Automatic Code Generation and Optimization of Multi-Dimensional Stencil Computations on Distributed- Memory Architectures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Ambitious Roadmap for City's South
4 nation MONDAY, MARCH 11, 2013 CHINA DAILY PLAN FOR BEIJING’S SOUTHERN AREA SOUND BITES I lived with my grandma during my childhood in an old community in the former Xuanwu district. When I was a kid we used to buy hun- dreds of coal briquettes to heat the room in the winter. In addition to the inconvenience of carry- ing those briquettes in the freezing winter, the rooms were sometimes choked with smoke when we lit the stove. In 2010, the government replaced the traditional coal-burning stoves with electric radiators in the community where grand- ma has spent most of her life. We also receive a JIAO HONGTAO / FOR CHINA DAILY A bullet train passes on the Yongding River Railway Bridge, which goes across Beijing’s Shijingshan, Fengtai and Fangshan districts and Zhuozhou in Hebei province. special price for electricity — half price in the morn- ing. Th is makes the cost of heating in the winter Ambitious roadmap for city’s south even less. Liang Wenchao, 30, a Beijing resident who works in the media industry Three-year plan has turned area structed in the past three years. In addition to the subway, six SOUTH BEIJING into a thriving commercial hub roads, spanning 167 km, are I love camping, especially also being built to connect the First phase of “South Beijing Three-year Plan” (2010-12) in summer and autumn. By ZHENG XIN product of the Fengtai, Daxing southern area with downtown, The “New South Beijing Three-year Plan” (2013-15) [email protected] We usually drive through and Fangshan districts is only including Jingliang Road and Achievements of the Plan for the next three 15 percent of the city’s total. -

Beijing Subway Map
Beijing Subway Map Ming Tombs North Changping Line Changping Xishankou 十三陵景区 昌平西山口 Changping Beishaowa 昌平 北邵洼 Changping Dongguan 昌平东关 Nanshao南邵 Daoxianghulu Yongfeng Shahe University Park Line 5 稻香湖路 永丰 沙河高教园 Bei'anhe Tiantongyuan North Nanfaxin Shimen Shunyi Line 16 北安河 Tundian Shahe沙河 天通苑北 南法信 石门 顺义 Wenyanglu Yongfeng South Fengbo 温阳路 屯佃 俸伯 Line 15 永丰南 Gonghuacheng Line 8 巩华城 Houshayu后沙峪 Xibeiwang西北旺 Yuzhilu Pingxifu Tiantongyuan 育知路 平西府 天通苑 Zhuxinzhuang Hualikan花梨坎 马连洼 朱辛庄 Malianwa Huilongguan Dongdajie Tiantongyuan South Life Science Park 回龙观东大街 China International Exhibition Center Huilongguan 天通苑南 Nongda'nanlu农大南路 生命科学园 Longze Line 13 Line 14 国展 龙泽 回龙观 Lishuiqiao Sunhe Huoying霍营 立水桥 Shan’gezhuang Terminal 2 Terminal 3 Xi’erqi西二旗 善各庄 孙河 T2航站楼 T3航站楼 Anheqiao North Line 4 Yuxin育新 Lishuiqiao South 安河桥北 Qinghe 立水桥南 Maquanying Beigongmen Yuanmingyuan Park Beiyuan Xiyuan 清河 Xixiaokou西小口 Beiyuanlu North 马泉营 北宫门 西苑 圆明园 South Gate of 北苑 Laiguangying来广营 Zhiwuyuan Shangdi Yongtaizhuang永泰庄 Forest Park 北苑路北 Cuigezhuang 植物园 上地 Lincuiqiao林萃桥 森林公园南门 Datunlu East Xiangshan East Gate of Peking University Qinghuadongluxikou Wangjing West Donghuqu东湖渠 崔各庄 香山 北京大学东门 清华东路西口 Anlilu安立路 大屯路东 Chapeng 望京西 Wan’an 茶棚 Western Suburban Line 万安 Zhongguancun Wudaokou Liudaokou Beishatan Olympic Green Guanzhuang Wangjing Wangjing East 中关村 五道口 六道口 北沙滩 奥林匹克公园 关庄 望京 望京东 Yiheyuanximen Line 15 Huixinxijie Beikou Olympic Sports Center 惠新西街北口 Futong阜通 颐和园西门 Haidian Huangzhuang Zhichunlu 奥体中心 Huixinxijie Nankou Shaoyaoju 海淀黄庄 知春路 惠新西街南口 芍药居 Beitucheng Wangjing South望京南 北土城 -

CRCT) First and Only China Shopping Mall S-REIT
CAPITARETAIL CHINA TRUST (CRCT) First and Only China Shopping Mall S-REIT Proposed Acquisition of Grand Canyon Mall (首地大峡谷) Proposed Acquisition15 ofJuly Grand Canyon 2013 Mall *15 July 2013* Disclaimer This presentation may contain forward-looking statements that involve assumptions, risks and uncertainties. Actual future performance, outcomes and results may differ materially from those expressed in forward-looking statements as a result of a number of risks, uncertainties and assumptions. Representative examples of these factors include (without limitation) general industry and economic conditions, interest rate trends, cost of capital and capital availability, competition from other developments or companies, shifts in expected levels of occupancy rate, property rental income, charge out collections, changes in operating expenses (including employee wages, benefits and training costs), governmental and public policy changes and the continued availability of financing in the amounts and the terms necessary to support future business. You are cautioned not to place undue reliance on these forward-looking statements, which are based on the current view of management on future events. The information contained in this presentation has not been independently verified. No representation or warranty expressed or implied is made as to, and no reliance should be placed on, the fairness, accuracy, completeness or correctness of the information or opinions contained in this presentation. Neither CapitaRetail China Trust Management Limited (the “Manager”) or any of its affiliates, advisers or representatives shall have any liability whatsoever (in negligence or otherwise) for any loss howsoever arising, whether directly or indirectly, from any use, reliance or distribution of this presentation or its contents or otherwise arising in connection with this presentation. -

China Railway Signal & Communication Corporation
Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited take no responsibility for the contents of this announcement, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this announcement. China Railway Signal & Communication Corporation Limited* 中國鐵路通信信號股份有限公司 (A joint stock limited liability company incorporated in the People’s Republic of China) (Stock Code: 3969) ANNOUNCEMENT ON BID-WINNING OF IMPORTANT PROJECTS IN THE RAIL TRANSIT MARKET This announcement is made by China Railway Signal & Communication Corporation Limited* (the “Company”) pursuant to Rules 13.09 and 13.10B of the Rules Governing the Listing of Securities on The Stock Exchange of Hong Kong Limited (the “Listing Rules”) and the Inside Information Provisions (as defined in the Listing Rules) under Part XIVA of the Securities and Futures Ordinance (Chapter 571 of the Laws of Hong Kong). From July to August 2020, the Company has won the bidding for a total of ten important projects in the rail transit market, among which, three are acquired from the railway market, namely four power integration and the related works for the CJLLXZH-2 tender section of the newly built Langfang East-New Airport intercity link (the “Phase-I Project for the Newly-built Intercity Link”) with a tender amount of RMB113 million, four power integration and the related works for the XJSD tender section of the newly built -

Public Protests Against the Beijing-Shenyang High-Speed Railway in China
Public protests against the Beijing-Shenyang high-speed railway in China He, G., Mol, A. P. J., & Lu, Y. This article is made publically available in the institutional repository of Wageningen University and Research, under article 25fa of the Dutch Copyright Act, also known as the Amendment Taverne. Article 25fa states that the author of a short scientific work funded either wholly or partially by Dutch public funds is entitled to make that work publicly available for no consideration following a reasonable period of time after the work was first published, provided that clear reference is made to the source of the first publication of the work. For questions regarding the public availability of this article, please contact [email protected]. Please cite this publication as follows: He, G., Mol, A. P. J., & Lu, Y. (2016). Public protests against the Beijing-Shenyang high-speed railway in China. Transportation Research. Part D, Transport and Environment, 43, 1-16. DOI: 10.1016/j.trd.2015.11.009 You can download the published version at: https://doi.org/10.1016/j.trd.2015.11.009 Transportation Research Part D 43 (2016) 1–16 Contents lists available at ScienceDirect Transportation Research Part D journal homepage: www.elsevier.com/locate/trd Public protests against the Beijing–Shenyang high-speed railway in China ⇑ Guizhen He a,b, , Arthur P.J. Mol c, Yonglong Lu a a State Key Laboratory of Urban and Regional Ecology, Research Centre for Eco-Environmental Sciences, Chinese Academy of Sciences, Beijing 100085, China b The Earth Institute, Columbia University, New York, NY 10027, USA c Environmental Policy Group, Wageningen University, Hollandseweg 1, 6706 KN Wageningen, The Netherlands article info abstract Article history: With the rapid expansion of the high-speed railway infrastructure in China, conflicts arise Available online 29 December 2015 between the interests of local citizens living along the planned tracks and the national interests of governmental authorities and project developers. -

Safety-First Culture Bringing MTR to Continuous & Global Excellence
Safety-First Culture Bringing MTR to Continuous & Global Excellence Dr. Jacob Kam Managing Director – Operations & Mainland Business 23 October 2017 Agenda ▪ Introducing MTR ▪ Safety First Culture ▪ Global Operational Safety ▪ Future Challenges MTR Corporation 1/15/2018 Page 2 MTR Operations in Hong Kong Heavy Rail Airport Express Light Rail Intercity Guangzhou-Shenzhen- Bus Hong Kong Express Rail Link To be opened in Q3 2018 MTR Corporation 1/15/2018 Page 3 MTR Network in HK is Expanding 1980 * 2016 Total Route Length in HK 14.8x 15.6 km 230.9 km MTR established in 1975 2 rail projects completed in 2016; MTR is present in all 18 districts in Hong Kong 2 rail projects totally 43km under construction * First network (Modified Initial System) commenced Source: MTR Sustainability Report in 1979 with its full line opening in 1980. MTR Corporation 1/15/2018 Page 4 MTR Network in HK is Expanding Source: MTR Annual Report 2016 MTR Corporation 1/15/2018 Page 5 MTR Network outside HK is also Expanding 2004 2016 Global Network 13.5x 88 km 1,192 km Stockholm Metro (MTR Tunnelbanen) MTR Tech (renamed from TBT) London Crossrail Stockholm Commuter Rail (MTR Pendeltågen) EM Tech AB South Western Railway MTR Express Beijing Line 4 Beijing Daxing Line Beijing Line 14 Beijing Line 16 (Phase 2 Sweden under construction) UK Beijing Hangzhou Line 1 + Extension Hangzhou Hangzhou Line 5 (being constructed) Shenzhen Shenzhen Line 4 Sydney Sydney Metro Northwest Melbourne As of 30 Jun 2017 Average Weekday Patronage Route Length (in operation) Mainland of China & Metro Trains Melbourne 5.79 M >2,000 km* International MTR Corporation 1/15/2018 Page 6 MTR Corporation 1/15/2018 Page 7 MTR Runs Very Well in HK – Safety Performance achieved a high level and continuous improvement in Operational Safety worse Fatalities per Billion Passenger Journeys better include suicide, accidents & illegal activities, 10-year average Source : CoMET 2016 Interim KPI Database AS – Asian Metros NA – North American Metros (2015 data). -

Model 4200A Prober and External Instrument Control
tek.com/keithley Model 4200A-SCS Prober and External Instrument Control 4200A-913-01 Rev. A December 2020 *P4200A-913-01A* 4200A-913-01A Model 4200A-SCS Prober and External Instrument Control © 2020, Keithley Instruments Cleveland, Ohio, U.S.A. All rights reserved. Any unauthorized reproduction, photocopy, or use of the information herein, in whole or in part, without the prior written approval of Keithley Instruments is strictly prohibited. All Keithley Instruments product names are trademarks or registered trademarks of Keithley Instruments, LLC. Other brand names are trademarks or registered trademarks of their respective holders. Actuate® Copyright © 1993-2003 Actuate Corporation. All Rights Reserved. Microsoft, Visual C++, Excel, and Windows are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. Document number: 4200A-913-01 Rev. A December 2020 Safety precautions The following safety precautions should be observed before using this product and any associated instrumentation. Although some instruments and accessories would normally be used with nonhazardous voltages, there are situations where hazardous conditions may be present. This product is intended for use by personnel who recognize shock hazards and are familiar with the safety precautions required to avoid possible injury. Read and follow all installation, operation, and maintenance information carefully before using the product. Refer to the user documentation for complete product specifications. If the product is used in a manner not specified, the protection provided by the product warranty may be impaired. The types of product users are: Responsible body is the individual or group responsible for the use and maintenance of equipment, for ensuring that the equipment is operated within its specifications and operating limits, and for ensuring that operators are adequately trained. -

PPP Case Studies – People's Republic of China
1 PPP Case Studies People’s Republic of China Craig Sugden, Principal PPP Specialist East Asia Department 13 May 2015 The views expressed in this presentation are the views of the author and do not necessarily reflect the views or policies of the Asian Development Bank Institute (ADBI), the Asian Development Bank (ADB), its Board of Directors, or the governments they represent. ADBI does not guarantee the accuracy of the data included in this paper and accepts no responsibility for any consequences of their use. Terminology used may not necessarily be consistent with ADB official terms. 2 Background PPP Case Studies: the PRC PRC’s PPP projects 3 EIU’s 1,186 infrastructure PPPs finalised in the Infrascope PRC from 1990 to 2014 highlighted the PRC’s Compared to 838 in India, 126 in the Philippines, 108 in Indonesia, 73 in Sri Lanka, “phenomenal” 65 in Bangladesh wealth of project 648 active PPPs in the UK, 567 in the experience Republic of Korea, 127 in Australia (as of 2013) Source: World Bank. 2015. Private Participation in Infrastructure Projects Database and Burger P. and I. Hawkesworth. 2013. Capital Budgeting and Procurement Practices. Organization for Economic Cooperation and Development. Paris. PPP Case Studies: the PRC PPP activity in the PRC 4 Note: Excludes projects that are led by a majority-state owned enterprise Source: World Bank PIAF Database and IMF PPP Case Studies: the PRC Case studies 5 • Beijing Subway Line 4 The PRC has • Shanghai Huadian Xinzhuang Industrial Park combined cycle heat and power project • Baiyinchagan-Yongtaigong -

【欧州】【鉄道】 Road/Railways – Autonomous Driving Vehicles: The
【欧州】【鉄道】 Road/Railways – autonomous driving vehicles: The development of driverless and autonomous trains – SNCF plans semi-autonomous trains to enter market in 2020 Andrea Antolini Former Researcher JTTRI 【概要:Summary】 supplied by Bombardier NUG Propulsion System (BNP), The development of autonomous transportation systems the company’s Chinese joint venture. has become a major aspect of the further development Also in Europe, there is an increasing interest in for several transport modes, including train systems. train automation. The challenge for automating train In recent years, railways have made important operations in Europe will be to adapt it to a railway advances in the development of driverless and system, in which there exist multiple freight and autonomous trains. There are currently around 42 passenger operators, which share the same tracks for cities in the world that run fully automated train the utilisation of different train types. There are lines. More than half of the existing 64 fully also numerous junctions and yards as well as links to automated lines worldwide are located in Asia. China industrial plants. Nevertheless, in several EU alone intends to operate 32 fully automated train countries, research continues on remotely controlled, lines by 2022. autonomous trains. In France, the French National The Automatic Train Operation (ATO) covers different Railways SNCF completed its first test run with a levels of automation; from the driver still remotely controlled locomotive-hauled autonomous maintaining control of most functions; train in July 2019, as part of a project to develop semi-automatic train operation of Grade-of- driverless passenger and freight train prototypes by Automation (GoA) level 2 to GoA 4, where there is no 2022. -

MTR's Experiences in PPP for Railway Projects
MTR’s Experiences in PPP for Railway Projects Dr Jacob Kam Managing Director – Operations & Mainland Business 11 May 2017 MTR Businesses in China and Overseas 港铁公司在国内及海外的铁路业务 Line 4 & Daxing Line 1.881 Mil Line 14, Line 16 113.4 km Elizabeth Line Stockholm Metro 14.2k 1.228 mil 32.5 km 110km South Western rail Contract started MTR Express Hangzhou Metro Line 537k 53.7km from Aug 2017 455km(shared track) 1 and Ext Shenzhen Metro 550k Stockholm Hong Kong MTR Line 4 and Ext Commuter rail 20.5km 8.6 mil 34.3k 266 km 241 km Sydney Metro 36 km North West Under construction Melbourne Metro • Over 1,200km route length (exclude shared track) • Over 14 Million Passenger trips per weekday (using line based counting) 812k • Line based passenger trips do not match with the passenger trip data in annual report 390km MTR Corporation 5/16/2017 Page 2 Why cities need railways? • High capacity • High energy efficiency, low carbon emission In persons per hour in both direction Source: UITP MTR Corporation 5/16/2017 Page 3 Why cities need railways? Effective land use Modal Bus Rapid Bus Tram Light Rail Metro Characteristics Transit Max Flow 2,500 6,000 12,000 18,000 30,000 & above (per hour per direction) Average speed 10-14 15-22 15-22 18-40 18-40 (kph) Reliability Improving Good Medium to Good Good Very Good Mixed running Largely Road-space Mixed running Totally segregated and on-road tram segregated Totally segregated with traffic alignment Allocation lanes alignments All underground: Land Consumed 15 – 25 times 10 – 15 times 5 – 10 times 3 – 6 times 1 -
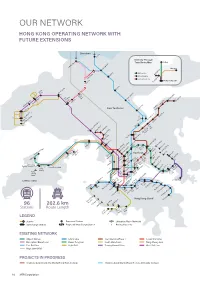
Our Network Hong Kong Operating Network with Future Extensions
OUR NETWORK HONG KONG OPERATING NETWORK WITH FUTURE EXTENSIONS Shenzhen Lo Wu Intercity Through Train Route Map Beijing hau i C Lok Ma Shanghai Sheung Shu g Beijing Line Guangzhou Fanlin Shanghai Line Kwu Tung Guangdong Line n HONG KONG SAR Dongguan San Ti Tai Wo Long Yuen Long t Ping 48 41 47 Ngau a am Tam i Sh i K Mei a On Shan a Tai Po Marke 36 K Sheungd 33 M u u ui Wa W Roa Au Tau Tin Sh 49 Heng On y ui Hung Shui Ki g ng 50 New Territories Tai Sh Universit Han Siu Ho 30 39 n n 27 35 Shek Mu 29 Tuen Mu cecourse* e South Ra o Tan Area 16 F 31 City On Tuen Mun n 28 a n u Sha Ti Sh n Ti 38 Wai Tsuen Wan West 45 Tsuen05 Wa Tai Wo Ha Che Kung 40 Temple Kwai Hing 07 i 37 Tai Wa Hin Keng 06 l Kwai Fong o n 18 Mei Fo k n g Yi Diamond Hil Kowloon Choi Wa Tsin Tong n i King Wong 25 Shun Ti La Lai Chi Ko Lok Fu d Tai Si Choi Cheung Sha Wan Hung Sau Mau Ping ylan n ay e Sham Shui Po ei Kowloon ak u AsiaWorld-Expo B 46 ShekM T oo Po Tat y Disn Resort m Po Lam Na Kip Kai k 24 Kowl y Sunn eong g Hang Ha Prince n Ba Ch o Sungong 01 53 Airport M Mong W Edward ok ok East 20 K K Toi ong 04 To T Ho Kwa Ngau Tau Ko Cable Car n 23 Olympic Yau Mai Man Wan 44 n a Kwun Ti Ngong Ping 360 19 52 42 n Te Ti 26 Tung Chung East am O 21 L Tung Austi Yau Tong Tseung Chung on Whampo Kwan Tung o n Jordan Tiu g Kowl loo Tsima Hung 51 Ken Chung w Sh Hom Leng West Hong Kong Tsui 32 t Tsim Tsui West Ko Eas 34 22 ha Fortress10 Hill Hong r S ay LOHAS Park ition ew 09 Lantau Island ai Ying Pun Kong b S Tama xhi aus North h 17 11 n E C y o y Centre Ba Nort int 12 16 Po 02 Tai -

Asia Infrastructure, Energy and Natural Resources (IEN)
Asia Infrastructure, Energy and Natural Resources (IEN) Slaughter and May is a leading international firm with a worldwide corporate, commercial and financing practice. We provide clients with a professional service of the highest quality combining technical excellence and commercial awareness and a practical, constructive approach to legal services. We advise on the full range of matters for infrastructure, energy and natural resources clients in Asia, including projects, mergers and acquisitions, all forms of financing, competition and regulatory, tax, commercial, trading, construction, operation and maintenance contracts as well as general commercial and corporate advice. Our practice is divided into three key practice areas: – Infrastructure – rail and road; ports and airports; logistics; water and waste management. – Energy – power and renewables; oil and gas. – Mining and Minerals – coal, metals and minerals. For each regional project we draw on long‑standing relationships with leading independent law firms in Asia. This brings together individuals from the relevant countries to provide the optimum legal expertise for that particular transaction. This allows us to deliver a first class pan‑Asian and global seamless legal service of the highest quality. Recommended by clients for project agreements and ‘interfacing with government bodies’, Slaughter and May’s team is best-known for its longstanding advice to MTR on some of Hong Kong’s key infrastructure mandates. Projects and Energy – Legal 500 Asia Pacific Infrastructure – rail MTR Corporation Limited – we have advised the • Tseung Kwan O Line: The 11.9‑kilometre MTR Corporation Limited (MTR), a long‑standing Tseung Kwan O Line has 8 stations and links client of the firm and one of the Hong Kong office’s the eastern part of Hong Kong Island with the first clients, on many of its infrastructure and eastern part of Kowloon other projects, some of which are considered to be amongst the most significant projects to be • Disney Resort Line: The 3.3‑kilometre Disney undertaken in Hong Kong.