Auditory and Audiovisual Close-Shadowing in Post-Lingually Deaf Cochlear-Implanted Patients and Normal-Hearing Elderly Adults
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Guide to Sensory Processing.Pdf
Guide to Sensory Processing Prepared by Allison Travnik, MSOTS Level II Fieldwork Student Project Kavitha N Krishnan MS OTR/L Fieldwork Instructor Sensory Processing In order to understand what is going on around us, we need to organize all of the incoming sensory information (Ayres, 2005). The sensory information involves what we see, smell, taste, hear, feel on our body, where our body is in relation to others, and how well we are balanced. This is a lot of information that our brains need to process in order to engage in productive behavior, learn, and form accurate perceptions. Proprioceptive Where are body is in space Tactile Auditory What we feel The noise on our skin around us Sensory Smell Processing The Sight difference What we see scents around us around us Oral Sensory Processing Vestibular The sensations Jean Ayres developed the sensory Our sense of Disorder + balance that food give integration (SI) theory. SI gives us in our mouth meaning to what our senses are recognizing. When the sensations are not being organized properly may notice some of the same qualities in the brain, Ayres compared it to about yourself.It is important to a traffic jam. The traffic jam of remember that everyone has some sensory information can lead to quirks about their sensory processing learning difficulties and problem whether it be a sensitivity to loud behavior (Ayres, 2005). Children noises or dislike of light touch. with Sensory Processing Disorder However the identification of SPD is (SPD) are struggling with this reserved for individuals whose traffic jam. sensory quirks are outside of the Sensory processing is a typical range and affect their daily dynamic and complex theory. -

Perforated Eardrum
Vinod K. Anand, MD, FACS Nose and Sinus Clinic Perforated Eardrum A perforated eardrum is a hole or rupture m the eardrum, a thin membrane which separated the ear canal and the middle ear. The medical term for eardrum is tympanic membrane. The middle ear is connected to the nose by the eustachian tube. A perforated eardrum is often accompanied by decreased hearing and occasional discharge. Paih is usually not persistent. Causes of Eardrum Perforation The causes of perforated eardrum are usually from trauma or infection. A perforated eardrum can occur: if the ear is struck squarely with an open hand with a skull fracture after a sudden explosion if an object (such as a bobby pin, Q-tip, or stick) is pushed too far into the ear canal. as a result of hot slag (from welding) or acid entering the ear canal Middle ear infections may cause pain, hearing loss and spontaneous rupture (tear) of the eardrum resulting in a perforation. In this circumstance, there may be infected or bloody drainage from the ear. In medical terms, this is called otitis media with perforation. On rare occasions a small hole may remain in the eardrum after a previously placed P.E. tube (pressure equalizing) either falls out or is removed by the physician. Most eardrum perforations heal spontaneously within weeks after rupture, although some may take up to several months. During the healing process the ear must be protected from water and trauma. Those eardrum perforations which do not heal on their own may require surgery. Effects on Hearing from Perforated Eardrum Usually, the larger the perforation, the greater the loss of hearing. -

Understanding Sensory Processing: Looking at Children's Behavior Through the Lens of Sensory Processing
Understanding Sensory Processing: Looking at Children’s Behavior Through the Lens of Sensory Processing Communities of Practice in Autism September 24, 2009 Charlottesville, VA Dianne Koontz Lowman, Ed.D. Early Childhood Coordinator Region 5 T/TAC James Madison University MSC 9002 Harrisonburg, VA 22807 [email protected] ______________________________________________________________________________ Dianne Koontz Lowman/[email protected]/2008 Page 1 Looking at Children’s Behavior Through the Lens of Sensory Processing Do you know a child like this? Travis is constantly moving, pushing, or chewing on things. The collar of his shirt and coat are always wet from chewing. When talking to people, he tends to push up against you. Or do you know another child? Sierra does not like to be hugged or kissed by anyone. She gets upset with other children bump up against her. She doesn’t like socks with a heel or toe seam or any tags on clothes. Why is Travis always chewing? Why doesn’t Sierra liked to be touched? Why do children react differently to things around them? These children have different ways of reacting to the things around them, to sensations. Over the years, different terms (such as sensory integration) have been used to describe how children deal with the information they receive through their senses. Currently, the term being used to describe children who have difficulty dealing with input from their senses is sensory processing disorder. _____________________________________________________________________ Sensory Processing Disorder -

SENSORY MOTOR COORDINATION in ROBONAUT Richard Alan Peters
SENSORY MOTOR COORDINATION IN ROBONAUT 5 Richard Alan Peters 11 Vanderbilt University School of Engineering JSC Mail Code: ER4 30 October 2000 Robert 0. Ambrose Robotic Systems Technology Branch Automation, Robotics, & Simulation Division Engineering Directorate Richard Alan Peters II Robert 0. Ambrose SENSORY MOTOR COORDINATION IN ROBONAUT Final Report NASNASEE Summer Faculty Fellowship Program - 2000 Johnson Space Center Prepared By: Richard Alan Peters II, Ph.D. Academic Rank: Associate Professor University and Department: Vanderbilt University Department of Electrical Engineering and Computer Science Nashville, TN 37235 NASNJSC Directorate: Engineering Division: Automation, Robotics, & Simulation Branch: Robotic Systems Technology JSC Colleague: Robert 0. Ambrose Date Submitted: 30 October 2000 Contract Number: NAG 9-867 13-1 ABSTRACT As a participant of the year 2000 NASA Summer Faculty Fellowship Program, I worked with the engineers of the Dexterous Robotics Laboratory at NASA Johnson Space Center on the Robonaut project. The Robonaut is an articulated torso with two dexterous arms, left and right five-fingered hands, and a head with cameras mounted on an articulated neck. This advanced space robot, now dnven only teleoperatively using VR gloves, sensors and helmets, is to be upgraded to a thinking system that can find, in- teract with and assist humans autonomously, allowing the Crew to work with Robonaut as a (junior) member of their team. Thus, the work performed this summer was toward the goal of enabling Robonaut to operate autonomously as an intelligent assistant to as- tronauts. Our underlying hypothesis is that a robot can deveZop intelligence if it learns a set of basic behaviors ([.e., reflexes - actions tightly coupled to sensing) and through experi- ence learns how to sequence these to solve problems or to accomplish higher-level tasks. -

Auditory System & Hearing
Auditory System & Hearing Chapters 9 part II Lecture 17 Jonathan Pillow Sensation & Perception (PSY 345 / NEU 325) Fall 2017 1 Cochlea: physical device tuned to frequency! • place code: tuning of different parts of the cochlea to different frequencies 2 The auditory nerve (AN): fibers stimulated by inner hair cells • Frequency selectivity: Clearest when sounds are very faint 3 Threshold tuning curves for 6 neurons (threshold = lowest intensity that will give rise to a response) Characteristic frequency - frequency to which the neuron is most sensitive threshold(dB) frequency (kHz) 4 Information flow in the auditory pathway • Cochlear nucleus: first brain stem nucleus at which afferent auditory nerve fibers synapse • Superior olive: brainstem region thalamus MGN in the auditory pathway where inputs from both ears converge • Inferior colliculus: midbrain nucleus in the auditory pathway • Medial geniculate nucleus (MGN): part of the thalamus that relays auditory signals to the cortex 5 • Primary auditory cortex (A1): First cortical area for processing audition (in temporal lobe) • Belt & Parabelt areas: areas beyond A1, where neurons respond to more complex characteristics of sounds 6 Basic Structure of the Mammalian Auditory System Comparing overall structure of auditory and visual systems: • Auditory system: Large proportion of processing before A1 • Visual system: Large proportion of processing after V1 7 Basic Structure of the Mammalian Auditory System Tonotopic organization: neurons organized spatially in order of preferred frequency • -

Study Guide Medical Terminology by Thea Liza Batan About the Author
Study Guide Medical Terminology By Thea Liza Batan About the Author Thea Liza Batan earned a Master of Science in Nursing Administration in 2007 from Xavier University in Cincinnati, Ohio. She has worked as a staff nurse, nurse instructor, and level department head. She currently works as a simulation coordinator and a free- lance writer specializing in nursing and healthcare. All terms mentioned in this text that are known to be trademarks or service marks have been appropriately capitalized. Use of a term in this text shouldn’t be regarded as affecting the validity of any trademark or service mark. Copyright © 2017 by Penn Foster, Inc. All rights reserved. No part of the material protected by this copyright may be reproduced or utilized in any form or by any means, electronic or mechanical, including photocopying, recording, or by any information storage and retrieval system, without permission in writing from the copyright owner. Requests for permission to make copies of any part of the work should be mailed to Copyright Permissions, Penn Foster, 925 Oak Street, Scranton, Pennsylvania 18515. Printed in the United States of America CONTENTS INSTRUCTIONS 1 READING ASSIGNMENTS 3 LESSON 1: THE FUNDAMENTALS OF MEDICAL TERMINOLOGY 5 LESSON 2: DIAGNOSIS, INTERVENTION, AND HUMAN BODY TERMS 28 LESSON 3: MUSCULOSKELETAL, CIRCULATORY, AND RESPIRATORY SYSTEM TERMS 44 LESSON 4: DIGESTIVE, URINARY, AND REPRODUCTIVE SYSTEM TERMS 69 LESSON 5: INTEGUMENTARY, NERVOUS, AND ENDOCRINE S YSTEM TERMS 96 SELF-CHECK ANSWERS 134 © PENN FOSTER, INC. 2017 MEDICAL TERMINOLOGY PAGE III Contents INSTRUCTIONS INTRODUCTION Welcome to your course on medical terminology. You’re taking this course because you’re most likely interested in pursuing a health and science career, which entails proficiencyincommunicatingwithhealthcareprofessionalssuchasphysicians,nurses, or dentists. -

Sensory Change Following Motor Learning
A. M. Green, C. E. Chapman, J. F. Kalaska and F. Lepore (Eds.) Progress in Brain Research, Vol. 191 ISSN: 0079-6123 Copyright Ó 2011 Elsevier B.V. All rights reserved. CHAPTER 2 Sensory change following motor learning { k { { Andrew A. G. Mattar , Sazzad M. Nasir , Mohammad Darainy , and { } David J. Ostry , ,* { Department of Psychology, McGill University, Montréal, Québec, Canada { Shahed University, Tehran, Iran } Haskins Laboratories, New Haven, Connecticut, USA k The Roxelyn and Richard Pepper Department of Communication Sciences and Disorders, Northwestern University, Evanston, Illinois, USA Abstract: Here we describe two studies linking perceptual change with motor learning. In the first, we document persistent changes in somatosensory perception that occur following force field learning. Subjects learned to control a robotic device that applied forces to the hand during arm movements. This led to a change in the sensed position of the limb that lasted at least 24 h. Control experiments revealed that the sensory change depended on motor learning. In the second study, we describe changes in the perception of speech sounds that occur following speech motor learning. Subjects adapted control of speech movements to compensate for loads applied to the jaw by a robot. Perception of speech sounds was measured before and after motor learning. Adapted subjects showed a consistent shift in perception. In contrast, no consistent shift was seen in control subjects and subjects that did not adapt to the load. These studies suggest that motor learning changes both sensory and motor function. Keywords: motor learning; sensory plasticity; arm movements; proprioception; speech motor control; auditory perception. Introduction the human motor system and, likewise, to skill acquisition in the adult nervous system. -

Inner Ear Infection (Otitis Interna) in Dogs
Hurricane Harvey Client Education Kit Inner Ear Infection (Otitis Interna) in Dogs My dog has just been diagnosed with an inner ear infection. What is this? Inflammation of the inner ear is called otitis interna, and it is most often caused by an infection. The infectious agent is most commonly bacterial, although yeast and fungus can also be implicated in an inner ear infection. If your dog has ear mites in the external ear canal, this can ultimately cause a problem in the inner ear and pose a greater risk for a bacterial infection. Similarly, inner ear infections may develop if disease exists in one ear canal or when a benign polyp is growing from the middle ear. A foreign object, such as grass seed, may also set the stage for bacterial infection in the inner ear. Are some dogs more susceptible to inner ear infection? Dogs with long, heavy ears seem to be predisposed to chronic ear infections that ultimately lead to otitis interna. Spaniel breeds, such as the Cocker spaniel, and hound breeds, such as the bloodhound and basset hound, are the most commonly affected breeds. Regardless of breed, any dog with a chronic ear infection that is difficult to control may develop otitis interna if the eardrum (tympanic membrane) is damaged as it allows bacteria to migrate down into the inner ear. "Dogs with long, heavy ears seem to bepredisposed to chronic ear infections that ultimately lead to otitis interna." Excessively vigorous cleaning of an infected external ear canal can sometimes cause otitis interna. Some ear cleansers are irritating to the middle and inner ear and can cause signs of otitis interna if the eardrum is damaged and allows some of the solution to penetrate too deeply. -

Neural Tracking of the Musical Beat Is Enhanced by Low-Frequency Sounds
Neural tracking of the musical beat is enhanced by low-frequency sounds Tomas Lenca, Peter E. Kellera, Manuel Varleta, and Sylvie Nozaradana,b,c,1 aMARCS Institute for Brain, Behaviour, and Development, Western Sydney University, Penrith, NSW 2751, Australia; bInstitute of Neuroscience (IONS), Université Catholique de Louvain, 1200 Woluwe-Saint-Lambert, Belgium; and cInternational Laboratory for Brain, Music, and Sound Research (BRAMS), Département de Psychologie, Faculté des Arts et des Sciences, Université de Montréal, Montréal, QC H3C 3J7, Canada Edited by Dale Purves, Duke University, Durham, NC, and approved June 28, 2018 (received for review January 24, 2018) Music makes us move, and using bass instruments to build the content (8, 9). Bass sounds are also crucial in music that en- rhythmic foundations of music is especially effective at inducing courages listeners to move (10, 11). people to dance to periodic pulse-like beats. Here, we show that There has been a recent debate as to whether evolutionarily this culturally widespread practice may exploit a neurophysiolog- shaped properties of the auditory system lead to superior tem- ical mechanism whereby low-frequency sounds shape the neural poral encoding for bass sounds (12, 13). One study using elec- representations of rhythmic input by boosting selective locking to troencephalography (EEG) recorded brain responses elicited by the beat. Cortical activity was captured using electroencephalog- misaligned tone onsets in an isochronous sequence of simulta- raphy (EEG) while participants listened to a regular rhythm or to a neous low- and high-pitched tones (12). Greater sensitivity to the relatively complex syncopated rhythm conveyed either by low temporal misalignment of low tones was observed when they tones (130 Hz) or high tones (1236.8 Hz). -

Can Other People Hear the Noise in My Ears? Not Usually, but Sometimes They Are Able to Hear a (Ertant Type Oftinnitus
Not at all. Tinnitus is the name for these head noises, and they are very common. Nearly 36 million Americans suffer from this discomfort. Tinnitus mav come and go, or you may be aware of a continuous sound. It can vary in pitch from a low roar to a high squeal or whine, and you may hear it in one or both ears. When the ringing is constant, It can be annoying and distracting. More than seven million people are afflicted so severely that they cannot lead normal lives. Can other people hear the noise in my ears? Not usually, but sometimes they are able to hear a (ertant type oftinnitus. This is called objective tinnitus, and it is caused either by abnormalities in blood vessels around the outside of the ear or by muscle spasms, which may sound like clicks or crackling illside the middle ear. There are many causes for subjective tinnitus, the nOlSC only you can hear. Some causes are not serious (a small plug of wax in the ear canal might cause temporary tinnitus). Tinnitus can also be a symptom of more serious middle ear problems such as infection, a hole in the eardrum, an accumulation of fluid, or stiffening (otosclerosis) of the middle ear bones. Tinnitus may also be caused by allergy, high or 10\V blood pressure (blood circulation problems), OUTER EAR MIDDLE EAR INNER EAR \ a tumor, diabetes, thyroid problems, injury to the head or neck, and a variety of other causes including medications such as anti-inflammatories, antibiotics, sedatives/antidepressants, and aspirin. -
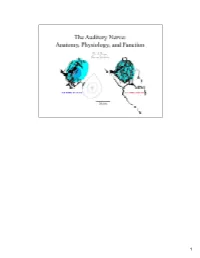
Auditory Nerve.Pdf
1 Sound waves from the auditory environment all combine in the ear canal to form a complex waveform. This waveform is deconstructed by the cochlea with respect to time, loudness, and frequency and neural signals representing these features are carried into the brain by the auditory nerve. It is thought that features of the sounds are processed centrally along parallel and hierarchical pathways where eventually percepts of the sounds are organized. 2 In mammals, the neural representation of acoustic information enters the brain by way of the auditory nerve. The auditory nerve terminates in the cochlear nucleus, and the cochlear nucleus in turn gives rise to multiple output projections that form separate but parallel limbs of the ascending auditory pathways. How the brain normally processes acoustic information will be heavily dependent upon the organization of auditory nerve input to the cochlear nucleus and on the nature of the different neural circuits that are established at this early stage. 3 This histology slide of a cat cochlea (right) illustrates the sensory receptors, the auditory nerve, and its target the cochlear nucleus. The orientation of the cut is illustrated by the pink line in the drawing of the cat head (left). We learned about the relationship between these structures by inserting a dye-filled micropipette into the auditory nerve and making small injections of the dye. After histological processing, stained single fibers were reconstruct back to their origin, and traced centrally to determine how they terminated in the brain. We will review the components of the nerve with respect to composition, innervation of the receptors, cell body morphology, myelination, and central terminations. -

What Is Sensory Integration?
WHAT IS SENSORY INTEGRATION? Sensory integration is the brain's innate ability to take in (register and perceive) information from the environment through the various senses, process and organize the information and then use it effectively. WHAT IS SENSORY INTEGRATION DYSFUNCTION? Sensory integration dysfunction is when the brain is unable to process the information received from the senses. When this occurs, the brain cannot analyze, organize or integrate this information to produce a functional outcome. POSSIBLE SYMPTOMS OF SENSORY INTEGRATION DYSFUNCTION Hyper or hypo sensitive to touch, movement, sight, sounds or smells. Activity level which is too high or too low. Coordination problems. Delays in speech, language, motor skills and academic achievement. Poor organization of behavior Poor self-concept (body awareness) THE VESTIBULAR SYSTEM Vestibular processing refers to the information that is provided by the receptors within the inner ear. These receptors are stimulated by movement of the head and input from other senses. This input tells where we are in relation to gravity, whether we are still or moving, how fast we are going, and in which direction. It also influences the development of balance, equilibrium, postural control and muscle tone. Vestibular input also plays an important role in helping to maintain a calm, alert state and keeping the level of arousal in the central nervous system balanced. An under-reactive vestibular system can contribute to distractibility and hyperactivity due to the lack of its modulating influence. Depending upon the situation, vestibular stimulation can either calm or stimulate and facilitate a more organized activity level. Children can be hyper and/or hypo-responsive to this type of input.