CWMT 2017 Machine Translation Evaluation Guidelines
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tibet School Music Education Development Process Since the Founding of New China
2019 2nd International Workshop on Advances in Social Sciences (IWASS 2019) Tibet School Music Education Development Process since the Founding of New China Kun Yang Lhasa Normal College, Lhasa, 850000, China, Tibet University, Lhasa, 850000, China Keywords: Tibet, Music education, The development course Abstract: music education in Tibet school is an important part of Tibet school education. With the national policy, social consciousness, teaching units, families and individuals attach importance to and help music education in schools, the public pays more and more attention to the importance of music education in schools. This paper reviews and summarizes the development of music education in preschool, primary and secondary schools and higher music education in Tibet since the founding of new China, and comprehensively grasizes the past and present of music education in Tibet schools, so as to provide reference for the sustainable development of music education in Tibet schools. 1. Introduction Since the founding of the People's Republic of China, music education in Tibet schools has developed in three aspects: preschool music education in Tibet, music education in Tibet primary and secondary schools, and music education in Tibet higher education. The higher music education in Tibet is divided into three parts: music education in Tibet (music major), music education in Tibet (preschool education major) and music education in Tibet (public art). By reviewing and tracing the development process of music education components in Tibet schools, it is of great theoretical and practical significance to help absorb advanced teaching experience and realize leapfrog development in the future. 2. Tibet Preschool Music Education Preschool education in Tibet can be divided into two periods: pre-democratic reform preschool education (before March 1959) and post-democratic reform preschool education (after March 1959). -

Westlake Youth Forum 2019 第四届西湖青年论坛
Westlake Youth Forum 2019 第四届西湖青年论坛 Call for Application Zhejiang University and China Medical Board (CMB) joint hands to host the 4th Westlake Youth Forum in 2019, with facilitation from China Health Policy and Management Society (CHPAMS). The Organizing Committee of the Forum is pleased to invite applications for participating in the Forum. The Forum provides a platform for young scholars worldwide to build up academic network, to exchange scientific thoughts and research experience, to communicate with senior scholars and policymakers, and to advance health policy in China. The 2019 Forum will be a three-day event for young researchers and practitioners in health policy and system on June 10-13, 2019 at Zhejiang University, China. Westlake Youth Forum: • When: June 10-13, 2019 • Where: Zhejiang University International Campus, Haining, Zhejiang Province, China • Preliminary Program: June 10. Registration and social activities June 11-12. Academic sessions and events of the Westlake Youth Forum June 13. Field visit What will be provided to all participants: • Local expenses including meals, accommodation, and local transportation in Haining, Zhejiang; • Networking with world-class academic leaders and young scholars from inside and outside of China; • Networking with Chinese academic leaders to explore your career opportunities in China; • Presenting your research and communicating with academic leaders and peers at the Forum. Who can apply for the participation (Eligibility)? • Scholars under 45 years old from CMB OC eligible schools (see Appendix I), OC awardees preferred but not required; • Working in public health related fields; • Having the interest to build collaboration with academic and research institutions, governmental departments, and corporations in China. -
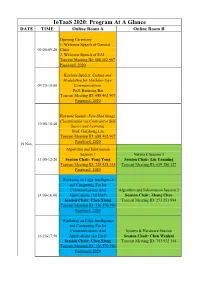
Iotaas 2020: Program at a Glance DATE TIME Online Room a Online Room B
IoTaaS 2020: Program At A Glance DATE TIME Online Room A Online Room B Opening Ceremony 1. Welcome Speech of General 09:00-09:20 Chair 2. Welcome Speech of EAI Tencent Meeting ID: 688 462 967 Password: 2020 Keynote Speech: Coding and Modulation for Machine-Type 09:20-10:00 Communications Prof. Baoming Bai Tencent Meeting ID: 688 462 967 Password: 2020 Keynote Speech: Few-Shot Image Classification via Contrastive Self- 10:00-10:40 Supervised Learning Prof. Guizhong Liu Tencent Meeting ID: 688 462 967 Password: 2020 19 Nov. Algorithm and Information Session 1 Network Session 1 11:00-12:20 Session Chair: Fang Yong Session Chair: Liu Yanming Tencent Meeting ID: 725 528 335 Tencent Meeting ID: 639 386 127 Password: 2020 Workshop on Edge Intelligence and Computing For Iot Communications And Algorithm and Information Session 2 14:00-16:00 Applications (1st Harf) Session Chair: Zhang Chen Session Chair: Chen Xiang Tencent Meeting ID: 273 251 994 Tencent Meeting ID: 156 570 396 Password: 2020 Workshop on Edge Intelligence and Computing For Iot Communications And System & Hardware Session 16:10-17:50 Applications (2st Harf) Session Chair: Chen Wenhui Session Chair: Chen Xiang Tencent Meeting ID: 751 932 354 Tencent Meeting ID: 156 570 396 Password: 2020 Workshop on Satellite Application Session Communications Session Chair: Abdullah Ghaleb 09:00-10:20 and Spatial Information Network Tencent Meeting ID: 672 146 720 Session Chair: Li Jingling Password: 2020 Tencent Meeting ID: 239 301 133 Network Session 2 Artificial Intelligence Session Session Chair: Li Bo Session Chair: Zhang Jingya 10:30-11:50 Tencent Meeting ID: 515 118 859 Tencent Meeting ID: 922 725 202 Password: 2020 Password: 2020 20 Nov. -

13 EN Tibet University--Yixiwangmu
Presentation of Tibet University Yixiwangmu International Exchange & Cooperation Department Tibet University http://www.utibet.edu.cn Where are We? http://www.utibet.edu.cn About Tibet Autonomous Region Geography Tibet Autonomous Region shares a 4,000 kilometer boarder with India, Bhutan, Nepal and Myanmar. “the Southwest Gate of China” “Roof of the World” “Third Pole of the Earth.” more than 1.2 million square kilometers, one eighth of China’s territory http://www.utibet.edu.cn http://www.utibet.edu.cn Natural Resources forest coverage of 14.626 million hectares, China’s richest water resource, 102 minerals being found, solar energy, geothermal energy, wind energy. highland barley, wheat, peas, and rapeseed, Tibetan antelope, wild yak, snow leopard, Tibetan Kiang, Tibetan eared-pheasant. http://www.utibet.edu.cn Administrative Districts 5 prefectural-level cities of Lhasa, Shigatse, Nyingchi, Qamdo, Lhoka, 2 prefectures of Nagqu and Ngari, 74 counties(district and city) http://www.utibet.edu.cn Population the lowest density population in China, 40 or more other ethnic groups (40,500) account for 92 percent and Han people (245,200) for 8 percent. http://www.utibet.edu.cn http://www.utibet.edu.cn http://www.utibet.edu.cn Tibet University History of TU 1985 The Tibet Normal School The Tibet Teacher’s School 1975 Founded as a Tibetan Language 1965 Training Class for Local Cadres The Tibet Normal School in 1975 1951 Tibet University In 1985 Founded as a TibetaTn hLea Tngibueatg Tee Tacrahienri’nsg S Cchlaososl fionr 1L9o6c5al Cadres in 1951 -

International Symposium on Water Resources Management and Comprehensive Reclamation of River Basins
International Symposium on Water Resources Management and Comprehensive Reclamation of River Basins International Scientific Symposium on Water Resources Management and Comprehensive Reclamation of River Basins Nanjing, China 17-19 November 2017 Organized by: Hohai University Nanjing Institute of Geography and Limnology, Chinese Academy of Sciences Chang’an University Operated by: Hohai University College of Hydrology and Water Resources State Key Laboratory of Hydrology-Water resources and Hydraulic Engineering National Engineering Research Center of Water Resources Efficient Utilization and Engineering Safety National Cooperative Innovation Center for Water Safety & Hydro Science Editorial Office of Water Science and Engineering Chinese Academy of Sciences Nanjing Institute of Geography Key Laboratory of Watershed Geography and Limnology Co-organized by: Beijing Normal University Tibet University Served by: Beijing Walter Consulting Co., Ltd 1 International Symposium on Water Resources Management and Comprehensive Reclamation of River Basins Scientific Committee Counselors: (Listed in no particular order) Congbin Fu Nanjing University and Hohai University, China Changming Liu Institute of Geographic Sciences and Natural Resources Research, CAS, China Yaoru Lu China University of Mining and Technology and Hohai University, China Yuqun Xue Nanjing University, China Jiyang Wang Institute of Geology and Geophysics, CAS, China Edward A. Sudicky University of Waterloo, Canada and Hohai University, China Chairs: (Listed in no particular order) -
![Arxiv:1906.05521V1 [Astro-Ph.HE] 13 Jun 2019 N Utaigmgeie Eaiitcpla Id[1] Wind Pulsar Relativistic Magnetized fluctuating a and .B Hu, B](https://docslib.b-cdn.net/cover/9763/arxiv-1906-05521v1-astro-ph-he-13-jun-2019-n-utaigmgeie-eaiitcpla-id-1-wind-pulsar-relativistic-magnetized-uctuating-a-and-b-hu-b-2149763.webp)
Arxiv:1906.05521V1 [Astro-Ph.HE] 13 Jun 2019 N Utaigmgeie Eaiitcpla Id[1] Wind Pulsar Relativistic Magnetized fluctuating a and .B Hu, B
First Detection of Photons with Energy Beyond 100 TeV from an Astrophysical Source M. Amenomori,1 Y. W. Bao,2 X. J. Bi,3 D. Chen,4 T. L. Chen,5 W. Y. Chen,3 Xu Chen†,3, 6 Y. Chen,2 Cirennima,5 S. W. Cui,7 Danzengluobu,5 L. K. Ding,3 J. H. Fang,3, 6 K. Fang,3 C. F. Feng,8 Zhaoyang Feng,3 Z. Y. Feng,9 Qi Gao,5 Q. B. Gou,3 Y. Q. Guo,3 H. H. He,3 Z. T. He,7 K. Hibino,10 N. Hotta,11 Haibing Hu,5 H. B. Hu,3 J. Huang§,3 H. Y. Jia,9 L. Jiang,3 H. B. Jin,4 F. Kajino,12 K. Kasahara,13 Y. Katayose,14 C. Kato,15 S. Kato,16 K. Kawata∗,16 M. Kozai,17 Labaciren,5 G. M. Le,18 A. F. Li,19, 8, 3 H. J. Li,5 W. J. Li,3, 9 Y. H. Lin,3, 6 B. Liu,2 C. Liu,3 J. S. Liu,3 M. Y. Liu,5 Y.-Q. Lou,20 H. Lu,3 X. R. Meng,5 H. Mitsui,14 K. Munakata,15 Y. Nakamura,3 H. Nanjo,1 M. Nishizawa,21 M. Ohnishi,16 I. Ohta,22 S. Ozawa,13 X. L. Qian,23 X. B. Qu,24 T. Saito,25 M. Sakata,12 T. K. Sako,16 Y. Sengoku,14 J. Shao,3, 8 M. Shibata,14 A. Shiomi,26 H. Sugimoto,27 M. Takita‡,16 Y. H. Tan,3 N. Tateyama,10 S. -

List of Designated Mainland Institutions Under Mainland University Study Subsidy Scheme 2019/20
List of Designated Mainland Institutions under Mainland University Study Subsidy Scheme 2019/20 Beijing Municipality University Shanghai University China Central Academy of Fine Tsinghua University Shanghai University of Arts University of International Traditional Chinese Medicine Central Conservatory of Music Business and Economics Shanghai International Studies The Central Academy of Drama University Central University of Finance Tianjin Municipality Shanghai Jiao Tong University and Economics Tianjin University Shanghai Conservatory of Music Minzu University of China Tianjin Polytechnic University Shanghai Normal University Renmin University of China Tianjin University of Traditional Shanghai New York University People’s Public Security Chinese Medicine Shanghai Ocean University University of China Tianjin Normal University Shanghai University of Finance China University of Petroleum Tianjin Medical University and Economics (Beijing) Hebei University of Technology Shanghai University of Sport China University of Geosciences Nankai University Tongji University (Beijing) Donghua University China University of Political Hebei Province Fudan University Science and Law North China Electric Power East China University of China Conservatory of Music University (Baoding) Political Science and Law Communication University of East China Normal University China Shanxi Province East China University Of China Agricultural University Tai Yuan University of Science And Technology China University of Mining and Technology The Second Military Medical -

University of Leeds Chinese Accepted Institution List 2021
University of Leeds Chinese accepted Institution List 2021 This list applies to courses in: All Engineering and Computing courses School of Mathematics School of Education School of Politics and International Studies School of Sociology and Social Policy GPA Requirements 2:1 = 75-85% 2:2 = 70-80% Please visit https://courses.leeds.ac.uk to find out which courses require a 2:1 and a 2:2. Please note: This document is to be used as a guide only. Final decisions will be made by the University of Leeds admissions teams. -

Tibet AS+MD Project
PROCEEDINGS OF THE 31st ICRC, ŁOD´ Z´ 2009 1 Tibet AS+MD Project M. Amenomori∗, X. J. Bi†, D. Chen‡, S. W. Cui§, Danzengluobu¶, L. K. Ding†, X. H. Ding¶, C. Fank, C. F. Fengk, Zhaoyang Feng†, Z. Y. Feng∗∗, X. Y. Gao††, Q. X. Geng††, Q. B. Gou†, H. W. Guo¶, H. H. He†, M. Hek, K. Hibino‡‡, N. Hottax , Haibing Hu¶, H. B. Hu†, J. Huang†, Q. Huang∗∗, H. Y. Jia∗∗, L. Jiang†† †, F. Kajinoxi , K. Kasaharaxii , Y. Katayosexiii , C. Katoxiv , K. Kawata‡, Labaciren¶, G. M. Lexv , A. F. Lik, H. C. Li§†, J. Y. Lik, C. Liu†, Y.-Q. Louxvi , H. Lu†, X. R. Meng¶, K. Mizutanixii xvii , J. Mu††, K. Munakataxiv , A. Nagaixviii , H. Nanjo∗, M. Nishizawaxix , M. Ohnishi‡, I. Ohtaxx , S. Ozawaxii , T. Saitoxxi , T. Y. Saitoxxii , M. Sakataxi , T. K. Sako‡, M. Shibataxiii , A. Shiomixxiii , T. Shirai‡‡, H. Sugimotoxxiv , M. Takita‡, Y. H. Tan†, N. Tateyama‡‡, S. Toriixii , H. Tsuchiyaxxv , S. Udo‡‡, B. Wang†, H. Wang†, Y. Wang†, Y. G. Wangk, H. R. Wu†, L. Xuek, Y. Yamamotoxi , C. T. Yanxxvi , X. C. Yang††, S. Yasuexxvii , Z. H. Yexxviii , G. C. Yu∗∗, A. F. Yuan¶, T. Yuda‡‡, H. M. Zhang†, J. L. Zhang†, N. J. Zhangk, X. Y. Zhangk, Y. Zhang†, Yi Zhang†, Ying Zhang∗∗ †, Zhaxisangzhu¶ and X. X. Zhou∗∗ (The Tibet ASγ Collaboration) ∗Department of Physics, Hirosaki University, Hirosaki 036-8561, Japan. †Key Laboratory of Particle Astrophysics, Institute of High Energy Physics, Chinese Academy of Sciences, Beijing 100049, China. ‡Institute for Cosmic Ray Research, University of Tokyo, Kashiwa 277-8582, Japan. §Department of Physics, Hebei Normal University, Shijiazhuang 050016, China. -

Open Courseware and the University of California June 20, 2008
Open Courseware and the University of California June 20, 2008 Gary W. Matkin Dean, Continuing Education University of California, Irvine 1 Slide 2 Timeline Slide 3 Global Reach Slide 4 Usage Statistics Slide 5 Universities working together to advance education and empower people 108 Institutions Associated w/ OCWC in 2007 Austria France Spain and Portugal University of Klagenfurt ParisTech OCW Universia OCW Univ. Central de Venezuela Vietnam Canada • Agronomie • Universidad Alicante Fulbright Econ. Teaching Prog. Capilano College • Arts et Métiers • Universidad Aveiro Vietnam OpenCourseWare • Universidad Barcelona China • Chimie Paris • Can Tho University China Open Res. for Education • Eaux et Forets • Univ. Carlos III de Madrid • Da Nang University • Bejing Hang University • Ecole des Mines de Paris • Universidad Islas Baleares • Beijing Jiao Tong University • Ecole Polytechnique • Universidad Jaume I • Hanoi Agriculture Univ. No. 1 • Beijing Normal University • Physique-Chimie France • Universidad Murcia • Hanoi Education University • Bejing Science & Tech. Univ. • Ponts et Chausse • Universidad Oviedo • Hanoi Medical University • Univ. Politécnica de Madrid • Central Radio and TV Univ. • Statistiques et Economie • Hanoi Nat. Univ. of Economics • Central South University • Techniques Avance • Univ. Politécnica de Valencia • Universidad Rovira i Virgili • Hanoi University of Technology • China Mining University • Telecom Paris • Univ. Santiago de Compostela • HCMC Education University • China People’s University India • Universidad Sevilla Saudi • HCMC Medical University • China Science & Tech. Univ. IIIT Bangalore Arabia • Dalian University of Tech. National Programme on Tech. • HCMC University of Economics Alfaisal University • Fu Dan University Enhanced Learning • Hue University • International Business & South Africa • Thai Nguyen University Econ. Univ. of China University of the Western Cape Japan • Vietnam Nat. -

Teaching and Learning in Tibet Provides an Unbiased and Comprehensive Guide to Documents And
BANGSBO Teaching andLearning inTibet A Review of Research and Policy Publications Teaching Ellen Bangsbo The issue of schooling and education for Tibetan children in TEACHING AND LEARNING the Tibetan Autonomous Region (TAR) is the focus of in- andLearning creasing national and international attention. Here, special attention has been given to the concept of ‘quality education’. One should be aware that this concept is understood differently by different groups. Educationalists and NGOs inTibet with programmes in Tibet view ‘quality education’ from the international perspective of methodology and pedagogy; here, the aim is to teach children to think independently. In contrast, Chinese authorities promote ‘quality education’ as A Review of Research and Policy Publications an antidote to ‘exam-oriented education’ and as a means to support nationalistic, patriotic and moral education. The challenge is to bridge these two views. ELLEN BANGSBO To this end, Teaching and Learning in Tibet provides an unbiased and comprehensive guide to documents and publications on schooling and education in Tibet dealing IN TIBET with issues relating to ‘quality education’, teaching and curriculum, bi- and trilingual teaching policies, teachers’ education, ‘key-schools’, access to school, and other chal- lenges related to schooling in Tibet. www.niaspress.dk PRELIMS.fm Page i Friday, February 6, 2004 2:34 PM TEACHING AND LEARNING IN TIBET PRELIMS.fm Page ii Friday, February 6, 2004 2:34 PM Nordic Institute of Asian Studies Recent NIAS Reports 28. Christopher E. Goscha: Vietnam or Indochina? Contesting Concepts of Space in Vietnamese Nationalism, 1887–1954 29. Alain Lefebvre: Islam, Human Rights and Child Labour in Pakistan 30. -

Go Abroad China
GO ABROAD CHINA GO ABROAD CHINA 1 THE BEST WAY TO EXPERIENCE CHINA TABLE OF CONTENTS l About GAC Programs 3 l GAC University Programs 4 l GAC High School Programs 5 l GAC 1-On-1 Tutoring 6 l GAC Business Chinese 6 l GAC Study Tours in China 7 l GAC Internship in China 8 l GAC Volunteer Program 9 l GAC Elective Workshops 9 l GAC Activities & Excursions 9 l GAC Accommodations 10 l GAC Service Package 11 l Contact GAC 12 GO ABROAD CHINA 2 THE BEST WAY TO EXPERIENCE CHINA ABOUT GAC PROGRAMS Unlike the study of other disciplines, learning a language is a truly personal pursuit and demands flexibility to best reflect students’ study habits and goals. With that in mind, our programs offer a variety of customizable options, including the choice of university, program level and intensity, dates and length of the study term, as well as numerous social and cultural activities. We offer courses from one week up to one year, from classes or group to 1-on-1 tutoring, and from total beginners to advanced students. We also offer internships, teach and volunteer programs. Whether you are a high school student looking for an edge before applying to college, a college student aiming to build your resume, or a professional seeking to build language skills and network, our programs are waiting for you! GAC China Study Abroad Programs l University Programs l High School Year Abroad Programs l High School Summer / Winter Camp Private Tutoring l l Business Chinese l Study Tours in China l Internship in China l Volunteer in China l Customized Program l GAC Service Package l Accommodation Elective Workshops l Chinese Massage l Chinese Calligraphy Chinese Painting l l Taiji Class l Martial Arts l Chinese Medicine Cities & Locations l Beijing l Shanghai l Xi’an l Qingdao l Dalian l Nanjing l Hangzhou l Shenzhen l Tibet GO ABROAD CHINA 3 THE BEST WAY TO EXPERIENCE CHINA GAC UNIVERSITY PROGRAMS BEIJING Learn the Chinese language and about the civilization at a top Chinese university in a unique integrated fashion.