruppati secondo qualche criterio o esigenza • Una Solution/Workspace è composta da: – uno o più progetti – opzioni particolari relative alla specifica solution • Vantaggi: – Riusabilità -
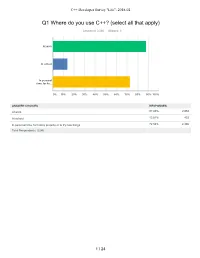
C++ Developer Survey "Lite": 2018-02
C++ Developer Survey "Lite": 2018-02 Q1 Where do you use C++? (select all that apply) Answered: 3,280 Skipped: 6 At work At school In personal time, for ho... 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES At work 87.93% 2,884 At school 13.81% 453 In personal time, for hobby projects or to try new things 72.56% 2,380 Total Respondents: 3,280 1 / 24 C++ Developer Survey "Lite": 2018-02 Q2 How many years of programming experience do you have in C++ specifically? Answered: 3,271 Skipped: 15 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 10.27% 336 3-5 years 20.85% 682 6-10 years 22.87% 748 10-20 years 30.63% 1,002 >20 years 15.38% 503 TOTAL 3,271 2 / 24 C++ Developer Survey "Lite": 2018-02 Q3 How many years of programming experience do you have overall (all languages)? Answered: 3,276 Skipped: 10 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 2.26% 74 3-5 years 11.66% 382 6-10 years 23.78% 779 10-20 years 33.55% 1,099 >20 years 28.75% 942 TOTAL 3,276 3 / 24 C++ Developer Survey "Lite": 2018-02 Q4 What types of projects do you work on? (select all that apply) Answered: 3,269 Skipped: 17 Business (e.g., B2B,.. -

List of Versions Added in ARL #2622
List of Versions added in ARL #2622 Publisher Product Version .NET Foundation Windows Installer XML 3.6 .NET Foundation Windows Installer XML 3.8 .NET Foundation WiX Toolset 3.8 .NET Foundation Windows Installer XML 3.7 /n software IP*Works! SSH 9.0 [den4b] Denis Kozlov ReNamer 6.2 [den4b] Denis Kozlov ReNamer 6.7 [den4b] Denis Kozlov ReNamer 6.9 [den4b] Denis Kozlov ReNamer 7.1 10x Genomics Loupe Browser 5.0 2BrightSparks SyncBackSE 9.1 2BrightSparks SyncBackFree 8.6 2BrightSparks SyncBackFree 9.0 2BrightSparks SyncBackFree 9.1 2BrightSparks SyncBackFree 9.2 2BrightSparks EncryptOnClick 2.1 2BrightSparks SyncBackPro 6.1 360 360 Total Security 10.6 3CX 3CXPhone 12.0 3CX 3CXPhone 15.0 3D Systems 3D Sprint 2.13 3D Systems 3D Sprint 2.5 3D Systems 3D Sprint 3.0 3D Systems Geomagic Control X 2020.0 3DP Chip 16.11 3M Detection Management Software 2.3 3T Software Labs Robo 3T 10.1 3T Software Labs Studio 3T 2021.3 3uTools 3uTools 2.31 3uTools 3uTools 2.32 3uTools 3uTools 2.33 3uTools 3uTools 2.36 3uTools 3uTools 2.37 3uTools 3uTools 2.38 3uTools 3uTools 2.39 3uTools 3uTools 2.50 3uTools 3uTools 2.51 3uTools 3uTools 2.53 3uTools 3uTools 2.56 4Team Sync2 2.83 4Team OST PST Viewer 1.12 4Team OST PST Viewer 1.22 8x8 Work for Desktop 7.3 8x8 Work for Desktop 7.4 8x8 Work for Desktop 7.5 8x8 Work for Desktop 7.6 8x8 Work for Desktop 7.7 A.N.D. Technologies Pcounter 2.85 A9Tech A9CAD 1.0 AbacusNext HotDocs Server Management Tools 10.2 AbacusNext HotDocs Server 10.2 ABB RobotStudio 2020.2 ABB RobotStudio 2020.4 ABB Drive composer pro 2.0 ABB Drive -

The Memec Hexapod Robot a Demonstration Platform
ISRN UTH-INGUTB-EX-E-2010/02-SE Examensarbete 15 hp September 2011 The Memec Hexapod Robot a demonstration platform Fredrik Persson Mattias Lindström Abstract The Memec Hexapod Fredrik Persson & Mattias Lindström Teknisk- naturvetenskaplig fakultet UTH-enheten This thesis shows how to replace a microcontroller unit (MCU) on a six legged robot, involving adapting hardware and developing software. The robot is based on the Besöksadress: mechanics from Lynxmotion’s Phoenix Hexapod Robot, which is a mechanical vehicle Ångströmlaboratoriet Lägerhyddsvägen 1 with 6 legs and 18 servos. The robot is controlled by two controller boards, which Hus 4, Plan 0 with available software can run pre-made movement sequences or be controlled by a Playstation2 hand controller. One of the controller boards needs to be replaced by Postadress: another more powerful MCU from another manufacturer. The new MCU comes Box 536 751 21 Uppsala from Avnet-Memec, which is a major emiconductor components distributor. They want to use the Hexapod Robot as a platform for demonstrating the capabilities of Telefon: the franchises on their line card to attract potential customer's interest and 018 – 471 30 03 awareness. The original Basic Atom Pro 28 MCU needs for that purpose to be Telefax: replaced with hardware from an Avnet-Memec franchise. Avnet-Memec has decided 018 – 471 30 00 to use the circuit board MBS270 from Mobisense Systems based on the ARM-processor Marvel PXA270 running Embedded Linux operating system. The Hemsida: project was successful and resulted in a Phoenix Hexapod Robot with a new more http://www.teknat.uu.se/student powerful and versatile MCU from an Avnet-Memec franchise. -
Working with the Digilent I/O Explorer USB
Working with the Digilent I/O Explorer USB This guide will be used as a reference for several lab experiences. Although the Explorer USB has many capabilities and can be used as a microprocessor, we will focus on three operations: 1. Analog input 2. Analog output 3. Encoder input We will use a simple software-based timing technique that will limit the sample rate that can be used in a reliable way. Faster rates are possible with the Explorer USB, but they require programming techniques beyond the scope of MCE484. The Explorer will be connected to the PC using a USB cable. We will write/modify programs to realize the 3 I/O operations. Programs will execute on the PC processor, not the Explorer. To do this, we will be using an open-source C++ compiler called CodeLite, which is equivalent to Microsoft Visual Studio, a paid program. Only a basic knowledge of programming techniques is required. The instructor will provide information on new concepts and C++ syntax as needed. 0. Basic connection and program compilation: Familiarize yourself with the Explorer board: a. Make sure you are not charged with static electricity before touching the board. You may discharge by touching a bare pipe or wearing an anti-static strap. b. Locate the mini USB connector, the ON/OFF power switch, the JE connector (upper- right relative to the logo) and the J1 connector (to the right of the logo). Also find the JP7 jumper and shift it to the 5V0 position (default is 3V3). This sets certain voltage levels to 5.0V instead of 3.3V.