Jiehan Zhu [email protected] Video
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Top of Page Interview Information--Different Title
Oral History Center University of California The Bancroft Library Berkeley, California The Freedom to Marry Oral History Project Thalia Zepatos Thalia Zepatos on Research and Messaging in Freedom to Marry Interviews conducted by Martin Meeker in 2016 Copyright © 2017 by The Regents of the University of California ii Since 1954 the Oral History Center of the Bancroft Library, formerly the Regional Oral History Office, has been interviewing leading participants in or well-placed witnesses to major events in the development of Northern California, the West, and the nation. Oral History is a method of collecting historical information through tape-recorded interviews between a narrator with firsthand knowledge of historically significant events and a well-informed interviewer, with the goal of preserving substantive additions to the historical record. The tape recording is transcribed, lightly edited for continuity and clarity, and reviewed by the interviewee. The corrected manuscript is bound with photographs and illustrative materials and placed in The Bancroft Library at the University of California, Berkeley, and in other research collections for scholarly use. Because it is primary material, oral history is not intended to present the final, verified, or complete narrative of events. It is a spoken account, offered by the interviewee in response to questioning, and as such it is reflective, partisan, deeply involved, and irreplaceable. ********************************* All uses of this manuscript are covered by a legal agreement between The Regents of the University of California and Thalia Zepatos dated September 6, 2016. The manuscript is thereby made available for research purposes. All literary rights in the manuscript, including the right to publish, are reserved to The Bancroft Library of the University of California, Berkeley. -

Heather Hayes Experience Songlist Aretha Franklin Chain of Fools
Heather Hayes Experience Songlist Aretha Franklin Chain of Fools Respect Ben E. King Stand By Me Drifters Under The Boardwalk Eddie Floyd Knock On Wood The Four Tops Sugar Pie Honey Bunch James Brown I Feel Good Sex Machine The Marvelettes My Guy Marvin Gaye & Tammie Terrell You’re All I Need Michael Jackson I’ll Be There Otis Redding Sittin’ On The Dock Of The Bay Percy Sledge When A Man Loves A Woman Sam & Dave Soul Man Sam Cooke Chain Gang Twistin’ Smokey Robinson Cruisin The Tams Be Young, Be Foolish, Be Happy The Temptations OtherBrother Entertainment, Inc. – Engagement Contract Page 1 of 2 Imagination My Girl The Isley Brothers Shout Wilson Pickett Mustang Sally Contemporary and Dance 50 cent Candy Shop In Da Club Alicia Keys If I Ain’t Got You No One Amy Winehouse Rehab Ashanti Only You Ooh Baby Babyface Whip Appeal Beyoncé Baby Boy Irreplaceable Naughty Girls Work It Out Check Up On It Crazy In Love Dejá vu Black Eyed Peas My Humps Black Street No Diggity Chingy Right Thurr Ciara 1 2 Step Goodies Oh OtherBrother Entertainment, Inc. – Engagement Contract Page 2 of 2 Destiny’s Child Bootylicious Independent Women Loose My Breath Say My Name Soldiers Dougie Fresh Mix Planet Rock Dr Dre & Tupac California Love Duffle Mercy Fat Joe Lean Back Fergie Glamorous Field Mobb & Ciara So What Flo Rida Low Gnarls Barkley Crazy Gwen Stefani Holla Back Girl Ice Cube Today Was A Good Day Jamie Foxx Unpredictable Jay Z Give It To Me Jill Scott Is It The Way John Mayer Your Body Is A Wonderland Kanye West Flashy Lights OtherBrother Entertainment, Inc. -

Thematic Patterns in Millennial Heavy Metal: a Lyrical Analysis
University of Central Florida STARS Electronic Theses and Dissertations, 2004-2019 2012 Thematic Patterns In Millennial Heavy Metal: A Lyrical Analysis Evan Chabot University of Central Florida Part of the Sociology Commons Find similar works at: https://stars.library.ucf.edu/etd University of Central Florida Libraries http://library.ucf.edu This Masters Thesis (Open Access) is brought to you for free and open access by STARS. It has been accepted for inclusion in Electronic Theses and Dissertations, 2004-2019 by an authorized administrator of STARS. For more information, please contact [email protected]. STARS Citation Chabot, Evan, "Thematic Patterns In Millennial Heavy Metal: A Lyrical Analysis" (2012). Electronic Theses and Dissertations, 2004-2019. 2277. https://stars.library.ucf.edu/etd/2277 THEMATIC PATTERNS IN MILLENNIAL HEAVY METAL: A LYRICAL ANALYSIS by EVAN CHABOT B.A. University of Florida, 2011 A thesis submitted in partial fulfillment of the requirements for the degree of Master of Arts in the Department of Sociology in the College of Sciences at the University of Central Florida Orlando, Florida Fall Term 2012 ABSTRACT Research on heavy metal music has traditionally been framed by deviant characterizations, effects on audiences, and the validity of criticism. More recently, studies have neglected content analysis due to perceived homogeneity in themes, despite evidence that the modern genre is distinct from its past. As lyrical patterns are strong markers of genre, this study attempts to characterize heavy metal in the 21st century by analyzing lyrics for specific themes and perspectives. Citing evidence that the “Millennial” generation confers significant developments to popular culture, the contemporary genre is termed “Millennial heavy metal” throughout, and the study is framed accordingly. -

Understanding Black Feminism Through the Lens of Beyoncé’S Pop Culture Performance Kathryn M
Seattle aP cific nivU ersity Digital Commons @ SPU Honors Projects University Scholars Spring June 7th, 2018 I Got Hot Sauce In My Bag: Understanding Black Feminism Through The Lens of Beyoncé’s Pop Culture Performance Kathryn M. Butterworth Follow this and additional works at: https://digitalcommons.spu.edu/honorsprojects Part of the Feminist, Gender, and Sexuality Studies Commons, and the Race, Ethnicity and Post- Colonial Studies Commons Recommended Citation Butterworth, Kathryn M., "I Got Hot Sauce In My Bag: Understanding Black Feminism Through The Lens of Beyoncé’s Pop Culture Performance" (2018). Honors Projects. 81. https://digitalcommons.spu.edu/honorsprojects/81 This Honors Project is brought to you for free and open access by the University Scholars at Digital Commons @ SPU. It has been accepted for inclusion in Honors Projects by an authorized administrator of Digital Commons @ SPU. I GOT HOT SAUCE IN MY BAG: UNDERSTANDING BLACK FEMINISM THROUGH THE LENS OF BEYONCÉ’S POP CULTURE PREFORMANCE by KATHRYN BUTTERWORTH FACULTY ADVISOR, YELENA BAILEY SECOND READER, CHRISTINE CHANEY A project submitted in partial fulfillment of the requirements of the University Scholars Program Seattle Pacific University 2018 Approved_________________________________ Date____________________________________ Abstract In this paper I argue that Beyoncé’s visual album, Lemonade, functions as a textual hybrid between poetry, surrealist aesthetics and popular culture—challenging the accepted understanding of cultural production within academia. Furthermore, Lemonade centers black life while presenting mainstream audiences with poetry and avant-garde imagery that challenge dominant views of black womanhood. Using theorists bell hooks, Stuart Hall, Patricia Hill- Collins and Audre Lorde, among others, I argue that Beyoncé’s work challenges the understanding of artistic production while simultaneously fitting within a long tradition of black feminist cultural production. -

Big Blast & the Party Masters
BIG BLAST & THE PARTY MASTERS 2018 Song List ● Aretha Franklin - Freeway of Love, Dr. Feelgood, Rock Steady, Chain of Fools, Respect, Hello CURRENT HITS Sunshine, Baby I Love You ● Average White Band - Pick Up the Pieces ● B-52's - Love Shack - KB & Valerie+A48 ● Beatles - I Want to Hold Your Hand, All You Need ● 5 Seconds of Summer - She Looks So Perfect is Love, Come Together, Birthday, In My Life, I ● Ariana Grande - Problem (feat. Iggy Azalea), Will Break Free ● Beyoncé & Destiny's Child - Crazy in Love, Déjà ● Aviici - Wake Me Up Vu, Survivor, Halo, Love On Top, Irreplaceable, ● Bruno Mars - Treasure, Locked Out of Heaven Single Ladies(Put a Ring On it) ● Capital Cities - Safe and Sound ● Black Eyed Peas - Let's Get it Started, Boom ● Ed Sheeran - Sing(feat. Pharrell Williams), Boom Pow, Hey Mama, Imma Be, I Gotta Feeling Thinking Out Loud ● The Bee Gees - Stayin' Alive, Emotions, How Deep ● Ellie Goulding - Burn Is You Love ● Fall Out Boy - Centuries ● Bill Withers - Use Me, Lovely Day ● J Lo - Dance Again (feat. Pitbull), On the Floor ● The Blues Brothers - Everybody Needs ● John Legend - All of Me Somebody, Minnie the Moocher, Jailhouse Rock, ● Iggy Azalea - I'm So Fancy Sweet Home Chicago, Gimme Some Lovin' ● Jessie J - Bang Bang(Ariana Grande, Nicki Minaj) ● Bobby Brown - My Prerogative ● Justin Timberlake - Suit and Tie ● Brass Construction - L-O-V-E - U ● Lil' Jon Z & DJ Snake - Turn Down for What ● The Brothers Johnson - Stomp! ● Lorde - Royals ● Brittany Spears - Slave 4 U, Till the World Ends, ● Macklemore and Ryan Lewis - Can't Hold Us Hit Me Baby One More Time ● Maroon 5 - Sugar, Animals ● Bruno Mars - Just the Way You Are ● Mark Ronson - Uptown Funk (feat. -

The Derailment of Feminism: a Qualitative Study of Girl Empowerment and the Popular Music Artist
THE DERAILMENT OF FEMINISM: A QUALITATIVE STUDY OF GIRL EMPOWERMENT AND THE POPULAR MUSIC ARTIST A Thesis by Jodie Christine Simon Master of Arts, Wichita State University, 2010 Bachelor of Arts. Wichita State University, 2006 Submitted to the Department of Liberal Studies and the faculty of the Graduate School of Wichita State University in partial fulfillment of the requirements for the degree of Master of Arts July 2012 @ Copyright 2012 by Jodie Christine Simon All Rights Reserved THE DERAILMENT OF FEMINISM: A QUALITATIVE STUDY OF GIRL EMPOWERMENT AND THE POPULAR MUSIC ARTIST The following faculty members have examined the final copy of this thesis for form and content, and recommend that it be accepted in partial fulfillment of the requirement for the degree of Masters of Arts with a major in Liberal Studies. __________________________________________________________ Jodie Hertzog, Committee Chair __________________________________________________________ Jeff Jarman, Committee Member __________________________________________________________ Chuck Koeber, Committee Member iii DEDICATION To my husband, my mother, and my children iv ACKNOWLEDGMENTS I would like to thank my adviser, Dr. Jodie Hertzog, for her patient and insightful advice and support. A mentor in every sense of the word, Jodie Hertzog embodies the very nature of adviser; her council was very much appreciated through the course of my study. v ABSTRACT “Girl Power!” is a message that parents raising young women in today’s media- saturated society should be able to turn to with a modicum of relief from the relentlessly harmful messages normally found within popular music. But what happens when we turn a critical eye toward the messages cloaked within this supposedly feminist missive? A close examination of popular music associated with girl empowerment reveals that many of the messages found within these lyrics are frighteningly just as damaging as the misogynistic, violent, and explicitly sexual ones found in the usual fare of top 100 Hits. -

Bibliography 50 Cent - in Da Club (Sheet Music)
Examples of MYP personal projects: Example 2C Bibliography 50 Cent - In Da Club (Sheet Music). (n.d.). Piano Box. Retrieved February 13, 2013, from http://my-pianobox.blogspot.com/2009/07/start.html Adams, B. (n.d.). Everything I Do I Do It For You Chords. ULTIMATE GUITAR. Retrieved February 5, 2013, from http://tabs.ultimate-guitar.com/b/ bryan_adams/everything_i_do_i_do_it_for_you_crd.htm Adele. (n.d.). Rolling In The Deep Chords. ULTIMATE GUITAR. Retrieved February 21, 2013, from http://tabs.ultimate-guitar.com/a/adele/rolling_in_the_deep_ver9_crd.htm Adele. (n.d.). Rolling in the Deep - Wikipedia, the free encyclopedia. Wikipedia, the free encyclopedia. Retrieved December 22, 2012, from http://en.wikipedia.org/wiki/ Rolling_in_the_Deep Software. (n.d.). Pop Music. Audials Software. Retrieved March 3, 2013, from audials.com/en/ genres/index.html Ballad of the Green Beret Chords. (n.d.). Ultimate Guitar. Retrieved January 16, 2013, from tabs.ultimate-guitar.com/b/barry_sadler/ballad_of_the_green_beret_crd.htm Bands, M. U. (n.d.). Kim Carnes - Bette Davis Eyes Chords. ULTIMATE GUITAR . Retrieved February 3, 2013, from http://tabs.ultimate-guitar.com/m/ misc_unsigned_bands/kim_carnes_-_bette_davis_eyes_crd.htm Beatles. (n.d.). I Want To Hold Your Hand Chords. ULTIMATE GUITAR. Retrieved January 12, 2013, from http://tabs.ultimate-guitar.com/b/beatles/ i_want_to_hold_your_hand_ver2_crd.htm Beatles. (n.d.). Hey Jude Chords. ULTIMATE GUITAR . Retrieved January 16, 2013, from http:// tabs.ultimate-guitar.com/b/beatles/hey_jude_crd.htm Believe Chords. (n.d.). ULTIMATE GUITAR. Retrieved February 12, 2013, from tabs.ultimate- guitar.com/c/cher/believe_ver2_crd.htm 60 Projects teacher support material 1 Examples of MYP personal projects: Example 2C Best of 2006: Hot 100. -

Top Songs of the 2010S
Top Songs of the 2010s FIREWORK Katy Perry Chart Run: Top 40: Top 10: #1: 40, 27, 20, 12, 9, 8, 7, 5, 3, 2, 1, 1, 1, 3, 4, 5, 6, 6, 6, 8, 11, 15, 21, 24 SOMEONE LIKE YOU Adele Chart Run: Top 40: Top 10: #1: 35, 30, 19, 14, 11, 10, 5, 2, 2, 1, 1, 1, 1, 4, 5, 5, 8, 10, 12, 12, 14, 16, 26, 32 STRONGER (WHAT DOESN ’T KILL YOU ) Kelly Clarkson Chart Run: Top 40: Top 10: #1: 27, 15, 13, 8, 5, 3, 2, 2, 1, 1, 1, 1, 3, 5, 8, 10, 13, 15, 17, 21, 39 SHAKE IT OFF Taylor Swift Chart Run: Top 40: Top 10: #1: 17, 8, 6, 4, 2, 2, 2, 1, 1, 1, 3, 4, 3, 4, 8, 10, 14, 16, 20, 21, 37 BLANK SPACE Taylor Swift Chart Run: Top 40: Top 10: #1: 31, 16, 11, 5, 3, 1, 1, 1, 1, 1, 1, 1, 2, 4, 5, 8, 9, 10, 12, 15, 30 THINKING OUT LOUD Ed Sheeran Chart Run: Top 40: Top 10: #1: 33, 21, 15, 13, 9, 8, 7, 3, 2, 1, 1, 1, 1, 2, 2, 4, 5, 13, 16, 23, 30 LOVE YOURSELF Justin Bieber Chart Run: Top 40: Top 10: #1: 33, 23, 16, 13, 11, 7, 4, 2, 1, 1, 2, 2, 2, 2, 3, 6, 8, 13, 14, 17, 22, 25, 26, 26, 32, 36 CAN ’T STOP THE FEELING Justin Timberlake Chart Run: Top 40: Top 10: #1: 20, 9, 6, 3, 1, 1, 1, 2, 3, 3, 4, 5, 10, 13, 15, 17, 19, 21, 24, 28 FEEL IT STILL Portugal. -

'Being in Love': an Interpretative Phenomenological Analysis of Young Australians' Romantic Experiences
‘BEING IN LOVE’: An Interpretative Phenomenological Analysis of Young Australians’ Romantic Experiences Ler Ping Wee (Levan) orcid.org/0000-0001-6840-8561 Submitted in total fulfilment of the requirements of the degree of Doctor of Philosophy September 2017 School of Social and Political Sciences UNIVERSITY OF MELBOURNE Abstract Romantic love touches and guides the intimate worlds of people every day. My thesis seeks to examine a popular experiential substrate of many Western romantic relationships – specifically, the feeling of ‘being in love’. Using Interpretative Phenomenological Analysis (IPA), this small- scale idiographic study focuses on the lives of four young Australians – all of whom profess to be in ‘truly loving’ partnerships with their ongoing beloveds. Multiple in-depth face-to-face interviews conducted over three years are the prime source of experiential data collection. My main research goal is to discover the shared qualities / meanings that interviewees themselves regard as defining facets of ‘being in love’. Inductive questions concerning their self-experiences, orientations towards partners, and other related existential enquiries are also explored. Key findings suggest interviewees’ ‘ideal’ or optimal states of loving are primarily composed of coalescing perceptions of self-growth, friendship, attraction, altruism, and reciprocity. By contrast, ‘unideal’ or impoverished states of ‘being in love’ occur amidst sustained declines in one or more of these thematic experiences. Both ideal and unideal conditions are crucial to shaping their overall impressions of ‘real love’. As per the directives of IPA research, all the above discoveries are examined in richly hermeneutic and phenomenological terms. Mark Johnson’s philosophy of embodiment is also applied – in particular, his notions of image schemas and non-dualistic processes of meaning-making. -

The Irreplaceable Role of Planned Parenthood Health Centers
The Irreplaceable Role of Planned Parenthood Health Centers Planned Parenthood is a leading provider of high-quality, affordable health care for women, men, and young people, and the nation’s largest provider of sex education. Planned Parenthood health centers provided millions of people in the U.S. with contraception, testing and treatment for sexually transmitted infections (STIs), lifesaving cancer screenings, and safe, legal abortion. At least one in five women has relied on a Planned Parenthood health center for care in her lifetime. • In 2018, Planned Parenthood health centers saw 2.4 million patients. Its centers provided nearly 5 million tests and treatments for sexually transmitted infections; more than 265,000 breast exams; more than 255,000 Pap tests; and birth control to nearly 2 million people. • Planned Parenthood leads the country with the most up-to-date medical standards and guidelines for reproductive health care and uses clinical research to advance health care delivery to reach people in need of care. • Fifty-seven percent (57%) of Planned Parenthood health centers are located in rural or medically underserved areas. Planned Parenthood health centers provide primary and preventive health care to many who otherwise would have nowhere to turn for family planning services. • More than one-third (39%) of Planned Parenthood patients are people of color, with more than 541,000 patients who identify as Latino and nearly 395,000 patients who identify as Black. • Of Planned Parenthood patients who report their income, nearly 75 percent live with incomes at or below 150 percent of the federal poverty level (FPL), and almost 60 percent of Planned Parenthood patients access care through the Medicaid program and/or the Title X family planning program. -

Songs by Artist
Songs by Artist Title Title (Hed) Planet Earth 2 Live Crew Bartender We Want Some Pussy Blackout 2 Pistols Other Side She Got It +44 You Know Me When Your Heart Stops Beating 20 Fingers 10 Years Short Dick Man Beautiful 21 Demands Through The Iris Give Me A Minute Wasteland 3 Doors Down 10,000 Maniacs Away From The Sun Because The Night Be Like That Candy Everybody Wants Behind Those Eyes More Than This Better Life, The These Are The Days Citizen Soldier Trouble Me Duck & Run 100 Proof Aged In Soul Every Time You Go Somebody's Been Sleeping Here By Me 10CC Here Without You I'm Not In Love It's Not My Time Things We Do For Love, The Kryptonite 112 Landing In London Come See Me Let Me Be Myself Cupid Let Me Go Dance With Me Live For Today Hot & Wet Loser It's Over Now Road I'm On, The Na Na Na So I Need You Peaches & Cream Train Right Here For You When I'm Gone U Already Know When You're Young 12 Gauge 3 Of Hearts Dunkie Butt Arizona Rain 12 Stones Love Is Enough Far Away 30 Seconds To Mars Way I Fell, The Closer To The Edge We Are One Kill, The 1910 Fruitgum Co. Kings And Queens 1, 2, 3 Red Light This Is War Simon Says Up In The Air (Explicit) 2 Chainz Yesterday Birthday Song (Explicit) 311 I'm Different (Explicit) All Mixed Up Spend It Amber 2 Live Crew Beyond The Grey Sky Doo Wah Diddy Creatures (For A While) Me So Horny Don't Tread On Me Song List Generator® Printed 5/12/2021 Page 1 of 334 Licensed to Chris Avis Songs by Artist Title Title 311 4Him First Straw Sacred Hideaway Hey You Where There Is Faith I'll Be Here Awhile Who You Are Love Song 5 Stairsteps, The You Wouldn't Believe O-O-H Child 38 Special 50 Cent Back Where You Belong 21 Questions Caught Up In You Baby By Me Hold On Loosely Best Friend If I'd Been The One Candy Shop Rockin' Into The Night Disco Inferno Second Chance Hustler's Ambition Teacher, Teacher If I Can't Wild-Eyed Southern Boys In Da Club 3LW Just A Lil' Bit I Do (Wanna Get Close To You) Outlaw No More (Baby I'ma Do Right) Outta Control Playas Gon' Play Outta Control (Remix Version) 3OH!3 P.I.M.P. -
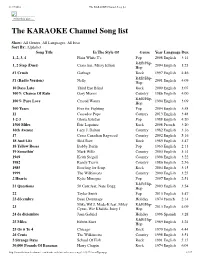
The KARAOKE Channel Song List
11/17/2016 The KARAOKE Channel Song list Print this List ... The KARAOKE Channel Song list Show: All Genres, All Languages, All Eras Sort By: Alphabet Song Title In The Style Of Genre Year Language Dur. 1, 2, 3, 4 Plain White T's Pop 2008 English 3:14 R&B/Hip- 1, 2 Step (Duet) Ciara feat. Missy Elliott 2004 English 3:23 Hop #1 Crush Garbage Rock 1997 English 4:46 R&B/Hip- #1 (Radio Version) Nelly 2001 English 4:09 Hop 10 Days Late Third Eye Blind Rock 2000 English 3:07 100% Chance Of Rain Gary Morris Country 1986 English 4:00 R&B/Hip- 100% Pure Love Crystal Waters 1994 English 3:09 Hop 100 Years Five for Fighting Pop 2004 English 3:58 11 Cassadee Pope Country 2013 English 3:48 1-2-3 Gloria Estefan Pop 1988 English 4:20 1500 Miles Éric Lapointe Rock 2008 French 3:20 16th Avenue Lacy J. Dalton Country 1982 English 3:16 17 Cross Canadian Ragweed Country 2002 English 5:16 18 And Life Skid Row Rock 1989 English 3:47 18 Yellow Roses Bobby Darin Pop 1963 English 2:13 19 Somethin' Mark Wills Country 2003 English 3:14 1969 Keith Stegall Country 1996 English 3:22 1982 Randy Travis Country 1986 English 2:56 1985 Bowling for Soup Rock 2004 English 3:15 1999 The Wilkinsons Country 2000 English 3:25 2 Hearts Kylie Minogue Pop 2007 English 2:51 R&B/Hip- 21 Questions 50 Cent feat. Nate Dogg 2003 English 3:54 Hop 22 Taylor Swift Pop 2013 English 3:47 23 décembre Beau Dommage Holiday 1974 French 2:14 Mike WiLL Made-It feat.