Multilingual Conversation Ascii to Unicode in Indic Script
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

This Document Serves As a Summary of the UC Berkeley Script Encoding Initiative's Recent Activities. Proposals Recently Submit
L2/11‐049 TO: Unicode Technical Committee FROM: Deborah Anderson, Project Leader, Script Encoding Initiative, UC Berkeley DATE: 3 February 2011 RE: Liaison Report from UC Berkeley (Script Encoding Initiative) This document serves as a summary of the UC Berkeley Script Encoding Initiative’s recent activities. Proposals recently submitted to the UTC that have involved SEI assistance include: Afaka (Everson) [preliminary] Elbasan (Everson and Elsie) Khojki (Pandey) Khudawadi (Pandey) Linear A (Everson and Younger) [revised] Nabataean (Everson) Woleai (Everson) [preliminary] Webdings/Wingdings Ongoing work continues on the following: Anatolian Hieroglyphs (Everson) Balti (Pandey) Dhives Akuru (Pandey) Gangga Malayu (Pandey) Gondi (Pandey) Hungarian Kpelle (Everson and Riley) Landa (Pandey) Loma (Everson) Mahajani (Pandey) Maithili (Pandey) Manichaean (Everson and Durkin‐Meisterernst) Mende (Everson) Modi (Pandey) Nepali script (Pandey) Old Albanian alphabets Pahawh Hmong (Everson) Pau Cin Hau Alphabet and Pau Cin Hau Logographs (Pandey) Rañjana (Everson) Siyaq (and related symbols) (Pandey) Soyombo (Pandey) Tani Lipi (Pandey) Tolong Siki (Pandey) Warang Citi (Everson) Xawtaa Dorboljin (Mongolian Horizontal Square script) (Pandey) Zou (Pandey) Proposals for unencoded Greek papyrological signs, as well as for various Byzantine Greek and Sumero‐Akkadian characters are being discussed. A proposal for the Palaeohispanic script is also underway. Deborah Anderson is encouraging additional participation from Egyptologists for future work on Ptolemaic signs. She has received funding from the National Endowment for the Humanities and support from Google to cover work through 2011. . -

Internationalization in Ruby 2.4
Internationalization in Ruby 2.4 http://www.sw.it.aoyama.ac.jp/2016/pub/IUC40-Ruby2.4/ 40th Internationalization and Unicode Conference Santa Clara, California, U.S.A., November 3, 2016 Martin J. DÜRST [email protected] Aoyama Gakuin University © 2016 Martin J. Dürst, Aoyama Gakuin University Abstract Ruby is a purely object-oriented scripting language which is easy to learn for beginners and highly appreciated by experts for its productivity and depth. This presentation discusses the progress of adding internationalization functionality to Ruby for the version 2.4 release expected towards the end of 2016. One focus of the talk will be the currently ongoing implementation of locale-aware case conversion. Since Ruby 1.9, Ruby has a pervasive if somewhat unique framework for character encoding, allowing different applications to choose different internationalization models. In practice, Ruby is most often and most conveniently used with UTF-8. Support for internationalization facilities beyond character encoding has been available via various external libraries. As a result, applications may use conflicting and confusing ways to invoke internationalization functionality. To use case conversion as an example, up to version 2.3, Ruby comes with built-in methods for upcasing and downcasing strings, but these only work on ASCII. Our implementation extends this to the whole Unicode range for version 2.4, and efficiently reuses data already available for case-sensitive matching in regular expressions. We study the interface of internationalization functions/methods in a wide range of programming languages and Ruby libraries. Based on this study, we propose to extend the current built-in Ruby methods, e.g. -

Final Proposal for Encoding the Warang Citi Script in the SMP of The
JTC1/SC2/WG2 N4259 L2/12-118 2012-04-19 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Final proposal for encoding the Warang Citi script in the SMP of the UCS Source: UC Berkeley Script Encoding Initiative (Universal Scripts Project) Author: Michael Everson Status: Liaison Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N1958 (1999-01-29), N3411 (2008-04-08), N3668 (2009-08-05) Date: 2012-04-19 1. Introduction. The Warang Citi script is used to write the Ho language. Ho is a North Munda language, which family, together with the Mon-Khmer languages, makes up Austro-Asiatic. Warang Citi was devised by charismatic community leader Lako Bodra as part of a comprehensive cultural program, and was offered as an improvement over scripts used by Christian missionary linguists. Ho people live in the Indian states of Orissa and Jharkand. In Jharkand, they are found in Ranchi, Chaibasa and Jamshedpur, and in villages like Pardsa, Jaldhar, Tekasi, Tilupada, Baduri, Purtydigua, Roladih, Tupu Dana, Jetia, Dumbisai, Harira, Gitilpi, Karlajuri, Sarliburu, Narsana, Gidibas Kokcho, Lupungutu, Pandaveer, Jhinkapani, Kondwa. According to the SIL Ethnologue, there are 1,026,000 speakers of Ho. There are at present two publications in the script: a magazine Ho Sanagam (‘meeting’ from Hindi saṅgam), which comes out yearly and Kolhan Sakam, which comes out biweekly. Today, the Ho community can be characterized as still a primarily oral community, with an emergent literary tradition. Many Ho do not write their language in any form. -

ONIX for Books Codelists Issue 40
ONIX for Books Codelists Issue 40 23 January 2018 DOI: 10.4400/akjh All ONIX standards and documentation – including this document – are copyright materials, made available free of charge for general use. A full license agreement (DOI: 10.4400/nwgj) that governs their use is available on the EDItEUR website. All ONIX users should note that this is the fourth issue of the ONIX codelists that does not include support for codelists used only with ONIX version 2.1. Of course, ONIX 2.1 remains fully usable, using Issue 36 of the codelists or earlier. Issue 36 continues to be available via the archive section of the EDItEUR website (http://www.editeur.org/15/Archived-Previous-Releases). These codelists are also available within a multilingual online browser at https://ns.editeur.org/onix. Codelists are revised quarterly. Go to latest Issue Layout of codelists This document contains ONIX for Books codelists Issue 40, intended primarily for use with ONIX 3.0. The codelists are arranged in a single table for reference and printing. They may also be used as controlled vocabularies, independent of ONIX. This document does not differentiate explicitly between codelists for ONIX 3.0 and those that are used with earlier releases, but lists used only with earlier releases have been removed. For details of which code list to use with which data element in each version of ONIX, please consult the main Specification for the appropriate release. Occasionally, a handful of codes within a particular list are defined as either deprecated, or not valid for use in a particular version of ONIX or with a particular data element. -

Name Hierarchy Methods Enums and Flags
Pango::Gravity(3pm) User Contributed Perl Documentation Pango::Gravity(3pm) NAME Pango::Gravity − represents the orientation of glyphs in a segment of text HIERARCHY Glib::Enum +−−−−Pango::Gravity METHODS gravity = Pango::Gravity::get_for_matrix ($matrix) • $matrix (Pango::Matrix) gravity = Pango::Gravity::get_for_script ($script, $base_gravity, $hint) • $script (Pango::Script) • $base_gravity (Pango::Gravity) • $hint (Pango::GravityHint) boolean = Pango::Gravity::is_vertical ($gravity) • $gravity (Pango::Gravity) double = Pango::Gravity::to_rotation ($gravity) • $gravity (Pango::Gravity) ENUMS AND FLAGS enum Pango::Gravity • ’south’ / ’PANGO_GRAVITY_SOUTH’ • ’east’ / ’PANGO_GRAVITY_EAST’ • ’north’ / ’PANGO_GRAVITY_NORTH’ • ’west’ / ’PANGO_GRAVITY_WEST’ • ’auto’ / ’PANGO_GRAVITY_AUTO’ enum Pango::GravityHint • ’natural’ / ’PANGO_GRAVITY_HINT_NATURAL’ • ’strong’ / ’PANGO_GRAVITY_HINT_STRONG’ • ’line’ / ’PANGO_GRAVITY_HINT_LINE’ enum Pango::Script • ’invalid−code’ / ’PANGO_SCRIPT_INVALID_CODE’ • ’common’ / ’PANGO_SCRIPT_COMMON’ • ’inherited’ / ’PANGO_SCRIPT_INHERITED’ • ’arabic’ / ’PANGO_SCRIPT_ARABIC’ • ’armenian’ / ’PANGO_SCRIPT_ARMENIAN’ • ’bengali’ / ’PANGO_SCRIPT_BENGALI’ • ’bopomofo’ / ’PANGO_SCRIPT_BOPOMOFO’ • ’cherokee’ / ’PANGO_SCRIPT_CHEROKEE’ • ’coptic’ / ’PANGO_SCRIPT_COPTIC’ • ’cyrillic’ / ’PANGO_SCRIPT_CYRILLIC’ • ’deseret’ / ’PANGO_SCRIPT_DESERET’ • ’devanagari’ / ’PANGO_SCRIPT_DEVANAGARI’ • ’ethiopic’ / ’PANGO_SCRIPT_ETHIOPIC’ • ’georgian’ / ’PANGO_SCRIPT_GEORGIAN’ perl v5.28.0 2018-10-29 1 Pango::Gravity(3pm) User Contributed -

The Fontspec Package Font Selection for X LE ATEX and Lualatex
The fontspec package Font selection for X LE ATEX and LuaLATEX WILL ROBERTSON With contributions by Khaled Hosny, Philipp Gesang, Joseph Wright, and others. http://wspr.io/fontspec/ 2020/02/21 v2.7i Contents I Getting started 5 1 History 5 2 Introduction 5 2.1 Acknowledgements ............................... 5 3 Package loading and options 6 3.1 Font encodings .................................. 6 3.2 Maths fonts adjustments ............................ 6 3.3 Configuration .................................. 6 3.4 Warnings ..................................... 6 4 Interaction with LATEX 2ε and other packages 7 4.1 Commands for old-style and lining numbers ................. 7 4.2 Italic small caps ................................. 7 4.3 Emphasis and nested emphasis ......................... 7 4.4 Strong emphasis ................................. 7 II General font selection 8 1 Main commands 8 2 Font selection 9 2.1 By font name ................................... 9 2.2 By file name ................................... 10 2.3 By custom file name using a .fontspec file . 11 2.4 Querying whether a font ‘exists’ ........................ 12 1 3 Commands to select font families 13 4 Commands to select single font faces 13 4.1 More control over font shape selection ..................... 14 4.2 Specifically choosing the NFSS family ...................... 15 4.3 Choosing additional NFSS font faces ....................... 16 4.4 Math(s) fonts ................................... 17 5 Miscellaneous font selecting details 18 III Selecting font features 19 1 Default settings 19 2 Working with the currently selected features 20 2.1 Priority of feature selection ........................... 21 3 Different features for different font shapes 21 4 Selecting fonts from TrueType Collections (TTC files) 23 5 Different features for different font sizes 23 6 Font independent options 24 6.1 Colour ..................................... -

Overview and Rationale
Integration Panel: Maximal Starting Repertoire — MSR-5 Overview and Rationale REVISION – APRIL 06, 2021 – PUBLIC COMMENT Table of Contents 1 Overview 3 2 Maximal Starting Repertoire (MSR-5) 3 2.1 Files 3 2.1.1 Overview 3 2.1.2 Normative Definition 4 2.1.3 HTML Presentation 4 2.1.4 Code Charts 4 2.2 Determining the Contents of the MSR 5 2.3 Process of Deciding the MSR 6 3 Scripts 8 3.1 Comprehensiveness and Staging 8 3.2 What Defines a Related Script? 9 3.3 Separable Scripts 9 3.4 Deferred Scripts 9 3.5 Historical and Obsolete Scripts 9 3.6 Selecting Scripts and Code Points for the MSR 10 3.7 Scripts Appropriate for Use in Identifiers 10 3.8 Modern Use Scripts 11 3.8.1 Common and Inherited 12 3.8.2 Scripts included in MSR-1 12 3.8.3 Scripts added in MSR-2 12 3.8.4 Scripts added in MSR-3 through MSR-5 13 3.8.5 Modern Scripts Ineligible for the Root Zone 13 3.9 Scripts for Possible Future MSRs 13 3.10 Scripts Identified in UAX#31 as Not Suitable for identifiers 14 4 Exclusions of Individual Code Points or Ranges 16 4.1 Historic and Phonetic Extensions to Modern Scripts 16 4.2 Code Points That Pose Special Risks 17 4.3 Code Points with Strong Justification to Exclude 17 4.4 Code Points That May or May Not be Excludable from the Root Zone LGR 17 4.5 Non-spacing Combining Marks 18 Integration Panel: Maximal Starting Repertoire — MSR-3 Overview and Rationale 5 Discussion of Particular Code Points 20 5.1 Digits and Hyphen 20 5.2 CONTEXT O Code Points 21 5.3 CONTEXT J Code Points 21 5.4 Code Points Restricted for Identifiers 21 5.5 Compatibility -
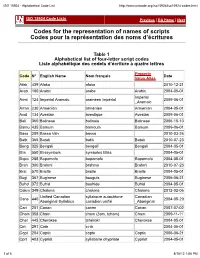
ISO 15924 - Alphabetical Code List
ISO 15924 - Alphabetical Code List http://www.unicode.org/iso15924/iso15924-codes.html ISO 15924 Code Lists Previous | RA Home | Next Codes for the representation of names of scripts Codes pour la représentation des noms d’écritures Table 1 Alphabetical list of four-letter script codes Liste alphabétique des codets d’écriture à quatre lettres Property Code N° English Name Nom français Date Value Alias Afak 439 Afaka afaka 2010-12-21 Arab 160 Arabic arabe Arabic 2004-05-01 Imperial Armi 124 Imperial Aramaic araméen impérial 2009-06-01 _Aramaic Armn 230 Armenian arménien Armenian 2004-05-01 Avst 134 Avestan avestique Avestan 2009-06-01 Bali 360 Balinese balinais Balinese 2006-10-10 Bamu 435 Bamum bamoum Bamum 2009-06-01 Bass 259 Bassa Vah bassa 2010-03-26 Batk 365 Batak batik Batak 2010-07-23 Beng 325 Bengali bengalî Bengali 2004-05-01 Blis 550 Blissymbols symboles Bliss 2004-05-01 Bopo 285 Bopomofo bopomofo Bopomofo 2004-05-01 Brah 300 Brahmi brahma Brahmi 2010-07-23 Brai 570 Braille braille Braille 2004-05-01 Bugi 367 Buginese bouguis Buginese 2006-06-21 Buhd 372 Buhid bouhide Buhid 2004-05-01 Cakm 349 Chakma chakma Chakma 2012-02-06 Unified Canadian syllabaire autochtone Canadian Cans 440 2004-05-29 Aboriginal Syllabics canadien unifié _Aboriginal Cari 201 Carian carien Carian 2007-07-02 Cham 358 Cham cham (čam, tcham) Cham 2009-11-11 Cher 445 Cherokee tchérokî Cherokee 2004-05-01 Cirt 291 Cirth cirth 2004-05-01 Copt 204 Coptic copte Coptic 2006-06-21 Cprt 403 Cypriot syllabaire chypriote Cypriot 2004-05-01 1 of 6 8/16/12 1:56 PM ISO -
Unibook Document
Title: Draft repertoire for DAM2 of ISO/IEC 10646:2012 (3rd edition) Date: 2012-10-25 L2/11- WG2 N4380 Source: Michel Suignard, project director Status: Project Editor's summary of the character repertoire addition as of October 25 2012 Action: For review by WG2 and UTC experts Distribution: WG2 and UTC Replaces: Status This document presents a summary of all characters that constitute the tentative repertoire of the amendment 2 to ISO/IEC 10646:2012, with code positions, representative glyphs and character names. In this document, the names and code positions are shown as currently approved by WG2 for the text of the forthcoming ballot. The purpose of this document is to allow WG2 delegates to review the character names, code positions and glyphs and notify the editor if they differ from what was approved in the meeting. A separate ballot document will be submitted by the project editor after the meeting. Manner of Presentation The character names and code points shown are the same for Unicode and ISO/IEC 10646, including annotations. In this document, the new characters are not shown in the context of the existing characters. The existing characters will be shown in the final ballot document or character names list. The occasional use of the word <reserved> in this draft is an artifact of the production process and should be ignored. Information about the status of a character proposal in WG2 and UTC as well as other information about the proposal is presented in a marginal note. Where a proposal refers to characters that are not in a single range, the information is repeated as necessary. -
Unicode Reference Lists: Other Script Sources
Other Script Sources File last updated October 2020 General ALA-LC Romanization Tables: Transliteration Schemes for Non-Roman Scripts, Approved by the Library of Congress and the American Library Association. Tables compiled and edited by Randall K. Barry. Washington, DC: Library of Congress, 1997. ISBN 0-8444-0940-5. Adlam Barry, Ibrahima Ishagha. 2006. Hè’lma wallifandè fin èkkitago’l bèbèrè Pular: Guide pra- tique pour apprendre l’alphabet Pulaar. Conakry, 2006. Ahom Barua, Bimala Kanta, and N.N. Deodhari Phukan. Ahom Lexicons, Based on Original Tai Manuscripts. Guwahati: Department of Historical and Antiquarian Studies, 1964. Hazarika, Nagen, ed. Lik Tai K hwam Tai (Tai letters and Tai words). Souvenir of the 8th Annual conference of Ban Ok Pup Lik Mioung Tai. Eastern Tai Literary Association, 1990. Kar, Babul. Tai Ahom Alphabet Book. Sepon, Assam: Tai Literature Associate, 2005. Alchemical Symbols Berthelot, Marcelin. Collection des anciens alchimistes grecs. 3 vols. Paris: G. Steinheil, 1888. Berthelot, Marcelin. La chimie au moyen âge. 3 vols. Osnabrück: O. Zeller, 1967. Lüdy-Tenger, Fritz. Alchemistische und chemische Zeichen. Würzburg: JAL-reprint, 1973. Schneider, Wolfgang. Lexikon alchemistisch-pharmazeutischer Symbole. Weinheim/Berg- str.: Verlag Chemie, 1962. Anatolian Hieroglyphs Hawkins, John David, and Halet Çambel. Corpus of Hieroglyphic Luwian Inscriptions. Ber- lin and New York: Walter de Gruyter, 2000. ISBN 3-11-010864-X. Herbordt, Suzanne. Die Prinzen- und Beamtensiegel der hethitischen Grossreichszeit auf Tonbullen aus dem Ni!antepe-Archiv in Hattusa. Mit Kommentaren zu den Siegelin- schriften und Hieroglyphen von J. David Hawkins. Mainz am Rhein: Verlag Philipp von Zabern, 2005. ISBN: 3-8053-3311-0. -
From Local Script to Global Standard
From Local Script to Global Standard The Lifecycle of a Script in Unicode SF Globalization MeetUp 3 August 2015 Deborah Anderson Anshuman Pandey Director, Script Encoding Initiative Post-Doctoral Researcher Department of Linguistics, UC-Berkeley Department of Linguistics, UC-Berkeley The Lifecycle of a Unicode Script • There are +100 scripts, symbol sets, and number blocks in Unicode • Transparent implementation of most into operating systems • As to be expected from a modern i18n and i10n perspective… • Nuts and bolts of script and language support also available • Code charts; fonts; and transliteration, collation, locale data • How is a Unicode standard for a script developed? Script Encoding Process: Overview 1. Users, linguists, others identify a script not yet encoded in Unicode/ISO 10646 standard 2. Research script and develop script proposal (often with revisions) 3. Two standards committees review proposals; may request changes; vote to approve or disapprove 4. Publication of script in Unicode/ISO 10646 standard 5. Create fonts, keyboards, update software SEI: Overview • Started 2002 in Department of Linguistics, UC Berkeley • Assists users with encoding characters and scripts into Unicode • Support: NEH (PR-50205), Google Research Award, other sources Script Encoding Process: Role of SEI 1. Users, linguists, others identify a script not yet encoded in Unicode/ISO 10646 standard SEI 2. Research script and develop script proposal (often with revisions) SEI 3. Two standards committees review proposals; may request changes; vote -
Section 13.4
The Unicode® Standard Version 12.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2019 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 12.0. Includes index. ISBN 978-1-936213-22-1 (http://www.unicode.org/versions/Unicode12.0.0/) 1.